


Определяем уровень интеллекта по страницам в VK с помощью ИИ
В статье рассказываем, как определить уровень интеллекта человека по его данным со страницы в VK с помощью ИИ.
2К открытий4К показов
Многие, кто начинают свой путь в искусственном интеллекте могут столкнуться с некоторыми общими правилами игры в этой отрасли. Все научное сообщество, кто разгадывает секреты «мышления машин» в целом делает следующие шаги:
- Проводят личные исследования и реализуют свои идеи;
- Выступают на разного веса конференциях со своими результатами (особенно секции workshops) по типу NeurIPS, WDS, WSAIA, MLP, CVPR и другие;
- Публикуются в материалах конференций и выкладывают свой код-решение, с инфографикой архитектуры в виде препринтов или статей на Arxiv;
- Другие ребята, кто не пишут статьи, занимаются реализацией этих самых архитектур и участвуют в соревнованиях по решению задач для ИИ, как например Kaggle, IASC, Zindi и другие;
- Затем студенты берут некоторые самые успешные методы и пишут на их основании свои дипломы, затем расширяют их в новое исследование и см. п. 1 настоящего списка.
Таким образом, мы проходи циклы развития разных полезных решений для отрасли. Все, кто занимается коммерческой интеграцией, берут свои идеи и решения из выше обозначенных ресурсов. Безусловно, есть большие организации, которые в целом ведут конференции и свои собственные воркшопы. Известные бренды имеют свои лаборатории.
Исследования Кембриджского Университета
В исследованиях «Personality and Patterns of Facebook Usage» Бачрача и Козинского рассматривается возможность определения типа личности по профилю социальной сети. Согласно опубликованным материалам, датасет составлял 180 000 пользователей, чьи данные удалось собрать посредством приложения «Мои черты характера» (опубликованного в 2007 году), в котором предлагалось пройти короткий опросник «Большая пятерка».
Обзор данных показал, что только 15 000 пользователей достаточно полно оформляли профиль социальной сети. В последствии оказалось, что только 5 000 профилей могут быть использованы в исследовании.
Команда Бачрача взяла следующие параметры из профиля социальной сети. Они отбирали наиболее присущие всем параметры для более независимой оценки.
- Friends: число друзей;
- Groups: число вхождений в группы;
- Likes: число «лайков»;
- Photos: число фотографий, загруженных пользователем;
- Statuses: количество созданных статусов;
- Tags: число раз, когда пользователь был отмечен на фотографиях.
После изучения данных и применение статистических методов анализа. Исследовательская группа получила следующие данные:
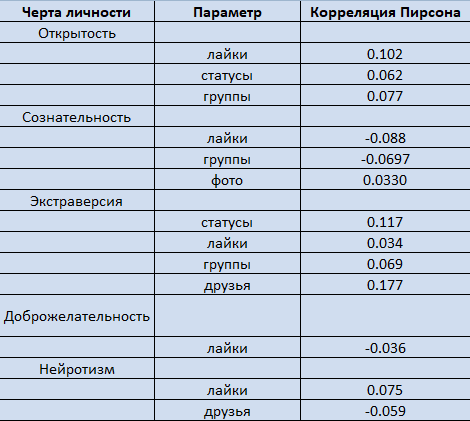
В таблице указана статистическая важность корреляции между чертами личности и параметрами профиля социальной сети (уровень важности p<1%)
Для того, чтобы проверить свою гипотезу и статистические данные, исследовательская команда применила multivariate linear regression для проверки прогнозной возможности параметров профиля социальной сети для угадывания черт личности.
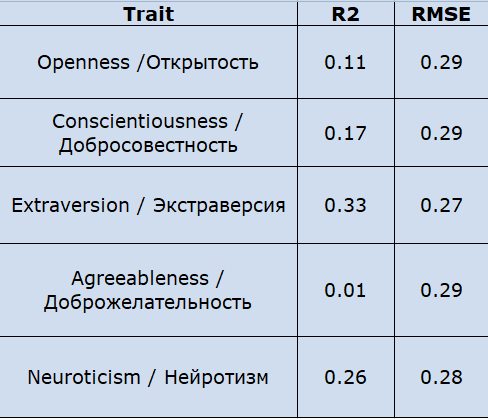
Таблица, показывающая прогноз черт личность, используя данные профиля социальной сети с помощью множественной линейной регрессии.
