Как прокачать свой SQL до уровня больших данных
Простое объяснение парадигмы MapReduce. Её понимание поможет вам писать эффективные SQL-запросы для работы с большими данными.

Чем отличается SQL в больших данных от обычного SQL? В больших данных используются распределённые вычисления.
Вычисления распределяются между несколькими серверами. Одна база данных находится сразу на нескольких серверах. Результат запроса тоже вычисляется одновременно несколькими серверами. Алгоритмы распределённых вычислений описывает парадигма MapReduce. Давайте разберём, на что это влияет и как прокачать свой SQL до уровня больших данных.
Предупреждение: в данной статье рассматриваются канонические архитектуры обработки данных. Многие современные СУБД и фреймворки построены на их основе и содержат в себе множество доработок и улучшений. Однако набор оптимизаций может отличаться. Поэтому реальная обработка данных на вашем проекте может отличаться в лучшую сторону благодаря именно вашему инструменту. Важно понимать, какие именно оптимизации способен выполнять ваш фреймворк, чтобы правильно контролировать эффективность алгоритмов.
Основы парадигмы MapReduce
Первое, что следует держать в голове, — в больших данных почти любая БД хранит данные на нескольких серверах.
Представим, что у нас есть 3 сервера и таблица клиентов. Вся таблица равномерна распределена на 3 части, каждый сервер хранит 1/3 данных. Чтобы вернуть результат запроса, нужно прочитать каждую часть с каждого сервера и собрать всё на одном сервере, где мы просматриваем результат.
Простейший SQL-запрос:
SELECT * FROM CLIENTS
Даже такой простой запрос разбивается на три обязательные части MapReduce:
- Map
- Shuffle
- Reduce
Каждая из этих операций по-разному распределяется и параллелится, поэтому важно понимать, что они собой представляют.
- Стадия Map зачастую представляет собой обычное чтение с жёсткого диска. Кроме чтения здесь могут применяться однострочные трансформации и фильтры, т.е. операции без join, group by, order by, distinct и без агрегирующих функций. Операции на этой стадии всегда хорошо параллелятся и не создают нагрузку на БД, т.к. каждый сервер читает только ту часть данных, которая имеется у него на жёстком диске. Данные зачастую сохранены равномерно на каждом сервере. Все серверы участвуют в этой стадии и делят нагрузку равномерно.
- На стадии Shuffle никаких вычислений не происходит, зато все данные перемещаются между серверами таким образом, чтобы из них можно было получить финальный результат на стадии Reduce. Этот шаг станет понятен только после погружения в стадию Reduce, поэтому перейдём к ней.
- Стадия Reduce самая коварная, т.к. она может провоцировать большие проблемы с производительностью БД. Здесь происходят все группирующие операции, а также операции, которые записывают результат. Некоторые операции не могут выполняться одновременно на нескольких серверах, поэтому для их выполнения требуется собрать весь объем данных на одном сервере. Если данные не помещаются на один сервер, запрос всегда будет выдавать ошибку.
Подробнее разберём на примерах ниже.
Как писать эффективные SQL-запросы
Вернемся к запросу:
SELECT * FROM CLIENTS
Здесь мы получим равномерное чтение таблицы на трёх серверах. Но что делать с результатом? Если мы захотим вывести его на экран, результат должен быть собран на один сервер, с которого мы выполняем запрос. Получается, что наш последний шаг вывода на экран сводит распределённые вычисления на нет — вся финальная нагрузка придётся на наш сервер, где мы получаем результат.
Стадия Map будет распределённой. Далее последует стадия Shuffle, которая перекинет все данные на один финальный сервер, который должен будет вместить весь результат и вывести его на экран. Если данные настолько большие, что не помещаются на один сервер, даже такой простейший запрос никогда не выполнится. Результирующий сервер всегда будет возвращать ошибку Out of memory.
