


Как устроена межсервисная авторизация в Авито PaaS
Антон Губарев, инженер в Avito PaaS, рассказал, как реализовать межсервисную авторизацию на 2500 сервисов и ничего не сломать.
462 открытий7К показов

Привет! Меня зовут Антон Губарев, я работаю инженером в Avito PaaS и веду канал о техническом лидерстве и инфраструктурной разработке на Go «Техлидошная». Сегодня я расскажу о том, как мы реализовывали межсервисную авторизацию в рамках платформы и с какими проблемами столкнулись. Я — фича-лид и основной разработчик этого проекта, поэтому мне есть, чем поделиться.
PaaS в Авито: 2500 сервисов, на которых нужно было реализовать авторизацию, и ничего не сломать
PaaS, по сути — набор готовых решений, который помогает продуктовым разработчикам не тратить время на погружение в особенности инфраструктуры: как она работает, как устроен прод, сколько используется своих дата-центров, сколько — облачных, и так далее. Подробнее про PaaS в Авито можно почитать в статье моего коллеги Александра Лукьянченко.
В PaaS есть UI-интерфейс — дашборд. В нём находится всё для управления сервисами. Например:
- деплой в разные окружения;
- информация о потреблении ресурсов;
- задеплоенные манифесты в Kubernetes;
- связи: в какие другие сервисы ходит этот сервис и откуда приходят запросы к нему.
Ещё у нас есть собственный формат для межсервисного взаимодействия — brief. Он похож на Protobuf, но немного упрощённый и заточенный под наши требования.
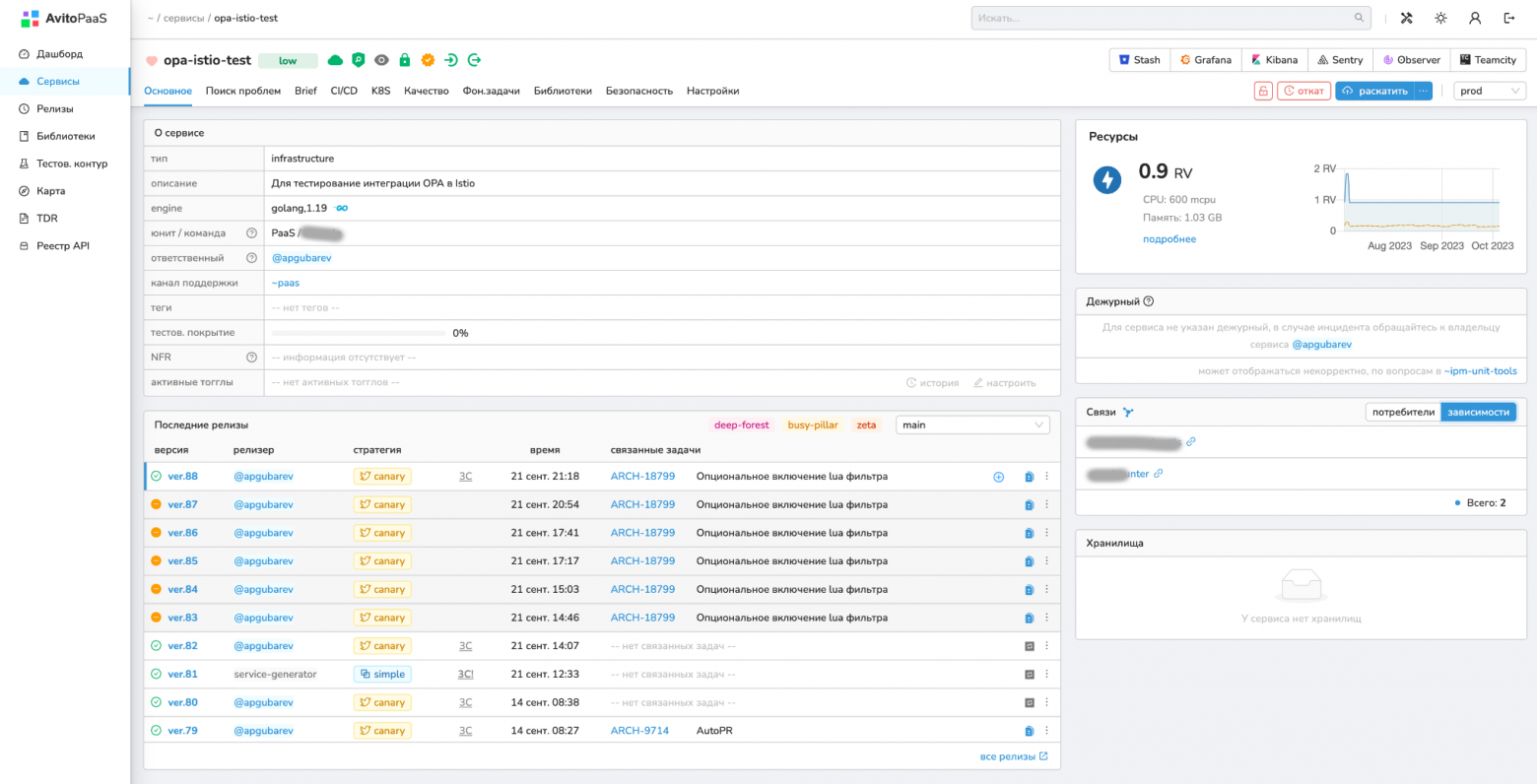
Пример брифа:
Похоже на protobuf, но только гораздо проще. Это значит, потребуется немного времени на погружение и вход.
Вот, как команды используют Brief:
- Разработчики пишут brief-схемы для сервиса, описывают ручки, которые хотят сделать.
