Как TanStack Query ускоряет работу с API и сокращает код
Использование TanStack Query дает разработчикам возможность упростить работу с API, сократить дублирование кода и ускорить разработку. Рассказываем о проблемах, связанных с использованием API, и соответствующих решениях для повышения эффективности разработки.

Представьте: вы — фронтенд-разработчик, и постоянно сталкиваетесь с рядом проблем. Еще один endpoint, еще один запрос, еще десяток строк почти идентичного кода. Вручную прописываете типы, парсите ответы, обрабатываете ошибки, обновляете кэш… А через неделю бэкенд-команда меняет API — и все, что вы строили, рассыпается как карточный домик.
Так случалось, пока не появились инструменты вроде TanStack Query и не родились «обертки», которые уменьшают объемы рутины. Как перестать тонуть в запросах на разработку API и начать дышать свободно, рассказывает Дмитрий Скляр, старший разработчик компании Axenix.
API: нервная система цифрового мира
В современном ИТ-ландшафте API давно перестал быть просто техническим термином. Теперь он — один из столпов, на котором держится цифровая цивилизация.
Философия современной разработки давно сместилась от принципа «сделай все сам» к парадигме «собери из лучших компонентов». API стал языком, на котором взаимодействуют цифровые сервисы. Он превратил ИТ-ландшафты и интернет из собрания разрозненных приложений и сайтов в единую живую экосистему, где каждый элемент может взаимодействовать с другим.
Когда разработчик использует API картографического сервиса, ему не нужно разбираться в геоданных или алгоритмах прокладки маршрутов — он просто отправляет запрос и получает готовое решение. Это похоже на то, как мы пользуемся электричеством: не нужно понимать, как работает электростанция, чтобы включить свет в комнате.
Но настоящую революцию API совершил в бизнесе, создав целые экосистемы цифровых услуг. Такие компании, как Stripe, Twilio или Plaid построили свои империи именно на API, предоставляя другим разработчикам готовые «кирпичики» для создания финансовых, коммуникационных или аналитических сервисов.
Внутри крупных компаний API выступают в роли «дипломатов» между микросервисами и ИТ-системами, позволяя разным командам работать независимо, но при этом сохранять общую согласованность. Когда маркетинговая система запрашивает данные о продажах, а сервис логистики получает информацию о новых заказах — все это происходит через четко определенные API-контракты, которые делают сложные системы управляемыми и гибкими.
Боль, которую никто не замечает
Но не все так просто и далеко не так радужно.
Да, формально API — это универсальный мост, например, между фронтендом и бэкендом. На практике же он часто напоминает шаткую подвесную конструкцию: данные приходят в разном формате, документация устаревает еще до релиза, а поля user_name и username существуют одновременно просто потому, что «исторически сложилось».
Типичный сценарий: вы пишете код для запроса списка товаров, все типизируя и описывая модели — 50 строк. Добавляете фильтрацию — еще 30 строк. А через месяц бэкенд меняет структуру ответа, забывает предупредить — и вы тратите день на поиск багов в трех разных местах. И самое обидное: 80% этого кода — копипаст. Проверка ошибок, трансформация данных, инвалидация кэша — все одно и то же, но плодится как вирусы.
Сюда можно добавить также сложность поддержки — API меняется, код устаревает.
Другой момент: код для каждого API-метода имеет схожую структуру. Повторяются основные шаблоны, а различия лишь в типах данных и отдельных деталях. Чем больше API-методов, тем сложнее отслеживать изменения в коде и поддерживать его в актуальном состоянии.
В итоге — дублирование кода, которое усложняет приложение, снижает его читаемость и замедляет разработку новых функций. Документация? Либо устарела, либо ее вообще не писали.
Спасение — в системе
Однажды наши разработчики устали писать однотипные хуки, чинить сломанные запросы и объяснять новичкам, что где находится, почему именно так это работает и почему нельзя просто взять и использовать что-то другое. Устали писать однотипный код для каждого запроса, захотели минимизировать ошибки и ускорить разработку, а также сделать работу с API более структурированной и понятной. Также у команд назрела потребность в скорейшем включении в проект новых разработчиков. Для всех этих задач подходит одно решение: унифицированный подход к API, который также наводит порядок в данных и отчетах, упрощая аналитику и логику приложения.
