


Как построить отказоустойчивую систему в облаке, снизить длительность простоев в год до 15 минут и уменьшить время отклика до 120 мс

Узнайте, как построить отказоустойчивую облачную инфраструктуру для IT-проекта. Вместе с экспертами Рег.облака и мебельного ритейлера «169» разбираем ключевые элементы миграции в облако — архитектурные принципы, автоматизацию процессов и мониторинг.
876 открытий4К показов

Современный бизнес, особенно отрасль e-сommerce, стремительно трансформируется, и облачные решения уже драйверы этой эволюции. Устаревшие локальные IT-системы часто не справляются с ростом данных и ожиданиями клиентов к скорости — они неэластичны, дороги и тормозят внедрение инноваций. Вместе с Сергеем Рыжковым (Рег.облако) и Русланом Лутидзе («169») разбираемся, как перенос в облако поможет не только решить технические проблемы, но и напрямую повлиять на выручку.
Когда растущий трафик интернет-магазина приводит к замедлению скорости генерации страниц и IT-архитектура с единым сервером перестает справляться, а еще учащаются DDoS-атаки, то перенос IT-проекта в облачные сервисы становится неизбежным. Именно с такой ситуацией столкнулся мебельный ритейлер «169». Изначально компания использовала для работы виртуальный хостинг и небольшие VPS-серверы, однако в связи с возникшими сложностями начала миграцию своих IT-систем в облако.
Наша проблема была типичной: локальные серверы не могли адаптироваться к всплескам трафика во время распродаж. Процедура закупки и настройки нового оборудования занимала недели, что противоречило динамике онлайн-торговли. Единственным логичным решением стала полная миграция в облако.
Настройка облачной инфраструктуры для IT-архитектуры
Чтобы справиться с проблемами производительности, компании «169» пришлось изменить подход к построению IT-инфраструктуры и внедрить четыре ключевых принципа современной облачной архитектуры.
Принцип разделения ответственности стал основой новой системы. Вместо хаотичного размещения сервисов на единой платформе была реализована четкая специализация компонентов. Под базы данных выделили мощные серверы PostgreSQL с репликацией по схеме master-slave для отказоустойчивости и производительности. Поисковые функции перенесли на отдельный кластер Elasticsearch с русскоязычной морфологией, что значительно ускорило работу с каталогом товаров. Фоновые задачи и очереди обработки вынесли на специализированные серверы с Redis и RabbitMQ — это разгрузило основные веб-ноды и повысило стабильность системы.
Далее внедрили многоуровневую систему кэширования, которая уменьшила время отклика в шесть раз. На уровне приложения настроили Redis для кэширования шаблонов и результатов API-запросов, что снизило нагрузку на базы данных. Для статического контента подключили браузерное кэширование с оптимальными сроками жизни ресурсов. Геораспределенная CDN-сеть помогла с быстрой доставкой контента пользователям из разных регионов, уменьшив задержки до минимума.
Децентрализованное хранение данных устранило проблемы с производительностью и надежностью медиаконтента. Все файлы были перенесены в S3-совместимое объектное хранилище, что позволило отделить хранение от логики приложения. Для безопасного доступа к приватным ресурсам реализовали механизм presigned URL с ограниченным временем жизни. Автоматизация управления данными через lifecycle-правила упростила процессы архивирования и удаления устаревших файлов, снизив затраты на хранение.
