Ищем свободное парковочное место с Python и глубоким обучением

В городах остро встаёт проблема нехватки парковочных мест. В этой статье мы напишем на Python программу, которая будет сообщать о наличии свободных мест.

Рассказывает Адам Гейтджи, разработчик в LinkedIn Learning
Я живу в прекрасном городе. Но, как и во многих других, поиск парковочного места вечно превращается в испытание. Свободные места быстро занимают, и даже если у вас есть своё собственное, друзьям будет сложно к вам заехать, ведь им будет негде припарковаться.
Поэтому я решил направить камеру в окно и использовать глубокое обучение, чтобы мой компьютер сообщал мне, когда освободится место:
Это может звучать сложно, но на самом деле написать рабочий прототип с глубоким обучением — быстро и легко. Все нужные составляющие уже есть — нужно всего лишь знать, где их найти и как собрать воедино.
Поэтому давайте немного развлечёмся и напишем точную систему уведомлений о свободной парковке с помощью Python и глубокого обучения!
Смотрите также:
Декомпозируем задачу
Когда у нас есть сложная задача, которую мы хотим решить с помощью машинного обучения, первым шагом нужно разбить её на последовательность простых задач. Затем мы можем использовать различные инструменты для решения каждой из них. Объединив несколько простых решений в конвейер, мы получим систему, которая способна на нечто сложное.
Вот как я разбил свою задачу:

На вход конвейера поступает видеопоток с веб-камеры, направленной в окно:

Через конвейер мы будем передавать каждый кадр видео, по одному за раз.
Первым шагом нужно распознать все возможные парковочные места на кадре. Очевидно, что прежде чем мы сможем искать незанятые места, нам нужно понять, в каких частях изображения находится парковка.
Затем на каждом кадре нужно найти все машины. Это позволит нам отслеживать движение каждой машины от кадра к кадру.
Третьим шагом нужно определить, какие места заняты машинами, а какие — нет. Для этого нужно совместить результаты первых двух шагов.
Наконец, программа должна прислать оповещение, когда освободится парковочное место. Это будет определяться за счёт изменений в расположении машин между кадрами видео.
Каждый из этих этапов можно пройти разными способами с помощью разных технологий. Нет единственного правильного или неправильного способа составить этот конвейер, у разных подходов будут свои преимущества и недостатки. Разберёмся с каждым шагом подробнее.
Распознаём парковочные места
Вот что видит наша камера:

Нам нужно как-то просканировать это изображение и получить список мест, где можно припарковаться. Как-то так:

Решением «в лоб» было бы просто захардкодить местоположения всех парковочных мест вручную вместо автоматического распознавания. Но в таком случае, если мы переместим камеру или захотим искать парковочные места на другой улице, нам придётся проделывать всю процедуру заново. Звучит так себе, поэтому поищем автоматический способ распознавания парковочных мест.
Как вариант, можно искать на изображении паркометры и предположить, что рядом с каждым из них есть парковочное место:

Однако с этим подходом не всё так гладко. Во-первых, не у каждого парковочного места есть паркометр, да и вообще, нам больше интересен поиск парковочных мест, за которые не надо платить. Во-вторых, местоположение паркометра ничего не говорит нам о том, где находится парковочное место, а всего лишь позволяет сделать предположение.
Другая идея заключается в создании модели распознавания объектов, которая ищет метки парковочного места, нарисованные на дороге:

Но и этот подход — так себе. Во-первых, в моём городе все такие метки очень маленькие и трудноразличимые на расстоянии, поэтому их будет сложно обнаружить с помощью компьютера. Во-вторых, на улице полно всяких других линий и меток. Будет сложно отделить парковочные метки от разделителей полос и пешеходных переходов.
Когда вы сталкиваетесь с проблемой, которая на первый взгляд кажется сложной, потратьте несколько минут на поиск другого подхода к решению задачи, который поможет обойти некоторые технические проблемы. Что вообще есть парковочное место? Это всего лишь место, на которое на долгое время паркуют машину. Возможно, нам вовсе и не нужно распознавать парковочные места. Почему бы нам просто не распознавать машины, которые долгое время стоят на месте, и не делать предположение, что они стоят на парковочном месте?
Другими словами, парковочные места расположены там, где подолгу стоят машины:

