Как ускорить приложения на Python
Рассказываем, как проанализировать и ускорить имеющийся код на Python, чтобы приложение работало так же быстро, как на C++.
На Python пишут как десктопные программы, так и высокопрофессиональные web-приложения. Он является интерпретируемым языком и благодаря этому можно использовать продвинутые инструменты. Например, интроспекцию и метапрограммирование.
Но Python накладывает и некоторые ограничения, одно из них — снижение скорости работы по сравнению с программами, написанными на компилируемых языках программирования (C++ и др).

Андрей Смирнов
Python-разработчик, преподаватель по финансовой грамотности в Московской школе программистов (МШП)
В статье я разберу интересный кейс, чтобы проанализировать и ускорить имеющийся код на Python.
Исходные данные (демо-приложение)
Сразу же скажу, что мы не будем погружаться в пучину хардкорной отладки и продираться сквозь десяток уровней вызовов функций в стеке и сложные алгоритмические конструкции. Причина проста: все методы, которые я покажу сегодня, прекрасно воспроизводятся на простом коде и после этого тиражируются на любые масштабные проекты.
А в качестве стартового кода мы возьмём задачу: имеется магазин, продающий определенные товары. Товар характеризуется тремя величинами: название, цена, валюта. Необходимо реализовать хранилище товаров, заполнить его некими товарами.
На языке Python такая задача решается быстро:

Сразу отмечу, что я взял достаточно большой размер списка с данными для того, чтобы программа выполнялась такое количество времени, которое позволит не искать дельту в тысячных долях секунды.
Профилирование
Казалось бы, необходимо оптимизировать код, но как понять, что именно необходимо менять? Для этого нужно собрать с приложения определённые метрики, показывающие, насколько хорошо оно работает.
Процесс сбора этих метрик называется профилированием приложения. Проводить процесс профилирования можно как по времени работы, так и по памяти.
Профилирование по времени
Сначала добавим в нашу программу измерение скорости её работы. Для этого в Python есть специальная функция time, находящаяся в одноименном модуле. Идея использования этой функции очень проста: мы изменяем текущее время в начале работы программы и в конце. Далее считаем дельту, которая будет являться длительностью работы программы.

И ещё несколько пунктов, которые обязательно нужно сказать про этот код:
- В ходе профилирования нет смысла измерять время работы кода, ответственного за ввод данных с клавиатуры, чтение из файла, получение данных из сетевого хранилища и т.д. Эти операции априори будут медленными из-за низкой скорости передачи данных по сравнению с аналогичной скоростью в передачи данных в ОЗУ компьютера. Если вы понимаете, что проблема низкой скорости кроется в коде ввода данных, тогда его нужно профилировать отдельно от основной программы.
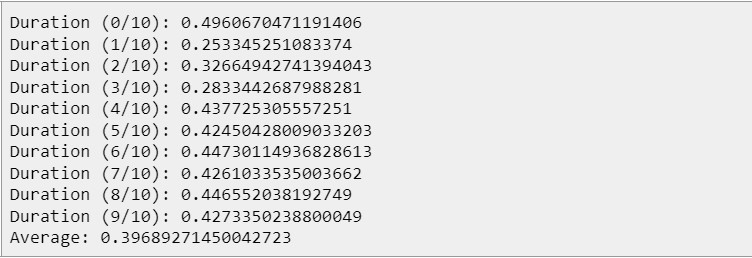
- Одна и та же программа, запущенная два раза, практически никогда не выдаст идентичное время выполнения. Это происходит из-за того, что программа выполняется в операционной системе, в которой постоянно работают фоновые процессы. И чаще всего отключить все лишние процессы невозможно. В таком случае, чтобы минимизировать их влияние, достаточно всего лишь запустить программу многократно и посчитать среднее время выполнения (что и сделано в коде).
Этот код при запуске показал следующие тайминги:

Сразу можно заметить, что отклонение по времени доходит до половины секунды. Запускал код я на системе со следующей конфигурацией:
- Intel Core i7-7700HQ
- 16Gb RAM
- KUbuntu 22.04
Ещё немного про профилирование по времени и сразу же первая оптимизация
Если у вас “тормозит” программа, в которой сотни и тысячи строк кода и сама архитектура этого кода состоит их множества функций и классов, тогда использовать замер таймингов в том виде, в котором я написал выше, будет крайне неудобно.
Но эта проблема решаема с помощью встроенного в Python средства профилирования, идеально подходящего для такой ситуации — утилиты cProfile. Она способна не просто запустить код и рассчитать время его работы, но и рассчитать время работы каждого отдельного метода (включая даже низкоуровневые методы создания списков, выделения памяти, добавления объектов и т.д.).
Для того, чтобы запустить cProfile, не требуется менять код. Достаточно просто запустить программу на исполнение с подключением дополнительного модуля:
В таком случае вся программа выполнится и после неё будет выведена детальная информация о времени выполнения каждой функции:
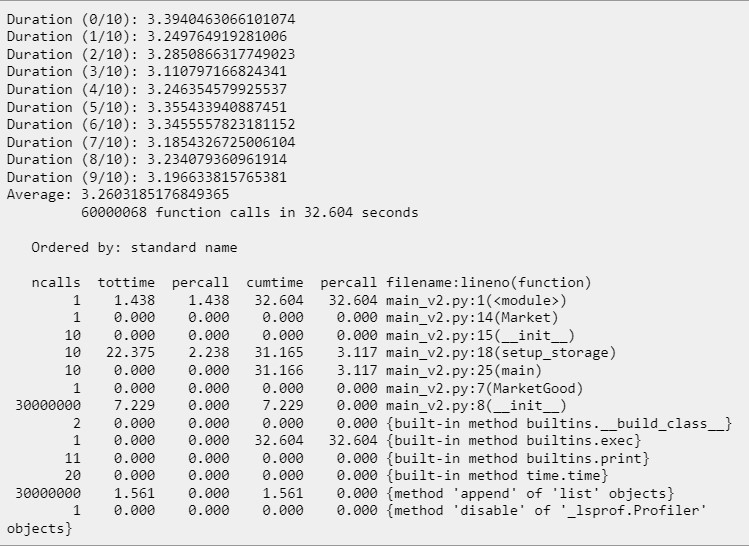
Сразу же есть две мысли:
- Наличие любого дополнительного профилировщика замедляет программу. Это происходит, потому что любой профилировщик добавляет свой исполняемый код, благодаря которому и собирается статистика выполнения. В результате этого среднее время выполнения нашей программы увеличилось с 2.46 до 3.26 секунд.
- Сразу же можно заметить, что больше всего раз вызывается метод list.append, который добавляет новый объект в список. И именно на этом месте появляется идея для оптимизации: если мы заранее знаем, что объектов будет добавляться именно три миллиона, что мешает нам создать заранее список такого размера?
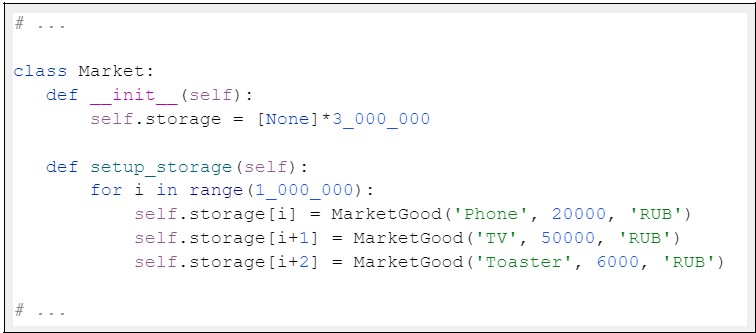
Попробуем изменить код так, чтобы список создавался сразу:
Запустим его также с использованием cProfile. И что же мы видим?
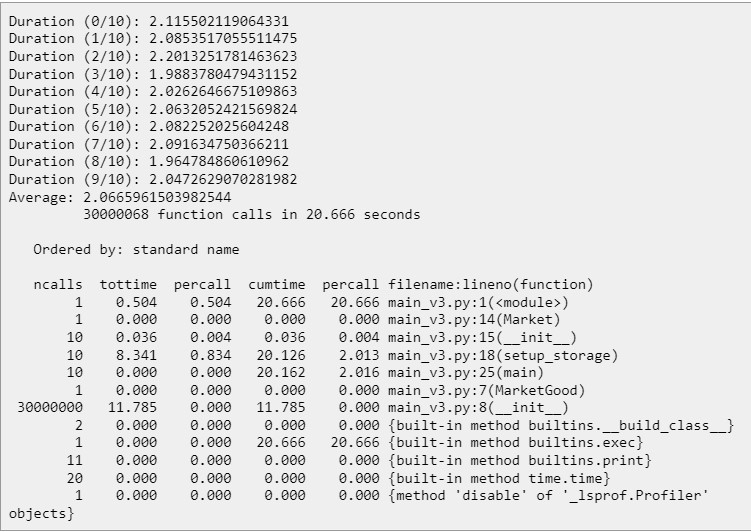
Среднее время уменьшилось до 2.06 секунд, и это со включённым профилировщиком. А без него будет так вообще 1.66! И всё путём простейшей оптимизации.
