


Как работает балансировка нагрузки

Как балансировщики нагрузки распределяют HTTP-запросы между серверами. Рассматриваем подходы: от простых базовых алгоритмов до больших современных решений.
735 открытий4К показов

Это перевод зарубежной статьи с сайта samwho.dev. Предлагаем обсудить ее в комментариях.
Веб-приложения рано или поздно перерастают один сервер. Чтобы продолжить работу, компаниям нужно повысить отказоустойчивость, масштабируемость. А лучше — и то, и другое.
Отличное решение — развернуть приложение на нескольких серверах, а перед ними поставить балансировщик нагрузки. Он будет распределять входящие запросы, которые в больших компаниях приходят тысячами. Именно от балансировки зависит, упадёт система на пике или сохранит работоспособность.
В статье расскажем, как балансировщики нагрузки распределяют HTTP-запросы между серверами. От простых алгоритмов до современных решений.
Визуализируем проблему
Начнём с простого: один балансировщик отправляет серверу один запрос в секунду. По мере обработки сервером каждый запрос «уменьшается в размере». Для многих веб-сайтов такая схема отлично работает. Мощные современные серверы обрабатывают множество запросов. Но что будет, если они перестанут справляться?
При скорости 3 RPS часть запросов отбрасывается. Если новый запрос приходит на сервер в момент, когда тот уже обрабатывает другой, сервер его отклонит. Пользователь получит ошибку — этого нужно избегать. Исправить ситуацию можно, добавив ещё один сервер в пул нашего балансировщика нагрузки. Ура, запрос принят! Балансировщик отправляет по очереди запрос каждому серверу. Это называется балансировкой, циклическим перебором или «round robin». Один из самых простых и действенных способов балансировки нагрузки. Он хорошо работает, когда серверы имеют одинаковую мощность, а запросы примерно одинаково затратны.
Когда round robin не подходит
На практике серверы редко имеют одинаковую мощность, а запросы требуют одинаковых ресурсов. Даже при идентичном оборудовании производительность может меняться.
Посмотрим, что произойдет, когда «стоимость» запросов отличается. В примере ниже запросы не равны по «цене»: это видно по тому, что одни уменьшаются (обрабатываются) дольше других.
Большинство запросов обрабатывается успешно. Но некоторые теряются. Очереди помогают справляться с неопределённостью, но это компромисс. Мы будем терять меньше запросов, ценой увеличения задержки у части из них.
Если понаблюдать за симуляцией, запросы немного меняют цвет. Чем дольше они не обрабатываются, тем темнее становятся.
Из-за различий в «стоимости» запросов в работе сервера происходит дисбаланс: накапливаются очереди. Накапливаются на тех серверах, которым не повезло, и подряд досталось несколько «дорогих» запросов. Если очередь заполнена, такой запрос будет отброшен.
Проблема сохраняется на серверах с разной мощностью. Маломощная часть железа быстро перегружается и начинает отбрасывать запросы. При этом более производительное оборудование простаивает. Этот сценарий показывает основную слабость round robin — колебания. Однако round robin всё равно остаётся стандартным методом балансировки HTTP-нагрузки для nginx.
Как улучшить round robin
Улучшить round robin балансировку можно с помощью алгоритма «взвешенного циклического перебора» или «weighted round robin». Так он лучше будет справляться с вариативностью.
Как он работает: разработчики присваивают каждому серверу вес. Определяется, сколько запросов в секунду потянет сервер. В симуляции мы используем известное значение мощности сервера — вес. И, проходя по пулам, отдаём более мощным серверам больше запросов.
Хотя такой подход лучше справляется с разбросом мощности серверов, чем обычный round-robin, нам всё ещё приходится иметь дело с вариативностью «стоимости» запросов. Тактика «поручать людям вручную выставлять веса» быстро перестаёт работать. Свести производительность сервера к одному числу сложно и требует аккуратного нагрузочного тестирования на реальных сценариях. Это делают редко, поэтому другой вариант взвешенного round-robin вычисляет веса динамически, используя прокси-метрику задержку (latency).
Логично, что если один сервер обрабатывает запросы в три раза быстрее другого, скорее всего, он действительно в три раза быстрее и должен получать в три раза больше запросов.
Разметим каждый сервер и покажем среднюю задержку трёх последних обработанных запросов. Отправляем 1, 2 или 3 запроса каждому серверу на основе относительного различия в задержках.
Результат схож с weighted round robin. При этом не нужно заранее указывать вес каждого сервера. Алгоритм адаптируется к изменениям производительности со временем. Это называется «динамический взвешенный round robin».
