


Какую AI-модель выбрать для программирования в декабре 2025
Спойлер: лидер не всегда очевиден, а самая быстрая модель обходит топовые решения по скорости в 4 раза
6К открытий14К показов

Мы проанализировали публичный лидерборд Bash Only, отзывы разработчиков на Reddit и собственный опыт работы в Cursor, чтобы составить честный рейтинг моделей. Спойлер: лидер не всегда очевиден, а самая быстрая модель обходит топовые решения по скорости в 4 раза.
Проблема с бенчмарками
С оценкой кодовых моделей есть фундаментальная проблема. Компании публикуют впечатляющие цифры — 75-81% на SWE-bench Verified — но тестируют в оптимальных для себя условиях: собственные агенты, собственные настройки, собственный harness. Воспроизвести эти результаты независимо невозможно.
Anthropic прямо признаёт это в своей документации: когда они улучшили тестовое окружение, GPT-5.1 показал только 48,6% на Terminal-Bench — а не те цифры, что заявляет OpenAI. В чужом сетапе модели резко теряют в производительности.
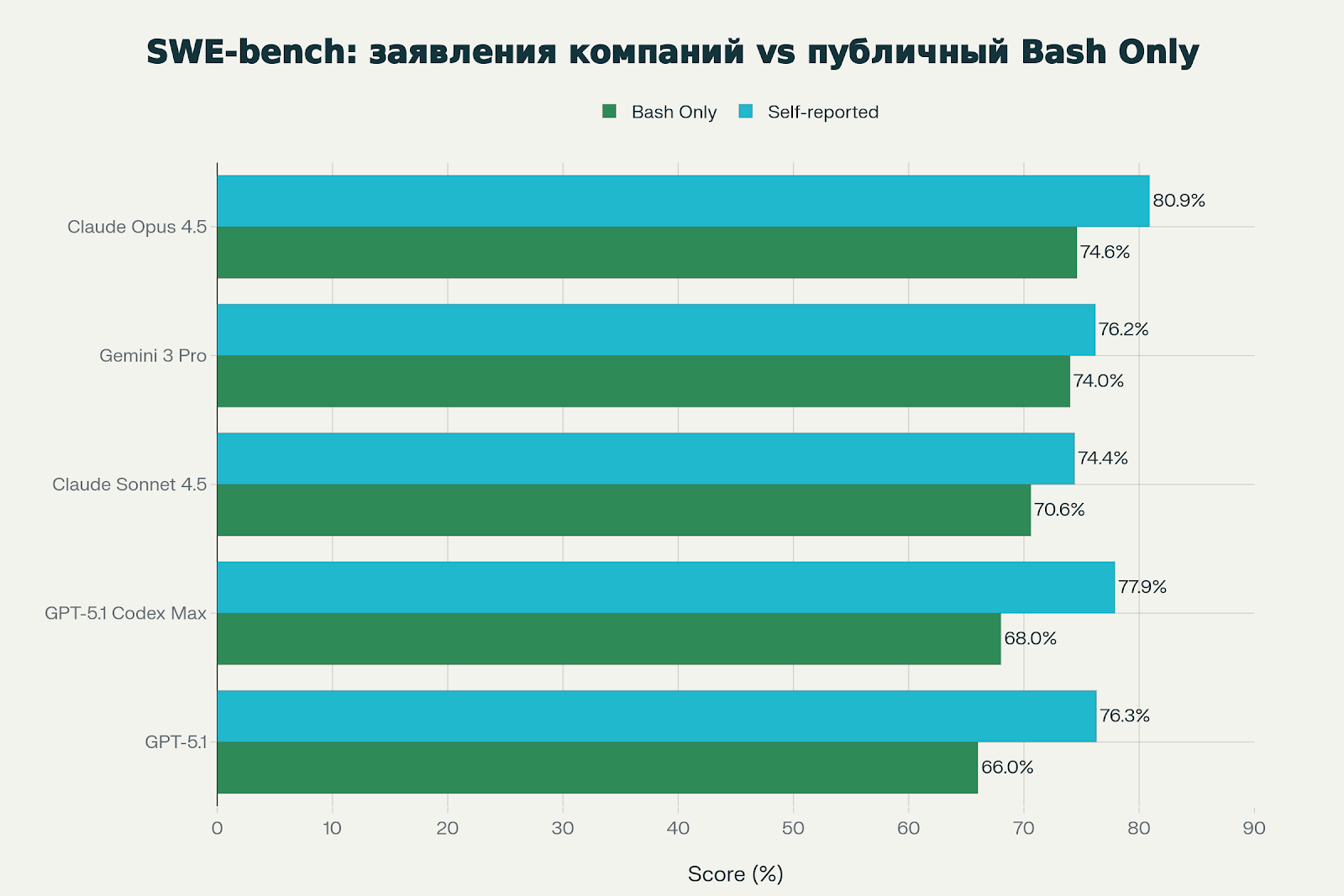
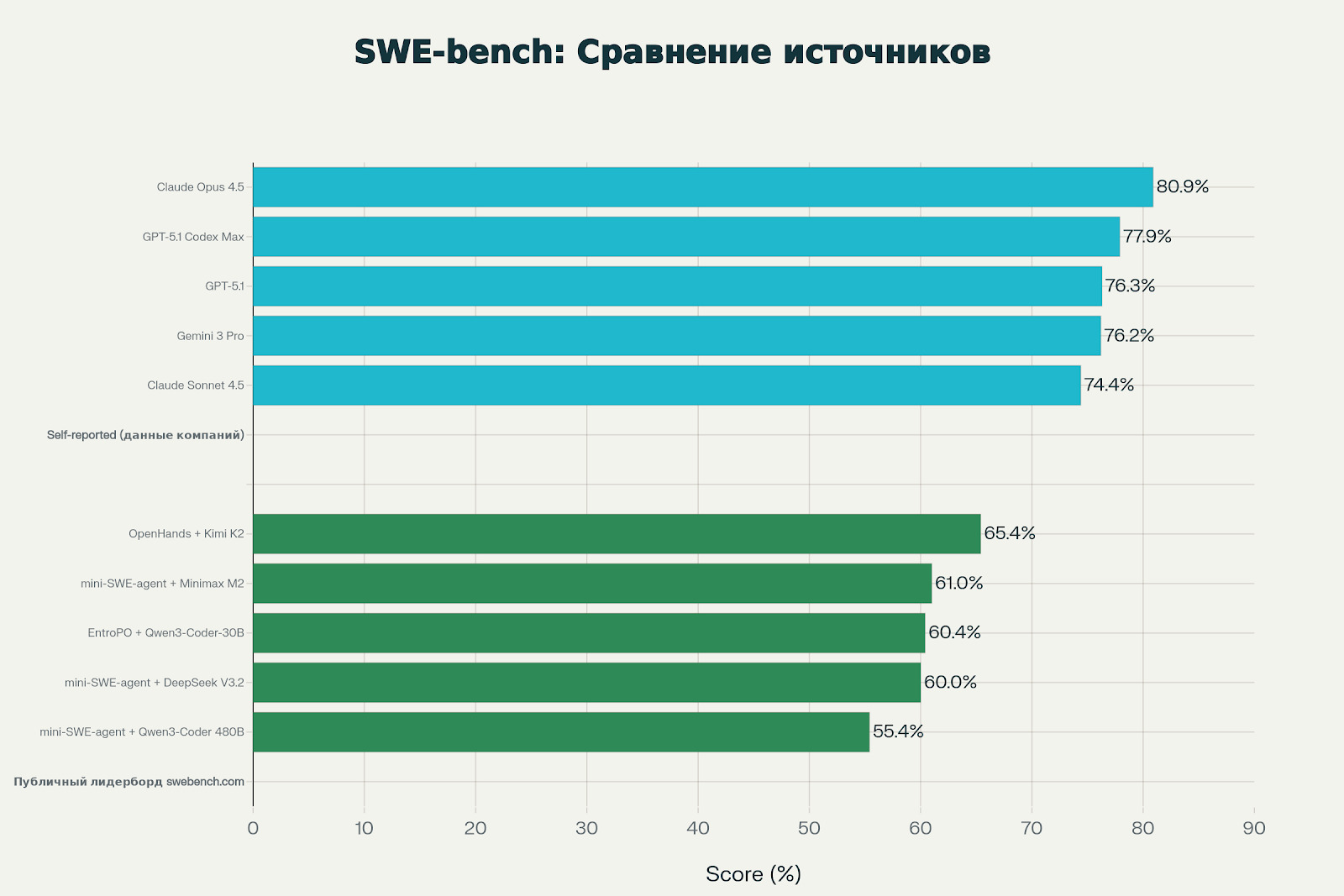
На графике видно расхождение между заявлениями компаний (синие столбцы) и публичным лидербордом Bash Only (зелёные столбцы). Разница составляет 6-10 процентных пунктов — это существенно.