Таким образом, если мы сможем распознать машины и выяснить, которые из них не двигаются между кадрами, мы сможем предположить, где находятся парковочные места. Проще простого — переходим к распознаванию машин!
Распознаём машины
Распознавание машин на кадре видео является классической задачей распознавания объектов. Существует множество подходов на основе машинного обучения, которые мы могли бы использовать для распознавания. Вот некоторые из них в порядке от «старой школы» к «новой школе»:
- Можно обучить детектор на основе HOG (Histogram of Oriented Gradients, гистограммы направленных градиентов) и пройтись им по всему изображению, чтобы найти все машины. Этот старый подход, не использующий глубокое обучение, работает относительно быстро, но не очень хорошо справляется с машинами, расположенными по-разному.
- Можно обучить детектор на основе CNN (Convolutional Neural Network, свёрточная нейронная сеть) и пройтись им по всему изображению, пока не найдём все машины. Этот подход работает точно, но не так эффективно, так как нам нужно просканировать изображение несколько раз с помощью CNN, чтобы найти все машины. И хотя так мы сможем найти машины, расположенные по-разному, нам потребуется гораздо больше обучающих данных, чем для HOG-детектора.
- Можно использовать новый подход с глубоким обучением вроде Mask R-CNN, Faster R-CNN или YOLO, который совмещает в себе точность CNN и набор технических хитростей, сильно повышающих скорость распознавания. Такие модели будут работать относительно быстро (на GPU), если у нас есть много данных для обучения модели.
В общем случае нам нужно самое простое решение, которое будет работать как надо и потребует наименьшее количество обучающих данных. Не обязательно, чтобы это был самый новый и быстрый алгоритм. Однако конкретно в нашем случае Mask R-CNN — разумный выбор, несмотря на то, что он довольно новый и быстрый.
Архитектура Mask R-CNN разработана таким образом, что она распознаёт объекты на всём изображении, эффективно тратя ресурсы, и при этом не использует подход скользящего окна. Другими словами, она работает довольно быстро. С современным GPU мы сможем распознавать объекты на видео в высоком разрешении на скорости в несколько кадров в секунду. Для нашего проекта этого должно быть достаточно.
Кроме того, Mask R-CNN даёт много информации о каждом распознанном объекте. Большинство алгоритмов распознавания возвращают только ограничивающую рамку для каждого объекта. Однако Mask R-CNN не только даст нам местоположение каждого объекта, но и его контур (маску):

Для обучения Mask R-CNN нам нужно много изображений объектов, которые мы хотим распознавать. Мы могли бы выйти на улицу, сфотографировать машины и обозначить их на фотографиях, что потребовало бы несколько дней работы. К счастью, машины — одни из тех объектов, которые люди часто хотят распознать, поэтому уже существуют несколько общедоступных датасетов с изображениями машин.
Один из них — популярный датасет COCO (сокращение для Common Objects In Context), в котором есть изображения, аннотированные масками объектов. В этом датасете находится более 12 000 изображений с уже размеченными машинами. Вот пример изображения из датасета:

Такие данные отлично подходят для обучения модели на основе Mask R-CNN.
Но придержите коней, есть новости ещё лучше! Мы не первые, кому захотелось обучить свою модель с помощью датасета COCO — многие люди уже сделали это до нас и поделились своими результатами. Поэтому вместо обучения своей модели мы можем взять готовую, которая уже может распознавать машины. Для нашего проекта мы воспользуемся open-source моделью от Matterport.
Если дать на вход этой модели изображение с камеры, вот что мы получим уже «из коробки»:

Модель распознала не только машины, но и такие объекты, как светофоры и люди. Забавно, что дерево она распознала как комнатное растение.
Для каждого распознанного объекта модель Mask R-CNN возвращает 4 вещи:
- Тип обнаруженного объекта (целое число). Предобученная модель COCO умеет распознавать 80 разных часто встречающихся объектов вроде машин и грузовиков. С их полным списком можно ознакомиться здесь.
- Степень уверенности в результатах распознавания. Чем выше число, тем сильнее модель уверена в правильности распознавания объекта.
- Ограничивающая рамка для объекта в форме XY-координат пикселей на изображении.
- «Маска», которая показывает, какие пиксели внутри ограничивающей рамки являются частью объекта. С помощью данных маски можно найти контур объекта.
Ниже показан код на Python для обнаружения ограничивающей рамки для машин с помощью предобученной модели Mask R-CNN и OpenCV:
После запуска этого скрипта на экране появится изображение с рамкой вокруг каждой обнаруженной машины:

Также в консоль будут выведены координаты каждой машины:
Вот мы и научились распознавать машины на изображении.
Распознаём пустые парковочные места
Мы знаем пиксельные координаты каждой машины. Просматривая несколько последовательных кадров, мы легко можем определить, какие из машин не двигались, и предположить, что там находятся парковочные места. Но как понять, что машина покинула парковку?
Проблема в том, что рамки машин частично перекрывают друг друга:

Поэтому если представить, что каждая рамка представляет парковочное место, то может оказаться, что оно частично занято машиной, когда на самом деле оно пустое. Нам нужно найти способ измерить степень пересечения двух объектов, чтобы искать только «наиболее пустые» рамки.
Мы воспользуемся мерой под названием Intersection Over Union (отношение площади пересечения к сумме площадей) или IoU. IoU можно найти, посчитав количество пикселей, где пересекаются два объекта, и разделить на количество пикселей, занимаемых этими объектами:
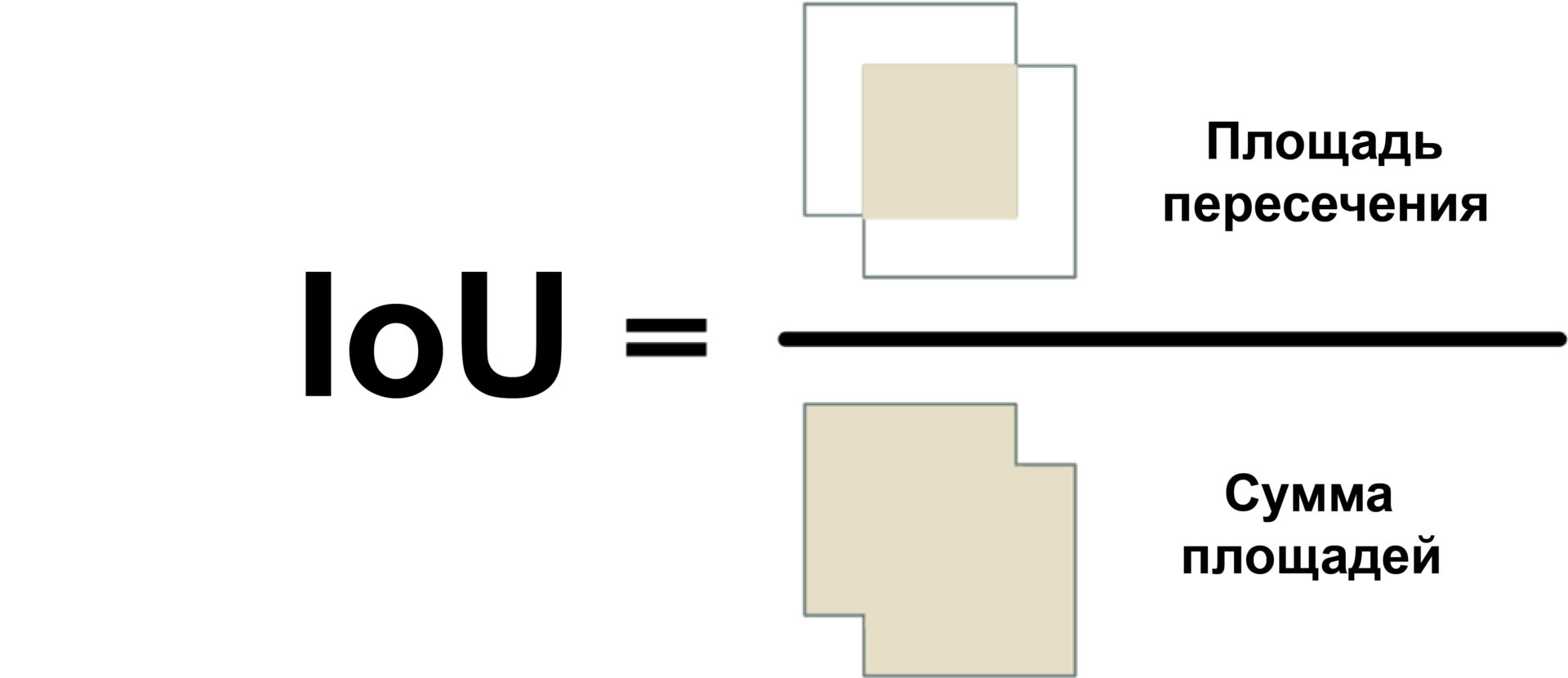
Так мы сможем понять, как сильно ограничивающая рамка машины пересекается с рамкой парковочного места. Это позволит легко определить, свободна ли парковка. Если значение IoU низкое, вроде 0.15, значит, машина занимает малую часть парковочного места. А если оно высокое, вроде 0.6, то это значит, что машина занимает большую часть места и там нельзя припарковаться.
Поскольку IoU используется довольно часто в компьютерном зрении, в соответствующих библиотеках с большой вероятностью есть реализация этой меры. В нашей библиотеке Mask R-CNN она реализована в виде функции mrcnn.utils.compute_overlaps().
Если у нас есть список ограничивающих рамок для парковочных мест, то добавить проверку на наличие машин в этих рамках можно, добавив всего строку-другую кода:
Результат должен выглядеть примерно так:

В этом двумерном массиве каждая строка отражает одну рамку парковочного места. А каждый столбец говорит о том, насколько сильно каждое из мест пересекается с одной из обнаруженных машин. Результат 1.0 означает, что всё место полностью занято машиной, а низкое значение вроде 0.02 говорит о том, что машина немного влезла на место, но на нём ещё можно припарковаться.
Чтобы найти незанятые места, нужно всего лишь проверить каждую строку в этом массиве. Если все числа близки к нулю, то скорее всего место свободно!
Однако имейте в виду, что распознавание объектов не всегда работает идеально с видео в реальном времени. Хоть модель на основе Mask R-CNN довольно точна, время от времени она может пропустить машину-другую в одном кадре видео. Поэтому прежде чем утверждать, что место свободно, нужно убедиться, что оно остаётся таким ещё на протяжении 5–10 следующих кадров видео. Таким образом мы сможем избежать ситуаций, когда система ошибочно помечает место пустым из-за глюка на одном кадре видео. Как только мы убедимся, что место остаётся свободным в течение нескольких кадров, можно отсылать сообщение!
Отправляем SMS
Последняя часть нашего конвейера — отправка SMS-уведомления при появлении свободного парковочного места.
Отправить сообщение из Python очень легко, если использовать Twilio. Twilio — это популярный API, который позволяет отправлять SMS из практически любого языка программирования с помощью всего нескольких строк кода. Конечно, если вы предпочитаете другой сервис, то можете использовать и его. Я никак не связан с Twilio, просто это первое, что приходит на ум.
Чтобы использовать Twilio, зарегистрируйте пробный аккаунт, создайте номер телефона Twilio и получите аутентификационные данные аккаунта. Затем установите клиентскую библиотеку:
После этого используйте следующий код для отправки сообщения:
Чтобы добавить возможность отправки сообщений в наш скрипт, просто скопируйте туда этот код. Однако нужно сделать так, чтобы сообщение не отправлялось на каждом кадре, где видно свободное место. Поэтому у нас будет флаг, который в установленном состоянии не даст отправлять сообщения в течение какого-то времени или пока не освободится другое место.
Складываем всё воедино
Для запуска того кода сначала нужно установить Python 3.6+, Matterport Mask R-CNN и OpenCV.
Я намеренно писал код как можно проще. Например, если он видит на первом кадре машины, то делает вывод, что все они припаркованы. Попробуйте поэкспериментировать с ним и посмотрите, получится ли у вас повысить его надёжность.
Просто изменив идентификаторы объектов, которые ищет модель, вы можете превратить код в нечто совершенно иное. Например, представьте, что вы работаете на горнолыжном курорте. Внеся пару изменений, вы можете превратить этот скрипт в систему, которая автоматически распознаёт сноубордистов, спрыгивающих с рампы, и записывает ролики с классными прыжками. Или, если вы работаете в заповеднике, вы можете создать систему, которая считает зебр. Вы ограничены лишь своим воображением. Экспериментируйте!
А что бы вы хотели распознавать и отслеживать?
Паркоместо
Место в маршрутке
Свежие статьи на Tproger
Новые мемы в /dev/null
Комаров

23К открытий23К показов

Рассказали, какие основные ошибки делает начинающий Python-разработчик, как их можно избежать и на что в целом обращать внимание.

Собрали несколько популярных мобильных приложений для изучения Python и не только и описали их плюсы и минусы.

В этой статье помогаем ускорить ознакомление с основными типами AI и показываем принципы принятия решений по внедрению AI.

Разобрали на примере, как работает Python selenium и настроили бота, который будет отсылать находки в Telegram.