Изучение данных пользователей VK
Интересная проделана работа! Я решил провести свое исследование и проверить их подход. И, так как у меня не было под рукой данных из их исследования, то взял наш Российский вариант из социальной сети VK.
Кроме того, с помощью cvcode.ru мы накопили достаточно количество данных (около 9 тыс.) ответов на IQ тест. Это позволило сформировать следующую гипотезу: «Социальные данные влияют на уровень интеллекта» и проверить ее на реальных данных.
Первая группа данных представляет собой выгрузку с cvcode.ru.
CVCODE это система для определения своих личных качеств характера и интеллекта. Выгрузка данных представляет собой следующий набор:

Вторая группа данных представляет собой выгрузку данных из ВК на основании открытого api по id пользователей из первого набора данных.

С командой CVCODE удалось собрать беспрецедентную по объему базу данных пользователей, прошедших несколько важных тестов.
- Опросник Большая пятерка (как у Майкла);
- Тест интеллекта Вандерлика.
С социальной сети ВК собраны данные о группах, друзьях, подписчиков, лайки и комментарии пользователей и посты с ленты.
Проведен разведочный анализ данных двух наборов. Один из наборов представляет собой выгрузку из ВКОНТАКТЕ по колонкам: ’birthday’, ’city’, ’first_name’, ’followers’, ’friends’, ’groups’, ’last_name’, ’posts’.
Второй датасет из СИВИКОДа содержит колонки: ’Номер’, ’Фамилия’, ’Имя’, ‘Вконтакте’, ’Тест Биг5’, ’Тест IQ’.
IQ распределение результатов по всей выборке.
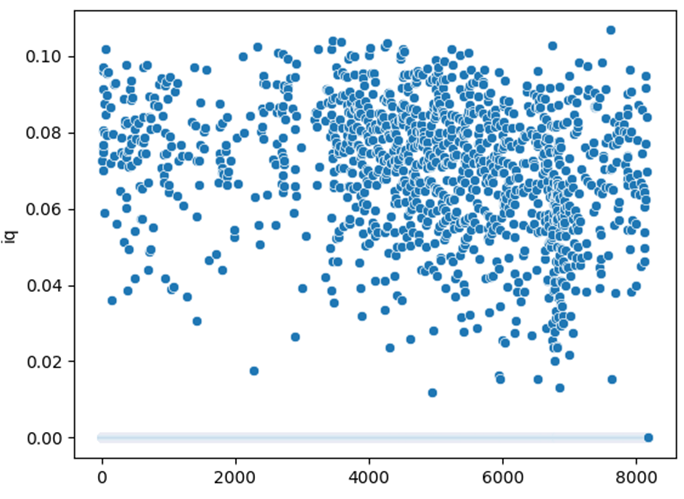
График хорошо иллюстрирует хорошее распределение, в котором мы не можем визуально определить линейные тренды, для задачи классификации это отличное исходное состояние, с которым будет интересно проводить эксперименты.
Визуализация распределения данных по количеству друзей

Количество друзей является одним из важных параметров для обучения модели. Интеллект является весьма важным в социуме качеством, поэтому возникает проблема связи его уровня с социальным поведением.
Все вместе взятое приводит к ясному заключению: сам по себе высокий интеллект выступает скорее положительным фактором адаптации.
Однако в том случае, если интеллектуально одаренный ребенок вкладывает свое время и силы в овладение какой-нибудь абстрактной областью, например, математикой или шахматами, он рискует выпасть из социальных контактов.
Интеллектуальные дети адаптивны. Не адаптивны те из одаренных детей, кто вкладывает силы в абстрактную и отдаленную от жизни деятельность. Исследование выявляет и сильные, и слабые стороны социального поведения интеллектуальных людей. Интеллектуальные люди, более объективны, меньше склонны поддаваться межгрупповым воздействиям. (Выготский).
Таким образом, наличие определенного количества друзей может коррелировать с уровнем развития интеллекта в данном наборе данных.