Интересные наблюдения:
- Gemini 3 Pro в публичном тесте почти догоняет Opus 4.5 (74% vs 74.6%), хотя по заявлениям Google разница должна быть больше
- GPT-5.1 Codex Max в Bash Only уступает Claude Sonnet 4.5, несмотря на громкие заявления OpenAI
- Claude Opus 4.5 лидирует в обоих рейтингах, но отрыв от конкурентов в независимом тесте меньше
Что такое Bash Only и почему это важно
Публичный лидерборд SWE-bench Bash Only на swebench.com даёт более честную картину. Все модели запускаются через одинаковый mini-SWE-agent с обычным bash-окружением. Никаких специальных оптимизаций, никакого подбора промптов под конкретную модель.
Но даже это не совсем то, что получится в реальной работе. В Cursor, Windsurf или других AI IDE — своя интеграция, свой контекст, свои системные промпты. Результаты будут отличаться.
Итоговый рейтинг
На основе субъективного опыта, отзывов разработчиков на Reddit и форумах, а также публичных бенчмарков — вот комплексный рейтинг моделей для использования в Cursor.
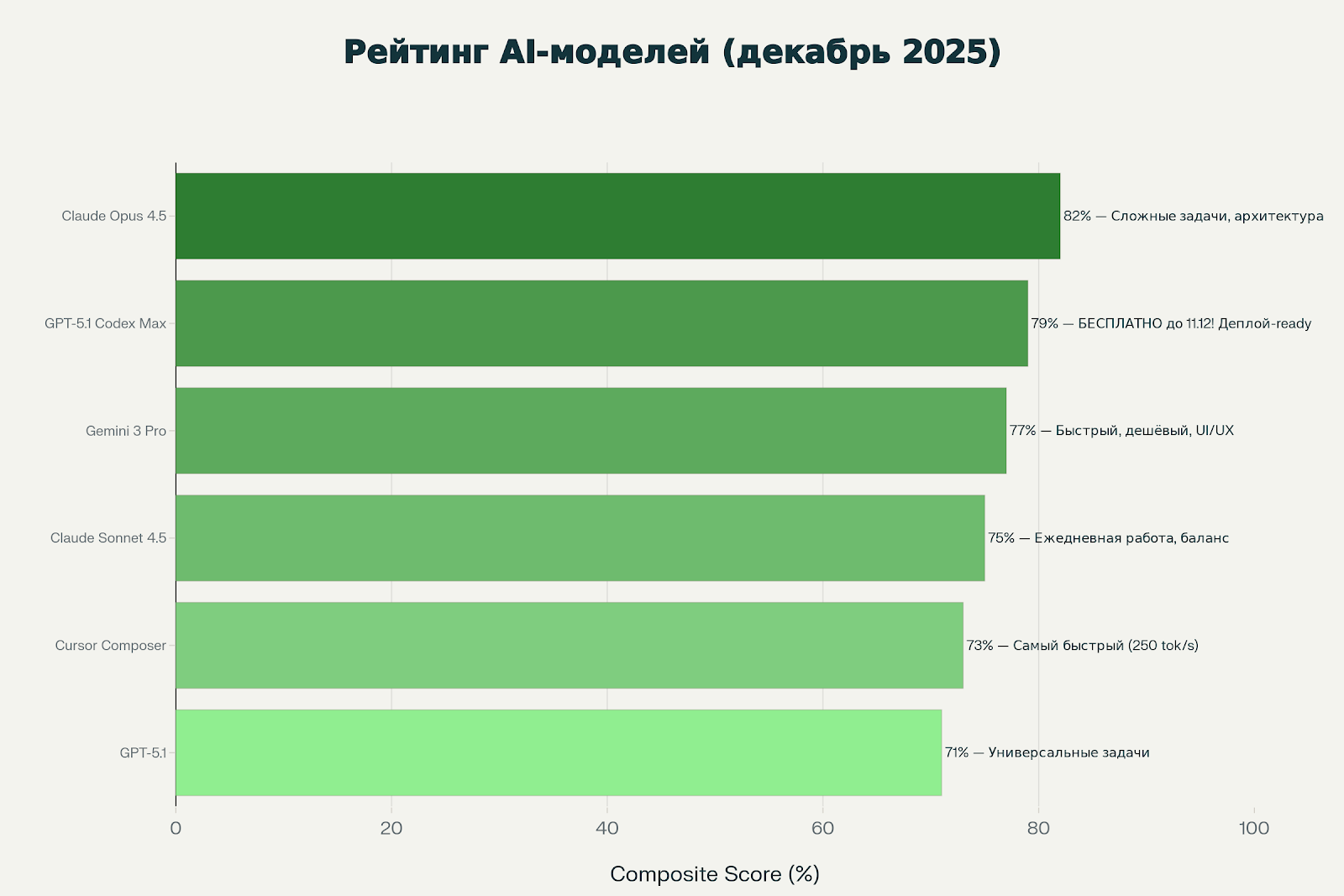
Комплексная оценка учитывает три фактора:
- Self-reported — заявления компаний (показывает потенциал модели)
- Bash Only — независимый публичный тест (показывает реальность)
- Практика — отзывы разработчиков о реальном использовании
Обзор моделей
1. Claude Opus 4.5 — для сложных задач
Комплексная оценка: 82%
Флагман Anthropic, выпущенный 24 ноября 2025. Лидирует и в self-reported тестах (80.9%), и в независимом Bash Only (74.6%).
