


5 open-source моделей, в которые можно вписаться до конца 2025 года — Qwen, Gemma, DeepSeek, Mistral, OpenAI


Пока одни ждут выхода коммерческих супермоделей от OpenAI и Anthropic, другие запускают Mistral или Gemma на одном ноуте и получают рабочий прототип. Open-source экосистема стала настолько сильной, что закрытые гиганты больше не единственный вариант. Рассказываем, кто из открытых игроков принесёт вашему проекту реальную пользу к концу года.
1К открытий4К показов

Почему open-source всё ещё рулит в эпоху закрытых гигантов
Open-source — это свобода и гибкость, но с оговорками: можно сделать круто, но придётся попотеть. Понадобится мощное железо, приличная инфраструктура, деньги на запуск и терпение при медленном инференсе. Инференс на GPU, хранение моделей и логов, сети и энергопотребление — всё это постепенно съедает бюджет.
ML-инженер Devansh рассчитал: умеренное внутреннее приложение — $125–190k в год, клиентский SaaS-фичер — $500–820k, а ядро продукта для предприятия — $6–12 млн и выше. И это без учёта головной боли с багами, несовместимостями и лицензиями, которые иногда «условно открытые».

Но именно поэтому и выбирают open-source: это возможность полностью контролировать стек, и не зависеть от прихотей гигантов, которые могут поднять цены на API или внезапно изменить модель. Вы можете проснуться и обнаружить, что закрытая модель стала работать хуже, чем раньше. С открытой моделью можно зафиксировать версию, докатить дообученные веса и быть уверенным, что поведение не сломается из-за апдейта.
На что обращать внимание при выборе open-source модели
Тут никак без экспериментов — разные модели по-разному ведут себя на одних и тех же задачах. Лидерборды для русского языка, например llmarena.ru — слабые и редко обновляются. На глобальных площадках различия не так заметны. Например, на lmsys можно тестировать модели side-by-side. В лидербордах ArtificalAnalysis видны OS LLM и есть рейтинги по генерации изображений и видео.
В поисках новых open-source моделей я часто заглядываю на VseGPT. Это не рейтинг, а скорее каталог, где авторы сами чистят неудачные решения. Там можно отследить, какие новинки появляются и приживаются, а заодно сравнить цену за токен. Как раз там я нашёл топовую для русского языка мёрдж-модель sainemo-remix-i1 для проекта NetTyan. И не забываем про «народные» тюны и мёрджи моделей — в архивном лидерборде OS LLM верхние строчки занимали именно они.
Пятёрка лучших
Выбор лучших моделей не сводится только к лидербордам. Рейтинги дают лишь срез производительности в конкретных тестах и на определённый момент времени, а разработчики иногда читерят, специально подгоняя модели под тесты. Мы собрали пятёрку, ориентируясь на опыт экспертов коммьюнити Reddit и обзоры пользователей. Получился неофициальный топ — набор моделей, которые зарекомендовали себя надёжными, интересными и востребованными в коммьюнити.
