


Использование технологий машинного обучения для идентификации конфиденциальных документов

В крупной компании сложно сдедить за соблюдением режима конфиденциальности, поэтому стоит воспользоваться помощью машинного обучения.
1К открытий1К показов

Константин Замков
руководитель направления внедрения и поддержки корпоративных решений в Sharesoft
Одни только открытые публикации в СМИ, говорят о том, что в России происходят сотни случаев утечек конфиденциальной информации каждый год. При этом большая часть утечек происходит непреднамеренно по вине рядовых сотрудников. В крупных корпорациях сотрудники обмениваются сотнями тысяч и миллионами документов в электронном виде ежедневно внутри компании и с внешними контрагентами. Как в таком потоке определять, какие документы являются конфиденциальными, а какие – нет? Кому можно отправлять тот или иной документ, а кому – нельзя? В компаниях, как правило, каждый сотрудник лично отвечает за неразглашение конфиденциальной информации, а предотвращением и контролем отсутствия нарушений на уровне организации занимается служба информационной безопасности. Но когда компания крупная и информационный поток большой – отследить соблюдение режима конфиденциальности становится сложнее и на помощь в этом случае приходят технологии машинного обучения.
Искусственный интеллект можно научить определять, какие документы конфиденциальные, а какие – нет. После этого система может делать необходимые действия с документами, например:
- Запрещать отправку конфиденциального документа на внешние адреса электронной почты.
- Шифровать конфиденциальные документы при отправке.
- Осуществлять или рекомендовать ограничения прав на просмотр, копирование, пересылку документа и др.
- Фиксировать факт отправки документа с различными параметрами в журнале аудита.
Приведу конкретный пример того, как такой процесс выглядит на практике для сотрудника компании. Предположим, что сотрудник хочет отправить документ Word по электронной почте на внешний почтовый ящик в другую компанию. Порядок действий в этом случае будет следующий:
- Сотрудник скачивает нужный ему документ Word из корпоративной информационной системы компании на рабочий компьютер.
- Открывает почтовый клиент (например, Outlook), пишет электронное письмо, указывает адрес получателя и прикрепляет документ, как вложение.
- При нажатии кнопки отправить текст письма и вложения передаются обученной модели для анализа на конфиденциальность (этот шаг происходит автоматически без участия сотрудника).
- Если документ конфиденциальный – сотрудник получает сообщение о необходимости ограничить доступ к письму перед отправкой и может установить для него политику конфиденциальности в почтовом клиенте (например, разрешить получателю только просматривать документ без копирования и пересылки на другие адреса электронной почты).
- В журнале службы информационной безопасности делается запись о том, что был выявлен конфиденциальный документ и о том, установил ли пользователь для документа политику конфиденциальности или отправил документ без ограничений доступа.
На четвертом шаге, в зависимости от процедур в компании, можно также не спрашивать пользователя, а сразу запретить отправку конфиденциального вложения.
Теперь давайте рассмотрим какие шаги необходимо выполнить, чтобы получить помощника, который подскажет, является ли документ конфиденциальным.