Когда использовать
- Проектирование архитектуры
- Глубокий рефакторинг legacy-кода
- Отладка запутанных багов
- Задачи, где важно качество, а не скорость
Особенности
- Самая дорогая модель ($75 за 1M токенов вывода)
- Самая медленная (~45 tok/s)
- Выдаёт наиболее продуманные, структурированные решения
- Хорошо понимает контекст больших кодовых баз
Рекомендация
Использовать для 20% задач, где критично качество.
2. GPT-5.1 Codex Max — попробуй бесплатно
Комплексная оценка: 79%
Специализированная версия от OpenAI для агентных задач. Главная фича — технология compaction: модель умеет работать с миллионами токенов через несколько контекстных окон.
Когда использовать
- Код, который сразу идёт в продакшен
- Работа с edge cases
- Длительные сессии рефакторинга
- Прямо сейчас — пока бесплатно
Особенности
- Бесплатна в Cursor до 11 декабря 2025
- По отзывам, выдаёт наиболее "деплоябельный" код — меньше лишнего, лучше обработка граничных случаев
- В независимых тестах показывает себя хуже, чем в заявлениях OpenAI (68% vs 77.9%)
Рекомендация
Обязательно попробовать в оставшиеся дни бесплатного периода. Субъективно код получается чуть чище, чем у Opus.
3. Gemini 3 Pro — сюрприз рейтинга
Комплексная оценка: 77%
Неожиданно сильный результат от Google. 74% на Bash Only — почти на уровне Opus 4.5, при значительно меньшей цене.
Когда использовать
- Быстрое прототипирование
- Фронтенд и UI/UX задачи
- Когда важен баланс цены и качества
- Работа в экосистеме Google
Особенности
- Быстрый (~100 tok/s)
- Дешёвый ($21 за 1M токенов)
- Отлично справляется с визуальными задачами
- Код может требовать доработки для продакшена
Рекомендация
Отличный выбор для прототипов и MVP.
4. Claude Sonnet 4.5 — рабочая лошадка
Комплексная оценка: 75%
Младшая версия Opus, но с важным преимуществом: 70.6% на Bash Only — обходит даже Opus 4 и GPT-5.1 в этом независимом тесте.
Когда использовать
- Ежедневная рутинная работа
- Когда нужен баланс скорости и качества
- Большой объём типовых задач
- Ограниченный бюджет
Особенности
- Хорошая скорость (~120 tok/s)
- Умеренная цена ($25 за 1M токенов)
- Стабильные, предсказуемые результаты
- Хорошо работает с правильно структурированным контекстом
Рекомендация
Основная модель для 60-70% повседневных задач.
5. Cursor Composer — максимальная скорость
Комплексная оценка: 73%
Собственная модель Cursor, выпущенная 28 октября 2025. Обучена с reinforcement learning на реальных кодовых базах.
Когда использовать
- TDD-циклы с быстрой итерацией
- Интерактивная отладка
- Когда критична скорость отклика
- Мелкие правки и доработки
Особенности
- 250 tok/s — в 4 раза быстрее конкурентов
- Большинство задач выполняет менее чем за 30 секунд
- Самая дешёвая модель ($10 за 1M токенов)
- Публичных бенчмарков нет, но на практике работает хорошо
Рекомендация
Идеальна для этапа исполнения в связке с reasoning-моделью.
7. GPT-5.1 — базовая версия
Комплексная оценка: 71%
Универсальная модель OpenAI для широкого спектра задач. Контекст 400K токенов, выход до 128K.