1. Qwen2.5-Omni
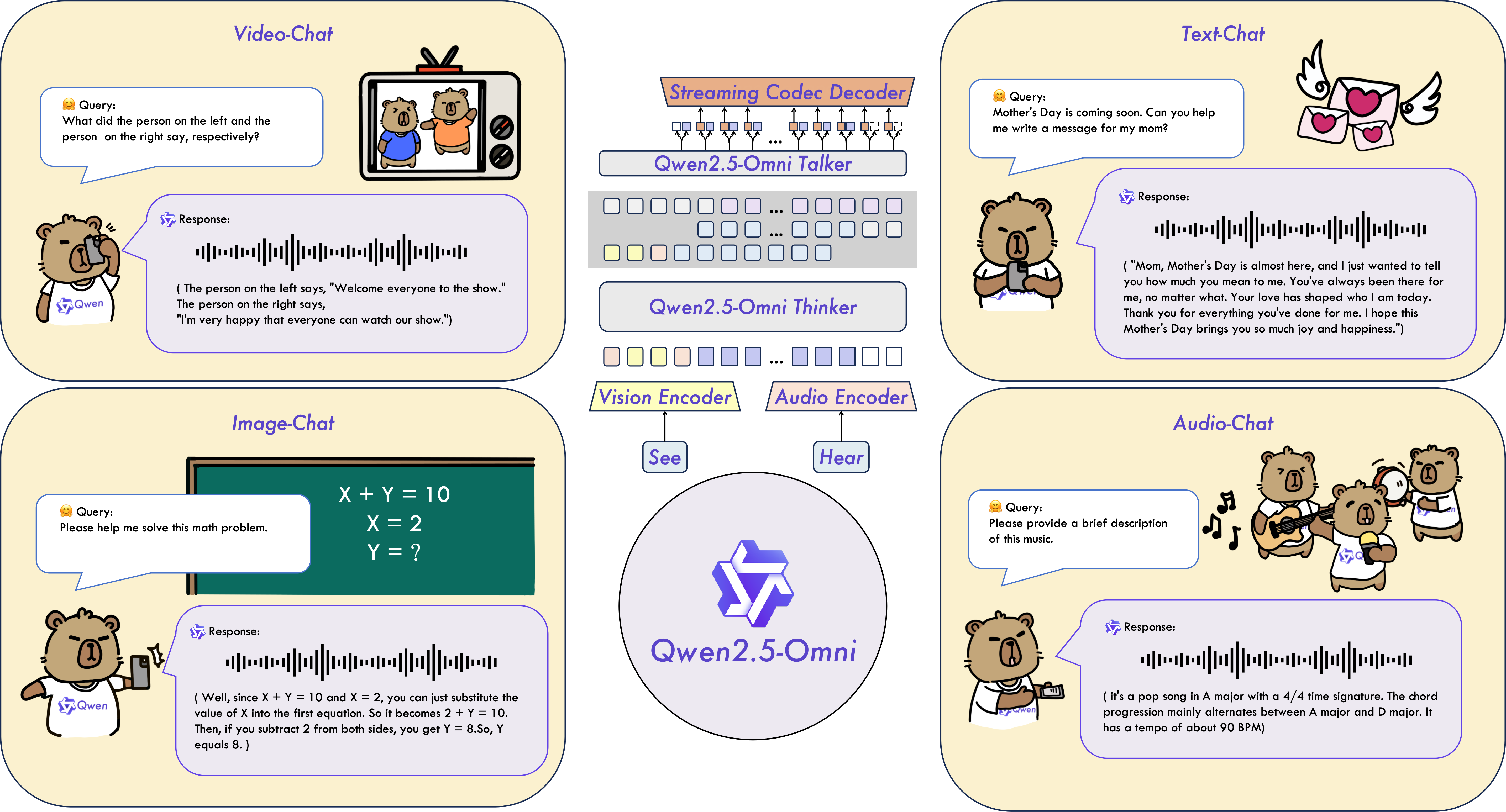
Техрепорт | GitHub | Demo | Hugging Face | Блогпост
Это мультимодальный комбайн от китайской Alibaba, который обрабатывает сразу несколько типов данных: текст, изображения, аудио и видео. В основе собственная потоковая архитектура Thinker–Talker: Thinker обрабатывает всё, что ему скармливают: текст, картинку, звук или даже кусок видео. Talker начинает говорить или печатать ответ, не дожидаясь конца обработки. Для разработчиков меньше контекстных костылей и API-склеек — модель уже «понимает мир» комплексно. У Qwen 2.5 Omni очень быстрое мультимодальное взаимодействие в реальном времени. При этом 3B-версию можно запустить на MacBook Pro.
Минусы тоже есть. Запуск модели может стать головной болью: основная загвоздка — новая архитектура для обработки нескольких модальностей, под которую нужно адаптировать квантование и оптимизацию. В голосовом режиме модель прожорлива до безобразия: пользователи Reddit жалуются, что даже 24 ГБ VRAM может не хватить. Если работать с видео, счёт идёт на десятки гигабайт: около 42 ГБ на полминуты ролика и больше 60 ГБ на минутный кусок.
Кроме того, входной сигнал должен быть хорошего качества, без посторонних звуков и фоновой болтовни. Ещё одна проблема в том, что универсальность Omni часто оборачивается компромиссами: специализированные модели обучены под конкретные задачи, а универсалы – на «всё понемногу». Если нужна чисто обработка изображений или только распознавание речи, лучше взять другую узкопрофильную модель.
2. Gemma 3
Техрепорт | GitHub | Hugging Face | Блогпост
Gemma 3 — это швейцарский нож для разработчика от Google. Лёгкая, мультимодальная: понимает текст, картинки и видео. Модель идёт в пяти размерах: от карманной 270M и 1B для небольших приложений до 27B, которая тянет серьёзные сценарии.
Оптимизация снижает нагрузку на память — даже 27B можно запускать на RTX 3090. Поддержка больше 140 языков делает её универсальной для глобальных проектов. Большие версии умеют работать с контекстом до 128K токенов, давая проглотить гигантские тексты за один запрос, а маленькие модели держат до 32K токенов.
Модель получила много положительных отзывов за компактность и эффективность, особенно версии 1B и 4B, которые можно запускать на слабом железе. Пользователи отмечают, что 27B — креативна, сильна в языковых задачах, хорошо структурирует информацию и подходит для RAG-сценариев. Её можно использовать как базу для fine-tuning: взять маленькую модель и подогнать под свой проект, например, сделать чат-бота или собственного мини-ассистента.