Осталось понять, как метод справится с мощными колебаниями в мощности серверов и стоимости запросов.
Уходим от round robin
Динамически взвешенный round robin хорошо учитывает колебания мощности сервера и затрат на запросы. Но можно решить задачу элегантнее и проще. Применим балансировку по принципу «наименьшего количества соединений» — least connections.
Балансировщик нагрузки находится между сервером и пользователем. Он отслеживает, сколько незавершённых запросов у каждого сервера. При поступлении нового запроса балансировщик знает, какие севера менее загружены, и отдаёт приоритет им.
Этот алгоритм просто реализовать, он отлично работает вне зависимости от степени вариативности, избавляет от неопределённости и точно вычисляет нагрузку каждого сервера. Поэтому метод — стандарт балансировки HTTP-нагрузки в балансировщиках AWS и применяется как опция в nginx. Как и в других подходах, не удаётся избавиться от потерь запросов. Но единственный случай, когда он отбрасывает запросы, — это когда буквально не остаётся места в очереди. Он гарантирует использование всех доступных ресурсов, и потому — отличный выбор по умолчанию для большинства рабочих нагрузок.
Оптимизируем latency (задержки)
Потерянные запросы — это очень плохо, и мы стараемся их избежать. Цель неплохая, но это не та метрика, под которую чаще всего стоит оптимизировать HTTP-балансировщик.
Чаще нас волнует задержка (latency). Она измеряется в миллисекундах — от момента создания запроса до момента его обслуживания. В этом контексте принято говорить о разных перцентилях. Например, 50-й перцентиль (он же медиана) — это такое значение в миллисекундах, ниже которого находится 50% запросов и выше — тоже 50%.
Запускаем три симуляции с одинаковыми параметрами на 60 секунд. Каждую секунду снимаем метрики. Симуляции отличаются только алгоритмом балансировки. Давайте сравним медианы для каждой.
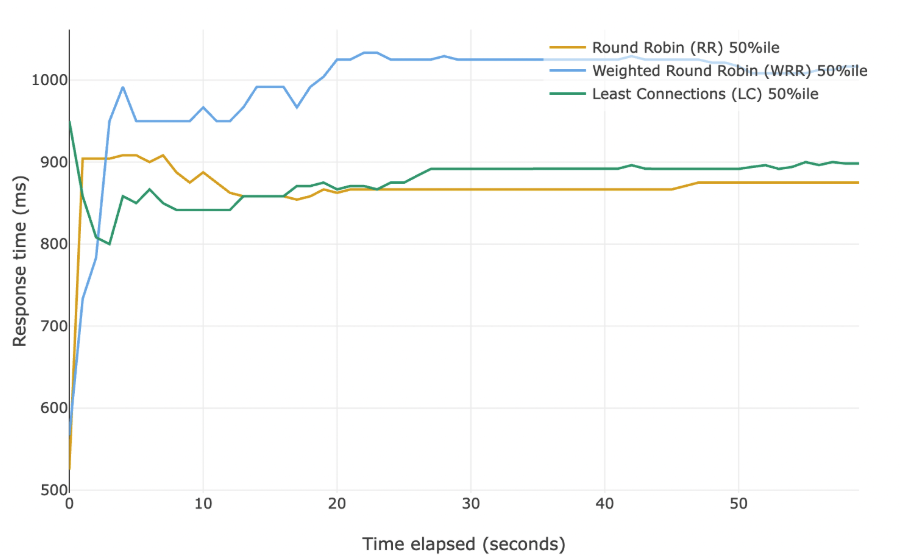
На графике перцентилям внутри одного алгоритма не назначены разные цвета. Более высокие перцентили всегда расположены выше.
Возможно, неожиданно, но у round-robin лучшая медианная задержка. Если смотреть только на этот показатель, мы упустим общую картину. Давайте посмотрим на 95-й и 99-й перцентили.