Когда использовать
- Универсальные задачи без специфики
- Когда не нужны специализированные возможности
- Работа с большим контекстом
Особенности
- 76.3% по заявлениям OpenAI, ~66% в Bash Only
- Средняя скорость и цена
- Хорошая работа с длинным контекстом
Рекомендация
Запасной вариант, когда другие модели недоступны.
Скорость генерации
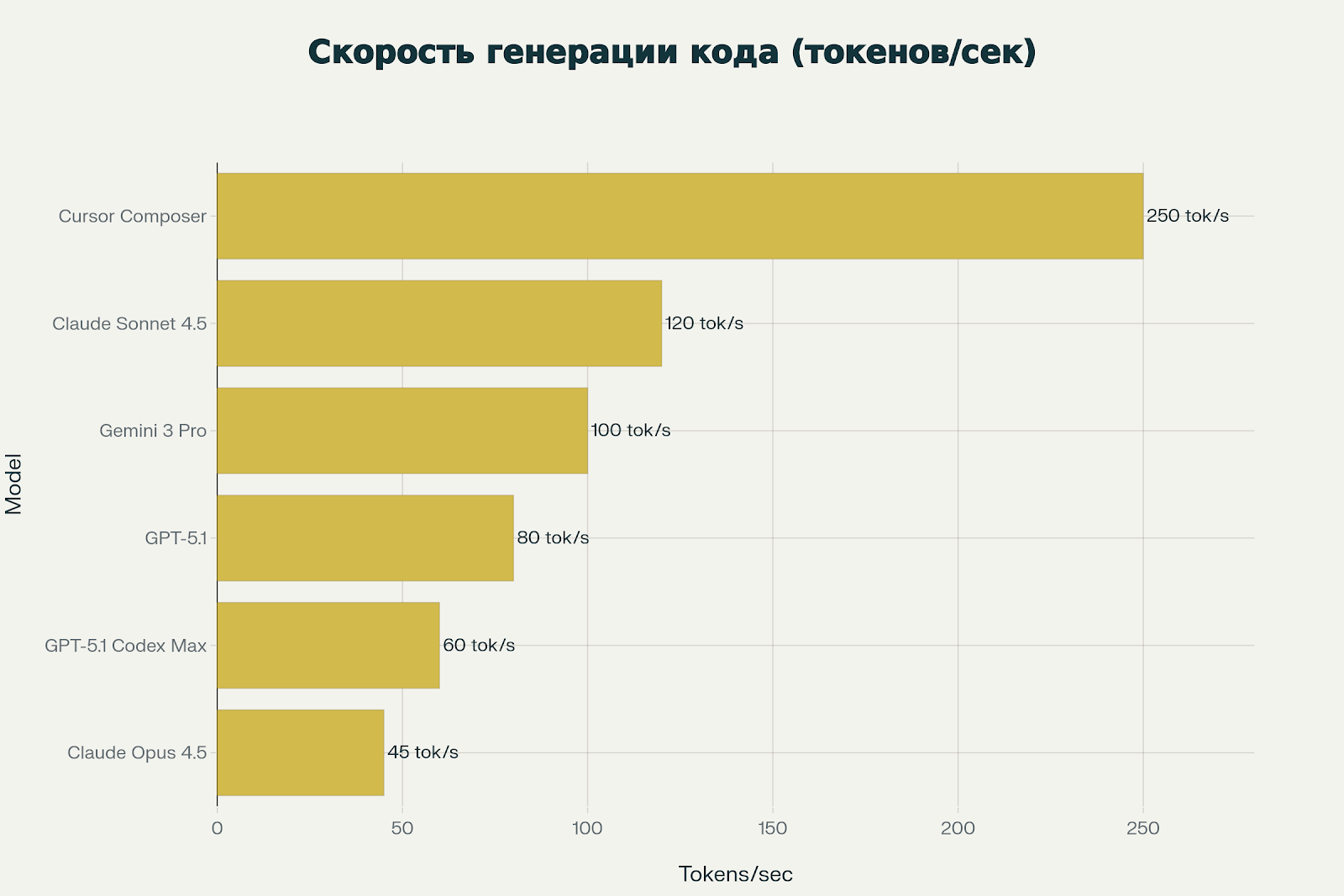
Скорость критична для интерактивной работы. Cursor Composer генерирует код в 4-5 раз быстрее самых медленных моделей. Это особенно заметно при частых мелких правках и TDD-циклах.