- Сбор данных для обучения модели: для обучения модели собирается массив данных из конфиденциальных и не конфиденциальных документов. Это позволит обучить модель так, чтобы в дальнейшем она могла принимать решения самостоятельно. В выборке рекомендуется набирать примерно поровну конфиденциальных и не конфиденциальных документов. И чем больше будет таких документов – тем точнее в последствии будут предсказания модели. Если говорить про цифры, то речь идёт о тысячах, а ещё лучше – о десятках тысяч документов. Это не самый простой процесс и можно даже написать отдельную статью про подготовку данных, но выполнить его можно и это нужно для того, чтобы двигаться дальше.
- Подготовка данных: из собранных на первом шаге документов выгружается текст и разбивается на векторы.
- Разработка модели: создается модель, в которую мы в дальнейшем будем загружать наши данные. Создать такую модель можно с использованием, например, языка программирования Python и фреймворка ML.Net.
- Обучение модели: загрузить в модель данные, полученные на 1 и 2 шагах, и обучить её на конфиденциальных и не конфиденциальных данных.
- Развертывание: обученная модель встраивается в модуль, который будет извлекать необходимый текст, перерабатывать его и передавать на анализ в обученную модель. После этого проводится тестирование модели на реальных документах и данных.
- Дообучение: в дальнейшем по мере эксплуатации рекомендуется дообучать модель, чтобы она со временем не теряла актуальность и точность предсказаний. Для этого формируется фокус-группа экспертов компании, которая помечает новые документы, как конфиденциальные или не конфиденциальные. В дальнейшем дополненный реестр конфиденциальных и не конфиденциальных документов используется для дообучения модели.
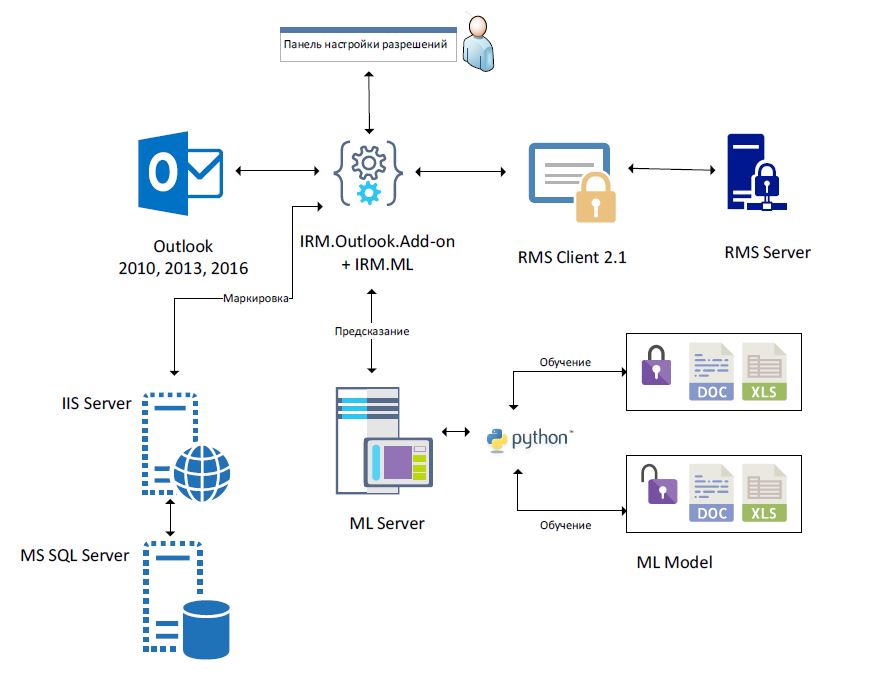
Один из возможных вариантов архитектуры системы представлен на Рисунке 1. Модель в данном случае расположена на отдельном сервере (ML Server), а модуль, извлекающий текст из писем и вложений и передающий его на анализ модели, реализован в качестве Add-on к почтовому клиенту Outlook. Если документ конфиденциальный – для управления правами доступа к нему используется RMS Клиент. Документы, которая экспертная группа маркирует, как конфиденциальные или не конфиденциальные, записываются в отдельную базу данных (на схеме это MS SQL Server), после чего эти данные можно оттуда забрать и провести на них дообучение модели. Важно уточнить, что Outlook здесь приведен в качестве примера, а на практике почтовый клиент может быть другим, а также подход применим и к другим ресурсам, где располагаются документы, а не только к почтовым клиентам.
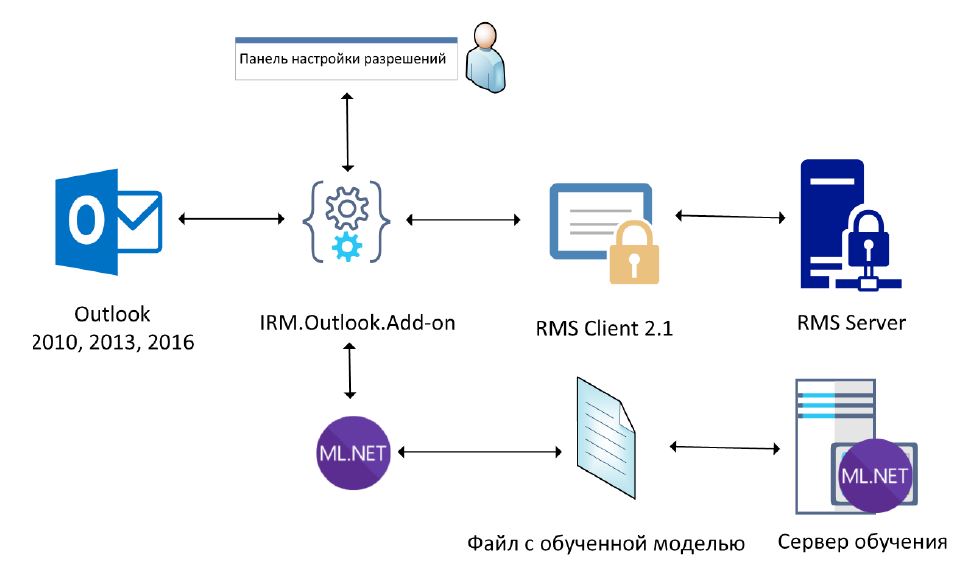
В случае, когда компания и трафик документов очень большие, можно расположить модель не на отдельном сервере, а на клиенте (Рисунок 2). Такой вариант предполагает иной подход для обновления модели: в этом случае модель уже обновляется не на сервере, а на всех клиентах. С другой стороны, сокращается время работы модели и сетевая нагрузка.
В результате получается инструмент, который может существенно облегчить жизнь как сотрудникам службы информационной безопасности, так и пользователям, которые сократят своё время на анализ конфиденциальности документов и потратят его на другие задачи.

1К открытий1К показов

Актуальные требования к обработке персональных данных в 2025 году. Как разработчикам соблюдать закон и избежать штрафов. Практические советы по защите информации в коде и архитектуре приложений.

Объем информации растет, но без системного подхода данные превращаются в шум. Разбираемся, как в компаниях структурируют, анализируют и защищают данные, чтобы они работали на бизнес, а не создавали хаос.

AI Darwin Awards 2025: Taco Bell с 76 тако, Deloitte с фейковыми цитатами, Replit с удалённой БД — худшие провалы ИИ года

Курсы робототехники. Рейтинг вариантов дистанционного обучения, обзор программы и стоимости курсов роботостроения.