Как за 75 долларов собрать датасет из 50 тысяч изображений: опыт стартапа Neatsy

Разбор кейса сбора большого датасета через краудсорсинг с поэтапным описанием.

Роман Куцев
дата-инженер в компании Neatsy
Привет! Я — Роман Куцев, дата-инженер в компании Neatsy. Мы с командой разрабатываем приложение, с помощью которого можно с первого раза заказать в интернете комфортную обувь. Наша идея — помочь людям подбирать обувь онлайн, а интернет-магазинам не терять деньги на возвратах. Чтобы осуществить задумку, нам нужно было обучить нейросеть — собрать и разметить 50 тысяч фотографий ног разного размера. Расскажу, как мы решали задачу, какие набили шишки и почему краудсорсинг — удобный инструмент для сбора данных.
Обратиться к 200 знакомым, собрать 3000 фотографий и попасть в два чёрных списка
Итак, перед нами задача: собрать датасет из 50 тысяч фотографий, чтобы научить алгоритм автоматически строить 3D-модель стопы и определять её размер даже при плохом освещении и на пёстрой плитке. Мы составили требования к съёмке с учётом разных условий:
- освещение: искусственное, дневной свет, сумерки;
- фон: паркет, линолеум, пушистый ковер, разноцветная плитка — годилось всё;
- цвета кожи: от светлых до тёмных;
- ракурсы ног: под разными углами, сверху, снизу, сбоку.
Мне уже приходилось искать исполнителей для разметки данных: до Neatsy я работал в Prisma, где тоже нужно было собирать данные для обучения нейронных сетей. В Prisma нам повезло: наш разработчик Вячеслав Тарасов параллельно преподавал в Воронежском государственном университете, и у него был доступ к большому числу студентов. Не знаю, как он их мотивировал — хорошей оценкой или «автоматом», но студенты присылали нужные фото и видео, и мы успешно собирали данные.
У команды Neatsy не было доступа к студентам, поэтому мы нашли другой способ: публиковали сториз, звонили и писали всем друзьям, знакомым и родным, безбожно отвлекали их от дел, просили заснять свои ноги и отправить нам. Мы были как секта сетевого маркетинга. Двое наших знакомых даже добавили нас в чёрный список.
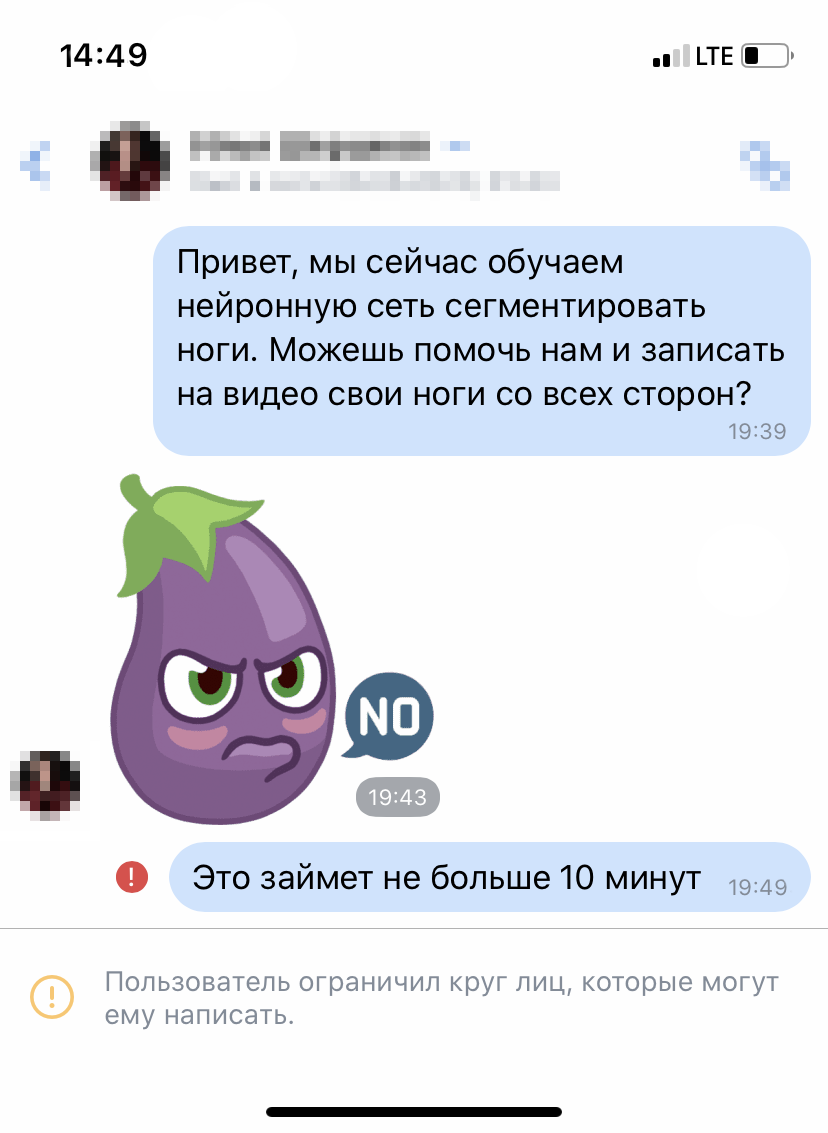
Такие дела
Осознать, что всё не так просто
Увы, стратегия оказалась проигрышной. Во-первых, на наш клич отозвались всего 200 человек, потому что круг знакомых всё-таки ограничен.
Во-вторых, такой метод отнимал слишком много сил и времени. Нужно написать каждому и рассказать, что сделать; дождаться данных, скачать и перепроверить. На одного человека уходило в среднем 20 минут. Потребовалось бы около восьми рабочих дней, чтобы собрать 200 видео. А нам нужно было больше, чем 200 видео.