Также важным элементом стала полная автоматизация процессов. Внедрили CI/CD на базе GitLab с автоматическим тестированием каждого коммита — это в разы ускорило вывод новых функций на прод. Система мониторинга на Prometheus и Grafana с продуманными алертами позволила оперативно реагировать на инциденты до их влияния на пользователей. Сейчас автоматическое масштабирование ресурсов по метрикам нагрузки позволяет вести бесперебойную работу даже в периоды пикового трафика, экономя ресурсы в спокойные периоды.
Мы предоставили ритейлеру отказоустойчивую и масштабируемую облачную инфраструктуру, которая позволила не только мгновенно реагировать на всплески трафика, но и значительно повысить безопасность и производительность ключевых сервисов. Облачная платформа Рег.облако стала надежным фундаментом для роста бизнеса.
В таблице представлены технические характеристики основных нод, развернутых в инфраструктуре Рег.облака.
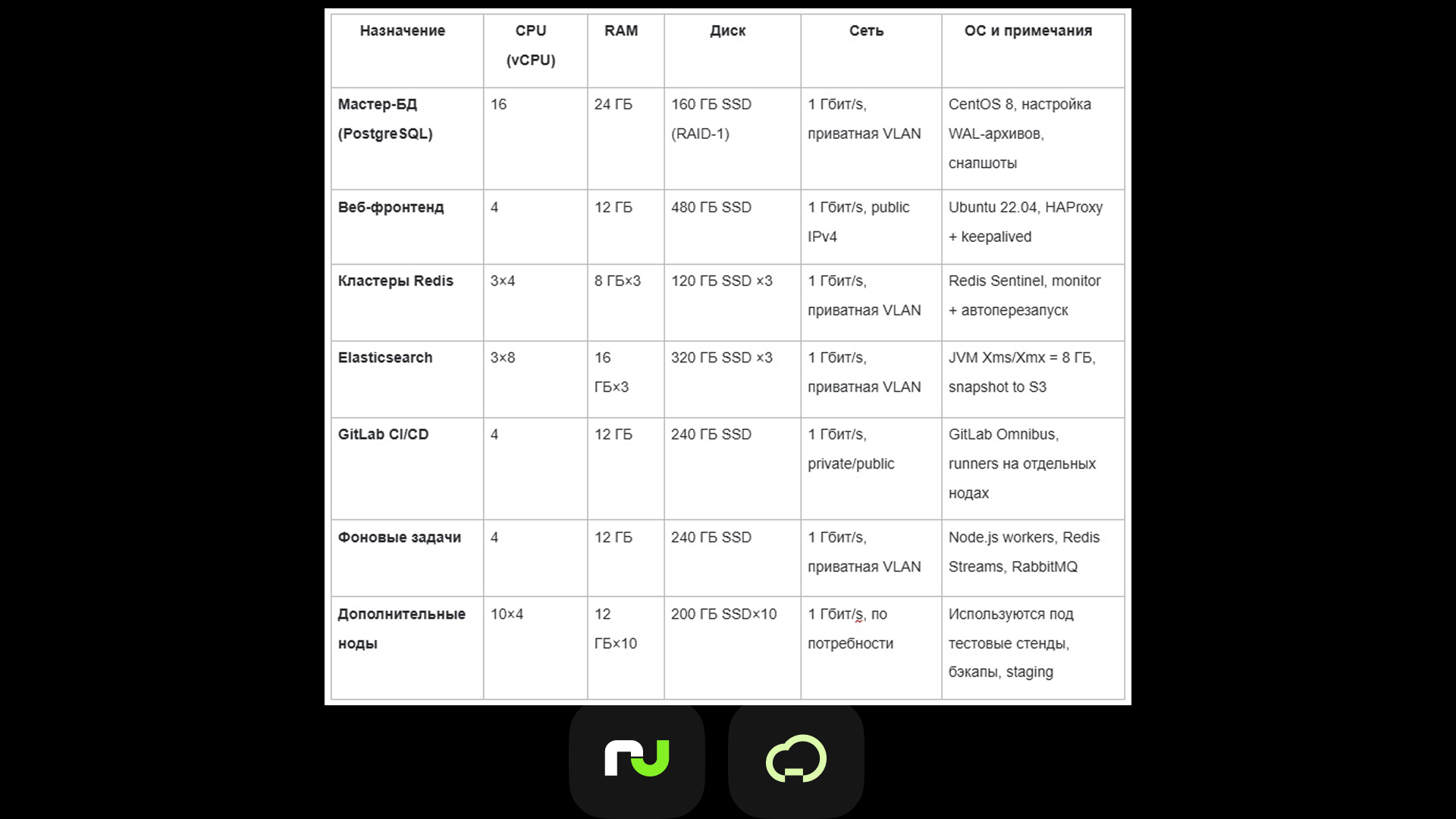
Технические результаты
Распределенная IT-архитектура с балансировкой нагрузки и резервированием критических компонентов помогла компании добиться выдающихся показателей отказоустойчивости. Среднее время простоя сервисов сократилось до менее 15 минут в год — это соответствует уровню доступности 99,98%. Существенно улучшилась и производительность: время отклика IT-системы уменьшилось в 6 раз — с 800 мс до 120 мс, а полная загрузка страниц стала занимать 200–250 мс. Эти улучшения не только повысили удовлетворенность пользователей, но и положительно сказались на SEO-показателях проектов.
Инфраструктура продемонстрировала высокую эластичность — в период пиковых нагрузок, например при распродажах, развертывание пяти дополнительных инстансов занимает менее 10 минут без прерывания работоспособности сервисов. Кроме того, технические изменения повлияли на бизнес-метрики и помогли увеличить конверсию и оборот, а также сократить операционные расходы.
Исходный план был реализован полностью, но в процессе мы усилили архитектуру несколькими важными корректировками: перешли на выделенные серверы для кластера БД из-за ограничений по приватным сетям, внедрили ELK-стек для централизованного логирования, развернули трехнодовый кластер Redis для кэширования, глубоко интегрировали CI/CD с Terraform и Ansible, подключили облачное S3-хранилище для медиаконтента и усилили защиту Anycast-DNS. Эти изменения позволили добиться максимальной отказоустойчивости и снизить нагрузку на бэкенд даже в пиковые периоды.
Создание отказоустойчивой облачной инфраструктуры — сложная задача, где от технических решений напрямую зависят бизнес-результаты. Как показывает практика, инвестиции в эластичную, автоматизированную и безопасную платформу окупаются не только за счет снижения эксплуатационных расходов, но и благодаря повышенной надежности, которая защищает репутацию компании и увеличивает доходы.

876 открытий4К показов

Выясним, где лучше развернуть бота, подключимся к облаку через CLI, осуществим деплой нашего бота в облако при помощи фреймворка serverless.
Инструменты DevOps, которые упрощают рабочие процессы и ускоряют труд инженеров. Топ-10 популярных платформ разного направления.

Паттерны проектирования архитектуры ПО. Показываем виды паттернов и их особенности. Рассматриваем пошаговую инструкцию и основные нюансы ✔ Tproger

Собрали всё, что нужно DevOps-инженеру: CI/CD, Kubernetes, серверлесс, безопасность, мониторинг и альтернативы Docker — практично и по делу.