


Как и на чём обучить модель машинного обучения

Раскатываем модель PyTorch на двух разных сетапах: проводим тренировку и выбираем оптимальный вариант.
2К открытий13К показов

Медицина, финансы, наука, бизнес, инфобез — машинное обучение используют, кажется, все и везде. Чем больше компания, тем больше и требовательнее модели. Как следствие, дата-сайентисты должны знать, как работать с этими моделями.
В статье покажем базу, полезную для крепких джунов и более опытных специалистов: объясним, как подобрать фреймворк и железо и раскатаем ML-модель.
Выбираем фреймворк: PyTorch
PyTorch — популярный, бесплатный фреймворк. Сравнительно простой в освоении, гибкий, интегрирован с Python. То есть подойдёт большинству разработчиков, которые берутся за ML-модели. Именно на нём написаны многие современные LLM, будь то ChatGPT или Llama.
Но он довольно требователен к RAM, поэтому сегодня сравним два облачных сервера и посмотрим, насколько хорошо каждый из них справится с «жадной» до оперативы моделью.
Выбираем железо: RTXA5000 16 Гб RAM GPU: 2
Чем мощнее железо, тем выше производительность и, как следствие, выше скорость обработки данных. Но «просто арендовать лучший сервер на рынке» — сомнительный вариант: во-первых, дорого; во-вторых, не факт, что вы будете использовать его на полную мощность и не потратите деньги в никуда.
Поэтому надо сперва разобраться в характеристиках. На старте разница между предлагаемыми конфигурациями может быть не ясна. Только для одной карты на сайте облачной платформы Immers.cloud их 13.
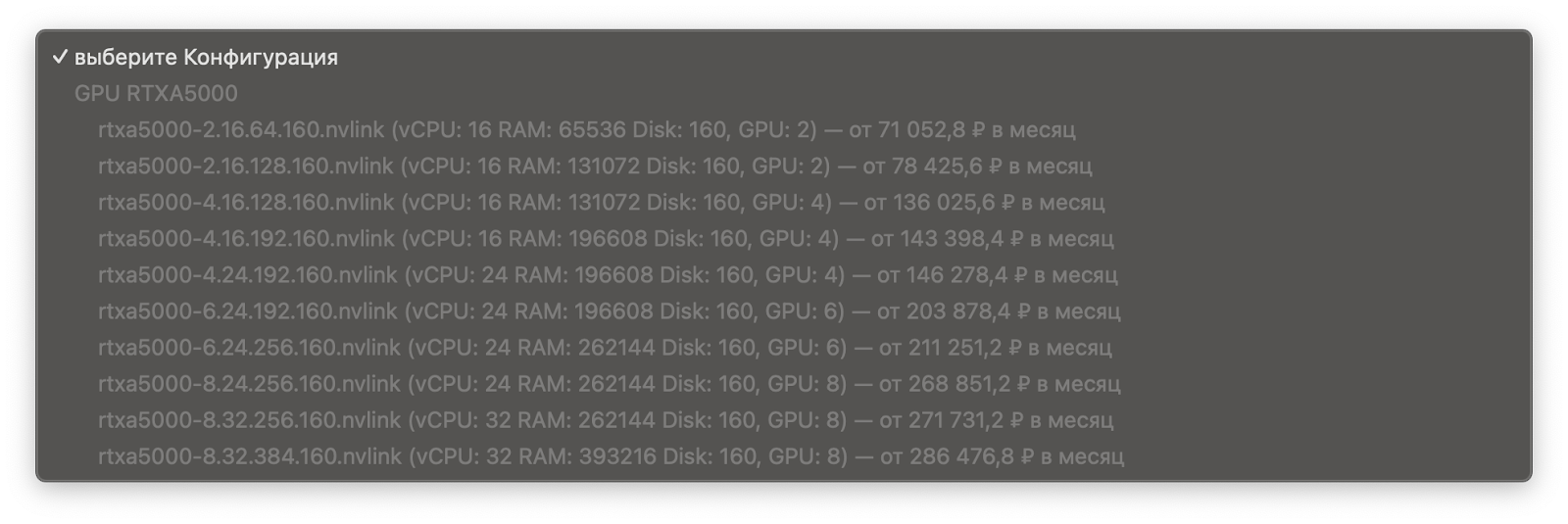
Чтобы понять, сколько ядер и Гб оперативной памяти взять, оттолкнёмся от задачи, масштабируемости облачного сервиса и цены. У нас тестовый проект и нет точных требований к железу, поэтому подойдут 8–16 Гб оперативной памяти и 2–4 ядра. Выбираем RTXA5000 на 16 Гб RAM с двумя ядрами: она полностью закрывает нашу задачу (8192 CUDA ядер позволяют выполнять тысячи параллельных вычислений одновременно) и стоит недорого. Обойдётся в 98 руб. в час, или 70 841 руб. в месяц.
Готовим рабочее окружение