Но есть и ограничения. Малые модели почти не знают фактов и не заменят энциклопедию, иногда фантазируют или дают слишком обобщённые ответы. Математика и кодинг у них слабые, возможны ошибки в сложных задачах. Версии для vision нормально работают только с чистыми изображениями, с текстом на картинках — проблемы.
У Gemma 3 сейчас серьёзный апгрейд — новая Gemma 3n. У неё «матрёшечная» архитектура и три модальности — текст, аудио и изображения. На самом деле их даже четыре: если кинуть несколько кадров или сделать раскадровку из одной картинки, можно работать с low-frame видео. Но Gemma 3n E4B всё же уступает большим моделям Gemma 3 12b и 27b. Но она намного легче и её проще запускать локально. При этом 3n E4B уже обгоняет Gemma 3 4b.
3. DeepSeek V3
Техрепорт | GitHub | Demo (chat) | Hugging Face
DeepSeek V3 выделяется среди open-source моделей из-за открытого исходного кода и лицензии MIT, благодаря которой она подходит для коммерческих проектов. В версии 0324 модель стала «человечнее» и выдаёт на 30% больше токенов. Это дороже, но некоторые считают, что оправданно, если нужно кодить или выполнять сложные логические задачи.
Минусы есть: локальная эксплуатация тяжёлая, и без супероптимизированных библиотек придётся мириться с очень медленной генерацией.
В августе была выпущена версия DeepSeek V3.1 с улучшенной производительностью и расширением контекста до 128K токенов. Но пользователи заметили падение креативности: сторителлинги и юмористические зарисовки стали шаблонными и предсказуемыми.
4. Линейка Mistral
Линейка Mistral — целый набор решений для фанатов open-source. Mistral делает ставку на компактные модельки для локального запуска и мультимодальные эксперименты — Pixtral. Mistral NeMo — мультиязычный тяжеловес с контекстом до 128k токенов, разработана совместно с NVIDIA и идеальна для сложных текстовых задач. Mistral Small 3 — компактная текстовая модель для большинства задач генеративного ИИ, оптимизированная для локального запуска с контекстом 32k токенов и возможностью тонкой настройки.
Стоит обратить внимание и на Devstral Small 1 — текстовый помощник для кода (24B), умеет работать с репозиториями и редактировать несколько файлов сразу. На бенчмарке SWE-Bench Verified с 500 реальными проблемами из GitHub, модель набирает 46,8%, обгоняя ближайших конкурентов и даже некоторые крупные закрытые модели вроде GPT-4.1-mini.
5. GPT-OSS
Техрепорт | GitHub | Hugging Face | Блогпост
В августе 2025 года OpenAI выпустили две open-source языковые модели. Это первый серьёзный релиз от OpenAI с открытыми весами после GPT-2. Вариантов два: большой 120b (почти o4-mini, но в open source) и компактный 20b для локалки.
Маленькая модель сопоставима с o3-mini, работает на 16 ГБ VRAM, то есть её можно запустить на хорошем ноуте или небольшом сервере без ускорителей. Обе модели умеют рассуждать, решать математику и вызывать функции. Отлично подходят для кастомных ассистентов и быстрых прототипов без дорогих API.