Тогда и родилась идея фабрики API — слоя абстракции, который скрывает рутину. Для этого мы привлекли возможности TanStack Query, семейство библиотек для управления состоянием данных (data fetching) в клиентских приложениях. Помимо TanStack Query (ранее React Query), к этому классу инструментов также относятся: RTK Query (из Redux Toolkit), Apollo Client (для GraphQL) и SWR.
Их общая философия: «делать рутину невидимой для разработчика». Рассмотрим Конкретные проблемы и их решения.
Однотипные хуки для каждого запроса
В большинстве проектов без дополнительной абстракции каждый хук под API-запрос пишется вручную. Меняется только URL и параметры, а структура остаётся одинаковой: queryKey, queryFn, опции запроса. Это быстро приводит к копипасту, дублированию логики и усложнению поддержки.
Например, для каждого ресурса вроде пользователей, продуктов, заказов и т.д. приходится повторять одну и ту же конструкцию. Если нужно изменить поведение запроса (например, добавить retry или staleTime), правки необходимо делать в десятках мест.
Решение: Универсальная обёртка над хуками TanStack Query
Создание единой функции-генератора для хуков позволяет избавиться от повторяющегося кода. Она принимает ключ, функцию запроса и опциональные параметры — и возвращает сразу «пачку» готовых хуков.
Такой подход:
- снижает количество шаблонного кода;
- упрощает масштабирование;
- централизует поведение всех запросов;
- позволяет быстро адаптироваться к изменениям (например, добавить логирование, типизацию, трансформации и т.п.).
Хрупкость при изменении API
В типичном приложении без централизованной трансформации мы напрямую используем ответ от бэкенда. Любое изменение формата требует правок в типах, в местах использования данных, и часто приводит к багам.
Решение: Централизованная трансформация данных + class-transformer.
С помощью class-transformer можно объявить классы сущностей и задать правила преобразования один раз.
Плюсы:
- Все данные автоматически приходят в нужном виде;
- Компоненты работают с гарантированно типизированными данными;
- Один источник правды: при изменении API – правим только Entity-класс;
- Удобно масштабируется, особенно если API большое и сложное.
«Мусор» в данных и отчётах
Решение: Валидация данных при трансформации (например, через class-validator); автоматическая синхронизация кеша (актуальные данные во всём приложении).
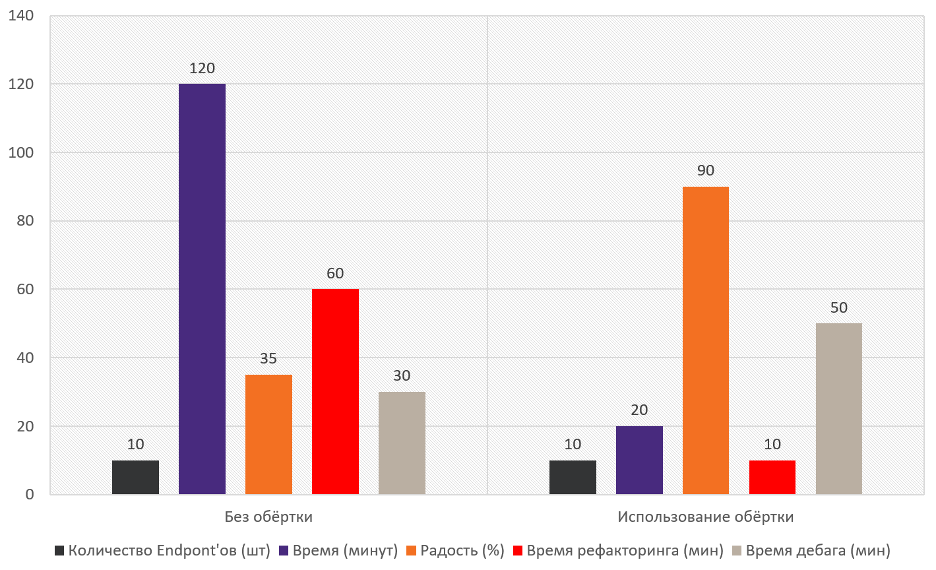
Почему это лучше ручного подхода? Смотрите: строк кода на 1 endpoint при ручном управлении потребуется 30+, а с фабрикой — 5-10. Времени для добавления нового поля — 1 час вручную, с фабрикой — 5 минут. Количество мест для правки при изменении API — вручную их много, с фабрикой — лишь одно.
