


Быстрый старт StarRocks Lakehouse — Apache Iceberg
Практический гид по StarRocks + Apache Iceberg: развёртывание MinIO и Spark через Docker Compose, создание Iceberg REST Catalog, импорт Parquet и быстрые SQL‑запросы по таблицам без миграции данных.
163 открытий2К показов

Предисловие
Это краткое руководство поможет быстро разобраться с Lakehouse‑архитектурой (лейкхаус): ключевые особенности, сильные стороны, типовые сценарии, а также как быстро собрать решение на базе StarRocks. В конце вы найдёте практические шаги и реальные кейсы использования StarRocks Lakehouse.
Ссылки на официальные материалы:
- Подробный туториал StarRocks + Iceberg: https://docs.starrocks.io/en/docs/quick_start/iceberg/
- Iceberg Spark Quickstart: https://iceberg.apache.org/spark-quickstart/
- Видео‑демо: https://www.bilibili.com/video/BV1ET42167TY/?spm_id_from=333.999.0.0&vd_source=1cb452610138142d1300dd37a6162a88
Введение в Apache Iceberg
Apache Iceberg — открытый табличный формат, созданный для масштабных и сложных наборов данных (до ПБ и выше). Изначально разработан в Netflix для управления большим числом таблиц, открыт в инкубаторе Apache в 2018 году и получил статус верхнеуровневого проекта в 2020 году.
Iceberg располагается между вычислительными движками (например, Apache Flink и Apache Spark) и форматами хранения (ORC, Parquet, Avro), выступая прослойкой, которая абстрагирует сложность низкоуровневых форматов и предоставляет унифицированные табличные семантики. Такой дизайн обеспечивает гибкость операций и управления схемой в разных средах без привязки к конкретному движку хранения, с масштабированием в HDFS, S3, OSS и т. п.
Архитектура и ключевые компоненты
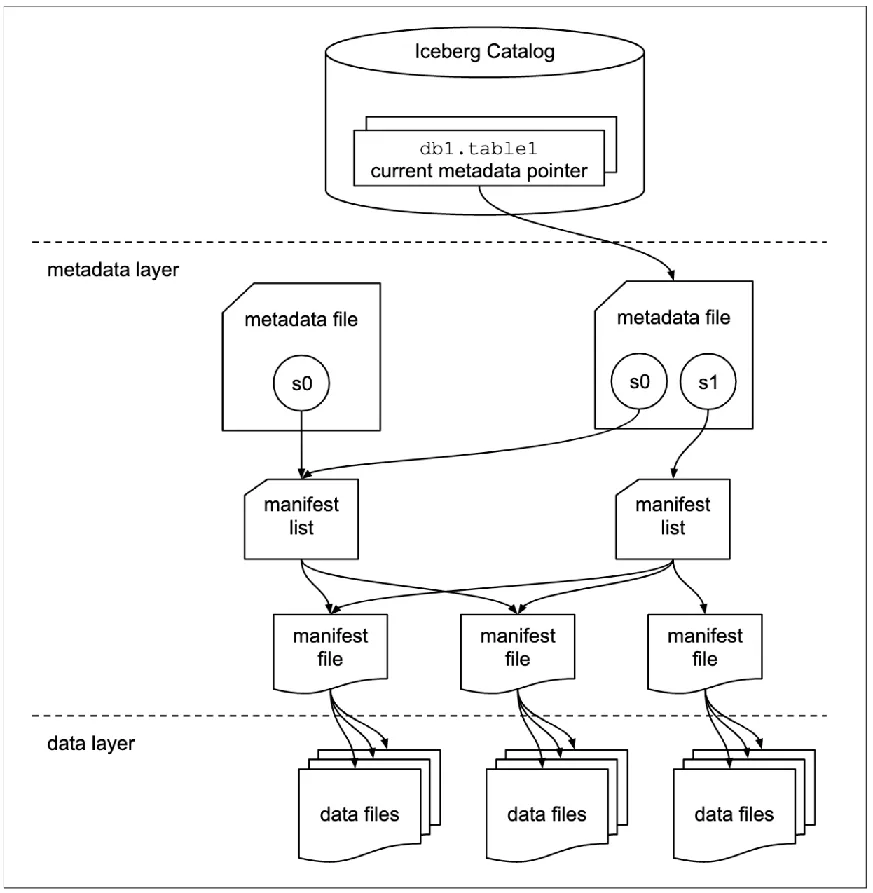
Архитектура Iceberg состоит из трёх слоёв:
- Слой данных: фактические файлы данных (Parquet, ORC и др.).
- Слой метаданных: многоуровневая структура со схемой таблицы и индексами файлов данных.
- Слой каталога (Catalog): указатели на местоположения файлов метаданных; доступны реализации вроде HadoopCatalog и HiveCatalog.
Управление метаданными включает три ключевых сущности:
- Файл метаданных (Metadata File): хранит текущую версию метаданных, включая все снимки.
- Снимок (Snapshot): отражает состояние таблицы после конкретной операции (коммита); новый коммит — новый снимок.
- Манифест (Manifest): перечисляет файлы данных, связанные со снимком, задаёт целостное представление организации данных и ускоряет поиск/модификации.
Цель Iceberg — отслеживать эволюцию таблицы во времени с помощью снимков, которые фиксируют полный набор файлов данных на произвольный момент. Каждый апдейт создаёт новый снимок, обеспечивая согласованность и упрощая историческую аналитику и инкрементальное чтение.
Ключевые возможности
- Скрытое партиционирование (Hidden partitioning): автоматическое разбиение по времени и другим функциям без необходимости знать детали партиций.
- Эволюция схемы (Schema evolution): безопасные изменения структуры таблицы без переписывания данных, с историей изменений.
- Эволюция партиционирования (Partition evolution): смена стратегии партиционирования без воздействия на исторические данные; новые данные следуют новой стратегии.
- Многоверсионный контроль (MVCC): записи не блокируют чтения; управление через Manifest‑файлы.
- ACID‑транзакции: оптимистичная блокировка для конкурентных записей, атомарность операций.
