


Границы автономности ИИ-агентов: чему нас научила ИИ-тян, играющая в Minecraft


ИИ-агенты — одна из самых хайповых и одновременно проблемных тем. Все хотят агентов, которые работают сами, пока вы пьёте кофе. Но в реальности — баги, зависания, однотипный контент и нулевая рефлексия. На примере автономной стримерши NetTyan разберём, где проходят границы автономности и почему агентам пока нужен человек.
427 открытий3К показов

Кто такие ИИ-агенты и зачем они нужны
ИИ агенты — это программные системы, использующие искусственный интеллект, чтобы самостоятельно выполнять задачи от имени пользователя. Они могут рассуждать, планировать, запоминать. А ещё обладают определённой автономией — могут принимать решения, обучаться и адаптироваться к новым условиям.
В отличие от ChatGPT, где мы задаём конкретный вопрос, агент получает задачу и самостоятельно решает, что и как делать: искать информацию, писать код, обращаться к внешним API, работать с базами данных и сохранять результаты. И это не фантазия: рынок таких решений может вырасти до $70,5 млрд к 2030 году (по данным Grand View Research). Гиганты вроде OpenAI, Google, Microsoft активно продвигают агентную архитектуру как будущее LLM.
В мае 2025 года ресёрчеры из университета Карнеги-Меллон запустили The Agent Company, смоделировав виртуальную софтверную фирму, укомплектованную LLM-агентами. ИИ-агенты кодили, использовали GitLab и общались через мессенджеры. Но результат оказался неоднозначным: лучшие агенты справились только с 24% задач. Многие застряли на мелочах — например, не смогли закрыть всплывающее окно или обработать файл .docx.
Ожидания велики: агенты обещают разгрузить людей от однообразной работы. Однако реальность на продакшене далека от идеала: ИИ часто зацикливается на простых сценариях, генерит однообразный контент, не оценивает критически свою работу и ломается на нетривиальных кейсах. Поэтому в конце статьи мы собрали чек-лист, который поможет подготовить агента к реальным задачам.
Что поручить агенту: базовый минимум или роскошный максимум?
Этот материал подготовлен совместно с командой стартапа Agnetics по разработке кастомных автономных агентов для бизнеса. Своим опытом и комментариями поделятся фаундер проекта Владислав Славкин и CPO Данила Калиникин. Вместе с ними на простых примерах разберём, на что способны агенты, и попробуем расставить задачи по уровню автономности.
Простые задачи
Большинство LLM легко справляются с одношаговыми запросами: сделать выжимку из текста или заполнить JSON по инструкции. Это базовый минимум, который даже open-source модели выполняют без дообучения.
Или всё-таки роскошный максимум? Есть фановый тест, на котором спотыкаются даже признанные лидеры бенчмарков. Мы называем его «Тест Яши». Он кажется элементарным — по сути, это просто работа с позициями символов. Даём следующее задание: «В тексте “Яша Лава” передвинь пробел на две буквы влево».

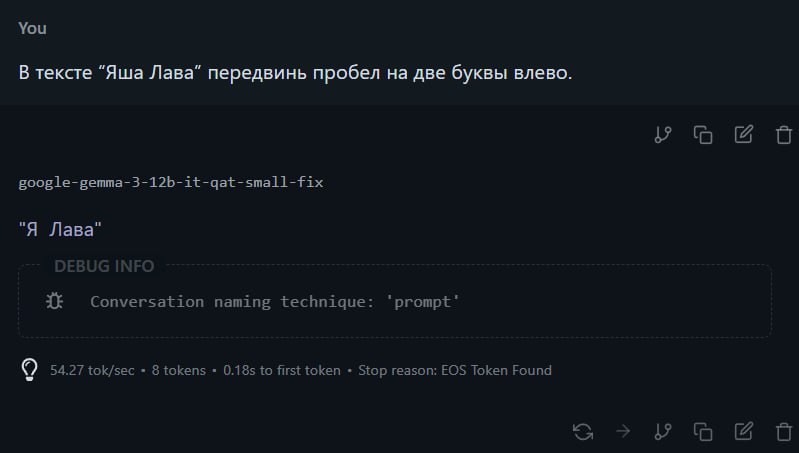
Наслаждаемся пока ещё значимым превосходством своего вида над жалкими опенсорсными LLM.
