


Как нейросети меняют систему рекомендаций

Нейросети кардинально меняют рекомендательные системы — теперь они анализируют не отдельные действия, а целостный портрет человека. Разбираем революцию персонализации с экспертом AI VK.
264 открытий2К показов

Рекомендательные системы в цифровых платформах долгое время развивались обособленно, решая узкие задачи без общего представления о пользователе. Одна модель анализировала контент, другая — поведение, третья — занималась ранжированием. Такой подход не позволял системе до конца понять, что именно интересно человеку. Сегодня всё меняется: нейросети объединяют эти элементы в единую архитектуру, формируя целостную модель интересов. Вместе с руководителем рекомендаций в AI VK Андреем Зимовновым разбираемся, как новые подходы вытесняют старые и делают рекомендации по-настоящему персонализированными.

Андрей Зиминов
Руководитель рекомендаций в AI VK
Почему старые модели больше не работают
Долгие годы рекомендательные системы состояли из десятков моделей, которые решали свои узкие задачи. На финальном этапе часто использовался градиентный бустинг — метод, при котором несколько слабых моделей, например, поведенческая (лайки и просмотры) и контентная (теги и описания), объединяются в одну, более точную и устойчивую. Такой подход плохо понимал контекст и динамику интересов пользователя. Например, если человек внезапно переключался с футбольных обзоров на кулинарные видео, система не могла быстро подстроиться. Сегодня это решается переходом к нейросетевым архитектурам, которые видят картину целиком.
Как данные превращаются в рекомендации
Современные системы кодируют и контент, и действия пользователей в эмбеддинги — векторы чисел, отражающие интересы и характеристики.
- Пользовательские эмбеддинги строятся по лайкам, просмотрам, времени активности, подпискам.
- Контент кодируется по заголовкам, описаниям, тегам, обложкам, звуку и даже тону комментариев.
Главная задача эмбеддингов — отобрать подходящий контент из миллионов вариантов.
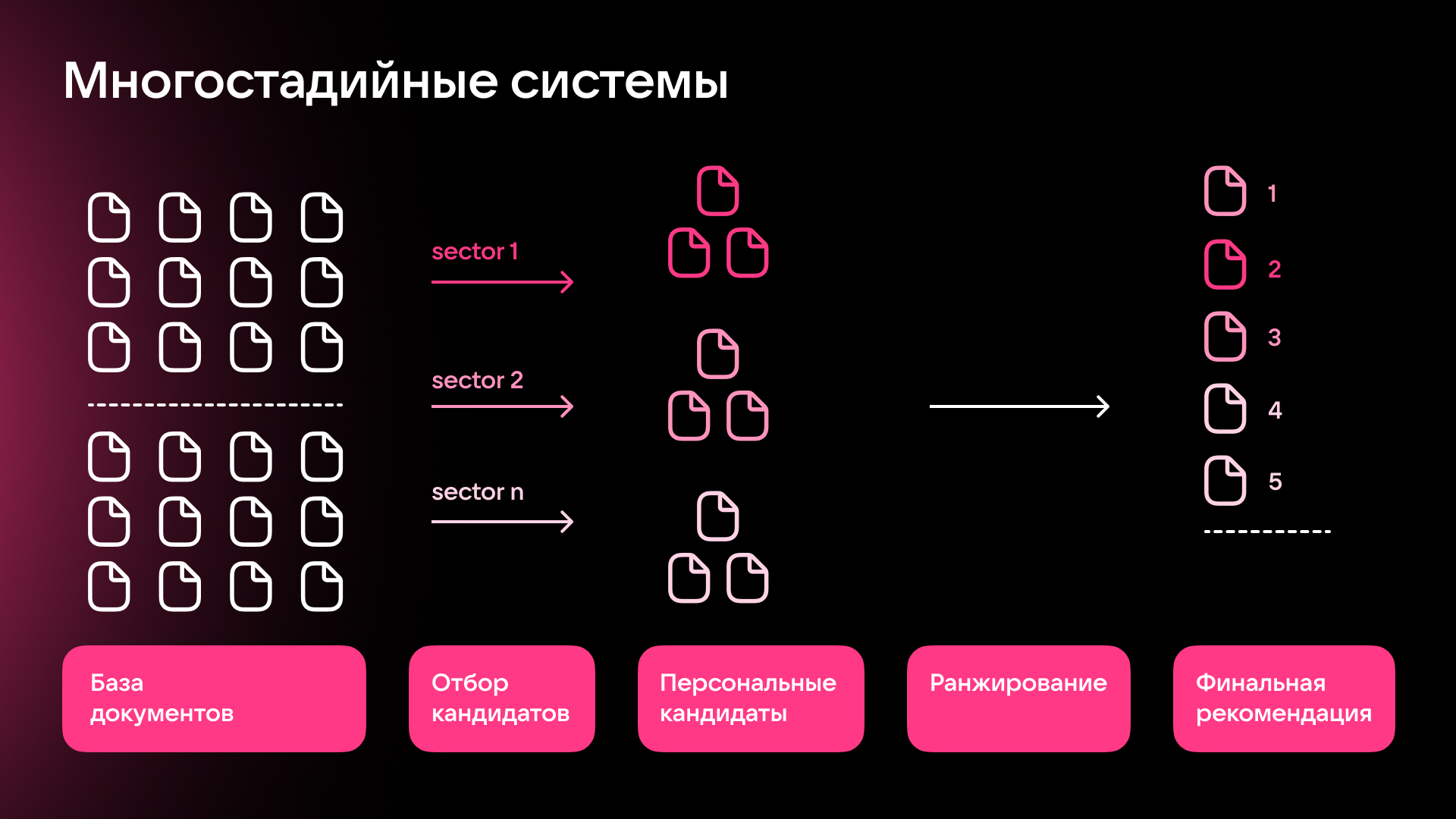
- Всё начинается с отбора кандидатов. При помощи поиска ближайших соседей ANN (approximate nearest neighbor search), реализованного через FAISS или аналоги, за миллисекунды находятся тысячи кандидатов, которые хотя бы примерно соответствуют интересам пользователя.
- После этого идёт этап предранжирования. Из тысячи кандидатов нужно выбрать пару сотен наиболее перспективных. Здесь уже работают алгоритмы градиентного бустинга, например, CatBoost или другие, выбор зависит от инфраструктуры. Они учитывают дополнительные признаки: насколько свежа публикация, насколько популярен автор, как часто пользователь взаимодействовал с похожим контентом.