Claude Opus 4.5 — самая медленная модель. Это осознанный trade-off: больше времени на "размышление" = более качественный код. Но для быстрой итерации это неудобно.
Стоимость
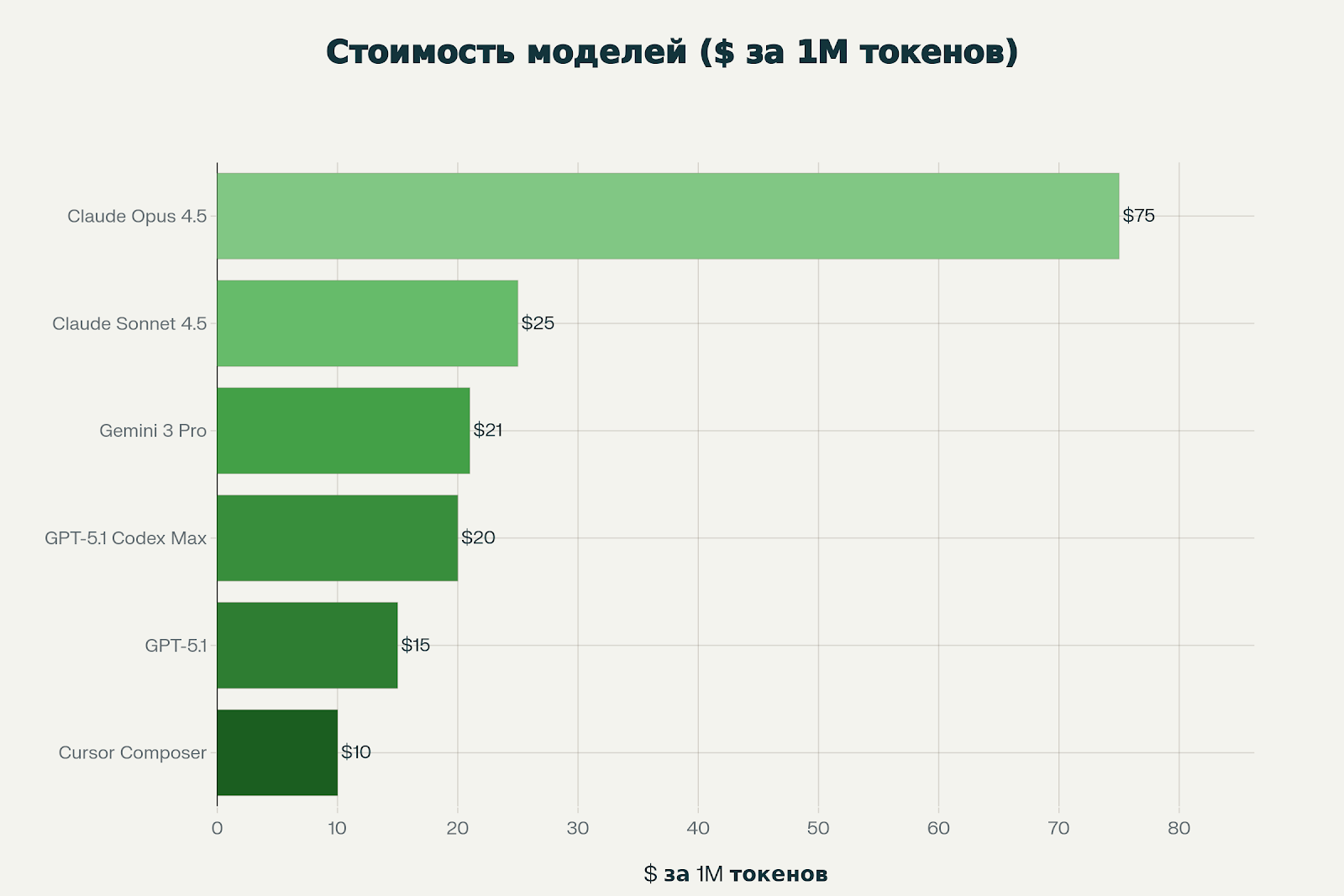
Разброс цен значительный — от $10 до $75 за миллион токенов вывода. Claude Opus 4.5 стоит в 7.5 раз дороже Cursor Composer.
Важно: GPT-5.1 Codex Max бесплатна до 11 декабря в Cursor. Это отличная возможность протестировать топовую модель без затрат.