- Затем они используют генератор, который на нужном языке программирования генерит код сервера и клиента
- Остается только реализовать логику внутри ручек или использовать клиенты для походов в другие сервисы
- При деплое brief-схемы регистрируются в отдельном реестре
Внутри платформы 2500 сервисов, и все они тесно связаны друг с другом форматом Brief. На этом большом живом организме нам нужно было реализовать авторизацию так, чтобы ничего не сломалось. Поговорим о том, как мы это делали.
Наши требования к межсервисной авторизации
Чтобы понять, каким будет наше решение для межсервисной авторизации, мы опросили команды сервисов, живущих внутри PaaS, поговорили с отделом безопасности, и выявили шесть требований:
- Контролировать доступ к ручкам. Часть сервисов или отдельные ручки могут содержать чувствительную информацию: данные пользователей или финансовые показатели.
- Логировать изменения. Нужно знать, кто и когда вносил изменения и пользовался ручками, — это основа любой системы безопасности.
- Не сломать связи 2.500 сервисов. Нарушение любой из связей могло привести к деградации продакшена.
- Не менять сервисы. Сервисов много, поэтому заставлять сотни разработчиков вносить изменения в свои сервисы — неправильно.
- Не повлиять на скорость работы. Для некоторых сервисов лишние 10мс — уже критично.
- Сделать платформенное решение. Некоторые команды уже стали пилить свою локальную авторизацию: например, через JWT-токены. Нам нужно было централизованное и удобное решение, подходящее всем.
Проанализировав требования, мы стали думать, как продуктово организовать конфигурацию политик авторизации.
Конфигурация политик авторизации. Как это выглядит для пользователя
У нас уже был подход конфигурации как код. В каждом сервисе есть файлик app.toml, на основании которого наша платформа катит сервис так, как это нужно разработчикам:
- с нужным количеством реплик;
- с нужными переменными окружения;
- с указанным расписанием запуска кронов;
- и многое другое.

Формат при этом максимально абстрагирован от инфраструктурных деталей и прост в использовании.
Политики конфигурируются через файл auth.toml — по аналогии с app.toml. Вот почему мы решили так сделать:
- разработчики уже привыкли к toml;
- можно логировать и апрувить изменения через git и настройки codereview;
- можно использовать канареечное тестирование;
- разработчикам не нужно погружаться в реализацию.
Структура auth.toml состоит из двух разделов: default и policy. Они позволяют задать общие правила и конкретизировать их для отдельных ручек.

Политик может быть несколько. Главное — не повторять ручки, ни внутри политики, ни внутри всего auth.toml, чтобы избежать наложений. Это контролирует наш валидатор.
В политиках мы указываем набор ручек и перечисляем клиентов, которые имеют к ним доступ. Всем остальным на эти ручки доступ запрещен.
Какие типы клиентов существуют:
- сервисы — сервисы внутри PaaS.
- пользователи — логин одного сотрудника (например, user:apgubarev) или целый юнит (например, user.unit:architecture).
- внешние зависимости (например, ext:pass-bot).
Генерация auth.toml происходит через утилиту auth init. Мы встроили её в свой внутренний CLI. Она позволяет не переписывать все ручки из брифа в auth.toml вручную и не допускать ошибок.
Утилита берёт потребителей из реестра, о котором я писал выше, и добавляет их в секцию default. Дальше разработчик может донастроить auth.toml через отдельные policy.
Также auth init добавляет в файл auth.toml мини-документацию, которая позволяет быстро вспомнить, какие разделы за что отвечают.

В итоге для пользователя вся конфигурация политик происходит в одном файле auth.toml. Всё остальное делаем мы.
Техническая реализация
У нас было два основных варианта, как сделать межсервисную авторизацию.
1. Запилить middleware для используемых языков. Но у такого решения есть ряд проблем:
– реализации на разных ЯП будут различаться и поддержка усложняется кратно количеству библиотек
– сложно обновлять — нужно вносить изменения в каждый сервис, а их я напомню 2500 и их количество растет.
– инфраструктурный слой протекает в сервисы — концептуально плохо.
2. Реализовать авторизацию на базе service mesh.
+ нет проблем, свойственных первому решению.
+ нагрузка только на команду PaaS, пользователям авторизации ничего делать не нужно.
В итоге мы остановились на service mesh на Istio. До Istio у нас было самописное решение, но сейчас Istio отвечает всем нашим потребностям — правда, приходится платить сложностью. Но это уже отдельная история.
Основной принцип любого service mesh — перехват входящего трафика и заруливание на сайдкар.