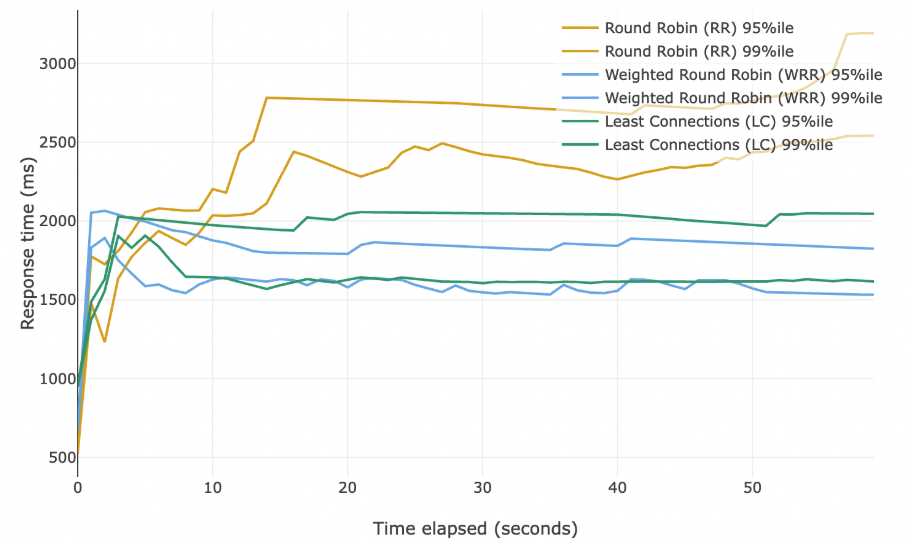
Мы видим, что round-robin показывает слабые результаты в верхних перцентилях. Как так получается, что у него отличная медиана, но плохие 95-й и 99-й перцентили?
При round-robin состояние серверов не учитывается, поэтому немало запросов попадает на простаивающие серверы — отсюда низкий 50-й перцентиль (медиана). Но с той же лёгкостью запросы отправляются и на перегруженные машины — поэтому 95-й и 99-й перцентили ухудшаются.
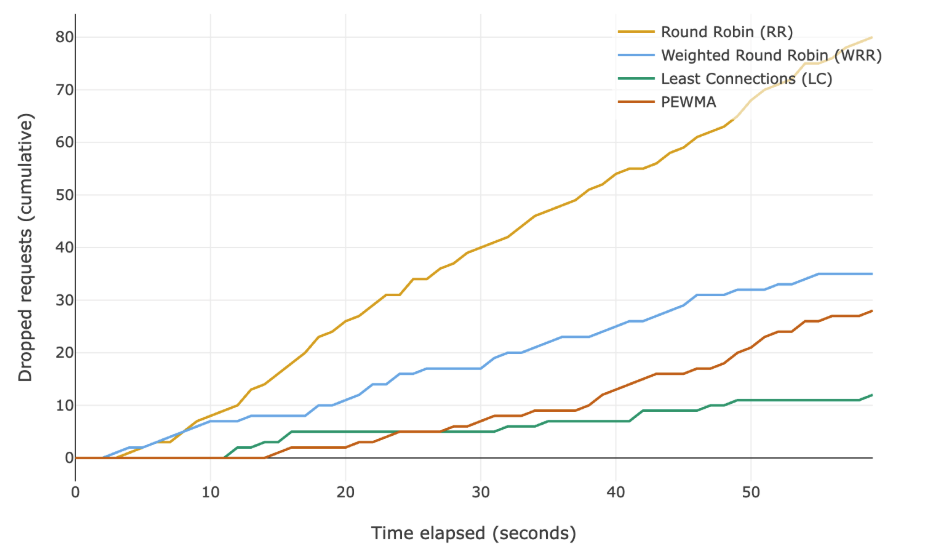
Выбираем параметры симуляций, чтобы избежать отбрасывания запросов. Это гарантирует сравнение одинакового количества наблюдений для всех трёх алгоритмов. Запустим симуляции с увеличенным значением RPS (запросов в секунду) и доведём все алгоритмы до предела. Ниже — график накопленного числа отброшенных запросов во времени.
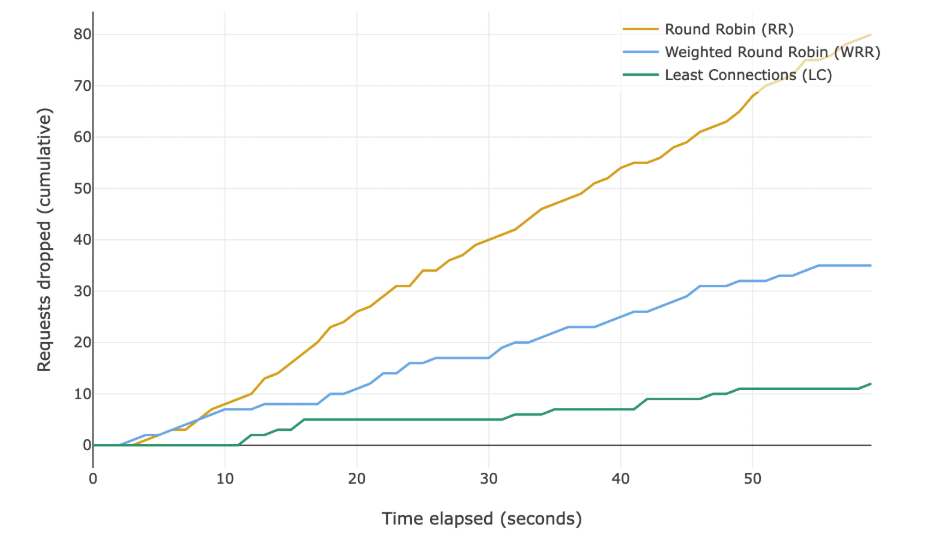
Балансировка по наименьшему числу подключений справляется с перегрузками лучше всех, но ценой более высокой задержки на 95-м и 99-го перцентили. В большинстве случаев это приемлемый компромисс.
