Регулярные выражения: начало работы с RegExp
Объяснение регулярных выражений для новичков на понятных примерах, а также перечень инструментов для удобного составления регекспов.
Что такое регулярные выражения?
Давайте разберёмся, что же собой представляют регулярные выражения. Если вам когда-нибудь приходилось работать с командной строкой, вы, вероятно, использовали маски имён файлов. Например, чтобы удалить все файлы в текущей директории, которые начинаются с буквы “d”, можно написать rm d*.
Регулярные выражения представляют собой похожий, но гораздо более сильный инструмент для поиска строк, проверки их на соответствие какому-либо шаблону и другой подобной работы. Англоязычное название этого инструмента — Regular Expressions или просто RegExp. Строго говоря, регулярные выражения — специальный язык для описания шаблонов строк.
Реализация этого инструмента различается в разных языках программирования, хоть и не сильно. В данной статье мы будем ориентироваться в первую очередь на реализацию Perl Compatible Regular Expressions.
Основы синтаксиса
В первую очередь стоит заметить, что любая строка сама по себе является регулярным выражением. Так, выражению Хаха, очевидно, будет соответствовать строка “Хаха” и только она. Регулярки являются регистрозависимыми, поэтому строка “хаха” (с маленькой буквы) уже не будет соответствовать выражению выше.
Однако уже здесь следует быть аккуратным — как и любой язык, регекспы имеют спецсимволы, которые нужно экранировать. Вот их список: . ^ $ * + ? { } [ ] \ | ( ). Экранирование осуществляется обычным способом — добавлением \ перед спецсимволом.
Набор символов
Предположим, мы хотим найти в тексте все междометия, обозначающие смех. Просто Хаха нам не подойдёт — ведь под него не попадут “Хехе”, “Хохо” и “Хихи”. Да и проблему с регистром первой буквы нужно как-то решить.
Здесь нам на помощь придут наборы — вместо указания конкретного символа, мы можем записать целый список, и если в исследуемой строке на указанном месте будет стоять любой из перечисленных символов, строка будет считаться подходящей. Наборы записываются в квадратных скобках — паттерну [abcd] будет соответствовать любой из символов “a”, “b”, “c” или “d”.
Внутри набора большая часть спецсимволов не нуждается в экранировании, однако использование \ перед ними не будет считаться ошибкой. По прежнему необходимо экранировать символы “\” и “^”, и, желательно, “]” (так, [][] обозначает любой из символов “]” или «[», тогда как [[]х] — исключительно последовательность “[х]”). Необычное на первый взгляд поведение регулярок с символом “]” на самом деле определяется известными правилами, но гораздо легче просто экранировать этот символ, чем их запоминать. Кроме этого, экранировать нужно символ «-», он используется для задания диапазонов (см. ниже).
Если сразу после [ записать символ ^, то набор приобретёт обратный смысл — подходящим будет считаться любой символ кроме указанных. Так, паттерну [^xyz] соответствует любой символ, кроме, собственно, “x”, “y” или “z”.
Итак, применяя данный инструмент к нашему случаю, если мы напишем [Хх][аоие]х[аоие], то каждая из строк “Хаха”, “хехе”, “хихи” и даже “Хохо” будут соответствовать шаблону.
Предопределённые классы символов
Для некоторых наборов, которые используются достаточно часто, существуют специальные шаблоны. Так, для описания любого пробельного символа (пробел, табуляция, перенос строки) используется \s, для цифр — \d, для символов латиницы, цифр и подчёркивания “_” — \w.
Если необходимо описать вообще любой символ, для этого используется точка — .. Если указанные классы написать с заглавной буквы (\S, \D, \W) то они поменяют свой смысл на противоположный — любой непробельный символ, любой символ, который не является цифрой, и любой символ кроме латиницы, цифр или подчёркивания соответственно.
Также с помощью регулярных выражений есть возможность проверить положение строки относительно остального текста. Выражение \b обозначает границу слова, \B — не границу слова, ^ — начало текста, а $ — конец. Так, по паттерну \bJava\b в строке “Java and JavaScript” найдутся первые 4 символа, а по паттерну \bJava\B — символы c 10-го по 13-й (в составе слова “JavaScript”).

Диапазоны
У вас может возникнуть необходимость обозначить набор, в который входят буквы, например, от “б” до “ф”. Вместо того, чтобы писать [бвгдежзиклмнопрстуф] можно воспользоваться механизмом диапазонов и написать [б-ф]. Так, паттерну x[0-8A-F][0-8A-F] соответствует строка “xA6”, но не соответствует “xb9” (во-первых, из-за того, что в диапазоне указаны только заглавные буквы, во-вторых, из-за того, что 9 не входит в промежуток 0-8).