Реальный кейс: в проекте с 50+ endpoint’ами переход на фабрику сократил код на 70%. Разработчики перестают быть «переводчиками» между API и интерфейсами сервисов и приложений, а сосредотачиваются на бизнес-логике. Как сказал один тимлид: «Теперь мы не фиксим баги данных, а делаем фичи, которые нравятся пользователям».
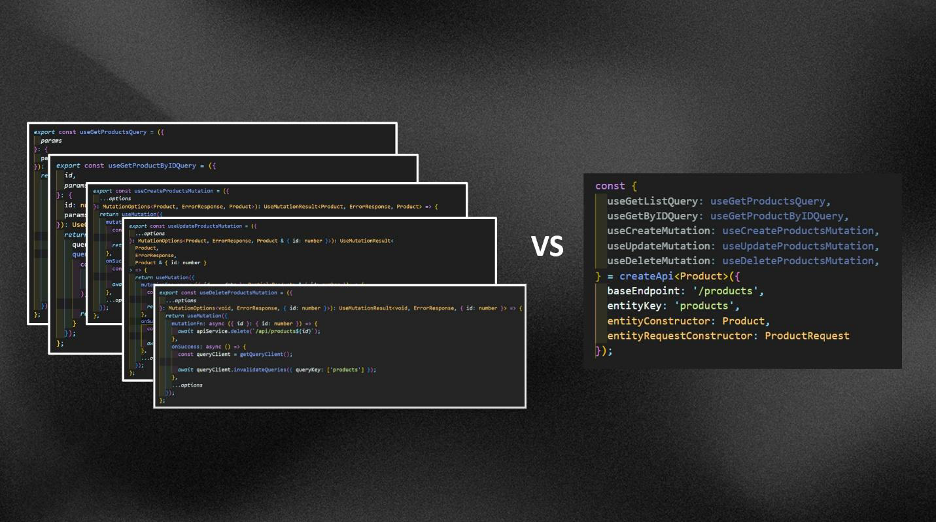
Еще пример: вместо пяти отдельных хуков для CRUD-операций фабрика дает одну функцию createApi(). Вместо ручного парсинга — автоматическую трансформацию данных через class-transformer. А главное — единые правила игры для всего проекта.
Как это работает? Представьте, что вы говорите системе: «Вот endpoint для товаров, вот их модель данных, вот правила валидации» — а все остальное она делает за вас. Хотите получить товар по ID? Пишете useGetByIDQuery. Нужно обновить? — useUpdatetMutation. И никакого шаманства с ручным описанием каждого хука.
Но главное — когда бэкенд меняет API, правки нужны только в одном месте. А новые разработчики перестают спрашивать: «Почему у нас три разных способа загрузить список пользователей?».
Как договориться и не сойти с ума
Проблема в том, что без четкого контракта, набора правил и подходов фронтенд- и бэкенд-разработчики живут в параллельных реальностях. Один думает, что данные придут в camelCase, другой шлет их в snake_case. Один ожидает массив, другой неожиданно подсовывает null. Итог — бесконечные баги, исправления «на живую» и испорченные нервы.
Решение? Четкий контракт. Простой, прозрачный, однозначный. В нем должны быть:
- Единые правила именования — если бэкенд отдает
snake_case, фронтенд не должен гадать, будут ли остальные поля вcamelCase, или, например, если в одной модели данныхfull_name, в другой не будетfullnameи так далее. - Единый формат запросов и ответов.
- Договоренности о структуре URL, формате данных и кодах ошибок.
- Строгая типизация — TypeScript-интерфейсы, которые знают, какие поля обязательны, а какие могут отсутствовать.