Применяем ещё один алгоритм
Если мы действительно хотим оптимизироваться по задержке, нам нужен алгоритм, который прямо учитывает latency. Было бы здорово объединить динамический взвешенный round-robin с least connections: чувствительность к задержке первого и устойчивость второго.
Возьмём плюсы от обоих подходов и попробуем избавить от минусов.
Такая идея возникла не впервые. Существует алгоритм Peak Exponentially Weighted Moving Average «пикового экспоненциально взвешенного скользящего среднего» или PEWMA. Название длинное и сложное, но принцип понятный.
Подбираем для симуляции конкретные параметры, гарантирующие демонстрацию ожидаемого поведения. Если присмотреться, алгоритм спустя время перестаёт отправлять запросы самому медленному левому серверу. Он понимает, что остальные серверы быстрее, и нет необходимости повышать задержку, работая с маломощным сервером.
Как он это делает? Комбинирует приёмы из динамического взвешенного round-robin и из least connections, а сверху добавляет щепотку собственной «магии».
Для каждого сервера алгоритм отслеживает задержку последних N запросов. Вместо того чтобы считать среднее, он суммирует значения с экспоненциально убывающим коэффициентом. В итоге, чем старее измерение задержки, тем меньше оно влияет на сумму; свежие запросы влияют сильнее, чем давние. Полученное значение умножается на количество открытых подключений к серверу. Результат использует, чтобы выбрать, на какой сервер отправить следующий запрос. Меньше — лучше.
Сначала посмотрим на 50-й, 95-й и 99-й перцентили в сравнении с данными для least connections из предыдущей части.
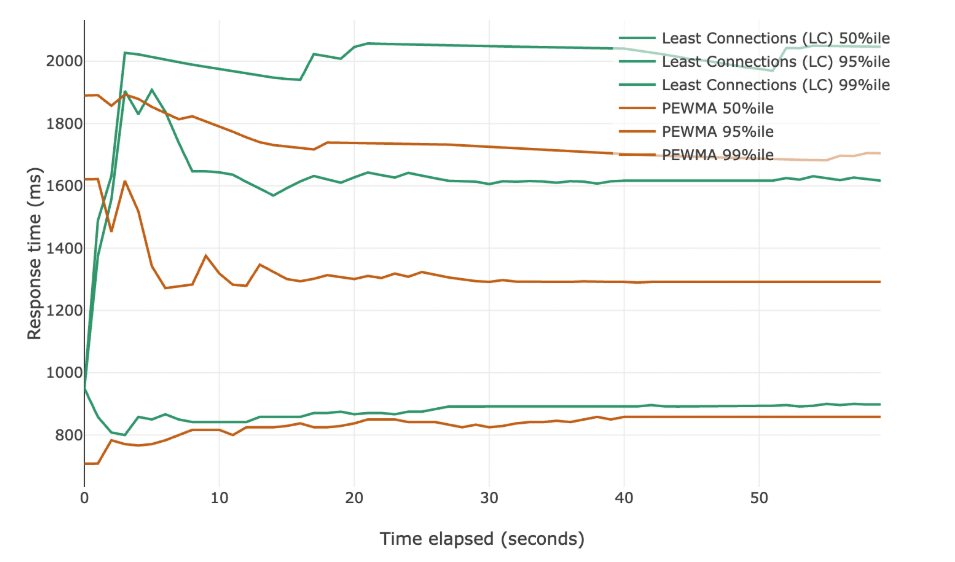
Мы видим заметное улучшение по всем метрикам! Оно особенно выражено на верхних перцентилях, но стабильно присутствует и на медиане. Ниже те же данные показаны в виде гистограммы.