- Затем наступает финальное ранжирование. Применяются глубокие нейросети, включая нейросетевые версии коллаборативной фильтрации, которые учитывают интересы похожих пользователей. Они прогнозируют, что пользователь будет делать дальше: досмотрит ли видео, поставит ли лайк или репостнёт. Здесь каждому кандидату уделяется особое внимание, ведь нужно выдать самые релевантные.
Всё это работает на единой DataPlatform, которая собирает сигналы от пользователей и обучает модели. В VK для этого есть единая Discovery-платформа, которая собирает клики, лайки, поисковые запросы и обновляет эмбеддинги.
Нейросетевой зоопарк: что стоит под капотом
В финальном ранжировании работает целая экосистема нейросетей. Это и многослойные перцептроны (MLP), и более сложные — сверточные (CNN), рекуррентные (RNN) и трансформеры.
1. Трансформеры и большие языковые модели (LLM)
Трансформеры — это тип нейросети, который умеет обрабатывать данные как последовательности. Возьмём предложение из трёх слов: «я ем Кафку». Трансформер не просто распознаёт значения отдельных слов — «я», «ем», «Кафку» — но и улавливает общий смысл фразы.
С помощью механизма self-attention он находит связи между элементами и понимает контекст. Это позволяет строить контекстные эмбеддинги — векторные представления, которые учитывают не только содержание, но и значение слов в конкретной ситуации. Так модель понимает, что в фразе «я ем Кафку» речь идёт о еде, а не о литературе.
В рекомендациях трансформеры анализируют действия пользователя как последовательность. Например, модель SASRec (Self-Attentive Sequential Recommendation), которая используется в VK, предсказывает, что может заинтересовать человека дальше, и уже даёт прирост точности на 2,5–3%.
Сильная сторона трансформеров — в умении распознавать связи между действиями пользователя, а не просто фиксировать каждое событие. Если человек будет стабильно взаимодействовать с определённым контентом, модель «поймёт», что это не случайность, и придаст этому интересу больший вес. При этом случайные действия, вроде одного нерелевантного клика, не исказят общую картину — механизм self-attention помогает отличать устойчивые паттерны от шумовых всплесков.
Трансформеры активно применяются в ранжировании, но изначально разрабатывались как универсальные архитектуры для работы с последовательностями. А вот LLM, например, T5 или GPT, обучены на текстах. Они более гибкие: их можно настраивать также через текст и встраивать в диалог. Но они пока медленнее, требуют больше ресурсов и уступают в производительности на больших потоках.
2. Мультимодальные модели