- Обновления на уровне строк: в v1 — Copy‑on‑Write (COW), в v2 — Merge‑on‑Read (MOR), поддержка position deletes и equality deletes для логических обновлений.
Преимущества Apache Iceberg
- Широкая поддержка движков вычислений: Spark, Flink, Hive и др.; есть нативный Java API.
- Гибкая организация данных: работает для потоковых инкрементальных и пакетных сценариев на единой модели хранения (HDFS, Apache Ozone и др.); поддерживает Parquet/ORC/Avro; скрытое партиционирование и эволюция партиций устраняют «островки данных».
- Оптимизированная загрузка данных (ingest): ACID делает новые данные мгновенно видимыми без влияния на текущие задачи; upsert/merge на уровне строк сокращают задержки.
- Инкрементальное чтение: встроенная интеграция со Spark Structured Streaming и Flink Table Source; поддержка исторических версий повышает надёжность и аудитируемость.
Типовые сценарии использования
- Импорт и запросы в реальном времени: непрерывная запись в таблицы Iceberg и мгновенная аналитика через Hive/Spark/Presto/Iceberg. ACID обеспечивает изоляцию и отсутствие «грязных» данных.
- Удаление/обновление данных: операции на уровне файлов вместо полной переработки таблицы; например,
DELETE FROM test_table WHERE id > 10. - Контроль качества данных: валидация схемы при загрузке; изменения схемы через DDL Spark SQL без переэкспорта исторических данных; ACID изолирует изменения схемы от текущих чтений.
- ML в реальном времени: конвейер подготовки данных (очистка/трансформации/feature engineering) превращается в надёжный поток; поддержка нативного Python SDK.
Ускорение запросов StarRocks × Iceberg
StarRocks эффективно анализирует как внутренние данные, так и данные в озере, поддерживает внешний каталог Iceberg (External Catalog) и позволяет запрашивать таблицы Iceberg без миграции данных. Поддерживаются Iceberg v1 и v2 (чтение/запись).
Оптимизации:
- Метаданные: кэш метаданных снижает избыточный I/O; распределённое планирование заданий ускоряет параллельное чтение/фильтрацию Manifest‑файлов; Manifest Cache уменьшает накладные расходы парсинга.
- План выполнения: стоимостной оптимизатор (CBO) использует статистики; StarRocks собирает статистики по внешним таблицам (включая гистограммы и сложные типы).
- Форматы файлов: оптимизации для Parquet/ORC снижают объём сканирования и I/O.
- Снятие различий между внешними и внутренними таблицами: кэш данных (Data Cache) снижает удалённый I/O; «умные» материализованные представления обеспечивают переписывание запросов и инкрементальное обновление.
- Интеграция с экосистемой: поддержка чтения/записи Iceberg упрощает обратную выгрузку в озеро и лёгкую переработку данных, улучшая производительность запросов и единое управление.
Быстрый старт
В рамках руководства вы:
- Развёрнёте объектное хранилище, Apache Spark, Iceberg Catalog и StarRocks с помощью Docker Compose.
- Импортируете данные в озеро Iceberg.
- Настроите StarRocks для доступа к Iceberg Catalog.
- Выполните запросы к данным озера из StarRocks.
Подробный учебник: https://docs.starrocks.io/en/docs/quick_start/iceberg/
Iceberg Spark Quickstart: https://iceberg.apache.org/spark-quickstart/
Развёртывание Iceberg
Чтобы добавить Iceberg в существующий Spark, достаточно подключить соответствующий JAR в параметры запуска. В данном руководстве используется контейнер tabulario/spark-iceberg — Spark уже с интегрированным Iceberg, что позволяет сразу работать в среде PySpark.
Окружение (Docker Compose)
Используется шесть контейнеров:
starrocks-fe: метаданные, подключения клиентов, планирование и диспетчеризация запросов.starrocks-be: выполнение планов запросов.rest: сервис метаданных — Iceberg Catalog (REST).spark-iceberg: окружение Apache Spark для PySpark.mc: MinIO Client.minio: объектное хранилище MinIO.
Docker Compose файл (скачайте из репозитория StarRocks) настраивает:
- Iceberg REST‑каталог (
http://iceberg-rest:8181) сCATALOG_WAREHOUSE=s3://warehouse/,S3FileIOиCATALOG_S3_ENDPOINT=http://minio:9000. - MinIO с публичной политикой на bucket
warehouse. - Переменные доступа S3‑совместимого хранилища:
AWS_ACCESS_KEY_ID=admin,AWS_SECRET_ACCESS_KEY=password.
Загрузка Docker Compose и набора данных
Запуск окружения в Docker
Подсказка: команды docker compose выполняйте из каталога, где лежит docker-compose.yml.
Дождитесь, когда starrocks-fe и starrocks-be перейдут в состояние healthy (обычно ~30 секунд).
Работа с PySpark и Iceberg
Скопируйте набор данных в контейнер spark-iceberg:
Запустите PySpark:
Загрузите данные в DataFrame и проверьте схему/выборку:
Создайте таблицу Iceberg и запишите в неё данные:
Примечание: таблица будет доступна через внешний каталог StarRocks (External Catalog) на следующем шаге.
Подключение к StarRocks и настройка доступа к Iceberg Catalog
Подключитесь к StarRocks из MySQL‑клиента (из контейнера FE):
Создайте внешний каталог iceberg в StarRocks:
Проверьте каталоги, переключитесь и посмотрите БД/таблицы:
Замечание по типам: в Spark
будет отображаться в StarRocks как
(и возможны другие конверсии типов).
Запросы к таблицам Iceberg из StarRocks
Время приёма заказа (первые 10 строк):
Пиковые часы по количеству поездок:
Видео‑демонстрация
Демонстрация StarRocks + Iceberg + MinIO (EN)https://www.bilibili.com/video/BV1ET42167TY/?spm_id_from=333.999.0.0&vd_source=1cb452610138142d1300dd37a6162a88
Расширенные материалы
- Apache Iceberg — Spark Quickstart: https://iceberg.apache.org/spark-quickstart/
- Apache Iceberg — Catalogs: https://iceberg.apache.org/docs/latest/catalogs/
- Apache Iceberg — REST Catalog: https://iceberg.apache.org/docs/latest/rest-catalog/
- StarRocks — Quick Start с Iceberg: https://docs.starrocks.io/en/docs/quick_start/iceberg/
- StarRocks — External Catalog (Iceberg): https://docs.starrocks.io/en/docs/data_source/catalog/iceberg_catalog/
Примечания по терминологии
- Catalog → каталог; External Catalog → внешний каталог (External Catalog).
- Metadata File / Snapshot / Manifest — используем русские эквиваленты с английскими терминами в скобках при первом упоминании.
- Hidden partitioning → скрытое партиционирование.
- Schema/Partition evolution → эволюция схемы/партиционирования.
- MVCC, ACID, CBO, Data Cache, Manifest Cache, Copy‑on‑Write (COW), Merge‑on‑Read (MOR), position/equality deletes — используем английские аббревиатуры/термины, так как это общепринятая практика в индустрии.

163 открытий2К показов

Что такое ArgoCD. Показываем основы работы с ArgoCD. Рассматриваем пошаговую инструкцию и основные нюансы инструмента ✔ Tproger

GPU для бизнеса: окупаемость и выбор стратегии. Расчет ROI, сравнение CAPEX vs OPEX для AI, рендеринга и HPC. Аренда мощностей NVIDIA V100/P100.

Архитектор Харшал Патил критикует Next.js: жёсткая связность, отсутствие модульности и ограничения мешают строить масштабируемые системы

Готовитесь к собеседованию по системному дизайну? Разбираем популярные вопросы, эталонные ответы и лучшие ресурсы для подготовки.