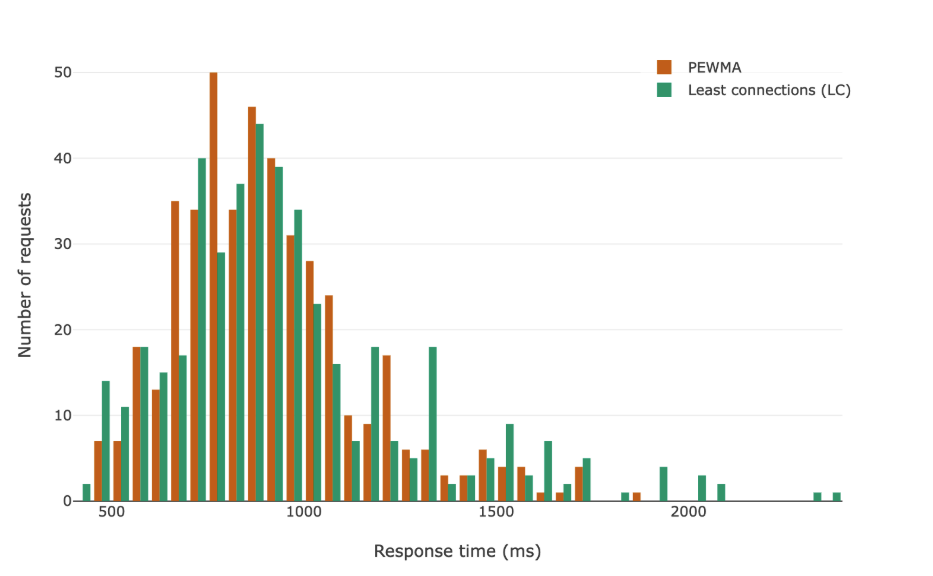
А что насчёт потерянных запросов?
Сначала он показывает лучшие результаты, но со временем начинает уступать least connections. Это логично: PEWMA стремится к наименьшим задержкам, и из-за этого иногда оставляет сервер недозагруженным.
К тому же, у PEWMA много настраиваемых параметров. Реализация, приведённая в этой статье, использует конфигурацию, хорошо показавшую себя в протестированных сценариях; дополнительная тонкая настройка может дать результаты лучше, чем у least connections. Но это и минус PEWMA по сравнению с least connections: большая сложность.
Заключение
Цель этой статьи — получить хотя бы интуитивное понимание методов балансировки нагрузки между серверами и найти решение, которое можно применять в различных ситуациях.
Всегда стоит измерять нагрузку на конкретном проекте. Не воспринимайте советы из интернета как панацею. В симуляциях игнорируются реальные ограничения — медленный запуск сервера, сетевые задержки. Они только демонстрируют свойства каждого алгоритма.
Подведём итоги:
- Round robin (циклический перебор) — самый простой алгоритм, который отправляет запросы по очереди каждому серверу. Хорошо работает только при одинаковой мощности серверов и одинаково затратных запросах. Имеет лучшую медианную задержку, но плохие высокие перцентили.
- Weighted round robin (взвешенный циклический перебор) — учитывает мощность серверов через веса, которые задают разработчики. Требует ручной настройки и тщательного тестирования. Не адаптируется к изменениям производительности.
- Dynamic weighted round robin (динамический взвешенный циклический перебор) — самостоятельно определяет веса серверов по задержке ответов. Адаптируется к изменениям производительности со временем. Хорошо справляется с колебаниями мощности и стоимости запросов.
- Least connections (наименьшее количество соединений) — отправляет запросы на сервер с наименьшим количеством активных соединений. Метод простой и эффективный. Он использует все доступные ресурсы. Стандартный метод в AWS, опция в nginx.
- PEWMA (пиковое экспоненциально взвешенное скользящее среднее) — самый сложный алгоритм, оптимизирует задержку, учитывая историю ответов с экспоненциально убывающим весом и текущую нагрузку. Лучшие показатели задержки во всех перцентилях, но его сложнее настроить. Метод также может сбоить при перегрузках.
В оригинале статьи на английском можно испытать симуляцию и в реальном времени выставлять различные параметры, чтобы посмотреть, как сервер будет вести себя под нагрузкой.

735 открытий4К показов

В России обнаружен новый вирус-троян, который имитирует банковские пуш-уведомления и заставляет пользователей передавать личные данные мошенникам

Где популярность, там и особый интерес злоумышленников. Не обошло это правило и тапалку Hamster Kombat, чьи пользователи столкнулись со взломом хакеров

Узнайте, почему программисты хватаются за голову в кинотеатре: разбор нелепого кода, фантазий про "хакера-одиночку" и нарушение законов физики в фильмах. Примеры из "Матрицы", "Мистера Робота" и других хитов с экспертной оценкой. Готовы посмеяться над Голливудом?
Google DeepMind анонсировала Genie 2 — искусственный интеллект, который превращает текстовые описания в полноценные 3D-окружения