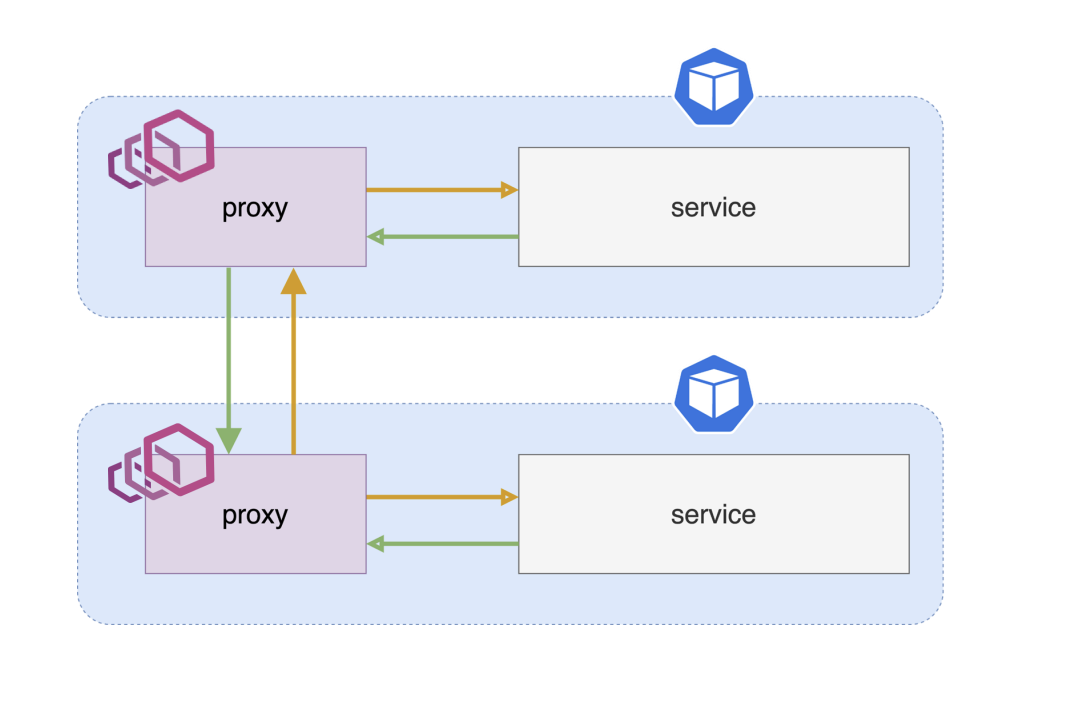
- В каждый под, где нужен service mesh, добавляется сайдкар.
- Трафик приходит в сайдкар.
- Из сайдкара трафик проксируется в сервис.
Обратно — аналогично. Сервис шлет трафик не напрямую, а через прокси.
Аутентификация через mTLS
Прежде чем реализовывать авторизацию, нужно узнать имя клиента. Для аутентификации мы используем mTLS. Он уже был реализован у нас ранее для:
- шифрования чувствительных данных. Трафик даже внутри кластера может быть небезопасным, поскольку там работает куча сторонних библиотек.
- защиты от несанкционированного доступа. Например, по IP пода. Чтобы постучаться в сервис, в mTLS нужен персональный сертификат. Сервис может управлять доступами, используя имена этих сертификатов.
Подробнее про использование mTLS в Авито можно почитать в статье моего коллеги.
Автоматизация выдачи сертификатов
TLS-сертификаты для доступа к сервисам можно выдавать вручную, но лучше — генерировать их автоматически. Для автоматизации выдачи сертификатов мы используем готовое решение — Spire.
Spire реализует стандарт SPIFFE, который описывает подход к идентификации и управлению секретами в инфраструктуре. Spire состоит из двух частей:
- Сервер — отвечает за выпуск новых сертификатов.
- Агент — выдает сертификаты.
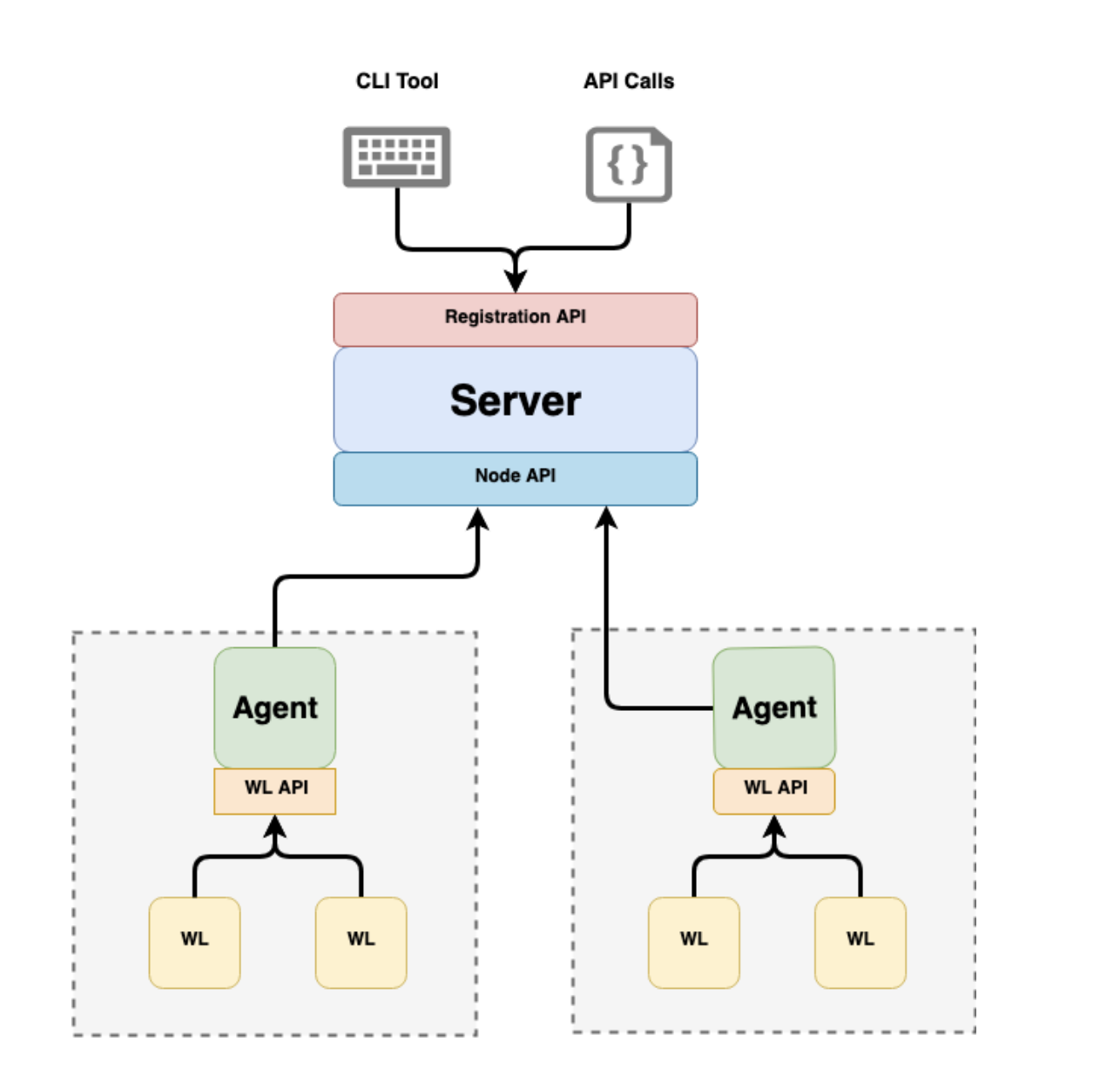
Вот, как работает автоматизация выдачи сертификатов с помощью Spire:
- Сервер выпускает новые сертификаты.