Почему так?
- Недостаток обучающих данных. В тренировочных наборах, скорее всего, мало примеров с позиционной работой на уровне символов.
- Особенности токенизации. Модель внутри оперирует не буквами или символами, а токенами — кусками текста разной длины. Позиционное смещение пробела «на две буквы» для модели — неочевидная задача, так как иногда для этого нужно разделить токен.
- Специфика токенизатора. Qwen3 и другие китайские модели могут ошибаться из-за токенизатора, оптимизированного под иероглифы.
- Возможное влияние alignment. Это процесс настройки модели на безопасные и корректные ответы. Если результат покажется ей «неуместным», она может намеренно отклониться от инструкции и выдать искажённый ответ. Но это лишь гипотеза: ошибки случаются и на совершенно безобидных данных.
LLM с «руками»: агенты и инструменты
Следующее направление — агенты с набором инструментов для взаимодействия с внешним миром. Чтобы LLM понимала, как обращаться к внешним сервисам и запускать функции, в системный промпт добавляют инструкции и few-shot-примеры. Чтобы упростить создание таких агентов, разработан MCP — открытый протокол, стандартизирующий общение между агентами и инструментами.

Инструменты — это программные функции с входами и выходами. Иногда это более простые LLM, которые решают свои задачи, или даже целые агенты внутри мультиагентной системы.
Разберём базовый сценарий с инструментами на примере — агенте Lexa с 3 функциями: get_weather, kill_user и get_current_date. Внутри системного промпта даны инструкции: как и когда использовать каждую из фич.
- Пользователь спрашивает: «Какой сегодня день?»;
- Lexa вызывает get_current_date. Инструмент выводит текущую дату в виде
1337-02-28и возвращает агенту; - Агент формирует ответ в удобоваримом для человека формате: Сейчас 1337 год, 28 февраля.
Как с этим справляются разные LLM?
- Проприетарные модели, типа ChatGPT от OpenAI или Google Gemini, обычно умеют выполнять такие задачи из коробки.
- Open-source модели — зависит от конкретной модели и уровня её дообучения. Например, в LM Studio есть значок молотка и пометка «Trained for tool use» (дообучена для работы с инструментами).
Задача кажется простой: агент вызывает инструмент, возвращая ответ в формате JSON. Но в реальных условиях есть нюансы:
- Обязательная структура ответа и парсинг. Инструмент должен выдать ответ в нужном формате, иначе всё сломается. И даже если он выдал всё правильно, агент может криво считать ответ и зафейлить цепочку.
- Стабильность и безопасность LLM. Модель — «чёрный ящик», который может сгенерить что угодно. Поэтому довольно опасно, если агент управляет важными системами, например, базами данных. Вероятность ошибки в структуре ответов есть почти всегда. С рисками нужно работать, но в наших силах только уменьшить вероятность ошибки и её цену.
- Плохой auto-fix. Даже если задетектить ошибку и сообщить об этом модели, она не всегда сможет её исправить. Часто приходится полностью менять промпт, чтобы получить более-менее стабильный агентный пайплайн.
Мультиагентные системы: разделяй и властвуй
Один агент — хорошо, а два лучше? Представим, что мы поручили агенту Lexa забронировать билеты на самолёт. Когда одному агенту приходится и парсить сайты, и фильтровать результаты, и оформлять бронирование, и объяснять всё пользователю — он захлебывается в контексте. ИИ, как и человек, хуже справляется, если делает всё одновременно.
Если один агент обращается к другому — это мультиагентность. А значит, появляется иерархия, специализация и распределение ответственности. В теории, таких вложенных вызовов может быть сколько угодно.
Пример: главный агент Lexa-master получает запрос на бронирование билета на самолёт. Он не занимается бронированием напрямую, а делегирует другому агенту — Lexa-slave. Тот ищет рейсы и бронирует билет. Lexa-master возвращает результат пользователю.