Механизм диапазонов особенно актуален для русского языка, ведь для него нет конструкции, аналогичной \w. Чтобы обозначить все буквы русского алфавита, можно использовать паттерн [а-яА-ЯёЁ]. Обратите внимание, что буква “ё” не включается в общий диапазон букв, и её нужно указывать отдельно.
Квантификаторы
Вернёмся к нашему примеру. Что, если в “смеющемся” междометии будет больше одной гласной между буквами “х”, например “Хаахаааа”? Наша старая регулярка уже не сможет нам помочь. Здесь нам придётся воспользоваться квантификаторами.
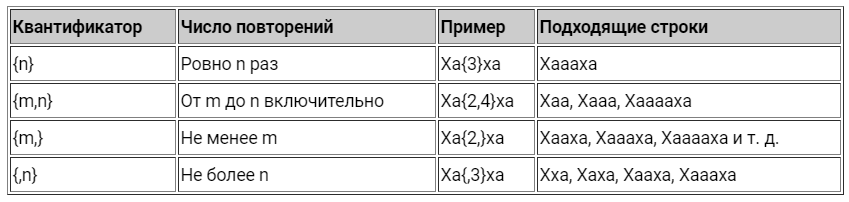
Обратите внимание, что квантификатор применяется только к символу, который стоит перед ним.
Некоторые часто используемые конструкции получили в языке RegEx специальные обозначения:

Таким образом, с помощью квантификаторов мы можем улучшить наш шаблон для междометий до [Хх][аоеи]+х[аоеи]*, и он сможет распознавать строки “Хааха”, “хееееех” и “Хихии”.
Ленивая квантификация
Предположим, перед нами стоит задача — найти все HTML-теги в строке
Очевидное решение <.*> здесь не сработает — оно найдёт всю строку целиком, т.к. она начинается с тега абзаца и им же заканчивается. То есть содержимым тега будет считаться строка
Это происходит из-за того, что по умолчанию квантификатор работают по т.н. жадному алгоритму — старается вернуть как можно более длинную строку, соответствующую условию. Решить проблему можно двумя способами. Первый — использовать выражение <[^>]*>, которое запретит считать содержимым тега правую угловую скобку. Второй — объявить квантификатор не жадным, а ленивым. Делается это с помощью добавления справа к квантификатору символа ?. Т.е. для поиска всех тегов выражение обратится в <.*?>.
Ревнивая квантификация
Иногда для увеличения скорости поиска (особенно в тех случаях, когда строка не соответствует регулярному выражению) можно использовать запрет алгоритму возвращаться к предыдущим шагам поиска для того, чтобы найти возможные соответствия для оставшейся части RegExp. Это называется ревнивой квантификацией. Квантификатор делается ревнивым с помощью добавления к нему справа символа +. Ещё одно применение ревнивой квантификации — исключение нежелательных совпадений. Так, паттерну ab*+a в строке “ababa” будут соответствовать только первые три символа, но не символы с третьего по пятый, т.к. символ “a”, который стоит на третьей позиции, уже был использован для первого результата.
Чуть больше о жадном, сверхжадном и ленивом режимах квантификации вы сможете узнать из статьи о регулярных выражениях в Java.
Скобочные группы
Для нашего шаблона “смеющегося” междометия осталась самая малость — учесть, что буква “х” может встречаться более одного раза, например, “Хахахахааахахооо”, а может и вовсе заканчиваться на букве “х”. Вероятно, здесь нужно применить квантификатор для группы [аиое]+х, но если мы просто напишем [аиое]х+, то квантификатор + будет относиться только к символу “х”, а не ко всему выражению. Чтобы это исправить, выражение нужно взять в круглые скобки: ([аиое]х)+.
Таким образом, наше выражение превращается в [Хх]([аиое]х?)+ — сначала идёт заглавная или строчная “х”, а потом произвольное ненулевое количество гласных, которые (возможно, но не обязательно) перемежаются одиночными строчными “х”. Однако это выражение решает проблему лишь частично — под это выражение попадут и такие строки, как, например, “хихахех” — кто-то может быть так и смеётся, но допущение весьма сомнительное. Очевидно, мы можем использовать набор из всех гласных лишь единожды, а потом должны как-то опираться на результат первого поиска. Но как?…
Запоминание результата поиска по группе
Оказывается, результат поиска по скобочной группе записывается в отдельную ячейку памяти, доступ к которой доступен для использования в последующих частях регэкспа. Возвращаясь к задаче с поиском HTML-тегов на странице, нам может понадобиться не только найти теги, но и узнать их название. В этом нам может помочь регулярное выражение <(.*?)>.