- Агент запускается на каждой ноде.
- Istio конфигурирует сайдкар так, чтобы он устанавливал соединения с другими сайдкарами по протоколу mTLS.
- Istio конфигурирует envoy: где и как он может получать сертификаты.
- Сайдкар приходит к указанному агенту и получает TLS-сертификат, с помощью которого шифрует трафик.
Подробнее про Spire и SPIFFE можно почитать в статье моего коллеги.
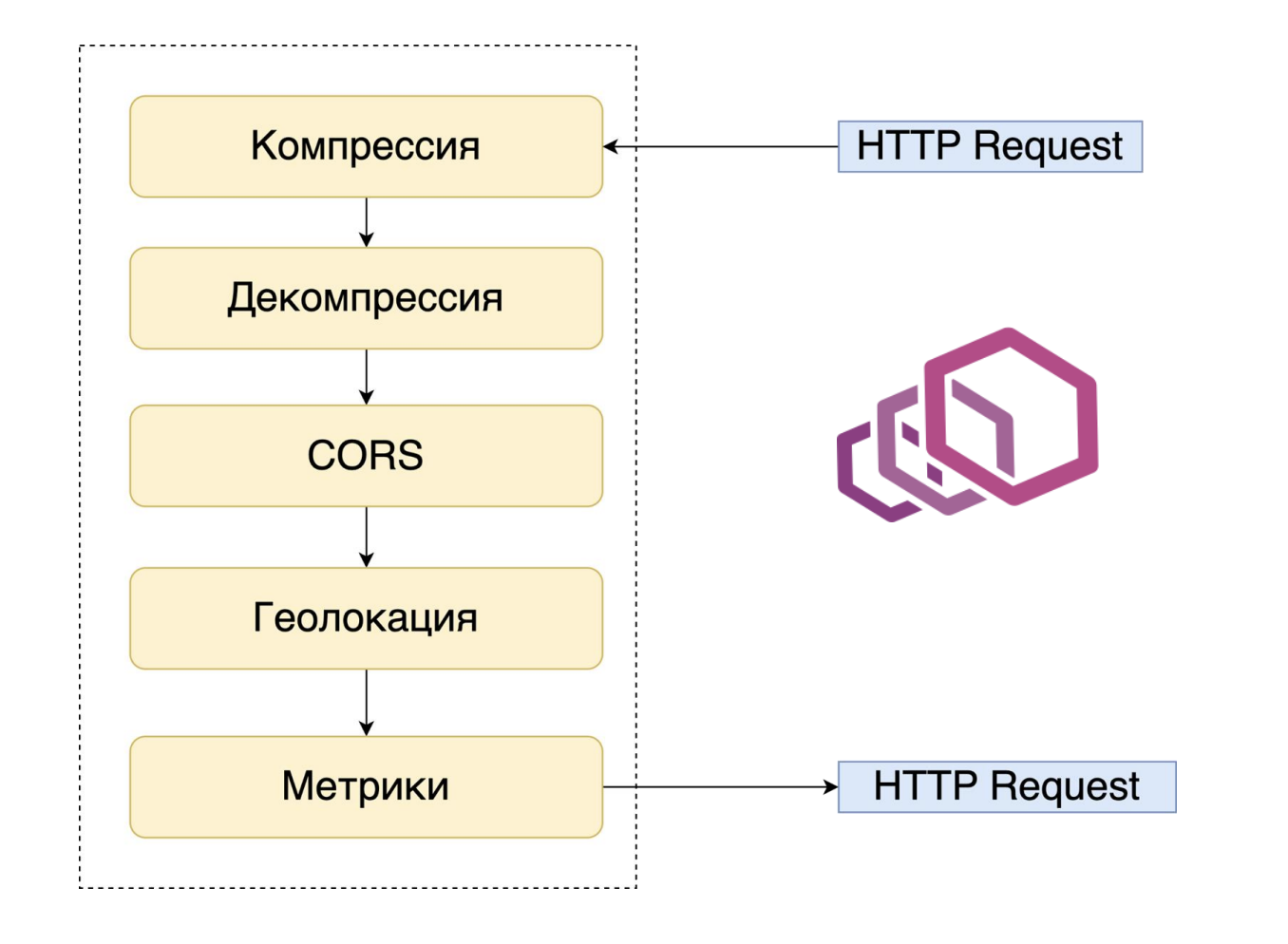
HTTP-фильтр
Istio в качестве сайдкара использует envoy. Внутри envoy запрос проходит через цепочку фильтров и идет в целевой порт внутри пода, если его не заблокировал один из HTTP-фильтров. В Istio много готовых фильтров, но можно написать и свои.
ext-authz спрашивает у некоего внешнего агента (можно подложить сюда что угодно, хоть самопис), можно ли запросу лететь дальше. Если запрос блокируется, envoy сразу отвечает кодом 403. До сервиса запрос даже не доходит.