- Документация, которая не врет — если Swagger говорит, что поле
emailесть, оно должно быть. Всегда.
И самое главное — этот контракт должен соблюдаться. Если бэкендеры меняют API, они обязаны предупредить. Иначе фронтенд превращается в сапера, который каждое утро разминирует прод.
Но, как правило, контракт сделать тяжело. Каждый видит REST по-своему: разные URL, форматы данных, обработка ошибок. Модели данных непоследовательны — поля то есть, то их нет, вложенность меняется. Документации либо нет, либо она устарела, так что API изучаем методом проб и ошибок. От такого надо отказываться сразу и стараться договорится на берегу.
Для унификации и строгого соответствия данных мы используем class-transformer: автоматически приводим данные к нужным форматам, вместо работы с сырыми JSON-объектами. Так получаются экземпляры классов с методами и свойствами. Далее убираем ручную обработку и проверки данных, преобразовываем вложенные структуры и применяем кастомные трансформации.
Что получаем в итоге?
Когда контракт есть, а обертка API готова, магия начинает работать:
- Простота использования: вместо десятков хуков — единая фабрика
createApi(). Меньше boilerplate-кода. - Мощные возможности: данные приходят уже в нужном формате без ручных проверок. Кэш, инвалидация и оптимизации — TanStack Query делает за вас всю грязную работу.
- Новички влетают в проект: больше не нужно объяснять, почему
useGetEntityв одном компоненте работает не так, как в другом. - Активное сообщество: TanStack Query — тысячи разработчиков, готовых ответить на вопросы. Здесь можно найти примеры для любых кейсов: от интеграции с Next.js до кастомного кеширования.
- Нет ограничений по использованию: TanStack Query — не только для React, есть версии для Vue, Svelte и даже Solid.js. Также работает с любым API — REST, GraphQL, WebSockets.
- Работа с SSR без боли: готовая интеграция с Next.js, Remix и другими фреймворками. При этом данные, полученные на сервере, автоматически передаются на клиент. TanStack Query синхронизирует серверный и клиентский рендеринг.
Но есть и ложка дегтя. Отладка усложняется, если что-то сломается внутри обертки — придётся копать глубже. Возникает зависимость от библиотек: class-transformer, axios и сам TanStack Query становятся обязательными.
Однако игра стоит свеч. Потому что время, сэкономленное на рутине, можно потратить на то, что действительно важно — фичи, которые понравятся пользователям, а не бесконечные правки API-вызовов.
Сравнительные примеры
GET /products — Список продуктов
GET /products/:id — Один продукт по id
POST /products — Создание продукта
PUT /products/:id — Обновление продукта по id
DELETE /products/:id — Удаление продукта по id
Как это выглядит в обертке
Все свойства и возвращаемые хуки и конфиги из фабрики:
Пример использования в компонентах:
Использование конфигов:
Для сравнения с классическим решением:
Когда стоит переходить на обертку?
Не каждый проект нуждается в таком подходе к API. Если у вас два-три endpoint’а и они никогда не меняются — возможно, обертка будет избыточной. Но представьте стартап, где каждый месяц добавляются новые сущности: сначала товары, потом отзывы, потом промокоды, рекомендации, аналитика.
Вот где система раскрывается на полную! Новая сущность? Пять минут на добавление — и готовы все CRUD-операции. Изменился бэкенд? Правим в одном месте — и все работает. Пришел новый разработчик? Он не тратит неделю на изучение особенностей API.
Правда, если бэкенд живет в мире хаотичных endpoint’ов (например, GET /fetch_items, но DELETE /removeProduct), обертка не спасет.
Но как навести порядок?
Главный секрет — общаться. Не ждать, пока API сломается, а сразу договориться:
- Какие будут названия полей (created_at vs createdAt);
- Как структурированы ошибки;
- Когда и как можно менять контракт.
Как сказал один разработчик: «фронтенд и бэкенд — как соседи по коммуналке. Можно ругаться из-за бардака на кухне, но лучше сесть и написать правила совместного проживания».
А напоследок — график, для закрепления разницы между работой с оберткой и без нее.