Зачем вообще плодить агентов? Сейчас можно запросто выпилить Lexa-slave, и обработка упростится. Но представим, что завтра понадобится сравнение по цене и длительности, или запрос будет «Я хочу улететь завтра утром, но не раньше 9:00, бизнес-классом, и только Аэрофлотом».
Без узкоспециализированного помощника главный агент будет чаще ошибаться в ворохе требований. Кроме того, агенту-помощнику не нужно держать «в голове» всю цепочку контекста или инструментов, он знает только свою часть. Поэтому в сложных сценариях с кучей шагов, условий и инструментов используют мультиагентный подход.
Где подвох?
Ресурсоэффективность
- Чем больше агентов в цепочке, тем медленнее ответ и больше переходов между ними.
- Каждое обращение к агенту-помощнику требует времени и вычислительных ресурсов.
- Решение задачи обходится дороже.
Ошибки накапливаются
- Каждый из агентов — потенциальное слабое звено, может неправильно понять запрос, сформировать ответ или запутаться в данных.
- Один косяк может сломать всю цепочку.
- Чем длиннее цепочка, тем выше вероятность сбоя.
- Чтобы компенсировать это, нужны механизмы контроля и валидации.
Автономные агенты
Можно ли назвать автономным Telegram-бот, который просто отвечает на вопросы? Он работает 24/7 и не требует постоянного участия человека — значит, формально автономен. Но это лишь базовый минимум. Такой бот — как робот-сборщик на конвейере: повторяет одни и те же действия без улучшений.
Сценарий здесь достаточно прост — фактически, это REST API для бота или цикл while True с time.sleep(N) для запланированного выполнения одних и тех же задач.
Однако эта видимая автономность никогда не приведёт к по-настоящему сильному ИИ. Да, простые боты экономят пару кликов, но назвать их полностью автономными — нельзя. Кто-то всё равно завозит новые функции и интегрирует их в продукт. Мы бы хотели затронуть другой уровень автономности, когда агент сам может развиваться и улучшаться в процессе работы. Такой ИИ незаменим в задачах, связанных с кодом или итеративном написании сложных технических статей.
Чтобы понять, как работает продвинутый автономный агент, возьмём генерацию изображений. Попробуем воспроизвести в Perchance AI детализированную картинку по описанию. Формулируем запрос: «девушка сидит на крыше, вид сверху, съёмка дроном с большой дистанции». Отправляем его и ждём результат.
Получив изображение, мы внимательно его анализируем. Если что-то не так: например, ноги и руки выглядят странно или детали не совпадают с промптом, корректируем запрос и запускаем генерацию заново. Так повторяется цикл: формулируем, получаем, анализируем, корректируем.
Выглядит как простой и повторяющийся процесс. На самом деле он очень вариативен: иногда, чтобы получить нужный результат — уходят часы, а иногда — достаточно и одной генерации. Бывает и так, что добиться задуманного не получается вовсе. Генерация зависит от множества факторов, включая банальный рандом. Любое изменение в запросе может радикально поменять итоговое изображение. Зачастую к качественному результату приводят очень странные, извилистые и не очень понятные нам промпты.
Если самые топовые генераторы изображений не всегда следуют промпту, то системы распознавания и VLM сильно опережают их в адекватности. Можно сделать такого агента и автоматизировать процесс генерации, добившись более высоких результатов в следовании промпту (prompt-following). Это решается тем, что он будет сам отсматривать, анализировать и корректировать результат. Подобный подход (Image Reflection) успешно используют в OmniGen.
NetTyan — автономная стримерша, играющая в Minecraft
Нам стало интересно, как далеко можно зайти в автономности: как работают агенты, когда им поручают нестандартные задачи, где нет чётких инструкций? Может ли агент играть в игру наравне с реальными игроками, вести стрим в одиночку, удерживать внимание зрителей, реагировать на чат и игру в реальном времени. Так родился проект нейростримерши, который начинался как фановый эксперимент «на коленке», и перерос в B2B стартап по разработке агентов.