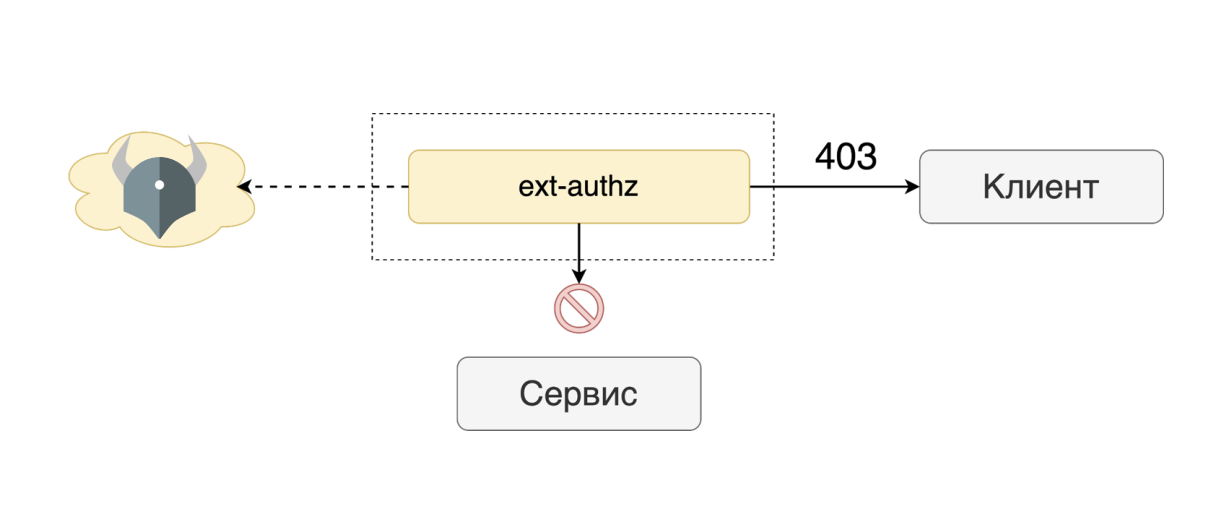
В качестве внешнего агента мы используем готовое и проверенное решение – Open Policy Agent.
Open Policy Agent
Open Policy Agent (OPA) — это CNCF-дипломированный проект, направленный на унификацию применения политик в различных технологиях и системах. Одно из назначений OPA — как раз service mesh. Плюс есть много готовых интеграций, в их числе — envoy.
Подробнее про Open Policy Agent →
OPA может работать в двух вариантах: как демон, или как Go-библиотека. В обоих случаях агенту можно передавать политики на языке Rego и данные в формате JSON.
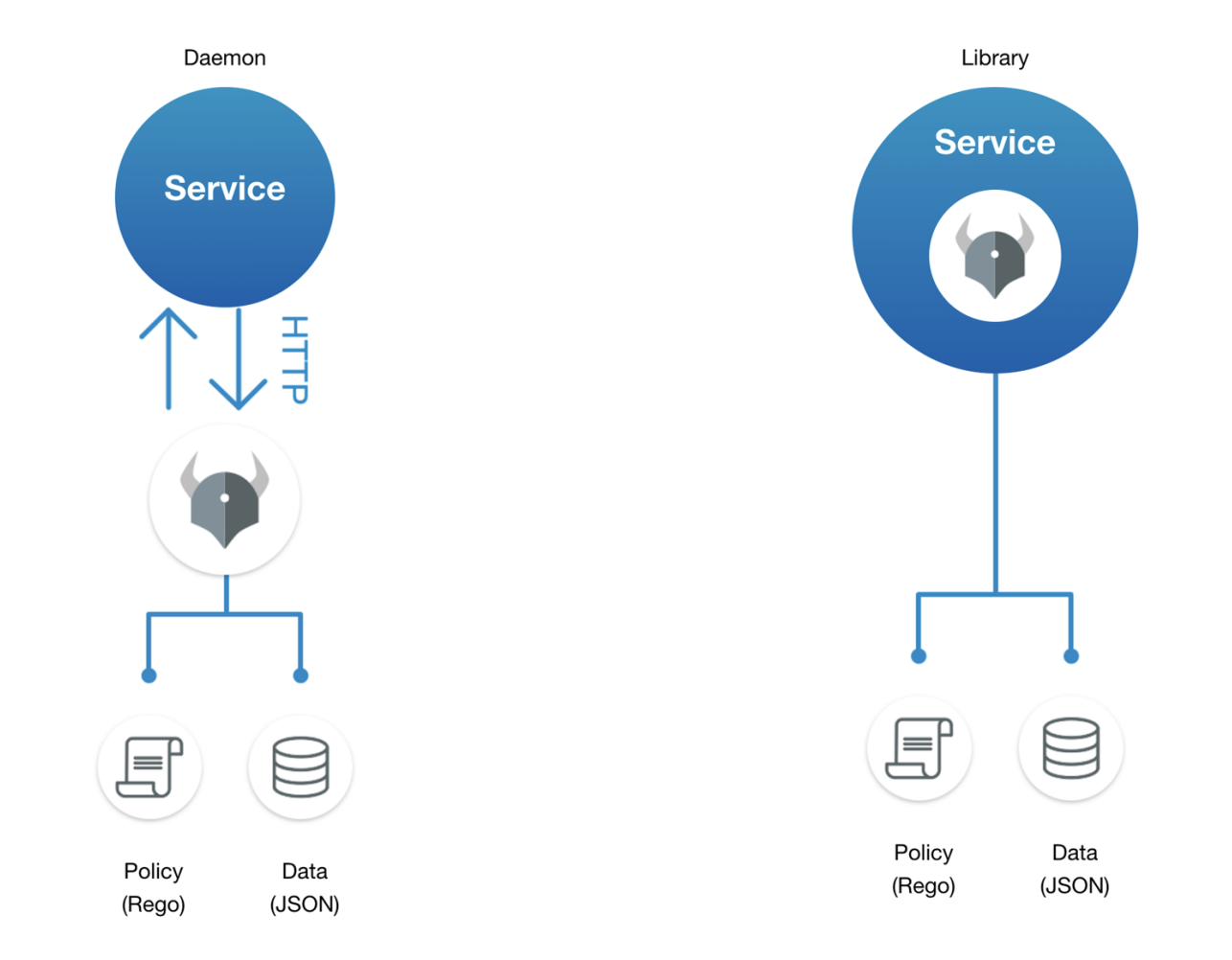
Rego — это собственный декларативный язык OPA для выражения политик над сложными иерархическими структурами данных.