Профилирование по памяти
Также сразу же добавим в наш код профилирование по памяти, так как очень интересно узнать “сколько же занимает в памяти три миллиона товаров”. Для подсчёта памяти будем использовать библиотеку pympler.
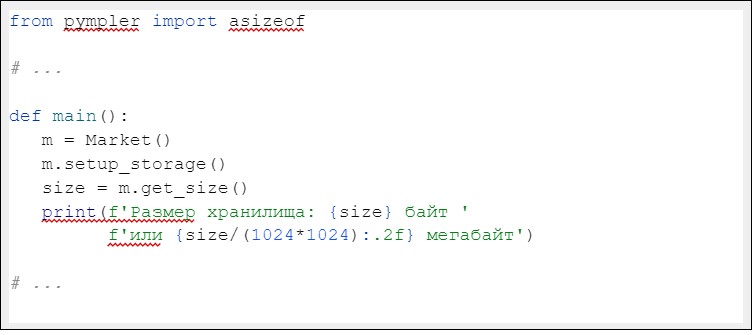
И такой код при размере хранилища в три миллиона товаров показал следующие результаты:
Вы можете заметить, что я убрал из кода подсчёт по времени. Причина проста: pympler для подсчёта количества занимаемой памяти проходит по всем имеющимся структурам данных, и во время подсчёта скорость выполнения увеличивается раз в пять, делая профилирование по времени неоправданным.
А теперь, когда мы достаточно знаем о поведении нашего приложения (и во времени, и в памяти) – приступим к его последовательной оптимизации.
Способы оптимизации
Оптимизация структур данных
Начнём мы с несколько нестандартной оптимизации, а именно — залезем внутрь нашего объекта товара и основательно там покопаемся.
Сейчас объект представлен в виде обыкновенного класса. Давайте подумаем, а возможно ли здесь использовать какую-нибудь иную структуру данных, которая построена на основе класса, но имеет дополнительный функционал? И такая структура есть, она называется датакласс. Правда, сразу стоит оговориться, что обычный датакласс является небольшой надстройкой над обычным классом, в которой разработчики языка чётко указали, какие будут поля и какие они будут иметь типы данных. А нам будет интересен датакласс с фиксированными полями, в который невозможно добавить новые поля.
Почему это важно? Для того, чтобы иметь возможность добавлять и удалять поля в рантайме, в классах питона реализована структура словаря __dict__. А это, в свою очередь, далеко не всегда является необходимым функционалом.
Поэтому, если сформировать чёткую структуру данных (а чаще всего для хранения больших объёмов данных используются как раз жёстко определённые структуры), то после этого можно убрать функционал динамического добавления полей, и в таком случае объекты будут работать быстрее.
Реализуем эту идею (для этого определим кортеж __slots__).