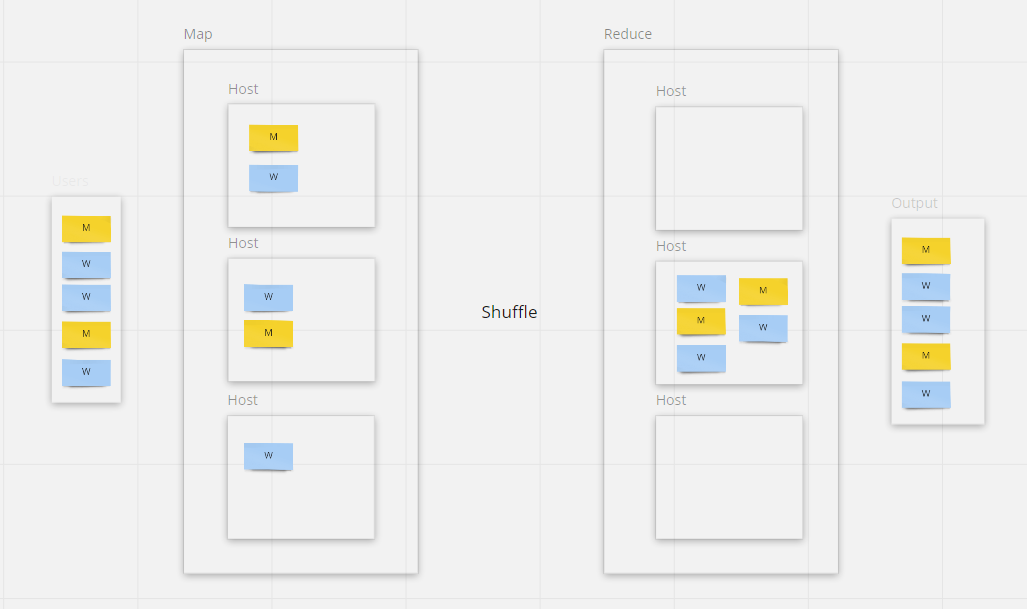
Этот запрос можно достаточно легко изменить:
INSERT INTO CLIENTS_NEW SELECT * FROM CLIENTS
Теперь вместо вывода результата на экран результат будет записан в другую таблицу. Поскольку другая таблица также хранится распределённо, запись могут производить одновременно 3 сервера.
Таким образом, не потребуется собирать все данные в одном месте, все вычисления будут хорошо распределяться. Стадия Map будет хорошо параллелиться, однако теперь стадия Reduce (запись результата) будет выполняться распределённо на тех же серверах, где данные и были прочитаны. Значит, мы можем пропустить стадию Shuffle (не передавать данные между серверами перед записью результата), что тоже ускоряет вычисления.
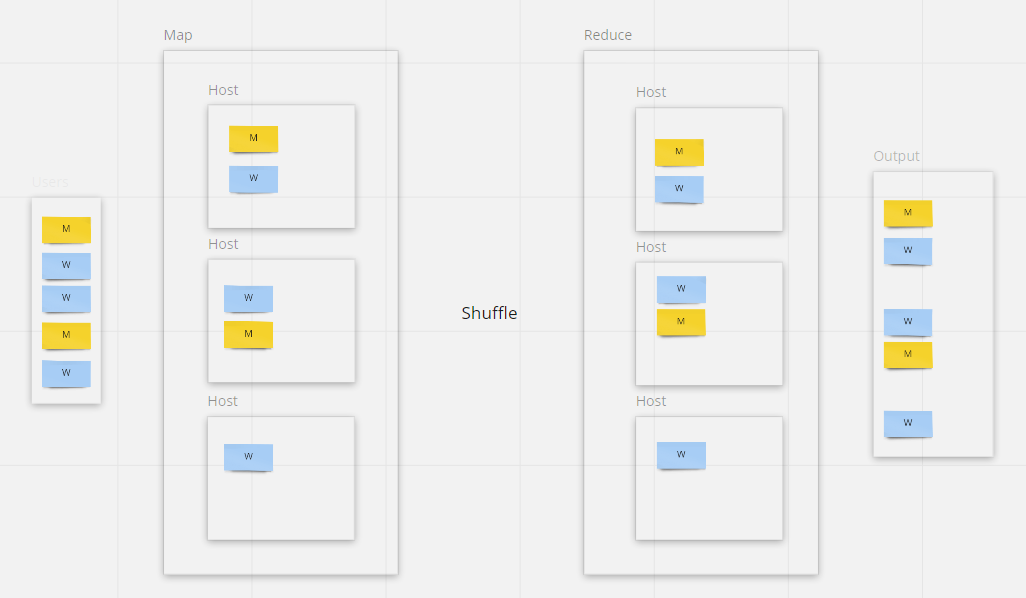
Аналогичная логика применима к операциям с фильтрами, такими как SELECT * FROM CLIENTS WHERE CLIENTS.GENDER = 1 и так далее. Такие фильтры также будут выполняться распределённо на стадии Map.