Мнения по GPT-OSS сильно разнятся: кто-то хвалит большую версию за перспективность, а кто-то разочарован версией 20B. Многие отмечают, что модель вроде бы умная на первый взгляд, но в кодинге может подводить. Так что для серьёзного кода или сложных рассуждений пока лучше брать что-то более продвинутое.
Что дальше: какой будет следующая гонка в open-source?
На горизонте две тенденции, которые могут изменить рынок: мультимодальность и компактные модели. Чем больше параметров — тем умнее модель. Маленькие модели очень важны, потому что инженеры часто «упираются» в кривую размера. Если делать компактные и оптимизированные модели, их легче встраивать в другие инструменты и делать мерджи.
Модальности могут быть не только в способностях понимания разных типов данных: есть гибридные архитектуры MLLM, которые генерируют не только текст, но и изображения, звуки или даже видео. Модели, которые общаются визуально — совершенно новый уровень. Примеры таких решений: Omni-gen2, где генератор совмещён с «пониматором» изображений и старый JarvisArt. Агент может не просто создавать картинку, но и редактировать её, отвечать по ней текстом и улучшать результат, как это делает человек в процессе экспериментов.
Не менее важны и фреймворки, на которых работают эти модели. В тренде — направление computer-use, когда модели помогают управлять интерфейсами и взаимодействовать с элементами экрана. В этом сегменте стоит обратить внимание на UI-TARS 2 и InternVL3, которые хорошо работают с визуалом.
Шпаргалка по open-source LLM
- LM Arena – сравнение LLM, бенчмарки, сравнение side-by-side.
- ArtificalAnalysis OS LLM — лидерборд.
- VseGPT – агрегатор LLM, инференс-платформа для запуска моделей от разных провайдеров.
- Design Arena — топ по производительности, по работе с кодом, видео, изображением.
- Reddit: LocalLLaMA, Hugging Face Forums — коммьюнити оупенсорс-юзеров.
- Видео: Гайд по Gemma 3 Gemma 3 Explained: Google’s Open-Source AI Beast (Full Guide).
- Видео: Как установить и запустить DeepSeek-V3 How to Install and Run DeepSeek-V3 Model Locally on GPU or CPU.
- Видео: Как запустить GPT-OSS локально OpenAI Open Source Models Are Here - Run GPT-OSS Locally on your computer.

1К открытий4К показов

Как сделать на HTML и CSS. Показываем, какими навыками нужно обладать для создания сайтов. Рассматриваем пошаговую инструкцию и основные нюансы ✔ Tproger
Автор YouTube-канала Тормари Лул научил ChatGPT решать домашнее задание. 3D-принтер записывает решения ручкой и рукописным текстом.

ZDNET назвал 5 самых красивых Linux-дистрибутивов: KDE Neon, EndeavourOS, Pop!_OS, ElysiaOS и BigLinux. Plasma правит бал в Linux

Разработчик саботировал IT-инфраструктуру компании после понижения, заложив вредоносный код. Суд признал его виновным, ему грозит до 10 лет тюрьмы