Если этот код запустить и проверить время выполнения, то мы получим ускорение в среднем на 25 процентов

А если директиву __slots__ указать в коде, который мы профилировали по памяти, то результаты получатся ещё более сногсшибательными:
То есть, путём отказа от динамического добавления элементов мы сразу уменьшили расходы памяти нашего приложения вдвое!
И на этом мы не остановимся.
Оптимизация интерпретатора
Следующая оптимизация, которая может помочь нам в достижении нашей цели — замена интерпретатора Python на интерпретатор PyPy.
Согласно определению из Википедии, PyPy – это интерпретатор языка Python, написанный на языке Python. Однако в него встроен трассирующий JIT-компилятор, способный преобразовывать код на Python в машинный код прямо во время выполнения программы. Эта особенность позволяет ему существенно ускорить процесс исполнения программы без каких либо изменений кода.
Установим pypy следующей командой:
А после этого запустим код с его помощью:
Результаты говорят сами за себя: скомпилированный код априори выполняется намного быстрее, нежели интерпретируемый код. Время исполнения уменьшилось ещё на 68%. И для такого запуска абсолютно не потребовалось менять исходный код.
{kind=link}
Справедливости ради нужно заметить, что за счёт глубинной оптимизации некоторые сторонние библиотеки, которыми вы можете пользоваться, не смогут запуститься в pypy. И для них придётся искать аналоги. Но самые популярные библиотеки (такие как twisted, django, numpy, scikit-learn и другие) им полностью поддерживаются и работоспособны.
А как ещё можно оптимизировать?
В мире существуют и другие способы оптимизации, но они уже относятся к категории радикальных, подразумевающих кардинальное изменение структуры кода и (или) даже языка программирования. Среди них:
- изменение структуры хранимых данных со списка объектов на pandas.DataFrame.
- добавление строгой типизации и адаптация кода под компилятор cython
- распараллеливание программы на потоки при помощи Nvidia CUDA.
- И, наконец, если затраты от потерь производительности существенно превышают затраты от кардинальной переработки кода, можно попробовать переписать критичные части кода на языке C++ и оформить их в виде библиотеки, функции из которой можно запустить из Python-кода.
Итоги
Итак, в ходе нашего увлекательного путешествия мы
- написали код
- измерили его производительность (по памяти и по времени)
- оптимизировали его несколько раз
- результаты в виде графиков приведены ниже.

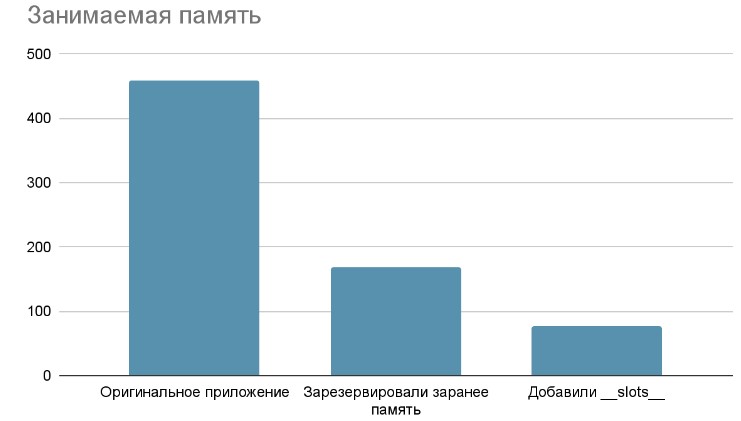
В каждом из случаев получилось улучшить измеряемый показатель производительности более чем в два раза, так что считаю, что цель достигнута.
Благодарю за внимание.