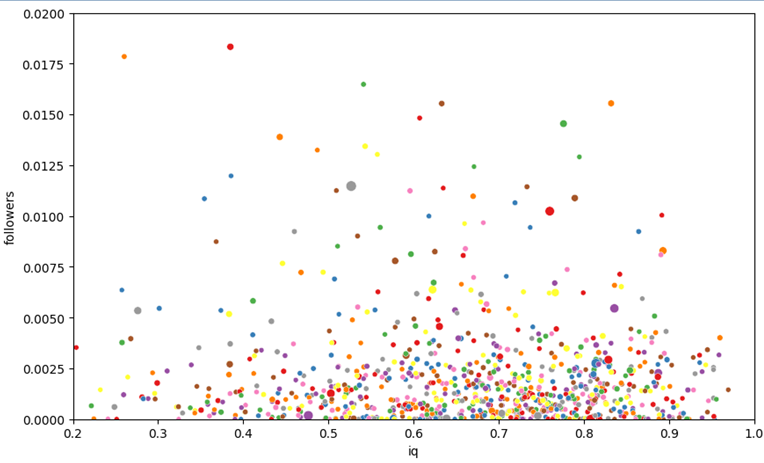
Визуализация распределения данных по количеству подписчиков
Второй социальный навык может быть обозначен как степень влияния на свое окружение. Подписчики не являются друзьями и получают именно тот контент, который они считают нужным делать публичным. Высокоинтеллектуальные люди не могут обеспечивать постоянный поток развлекательного контента, так как на определенные исследования требуется значительное время и затраты ресурсов.
В данном исследовании данных стоит придерживаться философии того, что социальная адаптация дается сложнее людям с высоким уровнем абстракции, а, следовательно, большое количество подписчиков скорей всего будет значить обратное, что невозможно.
Визуализация облака слов из постов

Дополнительный набор данных для классификации — это слова из постов, которые делали пользователи. Проведена процедура токенизации и очистки данных. Также, слова приведены в начальную форму именительного падежа, единственного числа. Основываясь на доводы исследований наследования вербального интеллекта, можно предположить, что он будет хорошо коррелировать с тем словарем, который получится достать из постов. К сожалению, много постов являются не авторскими и могут содержать чужие мысли, и семантику. Это является слабым местом такого анализа.
При разделении пользователей по медиане интеллекта на категории
- Dumb = 0,
- Smart = 1,
распределение длинны постов показывает, что количество слов в постах людей с более низким интеллектом больше чем у тех, кто показал высокие результаты по тесту. В основном количество постов достигается репостом записей других пользователей.
Таким образом, можно судить о том, что люди с низким интеллектом чаще делают репосты чужих записей.
Покончили с умными рассуждениями и давайте перейдем к непосредственно задачи классификации. Сможем ли мы на основе этих данных обучить классификатор, чтобы он по профилю ВК делил людей по уровню интеллекта?
Проведен подбор модели, показывающий наилучший результат. В ходе работы выбраны следующие модели классификации из библиотеки Sklearn:
- SGDClassifier;
- SVC;
- RandomForestClassifier;
- LogisticRegression;
- DecisionTreeClassifier.
Данные содержат результаты теста на интеллект Вандерлика, количество друзей в социальной сети Вконтакте, количество подписчиков в социальной сети Вконтакте и текст постов в профиле социальной сети Вконтакте.
- Цифровые данные: «Друзья», «Подписчики»;
- Категориальные данные: «Посты»;
- Целевые данные: «Уровень интеллекта».
Для решения задачи классификации, целевые данные — Уровень интеллекта были преобразованы на основании данных о среднем значении (mean):
- IQ = 1, при 0.01 < iq, и IQ = 0, при iq < 0.01;
- Для цифровых данных применен MinMaxScaler;
- Для категориальных данных CountVectorizer.
В ходе тестовых запусков всех 5 моделей использованы два подхода.
Первый подход заключался в выборе наиболее качественной модели при настройках Default. На каждую модель отправлены сначала Цифровые и Целевые данные, а затем Категориальные и Целевые данные. Это позволило сравнить модели между собой.
Использовались следующие метрики:
- Balanced accuracy;
- Confusion Matrix;
- F1;
- Recall;
- Precision.