Операции с агрегациями
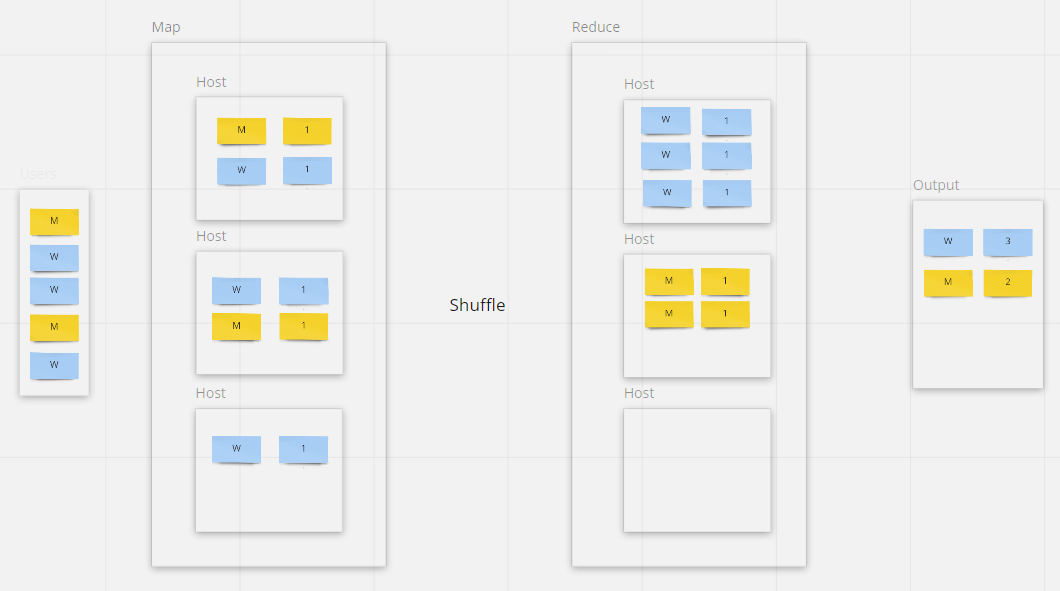
Рассмотрим теперь операции с агрегациями. Допустим, мы хотим посчитать количество клиентов по полу.
SQL-запрос такой:
SELECT COUNT(*) FROM CLIENTS GROUP BY CLIENTS.GENDER
Стадия Map без сюрпризов, снова параллельное чтение тремя серверами. А вот Reduce всё меняет.
Поскольку у нас есть группировка по полу, в ответе мы хотим увидеть два числа — количество мужчин и количество женщин. Значит, на стадии Reduce мы можем задействовать максимум два сервера. Один сервер должен считать всех мужчин, другой — всех женщин. Для этого на стадии Shuffle необходимо передать записи всех мужчин на один сервер, а записи женщин — на другой сервер. Тогда на этапе Reduce результирующим серверам останется только посчитать все записи, полученные на этапе Shuffle.
Мы видим, что Reduce распределяет вычисления в зависимости от группирующих функций. Такая логика применяется для всех агрегатных функций, distinct, join (где группировка идет в зависимости от условия join) и для сортировок.
С сортировкой нужно быть особенно аккуратным. Чтобы отсортировать все записи без группировки по ключу, Reduce соберёт все записи на один сервер и будет производить сортировку нераспределённо. Поэтому нужно избегать операций, которые выполняются с неравномерной группировкой (когда группирующих ключей меньше, чем доступных серверов).
Теперь вы знаете, на что нужно обращать внимание при написании запросов к большим данным. Ключ к написанию эффективного запроса — наблюдение за потребляемыми ресурсами БД в зависимости от изменения вашего запроса. Меняйте порядок join, группировок, подзапросы и ищете наилучшее сочетание производительности / нагрузки. Удачи!
Узнали для себя что-то новое о работе с большими данными?