Особенность Rego в том, что он позволяет описывать сложные политики сокращённым синтаксисом — буквально в одно выражение. Для нас это было полезно, поскольку в поддержке можно очень быстро «продебажить» код глазами, даже не открывая IDE.
Другие плюсы Rego:
- читабельность. Например, прогон многомерного массива в Rego можно сделать так: sites[].servers[].hostname.
- расширяемость. Поскольку Rego написан на Golang, в него легко добавлять свои плагины: например, для похода во внутренние API или БД.
- удобное тестирование и дебаг. Например, можно сравнивать политики двух сервисов на совместимость.
Перевод auth.toml в Rego
В нашей схеме разработчики описывают политики в auth.toml. А наша задача перевести этот конфиг на Rego, чтобы его понимал Open Policy Agent.
Вот, как мы реализовали перевод auth.toml в rego всего в пару сотен строк кода.
1. Общая часть. Забираем нужные входные данные, определяем тип клиента, устанавливает значения по умолчанию (например, allow = false).
2. Проходим по политикам в auth.toml. Если хоть одна из политик разрешает запрос, открываем доступ.
Итоговая схема
Подытожим, как работает межсервисная авторизация.
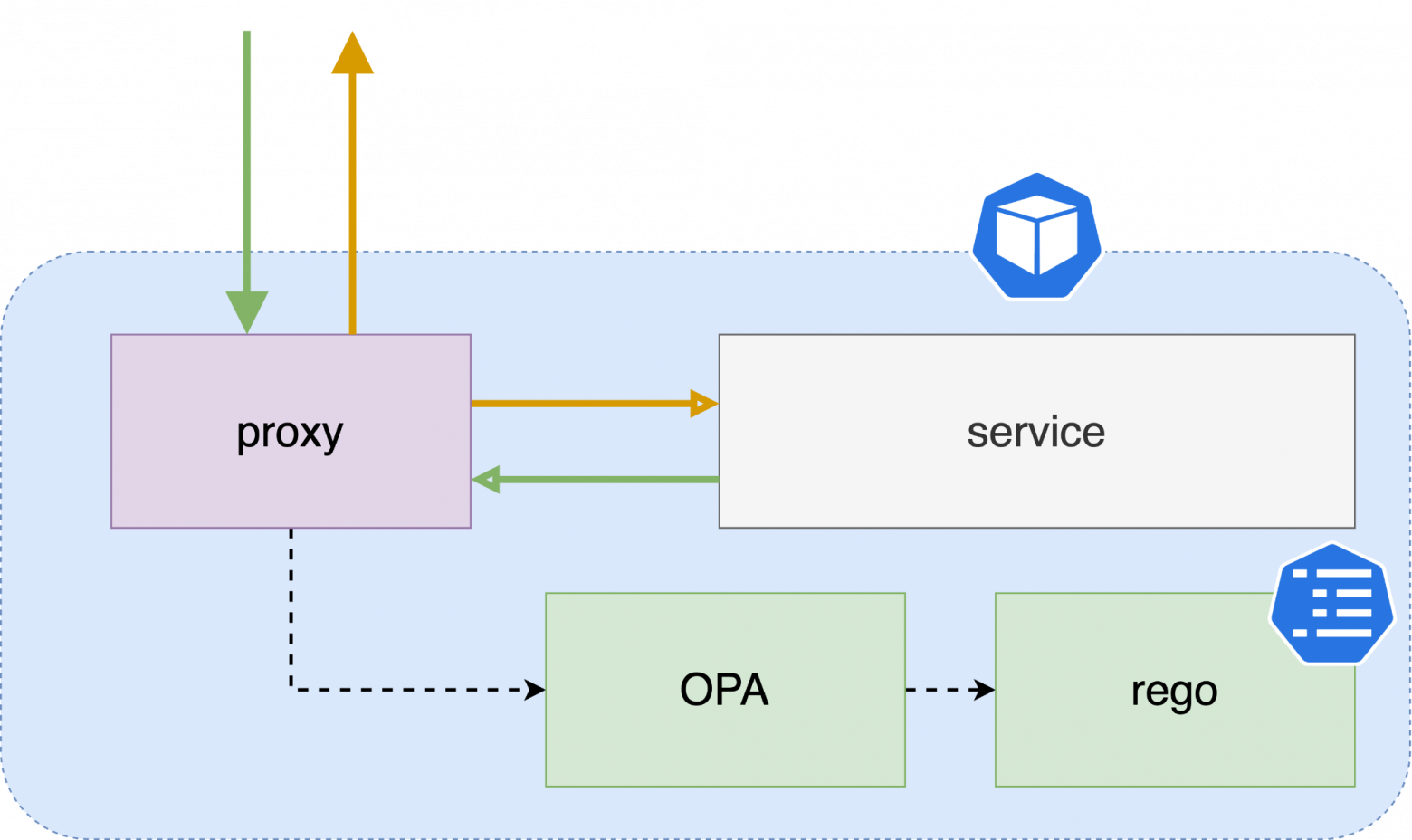
- Запрос попадает на сайдкар.
