


Как GPT-3 превратить в GPT-4
Рассказываем, как научить GPT-3 рисовать. По умолчанию эта функция недоступна в GPT-3, и воспользоваться ей можно только в GPT-4.
23К открытий27К показов
Как давно вы пользуетесь ChatGPT? Неделю? Месяц? Пол года? Год? А как много вы узнали о нём за всё это время? Возможно вы уже используете его в самых разных задачах: написание статей, документов, программного кода, составление таблиц, математических формул и диаграмм — и это только малая часть его возможностей. Возможно вы даже сами спрашивали лично у него: «А на что ты способен?». И он давал вам перечень своих возможностей, которые могли вас даже удивить. Но одна функция всегда оставалась недоступной — генерация изображений
Проблема
На данный момент ChatGPT — нейросеть, основанная на текстовой GPT-3 модели. Он не умеет генерировать изображения. Не умеет он и рисовать. Для таких целей существуют другие нейросети, например MidJourney и StableDiffusion
Сейчас активно разрабатываются мультимодальные нейросети, одна из которых всеми ожидаемая GPT-4. Она должна объединить в себе все имеющиеся на данный момент модели нейросетей: текстовые, художественные, музыкальные и многие другие. Однако, дата её выхода точно неизвестна. Так стоит ли вообще ждать её выхода? Может быть, есть способ объединить их уже сейчас?
В этой статье вы узнаете, как научить ChatGPT, работающий на модели GPT-3, генерировать изображения и рисовать картинки самостоятельно. При этом вам даже не потребуется платить за условное расширение возможностей
Но он же текстовый!
Замечали ли вы, в процессе работы с ChatGPT, что он может форматировать текст? Как он сам составляет заголовки, содержания, перечисления? Возможно он даже составил и отобразил вам таблицу с данными и даже предоставил возможность её скачивания! Всё это он делает с помощью языка разметки — Markdown
Markdown используется, например, на GitHub и подобных ему сервисах. С его помощью можно красиво оформить репозиторий проекта, составить описание. Многие даже пишут лендинги, используя только Markdown
Многие, кто им пользуется, знают, что Markdown позволяет раличным образом форматировать текст, выводить таблицы, формулы и даже диаграммы! Но Markdown также позволяет выводить и изображения, и видео, и музыку. Обычно, для того, чтобы вывести изображение используют такой код:
С помощью подобного кода, можно попросить ChatGPT показать вам какое-то изображение или видео, однако для этого вам придётся сначала дать ему нужную ссылку (хотя можно попросить его вывести рандомное видео с YouTube)
Безумная идея
Ну что, уже догадались, к чему всё идёт? Да, можно попросить его использовать определённые API сервисы, которые позволяют получать изображение по запросу. Много ли таких? Не очень. За время поисков я нашёл лишь несколько, которые упоминались в других англоязычных статьях на просторах интернета, но все они уже не работали к тому моменту. Ну и что же делать? Писать свой сервис? А может, научить его рисовать самому? — Звучит как бредовая идея, не так ли? Модель-то текстовая
А что он умеет?
Что вы слышали об SVG? Формат изображений, основанный на векторной графике. Кто-то знает его через PhotoShop, кто-то через Illustrator, кто-то активно использует его на своих сайтах в качестве иконок для кнопочек. Но что под капотом? – обычный XML, простой базовый язык разметки, на котором основан тот же HTML. В него даже можно строить JavaScript код!
Так вот, мы с вами знаем, что ChatGPT умеет программировать. Знает он и языки разметки и, оказалось, он хорошо знает и SVG! (ведь SVG — это XML, а его он знает)
Я полагаю, по крайней мере некоторые, знают, что такое Data URI формат? Способ отображения бинарных файлов прямо на HTML странице. Он основан и использует base64 для того, чтобы закодировать файл, а после этого легко передавать его по сети. Файлы в таком формате можно легко встроить целиком в HTML код, например
Поговорив с ChatGPT, он подтвердил, что знает формат Data URI и умеет кодировать в base64
Чёрная магия?
Теперь, всё, что нужно, это составить правильный промпт, для того, чтобы научить его рисовать самостоятельно. Не буду вас томить, вот он:
А ниже – примеры его работ с таким промптом:




Не всё так радужно
Ну что, воодушевились? Как бы не так. Хотя ChatGPT и знает, что он рисует, знает, что такое base64, знает как он работает и даже умеет сам кодировать, слишком часто он ошибается в кодировке и изображение либо получается неправильным, либо неточным, либо не выводится вообще. Поэтому, если вы попросите его нарисовать какую-нибудь сложную картинку (да даже самый простой треугольник) — велика вероятность, что картинка даже не выведется
И что бы я ни делал, как бы ни редактировал промпт, у меня не получалось добиться стабильной его работы. Максимум что получилось сделать — перевести промпт на английский язык, дать ему время на обучение и очень жёстко контролировать посредством системы очков. Тогда результаты стали явно лучше, но не на много
Решение
Подумав, было решено писать свой мини-сервис для того, чтобы облегчить работу ChatGPT в процессе кодировки. Было решено переложить этап кодировки на этот сервис, чтобы ChatGPT просто отсылал SVG-код картинки и получал готовое изображение. Так был создан get2piс — простой скрипт на PHP, который позволяет ChatGPT обойти этап с кодированием и сразу рисовать сложные картинки без потерь
Работает от просто: по GET запросу передаётся SVG-код картинки, скрипт генерирует изображение в Data URI и отдаёт пользователю
Таким образом, результаты его умений стали намного более лучше, стабильнее. Появилась возможность сразу запрашивать у него сложные фигуры и картинки
Подробнее о проекте можете почитать здесь, на GitHub. Вы также можете ознакомиться там со всем необходимым, для того чтобы запустить его у себя на сервере. К тому же, там содержатся нужные промпты, описание и небольшая галерея примеров его работ
Ссылка на get2pic проект:
Всё ещё под вопросом
И всё же, пусть это и большое достижение: научить ChatGPT самостоятельно рисовать (хотя это сугубо текстовая модель), это всё же далеко от того что может MidJourney или даже StableDiffusion. Как ни крути, это всё же печально, но уже много лучше, чем ASCII рисование (да, так он тоже умеет)
Что же делать? Искать API сервисы для генерации изображений, как тот же StableDiffusion? Искать сервисы-аггрегаторы? Писать свой сервис с нуля?
Дальше – больше
Как уже было сказано выше, я отправился в интернет искать готовые сервисы. То, что я тогда там нашёл уже не было актуально. Поэтому я предпринял попытку поискать на GitHub — и не прогадал. Среди десятков репозиториев, которые хоть как-то относились к ChatGPT и к генерации изображений, я нашёл один рабочий сервис: pollinations.ai
Этот сервис уже позволяет генерировать, с помощью их ИИ, полноценные, сложные, реалистичные изображения по запросу. Получается что-то типо StableDiffusion и пользоваться им довольно легко
Вот рабочий промпт, который я перевёл с оригинала на русский:
А ниже — примеры того, как это будет выглядеть:

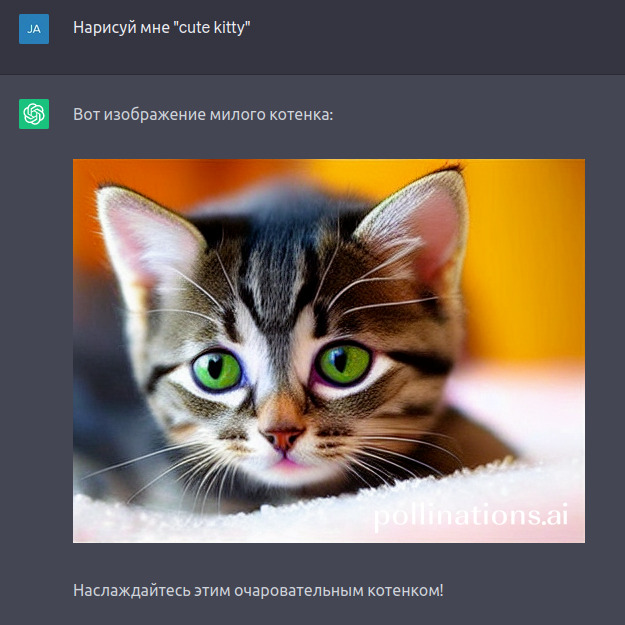
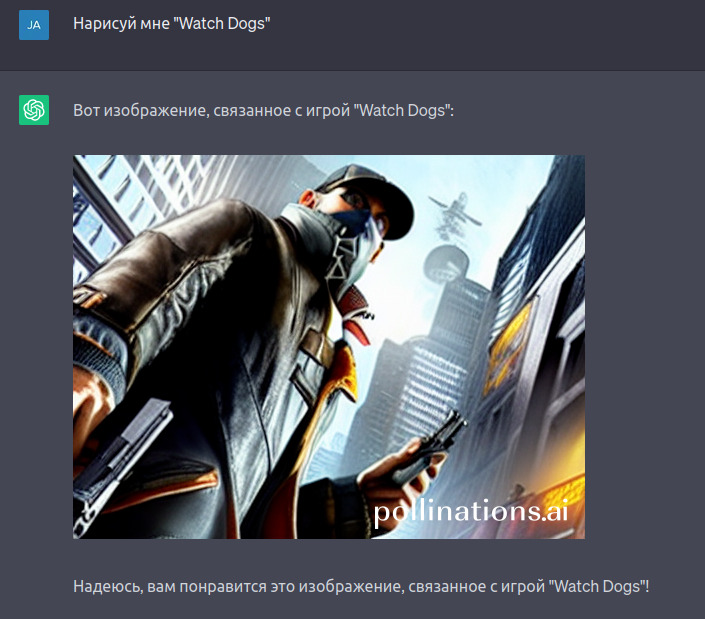
Как вы могли заметить, это уже что-то посерьёзнее, чем рисовать какие-то там фигурки. Однако, стоит заметить, что хотя сервис действительно работает, лучше делать запросы на английском языке. Также, стоит заметить, что изображения не сохраняются при обновлении диалога с ChatGPT — каждый раз будут разные изображения. Но даже так — это уже что-то!
Подробнее о проекте pollinations.ai вы можете почитать по ссылке ниже:
Заключение
Ну что скажете? Прикольно? Я считаю — да. По крайней мере, всё это можно пробовать и использовать уже сейчас совершенно бесплатно, не дожидаясь полноценного выхода GPT-4. А что уж будет когда он выйдет — этого мы не знаем, но будет определённо захватывающе!
Так что давайте продолжать использовать ChatGPT и погружаться в его мир возможностей. Вам необходимо лишь одно — воображение и желание экспериментировать. Итак, давайте учиться вместе с этим захватывающим инструментом и открывать новые горизонты творчества и инноваций. Будущее уже здесь, и мы можем быть частью этого удивительного путешествия
Эта статья не была сгенерирована с помощью ChatGPT или какой-либо другой нейронной сети — за это можете не переживать.

23К открытий27К показов

Глава AWS Мэтт Гарман назвал замену джуниоров на ИИ «глупой идеей», подчеркнув их роль в будущем кадровом резерве и росте бизнеса

В GitHub Copilot Chat нашли уязвимость (CVSS 9.6): через промпт-инъекцию и обход CSP можно было вытянуть приватные репозитории и AWS-ключи

Топ-10 способов заработать на искусственном интеллекте. Как ИИ может приносить прибыль бизнесу и специалистам.

ИИ-ассистент, оптимизирующий клиентский сервис, для поддержки клиентов в Service Desk/Help Desk от Upservice. Обзор на нейропощника.