Тестовые запуски приведены в таблице
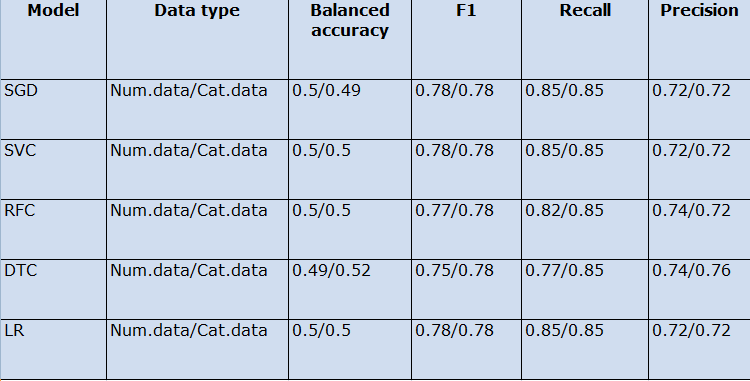
Очевидно, что похожие показатели по параметрам являются признаками проблем с датасетом или с вопросом изоляции данных. Данная гипотеза ошибки будет проверена в следующей работе, с использованием других моделей.
Также, стоит применить балансировку классов, так как в самом начале классы поделены не совсем равномерно при разбиении на два класса по границе mean.
Классификация на объединенных данных c подбором гиперпараметров
Проведенными исследованиями выбрана модель DecisionTreeClassifier. Подбор гиперпараметров осуществлялся GridSearchCV.
Использованные параметры:
- ’classifier__max_depth’: range(2, 10),
- ’classifier__min_samples_split’: range(2, 11),
- ’classifier__max_features’: range(2, 10).
Полученные результаты:
- Best CV score (mean) = 0.825;
- {’classifier__max_depth’: 5, ’classifier__max_features’: 8, ’classifier__min_samples_split’: 5};
- Train accuracy: 0.8269137006338372;
- Balanced accuracy: 0.503399708596406.
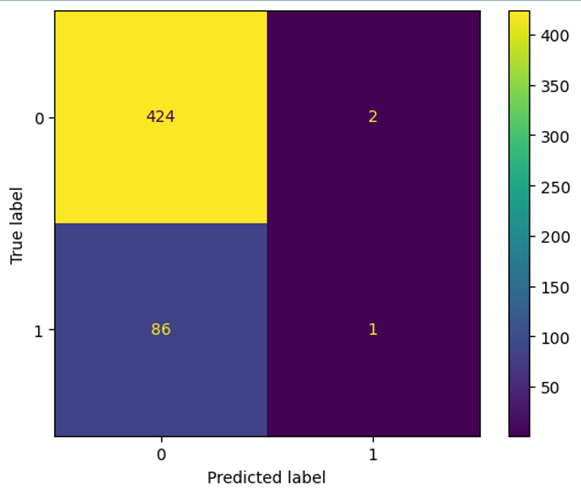
Выводы:
- Стоит обратить внимание на структуру данных и разделение их на тестовую и тренировочную выборки. Провести исследования векторизации категориальных данных. Изменить подход к нормализации числовых данных.
- На последнем этапе исследованы модели бустинга на данных социальной сети Вконтакте и данных тестов cvcode.
В ходе работы исследованы стандартные модели библиотеки Sklearn:
- AdaBoost;
- GradientBoostingClassifier;
- RandomForestClassifier;
- CatBoostClassifier;
- XGBClassifier.
На пробном запуске каждой из модели на данных собраны следующие результаты:
Оборудование:
- MacBook Air (Retina, 13-inch, 2020);
- Процессор: 1,1 GHz 2‑ядерный процессор Intel Core i3;
- Память: 8 ГБ 3733 MHz LPDDR4X;
- Видеокарта: Intel Iris Plus Graphics 1536 МБ.
Метрики:
- Balanced Accuracy;
- ROC-AUC;
- f1-score.
В ходе первичного анализа данных сформирована тепловая карта по корреляции элементов между собой.
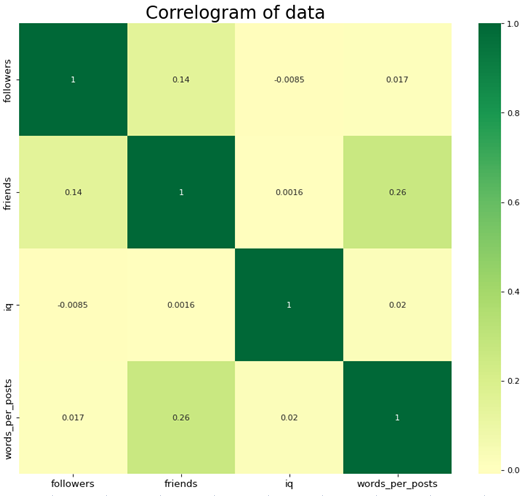
Как видно из представленной матрицы — корреляция в наборе данных слишком слабая. Можно сказать, ее вообще нет. Информация о данных в таблице ниже.