- Сайдкар спрашивает у агента, можно ли пустить запрос дальше.
- Агент обрабатывает rego-правила и решает, нужно ли блокировать запрос.
- Если запрос блокируется, клиент получает 403. Если нет — запрос доходит до сервиса.
Проблема: latency запросов к OPA
После реализации авторизации через запрос к сайдкару мы замерили latency. Оказалось, что envoy тратит дополнительные 10 мс для походов в OPA.
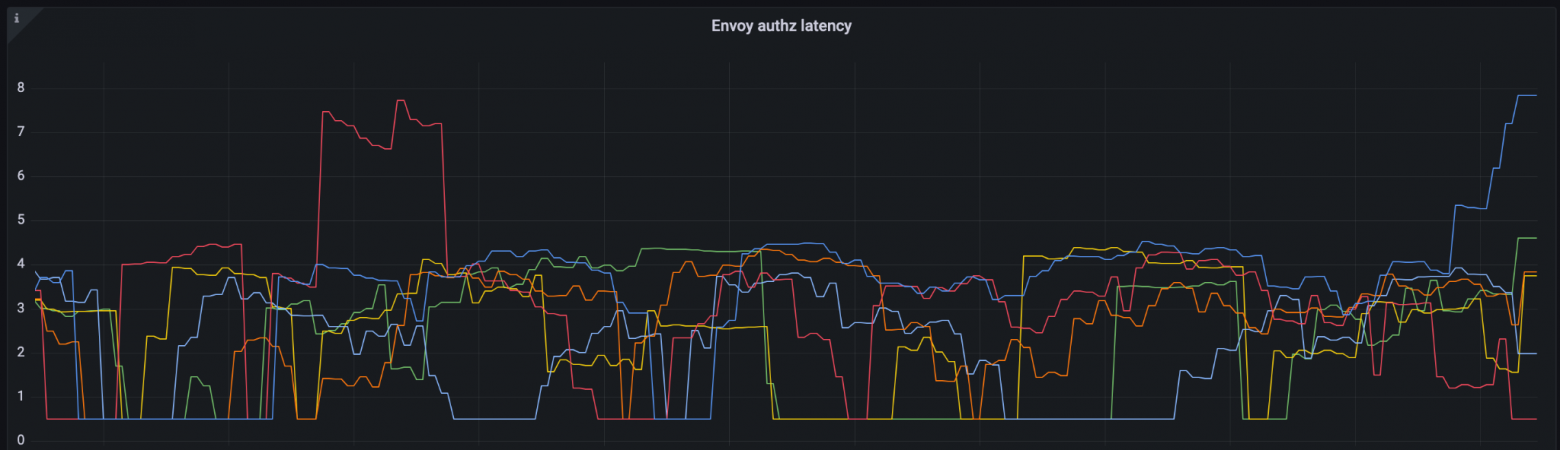
Для нагруженных сервисов это критично — им нельзя добавлять больше 2 мс. Поэтому для них такой latency стал бы блокером для использования авторизации.
Мы выяснили, что тратили время на одинаковые запросы к OPA. Ведь для пользователя apgubarev авторизационный ответ для ручки getUser будет одним и тем же на протяжение всей жизни пода (помним — политики меняются только при новом деплое).
Решение — кешировать. Envoy позволяет писать расширения разными способами, но нам лучше всего подошел Lua. Теперь запрос один раз посылается агенту, сохраняется в памяти и больше туда не ходит, если не было изменений в auth.toml. Прибавка — не больше 1 мс.
Валидация изменений в политиках авторизации
Недостаточно просто включить межсервисную авторизацию, нам было важно ничего не сломать. И у нас получилось.
Представим ситуацию: у сервиса A есть ручка getUser, на которую ходит сервис B. Владелец сервиса A закрывает доступ к этой ручки через auth.toml — сервис B ломается, получаем деградацию продакшена.
Мы сделали валидатор, чтобы не допускать таких ситуаций. Вот, как мы валидируем изменения, связанные с авторизацией:
— Предотвращаем закрытие существующих связей.
— Проверяем корректность auth.toml: указанные клиенты существуют, одна ручка указана только один раз и т.д.
— Не допускаем в прод с ошибками — блочим деплой.
Ещё мы завели реестр auth.toml. У нас уже был сервис схем для Brief, с помощью которого мы проверяли, что изменения не ломают обратную совместимость ручки или не удаляют поле, которое кто-то использует.