Качество vs Скорость
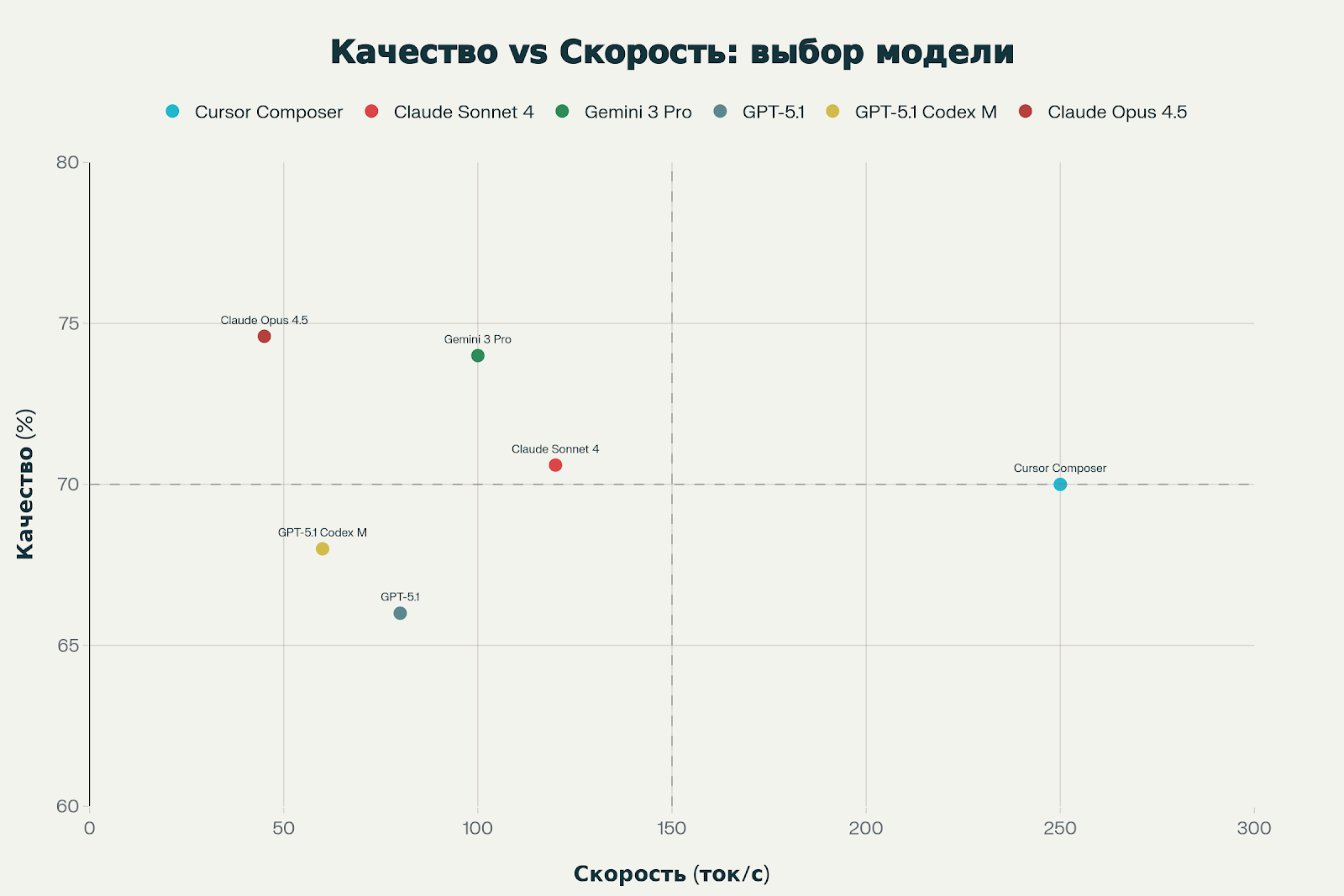
Этот график помогает выбрать модель под конкретные приоритеты:
- Правый верхний угол (быстро и качественно) — идеал, но пока недостижим. Ближе всего Gemini 3 Pro.
- Левый верхний угол (качественно, но медленно) — Claude Opus 4.5. Для задач, где скорость не критична.
- Правый нижний угол (быстро, но менее точно) — Cursor Composer. Для быстрой итерации с последующей проверкой.
Рекомендуемый workflow
Главный совет, который даёт максимальный буст продуктивности: разделять стадии планирования и реализации.