Поясню, почему мы собирали видео, а не фото. Если обучать нейронную сеть на тех же данных, которые ожидаются в реальной жизни, качество её работы будет выше. А мы планировали обучить нейронную сеть сегментировать ноги по видеопотоку. Поэтому кадры, нарезанные из видео, были предпочтительнее фотографий.
В общей сложности мы собрали около 3000 изображений. В принципе, для проверки гипотез и создания MVP этого достаточно. Но чтобы создать продукт, который работает в любом месте и на каждом человеке, данных надо намного больше.
Встать на нужные рельсы
Набив шишки, мы решили пойти по другому пути и отдать задачу в Яндекс.Толоку. Вот несколько моментов, которые были нам на руку:
- Передача авторских прав. Юристы в международных компаниях часто беспокоятся о чистоте и прозрачности передачи прав на результаты интеллектуальной деятельности. В Толоке всё было просто и однозначно: результаты разметки принадлежат заказчику. Словом, можно спать спокойно.
- Гибкое масштабирование. Нам понравилось, что Толока работает как биржа: мы дали задание — его выполняют, не дали — исполнители занимаются другими заданиями и ничего от нас не ждут. Это намного удобнее, чем нанимать штат разметчиков, которым не будет хватать нагрузки: рано или поздно актуальные задачи могут закончиться.
- Огромное количество исполнителей. На краудсорсинговых платформах ежедневно работают десятки тысяч исполнителей. Мы подсчитали, что с нашей задачей, которую штат разметчиков будет делать три недели, разметчики на краудсорсинговой платформе справятся за день.
- Стоимость разметки. Забегу вперёд и скажу, что мы получили огромный объём фотографий за пять дней, потратив на это меньше 100 долларов.
Теперь к делу — расскажу, как мы собирали данные и что из этого вышло.
Грамотно настроить пайплайн
Основное правило краудсорсинга гласит: большую задачу нужно декомпозировать — то есть разбить на множество маленьких подзадач. Мы прикинули, из каких этапов будет состоять проект, и разделили его на четыре части.
1. Сбор видео
Первым делом мы попросили толокеров снять ноги на видео и показали видеопример: лучше один раз увидеть, чем сто раз услышать. В первой инструкции мы клали на пол любую пластиковую карточку, предполагая, что карточка в кадре поможет улучшить точность построения 3D-скана. Но прироста в точности это не дало, так что мы отмели эту идею, и финальные условия стали такими:
- продолжительность записи — 20–60 секунд (нам нужно около 30 секунд видео от одного толокера, чтобы на выходе получить 30–50 различных кадров от каждого);
- камеру навести на ноги без носков и обуви, с подвёрнутыми до икр штанами;
- помещение не должно быть слишком тёмным;
- видео снять с самых разных ракурсов: мы просили менять высоту, и угол съёмки.
Вот как выглядела инструкция:

Она неспроста такая подробная: чем чётче вы всё распишете, тем точнее разметчики выполнят задание и тем умнее будет нейросеть.
За 2 дня и 17 часов мы собрали 2472 ролика. Чтобы видеозаписи были как можно разнообразнее, мы установили ограничение на количество заданий. Один толокер мог прислать нам только одно видео.
Задание было с отложенной приёмкой: мы отправляли полученные видео на проверку следующей группе исполнителей и спрашивали, верно ли записан ролик. После этого первой группе исполнителей выплачивали деньги — только тем, чьи ролики были приняты.
2. Проверка видео и фото
На этом этапе исполнители определяли, соответствует ли техническому заданию присланный первыми толокерами контент. Но сначала пользователи проходили обучение, и доступ открывался только тем, кто хорошо выполнял задания. Работало это так: мы просили проверить 30 видео (для каждого из которых знали правильный ответ) и считали число правильных ответов у исполнителя. Если точность была больше 85%, мы допускали его к основному заданию.
Вот как выглядела инструкция на этом этапе:

Обратите внимание на первый абзац: очень важно говорить исполнителям, для чего они работают. Понимая, что их труд уходит не впустую, они активнее включаются и качественнее выполняют задания
Также было важно настроить правила контроля качества: от них зависит и качество датасета, и мотивация исполнителей — можно выявлять и блокировать тех, кто плохо выполняет задания, и поощрять тех, кто исправно работает. Чтобы поощрять хороших исполнителей, мы платили больше денег за задания, которые были выполнены более качественно, а чтобы отсеивать недобросовестных исполнителей, использовали ханипоты и блокировку за слишком быстрые ответы. Ханипоты — это «проверочные» задания, для которых мы заранее знаем правильный ответ. Внешне они не отличаются от остальных, но по ответам на эти задания можно определить, насколько хорошо толокер выполняет задачу.
Из 2472 видео мы приняли 1507. За каждый принятый ролик мы заплатили 0,025 доллара, ещё 7,41 — за проверку всех роликов. То есть всего к этому этапу проекта мы потратили 45 долларов. На мой взгляд, это очень круто.
3. Раскадровка видео
Следующий этап — разбивка видео на кадры. Мы сделали это автоматически, не привлекая толокеров. Я использовал программу FFmpeg, которая очень быстро работает с картинками и видео. В процессе участвовал каждый десятый кадр, и из 1507 видео мы собрали 156 576 кадров, получив в три раза больше изображений, чем планировали.
Но для качественного обучения нейронной сети нужен вариативный датасет: в нём должны быть непохожие друг на друга картинки. В нашем случае в датасете получилось много кадров-близнецов, оставив которые, мы не добились бы повышения качества, а только потратили много денег на разметку. Поэтому я удалил их автоматически, используя библиотеку ImageHash. Для каждого изображения я получил хэш — набор чисел, который характеризует изображение. Алгоритм составления хэша так устроен, что похожие картинки будут иметь похожий хэш, а разные — разный. Кластеризовав хэши, я нашёл все похожие изображения и оставил только по одному кадру в каждом кластере. На следующем этапе толокеры проверяли 57 тысяч кадров.
4. Проверка кадров — финальный этап в Толоке
Завершающий этап работы в Толоке — проверка кадров. Иногда во время съёмки может дёрнуться рука, и на видео появляются размытые кадры. Мы удалили размытые и отобрали чёткие изображения, на которых видна стопа человека. Вот как это выглядело:

Весь процесс в Толоке я менеджерил в одиночку. Вначале проект довольно трудно настроить (написать интерфейс, инструкции, выстроить контроль качества), но, когда он налажен, всё идёт само по себе и не требует постоянного внимания.
5. Бонус: досбор контента на Amazon Mechanical Turk
На тот момент в Толоке работали в основном жители России и стран СНГ, и мы получали фото ног с достаточно светлой кожей. Нам же хотелось, чтобы нейронная сеть могла работать в том числе и на более смуглой коже. Сейчас такой проблемы уже нет — в Толоке появились исполнители из Индии и Африки, но тогда нам пришлось собирать другие оттенки через платформу Amazon Mechanical Turk.
Мы создали одно задание, в котором просили людей заснять свои ноги, загрузить видео на файлообменник и прислать нам ссылку. Задание было с отложенной приёмкой, проверкой занимался наш стажёр.
Если сравнивать цены, стоимость одного видео в Amazon была выше, чем в Толоке — 0,1 доллара. Что касается качества — некоторые исполнители, как и в Толоке, присылали неправильные видео, но мы их отклоняли и не платили за эти задания.
Оглянуться и сделать выводы
Вот наши результаты:
- собрали: 156 576 кадров;
- применили в деле: 50 994 изображения;
- потратили времени: 5 дней;
- потратили денег: 75 долларов.
Мы боялись, что в Толоке никто не захочет выполнять нашу странную задачу. Но к счастью, этот страх не оправдался, и мы получили то, за чем пришли. Мы переживали, что толокеры будут халтурить и неправильно выполнять задания, но с помощью инструментов контроля качества нам удалось сделать так, чтобы люди присылали то, что нужно. И самое главное — мы собрали необходимые данные меньше чем за неделю!
А на днях мы наконец закончили разработку и выпустили приложение в свет. Но это уже совсем другая история.

4К открытий4К показов

Полиморфизм — один из основных принципов ООП: что это такое, в каких случаях используется, а также наглядный пример полиморфизма в ООП.

Что общего между сторис в соцсетях и интересной презентацией отчета руководству? Разобрали на примере технику «Бинг — бэнг — бонго»

Какие у российской IT-сферы есть плюсы и минусы, как меняется ситуация, какие преимущества стоит ценить, а с какими недостатками приходится мириться.

Узнайте, приятнее ли с вами работать, чем с Линусом Торвальдом — ужасным скандалистом, который постоянно ссорится с коллегами.