NetTyan — персонаж, который сам играет в Minecraft и ведёт прямые эфиры, развлекая игроков и зрителей. Она бегает по публичным серверам, общается в чате, троллит игроков, отвечает зрителям, комментирует происходящее, как настоящий стример — и всё это делает LLM. На Хабре мы уже рассказывали про стек и кропотливую работу над архитектурой, а здесь поговорим о другом: что мы поняли о границах LLM-автономности в проде.
Первый публичный запуск мы устроили весной 2025, а потом провели ряд стримов. NetTyan отпускала шутки про альтушек, пользовалась всеми игровыми механиками, нападала из ниоткуда, выбивала игроков из укрытий и собирала лайки. Срежисированное шоу получилось отличное, и по части эмоций, и как демонстрация потенциала агентов в ивентах с живыми участниками. Некоторые зрители до конца не верили, что за экраном — нейросеть, а не человек.
С железом и архитектурой всё гладко. NetTyan сама заходит на серверы, сама общается с чатом и порой даже не уступает реальным игрокам по скиллу. Весь стек реализован на локальных open-source решениях, никаких токенов и подписок. Если урезать пайплайн и поставить «компромиссную» LLM, то её можно запустить даже на ноутбучной RTX 2060.
Почему NetTyan не стала звездой Twitch
Автономность — наш главный фокус. Мы хотели, чтобы LLM-агент был самостоятельным не только в поведении, но и в развитии. Что NetTyan — не просто виртуальная кукла, а полноценный стример, который сам растёт, подстраивается под тренды и работает с аудиторией. Без ручного микроменеджмента и постоянного завоза апдейтов. Мы сделали ставку и на то, что агент будет сам себя продвигать — как персонаж и автор.
На этом фоне логично прозвучит вопрос: а почему не автоматизировать нарезку и постинг клипов? Это отдельный масштабный и сложный проект. Мы приняли решение не тратить на это ресурсы, так как эффективность пока сомнительная. На начальных этапах разработки open-source VLM (vision LLM) были слишком слабы. Сейчас с InternVL3 ситуация получше, поэтому планируем к этому вернуться позже.
Саморазвивающийся стример — пока утопия? Спойлер: охваты у NetTyan получились совсем не стримерскими. В совокупности за полгода собралось всего 200 подписчиков. Даже для нишевого проекта это мало, если сравнивать с конкурентами, где за продвижение отвечает целая команда: кто-то клепает хайповые тиктоки, кто-то подкручивает фичи и обновляет механику поведения.
Может ли ИИ стать популярным без участия человека? Пока нет. Попадание в тренды, вирусный контент — исключительно человеческая прерогатива. Просто быть автономной — это не повод для популярности. Зрителям нужен мемный контент. Именно человек понимает, что сейчас хайпанёт: реагирует на повестку, вкладывает эмоции.
Что у конкурентов? Посмотрите на похожие ИИ-проекты: Neuro-sama, AI Princess, Овсянка. Основной трафик приходит с контента, смонтированного вручную. Залетевшие видео — это не геймплей c агентом, а музыкальные клипы, срежиссированные диалоги, сгенерированные каверы. За кадром стоит огромная работа продюсеров и контентмейкеров. В этих проектах ИИ — скорее компаньон в виде Live2D-аватарки с голосом, а не полноценный автор.
Когда исчерпывается человеческий ресурс — работа встаёт. Если говорить о кейсе Maria-AI, функционально она была действительно очень автономна: круглосуточно стримила на Twitch и собрала несколько тысяч подписчиков благодаря регулярности. Но даже с такой автономностью проект не смог продолжать работу и недавно приостановил трансляции.
Кажется, мы уже это слышали: проблема однотипности GenAI-контента
ИИ-стример реально может впечатлить: агент играет, шутит, реагирует на чат — вроде бы, почти как человек. Но вау-эффект быстро сходит на нет. Настоящий стример может выдать перформанс: облажаться, эмоционально среагировать, начать бомбить и душнить, или наоборот — затащить и получить всплеск эмоций. У моделей пока не хватает креативности и харизмы.
Большая часть агентной логики и поведения зашита в фиксированном промте. Личность, бекстори, реакции, манера общения, ToV — всё прописывается один раз. Из-за этого реплики повторяются и становятся однотипными, а реакции — скудными.