Этап 1: Планирование
Используй reasoning-модель (Claude Opus 4.5, o3) для:
- Анализа задачи
- Проектирования архитектуры
- Разбиения на подзадачи
- Продумывания edge cases
Этап 2: Реализация
Передай план быстрой модели (Cursor Composer, Claude Sonnet 4.5, GPT-5.1) для:
- Генерации кода по готовому плану
- Быстрой итерации
- Мелких правок
Cursor 2.0 поддерживает это нативно — можно настроить разные модели для разных режимов работы.
Сводная таблица
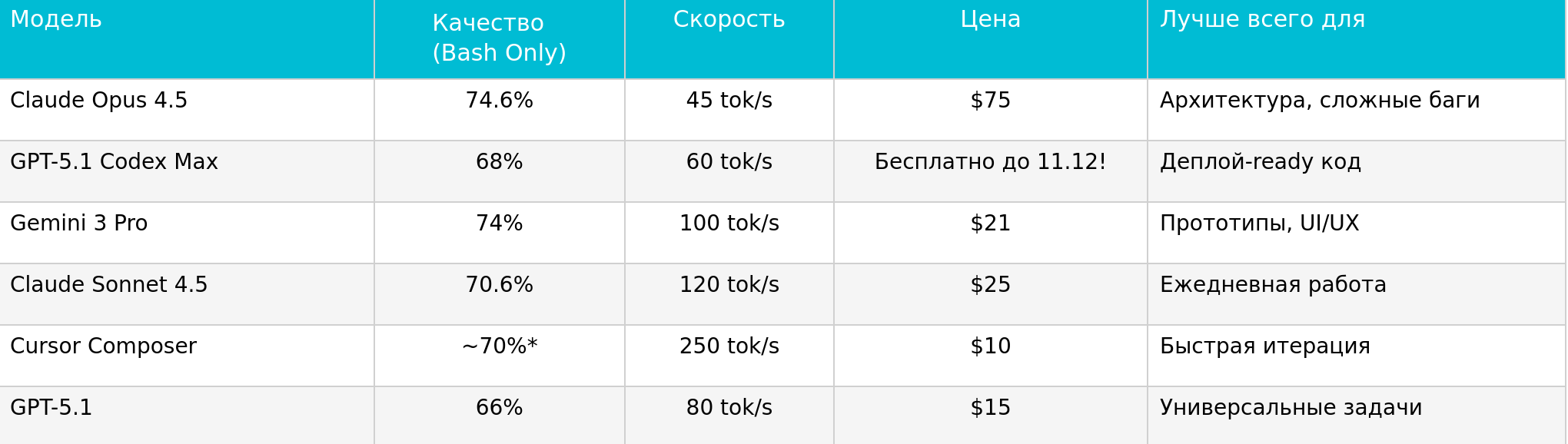
Выводы
- Не доверяй заявлениям компаний вслепую — реальные результаты в независимых тестах Bash Only на 6-10% ниже self-reported данных.
- Комбинируй модели для максимальной продуктивности — reasoning-модель (Claude Opus 4.5) для планирования архитектуры, быстрая модель (Cursor Composer, Claude Sonnet 4.5) для реализации. Cursor 2.0 поддерживает это нативно.
- GPT-5.1 Codex Max стоит попробовать прямо сейчас — бесплатна в Cursor до 11 декабря 2025. По отзывам, выдаёт лучший код с лучшей обработкой граничных случаев.
- Gemini 3 Pro — недооценённая звезда — 74% на Bash Only (почти на уровне Opus 4.5) при цене втрое ниже ($21 vs $75 за 1M токенов). Отличный выбор для прототипов и MVP.
- Cursor Composer — король скорости — 250 tok/s против 45-120 tok/s у конкурентов. Идеален для TDD-циклов и быстрой итерации. Самая дешёвая модель ($10 за 1M токенов).
- Claude Opus 4.5 остаётся лидером для сложных задач — 80.9% в self-reported и 74.6% в Bash Only. Дорого ($75) и медленно (45 tok/s), но для архитектурных решений и отладки запутанных багов — лучший выбор.

6К открытий14К показов

Подборка рабочих промптов для ChatGPT — от улучшения резюме до настройки ментора по фронтенду и управления продуктивностью.

В статье расскажем о невидимых метках, которые оставляет ChatGPT во время работы, а также о «мировом заговоре», который возник из-за этого, и как удалось его раскрыть.

ТОП-10 уязвимостей OWASP. Показываем, какие бывают и основные методы защиты. Рассматриваем пошаговую инструкцию и инструменты ✔ Tproger

Разработчик с 12-летним опытом предупреждает: ИИ и вайб-кодинг дают быстрый результат, но лишают понимания кода и ведут к деградации