Результат поиска по всему регексу: “”, “”, “”, “”, “”, “”.
Результат поиска по первой группе: “p”, “b”, “/b”, “i”, “/i”, “/i”, “/p”.
На результат поиска по группе можно ссылаться с помощью выражения \n, где n — цифра от 1 до 9. Например выражению (\w)(\w)\1\2 соответствуют строки “aaaa”, “abab”, но не соответствует “aabb”.
Если выражение берётся в скобки только для применения к ней квантификатора (не планируется запоминать результат поиска по этой группе), то сразу после первой скобки стоит добавить ?:, например (?:[abcd]+\w).
С использованием этого механизма мы можем переписать наше выражение к виду [Хх]([аоие])х?(?:\1х?)*.

Перечисление
Чтобы проверить, удовлетворяет ли строка хотя бы одному из шаблонов, можно воспользоваться аналогом булевого оператора OR, который записывается с помощью символа |. Так, под шаблон Анна|Одиночество попадают строки “Анна” и “Одиночество” соответственно. Особенно удобно использовать перечисления внутри скобочных групп. Так, например (?:a|b|c|d) полностью эквивалентно [abcd] (в данном случае второй вариант предпочтительнее в силу производительности и читаемости).
С помощью этого оператора мы сможем добавить к нашему регулярному выражению для поиска междометий возможность распознавать смех вида “Ахахаах” — единственной усмешке, которая начинается с гласной: [Хх]([аоие])х?(?:\1х?)*|[Аа]х?(?:ах?)+
Полезные сервисы
Потренироваться и/или проверить регулярное выражение на каком-либо тексте без написания кода можно с помощью таких сервисов, как RegExr, Regexpal или Regex101. Последний вдобавок приводит краткие пояснения к тому, как работает регулярка.
Разобраться, как работает регулярное выражение, которое попало к вам в руки, можно с помощью сервиса Regexper — он умеет строить понятные диаграмы по регуляркам.
RegExp Builder — визуальный конструктор функций JavaScript для работы с регулярными выражениями.
Больше инструментов можно найти в нашей подборке.
Задания для закрепления
Найдите время
Время имеет формат часы:минуты. И часы, и минуты состоят из двух цифр, пример: 09:00. Напишите RegEx выражение для поиска времени в строке: “Завтрак в 09:00”. Учтите, что “37:98” — некорректное время.
Решение
Java[^script]
Найдет ли регулярка Java[^script] что-нибудь в строке Java? А в строке JavaScript?
Решение
Ответы: нет, да.
- В строке Java он ничего не найдёт, так как исключающие квадратные скобки в Java[^…] означают «один символ, кроме указанных». А после «Java» – конец строки, символов больше нет.
- Да, найдёт. Поскольку регэксп регистрозависим, то под [^script] вполне подходит символ “S”.
Цвет
Напишите регулярное выражение для поиска HTML-цвета, заданного как #ABCDEF, то есть # и содержит затем 6 шестнадцатеричных символов.
Решение
Итак, нужно написать выражение для описания цвета, который начинается с «#», за которым следуют 6 шестнадцатеричных символов. Шестнадцатеричный символ можно описать с помощью [0-9a-fA-F]. Для его шестикратного повторения мы будем использовать квантификатор {6}.
Разобрать арифметическое выражение
Арифметическое выражение состоит из двух чисел и операции между ними, например:
- 1 + 2
- 1.2 *3.4
- -3/ -6
- -2-2
Список операций: “+”, «-», “*” и “/”.
Также могут присутствовать пробелы вокруг оператора и чисел.
Напишите регулярку, которая найдёт, как всё арифметическое действие, так и (через группы) два операнда.
Решение
Регулярное выражение для числа, возможно, дробного и отрицательного: -?\d+(\.\d+)?.
Оператор – это [+*/\-]. Заметим, что дефис мы экранируем. Нам нужно число, затем оператор, затем число, и необязательные пробелы между ними. Чтобы получить результат в требуемом формате, добавим ?: к группам, поиск по которым нам не интересен (отдельно дробные части), а операнды наоборот заключим в скобки. В итоге:
Кроссворды из регулярных выражений
Такие кроссворды вы можете найти у нас.
Удачи и помните — не всегда задачу стоит решать именно с помощью регекспов (“У программиста была проблема, которую он начал решать регэкспами. Теперь у него две проблемы”). Иногда лучше, например, написать развёрнутый автомат конечных состояний.
