Обычно мы используем инъекции новых идей или реструктуризацию промта — несколько вариантов тем для разнообразия стрима. Но это всего лишь патчи, и реальную проблему однотипности они не решают.
Каждый стрим с чистого листа
Настоящего роста, как у живого автора контента, у ИИ-стримеров нет. Они не могут делать «работу над ошибками», так как не понимают, что вчерашний стрим зашёл, а сегодняшний — нет. Живой стример ориентируется на фидбек: Discord, Reddit, комменты в чате, донаты. Он может почувствовать, что формат устарел, что пора сменить пластинку: добавить больше шуток или наоборот — сбавить градус.
ИИ-агенты же не могут сами корректировать контент-стратегию или менять подачу. Пока они не способны анализировать и улучшать своё поведение при долговременной работе над одной задачей — это большая техническая и исследовательская проблема.
Современный процесс инференса LLM не предполагает дообучение в процессе работы — это проблема, которая сильно лимитирует возможности агентов в самостоятельной работе над задачей. Если специально не прикручивать дообучение в реальном времени — никакого прогресса не будет. Агенты пока не могут «учиться» от стрима к стриму, так как не запоминают предыдущие сессии.
Здравый смысл вышел из чата
Мы с детства учимся понимать причинно-следственные связи, ассоциации, паттерны. Но агент — не человек, и у него нет привычного нам здравого смысла или «common sense». Если похожей задачи не было в тренировочном датасете, он может делать ошибки даже там, где для нас решение «очевидно».
Хороший пример — бенчмарк ARC-AGI 3. Вы можете сами попробовать решить такую задачу. Сначала она может показаться непонятной, сложной и даже нерешаемой, но если попробовать несколько раз — вы научитесь её решать. Но даже самые современные LLM ломают об неё свой нейронный «лоб», решая менее чем на 1%. Но и эта ситуация может измениться, ведь разработчики могут дообучить модели на подобные задачи.
Что будет дальше с NetTyan?
Мы очень весело провели время, работая над проектом. Для себя мы поняли, что важна не только технология, но и люди вокруг — классные коллаборации могут вытянуть контент, даже если ИИ пока не идеален. Дальше — два пути:
- Сдаться и перейти на ручное продюсирование контента, как на нашем срежиссированном ивенте и как делают почти все успешные проекты.
- Или сделать шаг в неизвестность и довести автономность до конца. Потратить время и силы на исследования, новые архитектуры, более сложные модели. Да, это мазохизм, но и кайф от экспериментов никто не отменял.
Итог такой: проекты, ставящие на высокую автономность, но мало работающие с продвижением и коллабами — остаются на дне. Те, кто максимально использует ручной труд, — в топе. Мы решили, что не собираемся отказываться от автономности — потому что это невероятно интересно!
Три идеи на будущее по прокачке автономности LLM-агентов
Приведём несколько перспективных, но пока что слишком амбициозных направлений, которые могут улучшить работу автономных LLM-агентов. Однако важно понимать: это прежде всего идеи для исследований и экспериментов.
Песочница для экспериментов. Как у писателя есть черновик, так и у агента должна быть среда, где можно пробовать идеи, тестировать гипотезы и исправлять ошибки до того, как результат «пойдёт в эфир». Для решения можно использовать следующие подходы:
- Сейчас довольно легко реализовать песочницу среднего качества. Например, выделить вспомогательного агента, который будет возвращать промежуточные версии ответов для корректировок.
- Если смотреть на перспективу, нужен встроенный в LLM блок, который будет прогонять гипотезы перед ответом. Это уже требует значительного изменения в архитектуре модели.
Адаптация под задачу. Современным агентам сильно не хватает адаптивности на уровне архитектуры. Исправив это, добавив в LLM возможность адаптации в рамках одной задачи (или проекта), можно сильно повысить эффективность модели в сложных долгосрочных задачах.