Прорывной подход в рекомендательных системах. Они обрабатывают сразу несколько форматов: текст, изображения, звук. Всё это кодируется в векторы и сводится в общее пространство — часто тоже с помощью трансформеров. Так система понимает не только ключевые слова, но и смысл контента в разных форматах. По такому принципу работает Zelda — семейство моделей и фреймворк, лежащий в основе рекомендаций VK.
Раньше всё сводилось к матрице «пользователь × объект», где система пыталась предсказать оценки. Это работало, пока человек смотрел однотипный контент. Если пользователь смотрит обзоры гаджетов, то старая модель начинает искать похожие видео — с теми же тегами. Но если видео не помечено как «техника», система может его пропустить. Когда интересы меняются, алгоритм не понимает, почему пользователь внезапно увлёкся музыкой или историей.
Мультимодальные модели считывают сам контент: текст, видео, изображение — и ищут то, что объединяет их по смыслу. Это позволяет точнее угадывать неожиданные интересы, подстраиваться под смену вкусов и работать с новым, нестандартным контентом, который раньше выпадал из поля зрения.
3. Диффузионные модели
Диффузионные модели восстанавливают «чистые» предпочтения пользователя, убирая шум вроде случайных кликов и скипов. Например, вы смотрите обзоры смартфонов и случайно кликаете на видео про косметику с маркетплейса. Вы быстро переключили обратно на видео про смартфоны, и нейросеть понимает, что произошло, и не рекомендует видео про косметику.
Диффузионные модели особенно полезны при работе с разреженными и шумными данными — например, для новых пользователей. Такие модели, как DiffRec, показывают до 10% прироста точности на сложных датасетах и постепенно начинают конкурировать с трансформерами.

Система рекомендаций продолжит меняться
Следующим этапом в развитии нейросетевых методов может стать переход к сквозным (end-to-end) архитектурам, когда одна большая нейросеть берёт на себя все функции сразу. Некоторые платформы, например, TikTok и YouTube, уже частично внедряют end-to-end пайплайны. Это снижает ошибки на промежуточных этапах и учитывает цели платформы — вовлечение и удержание.

264 открытий2К показов
Microsoft превратил Copilot в no-code платформу: теперь ИИ создает приложения и автоматизирует задачи по обычным текстовым промтам

Обзор iPhone 17 Pro: как смена дизайнерской парадигмы сделала смартфон по-настоящему профессиональным. Отказ от титана, новая система охлаждения, 48-Мп телеобъектив и чип A19 Pro — почему инженерные решения важнее внешнего лоска.

Свежий проект собрал личные сайты создателей популярных языков программирования Python, Go и Ruby в одном месте, но столкнулся с техническими трудностями, такими как высокая загрузка процессора

Как зайти в профессию в 2026: навыки, портфолио, пошаговый план входа в профессию и актуальные зарплаты по грейдам