Для начала создадим сервер с GeForce RTX A5000 (rtxa5000-2.16.64.160.nvlink) с Ubuntu 20.04. все дефолтные настройки оставим без изменений.
Скачиваем кред в формате .pem в разделе «Ключевые пары». Расположим его в папке проекта на своей машине, и затем, следуя инструкции по подключению для той или иной ОС, выставим права на файл.pem и зайдём на сервер:
Создадим директорию проекта:
Создадим виртуальное окружение:
Установим PyTorch:
Обучаем модель
Наполним скрипт huge_torch_model.py:
Для начала импортируем необходимые библиотеки: PyTorch и её модуль torch.nn для создания и управления архитектурой нейросетей:
Далее определим класс HugeModel (наследуется от nn.Module): в методе __init__ создается последовательность из 50 слоев с линейной активацией и добавляется функция активации ReLU для каждой пары слоёв. Метод forward определяет прямое прохождение данных через модель, то есть вычисление результирующих значений на основе ввода.
Если вы только начали изучать PyTorch, вот годная вводная статья, которая поможет разобраться с терминологией: слоями активации, ReLu, и нейросетями типа feedforward и прочим.
Создадим экземпляр модели:
Сгенерируем входные данные — случайный тензор размером 64 x 10000, где 64 — величина подаваемого за раз пакета, а 10000 — количество признаков (input_size):
Эти строки определяют, будет ли использован GPU или CPU для вычислений, и перемещают модель и входные данные на выбранное устройство. Если доступен GPU, вычисления ускорятся:
Подадим данные модели для получения результата:
Запустим скрипт:
В консоль выводятся тензоры — результаты:
Даже авторасширения RAM не потребовалось, а на обучение ушло около минуты.
Эту модель можно сразу использовать как инструмент для решения бизнес-задач. Вот несколько примеров, что можно сделать с помощью неё:
- «Суфлёр» техподдержки. Подаём базу реплик операторов и просим модель сгенерировать ответ на новый вопрос на основе нашей базы знаний:
- Расшифровка ДНК. Фичами-столбцами станут последовательности зашифрованных нуклеотидов:
- A => 1, 0, 0, 0
- C => 0, 1, 0, 0
- G => 0, 0, 1, 0
- T => 0, 0, 0, 1
- Обучение беспилотных авто. Признаками станут координаты транспорта и скорость в момент времени:

Сравниваем с Intel Xeon 2 x 3.3 ГГц CPU 16 Гб RAM
Для сравнения возьмём сервер другого провайдера: Intel Xeon, 2 ядра CPU, 8 Гб оперативной памяти. Похожие основные характеристики, но без GPU, и с картой от Intel. Настройка среды аналогична, и там, и там Ubuntu 20.04, но команда установки PyTorch выглядит так:
Запускаем модель с теми же параметрами, почти сразу получаем RuntimeError: попросту нечем удерживать такой объём данных одновременно.
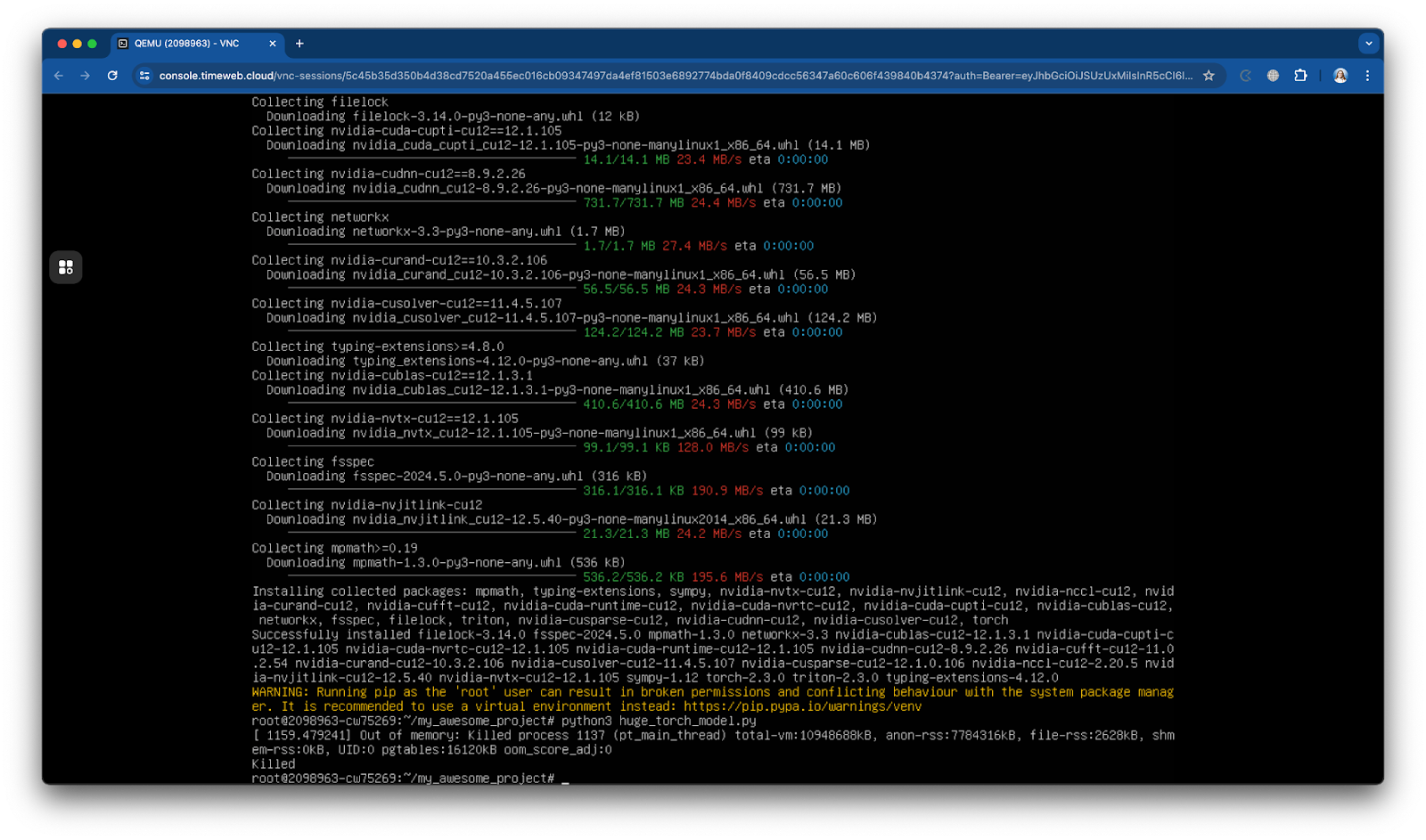
Только снизившись до input_size = 1000 и понизив число слоев до 10, укладываемся в выделенные мощности:
Обучение заняло более 20 минут даже при таком понижении
Объём передаваемых данных тоже существенно снизился:
Что в итоге
Мы сгенерировали таблицу на 10 тысяч столбцов с рандомными значениями, и попросили модель предсказать значения ряда на основании неких входных данных.
RTX A5000 справился за минут, Intel — за 20. Что повлияло на результат: в данной ситуации:
- GPU специально разрабатываются и оптимизируются для высокопроизводительных вычислений что важно для манипуляций с большими матрицами и векторизациями в ML и DL.
- CPU хорошо подходит для задач, требующих последовательных вычислений и высокой тактовой частоты, но они менее эффективны для параллельных рабочих нагрузок. Так что рассчитывать на серьёзную модель и использовать ее для решения бизнес-задач при таких параметрах нельзя.
Из двух карт только в RTX можно, например, загружать датасеты терабайтами и обучать модель для помощи представителям саппорта, генным инженерам или создателям беспилотного авто.
Immers.cloud предоставляет виртуальные GPU и CPU для работы с ИИ: обучения нейросетей, инференса и файн-тьюнинга и прочего. На сайте можно подобрать мощности по разные задачи и любой бюджет.
immers.cloud подготовил для наших читателей бонус — +20% на пополнение счёта! Регистрируйтесь и пополняйте баланс, чтобы активировать его.
Реклама, ООО «Диджитэл Тек Энд Лаб», erid: LjN8KQW4p

2К открытий13К показов