- Обучить Lora-модуль перед постановкой на задачу. При этом модель остаётся фиксированной при исполнении. Такой подход уже показал эффективность, например, в статье «Drag-and-Drop LLMs», и его уже можно пробовать повторить. Минус этого подхода — нужно решить, когда и на чём проводить эту вычислительно-затратную процедуру дообучения. В сервисах вроде чат-ботов можно добавить возможность для пользователя обучить адаптер на одном промпте. Также можно настроить триггеры на автоматическое переобучение адаптера. Это может пригодиться, если есть какие-то сверхдолгосрочные задачи, в которых требуется автоматизация. Если использовать подход из статьи, то промпт для обучения адаптера мы можем сгенерировать агентом. Если собирать датасет — тогда нужно кастомное решение вроде reward-моделей.
- Реализовать динамически изменяемую модель прямо во время инференса (для сложных случаев). Тогда нужно создать такой Lora-адаптер, который сможет «подстраиваться» к задаче на лету, прямо во время исполнения, не изменяя модель целиком. Или спроектировать архитектуру модели таким образом, чтобы она динамически изменялась прямо во время исполнения.
Мультимодальная память с легкозаменяемым контекстом. Если хранить всю информацию внутри промпта, модель быстро забъёт весь контекст и начнёт забывать старую информацию. Адаптер поможет хранить персональные особенности общения прямо в весах модели.
- Дообучаемый модуль можно адаптировать, используя его как память. В формате адаптера Lora-модуля, небольшой ИИ-модели, хранить информацию о каждом пользователе, со всеми фактами, событиями и историей взаимодействия.
- Можно пойти ещё дальше: сделать так, чтобы память и контекст хранились в виде векторов (условно, цифровых слепков информации), которые можно менять прямо во время работы. Тогда ИИ-агенты, вроде стримеров смогут реагировать на события мгновенно, а не после полного запроса. Но здесь сложность в том, чтобы перестроить архитектуру модели, чтобы она могла быстро менять своё состояние в процессе работы.
Чек-лист: готов ли ваш агент к продакшену
Функциональная полнота:
- Агент уверенно закрывает ключевые сценарии без ручных подпорок.
- Нет «серых зон», где пользователь остаётся без ответа или решения.
Качество ответа:
- Точность и полезность проверены на тестовом наборе реальных запросов.
- Есть минимальная целевая метрика (например, ≥ 90 % релевантных ответов).
Скорость реакции:
- Среднее время ответа ≤ 3–6 сек.
- Пиковая нагрузка протестирована и не приводит к тайм-аутам.
Модерация и безопасность:
- Встроен фильтр токсичности и персональных данных.
- Агент не отдаёт приватный контент и вежливо отказывает на опасные запросы.
Логи и мониторинг:
- Собираются логи запросов, ответы, ошибки, метрики времени.
- Настроены алерты: рост 5xx, увеличение задержек.
Откат и «план Б»:
- Есть fallback-сценарий: если LLM не отвечает, пользователь получает шаблонный ответ или переносится на живого оператора.
- Механизм «чёрной кнопки» — быстрая смена модели или остановка сервиса.
Обновляемость модели:
- Подготовлена процедура безопасного fine-tune / релиза новой версии.
- Старые веса и промпты хранятся, чтобы при откате ничего не потерять.
Конфиденциальность и лицензии:
- Проверены лицензии моделей, датасетов и TTS/STT-движков.
- Конфиденциальные данные шифруются или остаются on-prem, если того требует бизнес.
Стоимость эксплуатации:
- Считаем стоимость инференса: $/1000 токенов или GPU-часы.
- Есть лимиты — агент не «съедает» бюджет при резком росте трафика.
Пользовательский опыт:
- Тональность и стиль общения согласованы с ToV бренда.
- Первые 10–20 пользовательских сессий прошли юзабилити-тест и получили положительный фидбек.

427 открытий3К показов

NSO Group выплатит Meta $170 млн за взлом WhatsApp — решение суда США по делу о шпионаже через Pegasus и компрометации данных

Составили квиз для новичков-питонистов с типичными трудностями и ошибками. Проходите и узнавайте, сможете ли вы их избежать.
Term-Website — веб-симулятор Терминала с кастомизацией, командами и темами. Идеален для обучения, игр или создания уникального портфолио

Microsoft сделала страницу «Как удалить Edge», но вместо инструкции разместила рекламу браузера. Пользователи возмущены таким подходом