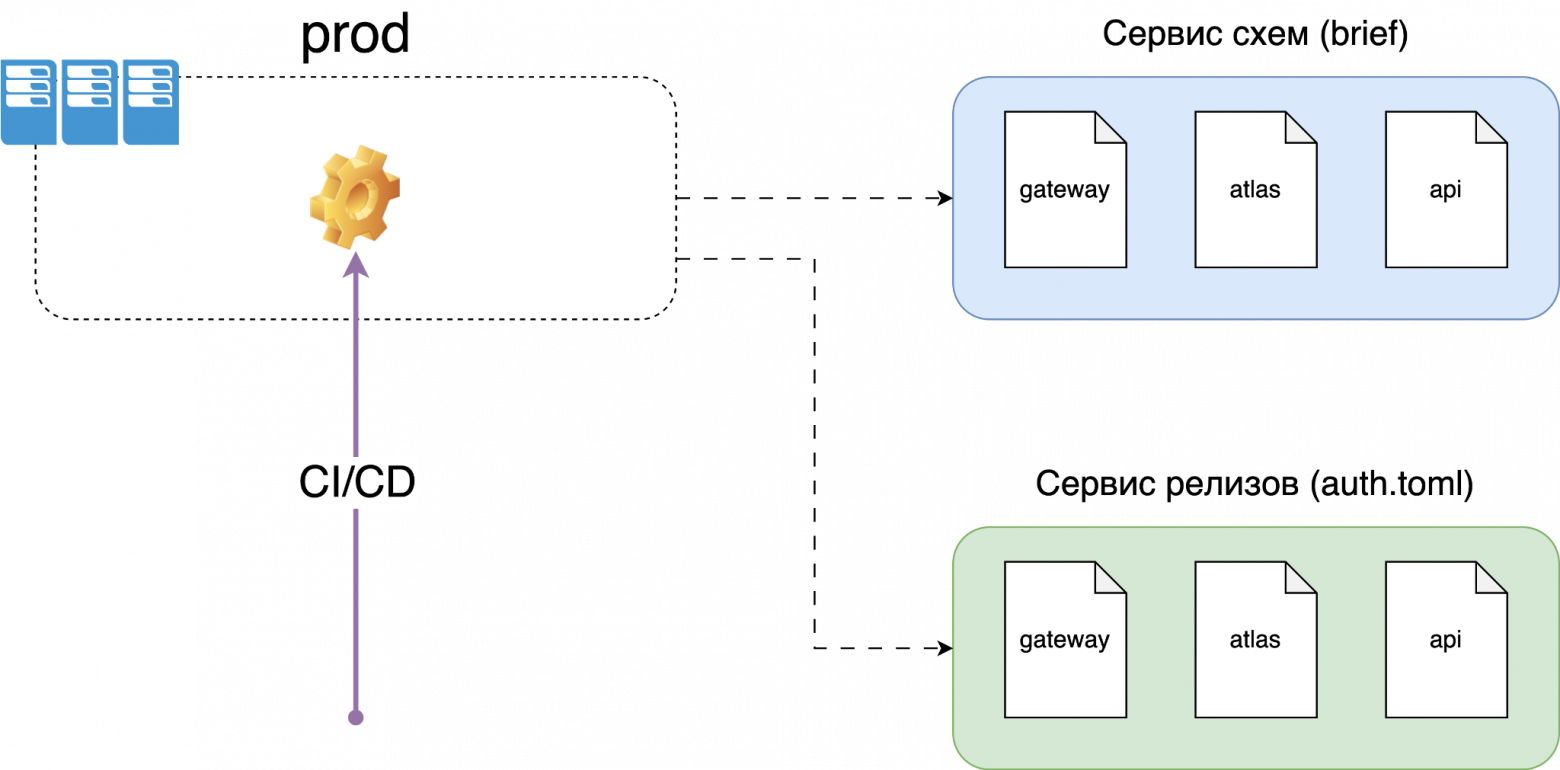
Перед деплоем сервиса мы достаём связи из реестра и тестируем rego правила: проверяем зависимости и клиентов.
Проверка зависимостей происходит следующим образом:
- Смотрим зависимости в brief-папке.
- Берём rego зависимостей из прода.
- Тестируем rego с данными текущего сервиса: передаём путь и клиента, убеждаемся, что пришёл положительный ответ.
Проверка клиентов выглядит так:
- Смотрим зарегистрированные клиенты у сервиса.
- Берём текущий rego сервиса.
- Проверяем доступ у клиентов: передаём путь и клиента, убеждаемся, что доступ есть.
Если билд падает, мы делаем одно из трех:
- Оставляем связь как есть — наткнулись на связь, которая реально нужна, разработчикам нужно договориться, что с ней делать.
- Помечаем связь как deprecated — связь уже устарела, нужно поставить задачу, чтобы её выпилить.
- Ничего не делаем — нашли ненужную связь.
Таким образом нам удалось не допустить поломок существующих связей. До сих пор не было ни одного инцидента связанного с этим.
Выводы
Что у нас получилось
- Простое платформенное решение для межсервисной авторизации. auth.toml не требует погружения, разработчики сразу начинают писать политики.
- Сервисы не затронуты. Ничего менять не нужно, достаточно добавить ещё один файлик конфигурации.
- Связи не сломаны. Все валидаторы отрабатывают корректно, пока не было ни одного инцидента.
Что поняли
Просто добавить авторизацию недостаточно. Как минимум нам ещё понадобилась генерация auth.toml и валидаторы для контроля изменений.
Что нам дали Open Policy Agent и rego
- Не надо писать и поддерживать своё решение.
- Понятная и читаемая политика для платформенной команды.
- Удобная работа с оргструктурой, включая все иерархические вложенности.
- Возможность тестирования доступов.
Полезные ссылки:

462 открытий7К показов

В середине ноября релизнули совместное исследование Хабра и ЭКОПСИ, цель которого – составить рейтинг лучших IT-работодателей России. Мы в Avito внимательно этот рейтинг изучили, выводы сделали, и готовы вам о них рассказать.

Авито проводит стажировку для аналитиков: присоединиться к ней могут студенты старших курсов и выпускники. Это возможность сделать первые шаги в карьере, получить опыт работы в крупной IT-компании и поработать с лучшими профессионалами на рынке. Рассказываем, какие этапы отбора надо пройти, чтобы попасть на программу, — а бонусом делимся советами от бывших стажёров и экспертов, которые общаются с потенциальными кандидатами.

Дмитрий Королев расскажет про распространённые ошибки при работе со слайсами, каналами и другими структурами в Go. Научимся предупреждать их исправлять на примерах.

Иван Якунин, продуктовый аналитик команды Fintech Marketplace, рассказал про то, как в Авито работают с Vertica, и на примерах объяснил, что такое проекции, и когда их стоит использовать.