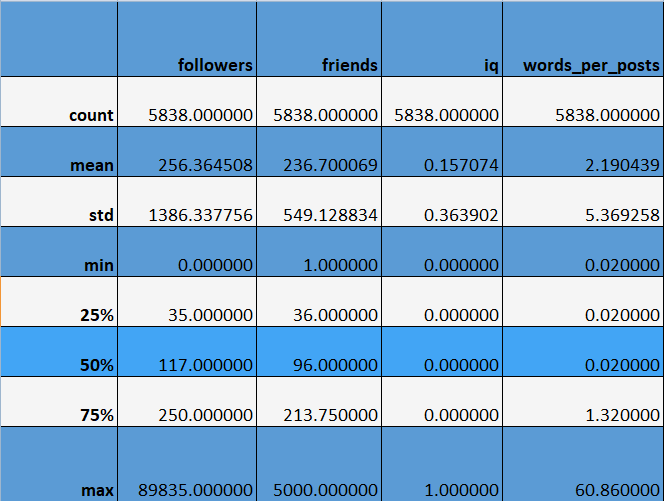
Параметры запусков:
- Random_state = 123;
- Learning_rate = 1;
- N_estimators = 1000.
AdaBoost
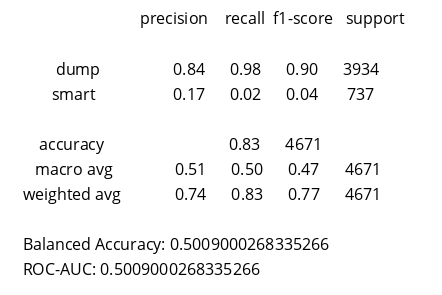
—————————————————————————
CPU times: user 2.4 s, sys: 73.6 ms, total: 2.47 s
Wall time: 2.81 s
GradientBoostingClassifier
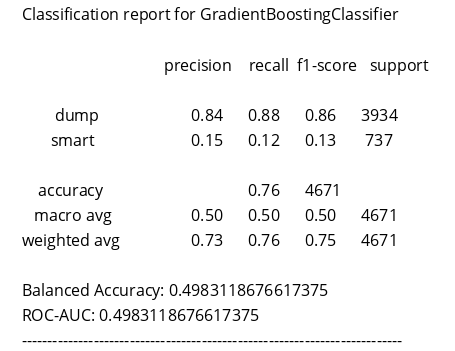
—————————————————————————
CPU times: user 1.22 s, sys: 25 ms, total: 1.24 s
Wall time: 1.34 s
RandomForestClassifier
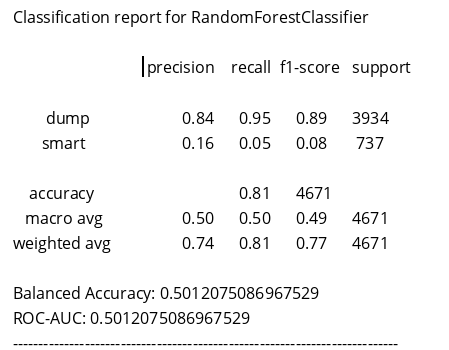
—————————————————————————
CPU times: user 3.04 s, sys: 57.1 ms, total: 3.1 s
Wall time: 3.26 s
CatBoostClassifier
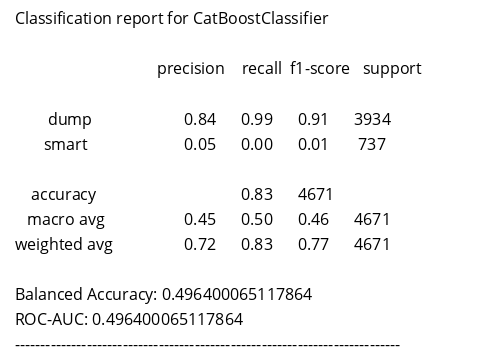
—————————————————————————
CPU times: user 2.11 s, sys: 181 ms, total: 2.29 s
Wall time: 1.2 s
XGBClassifier
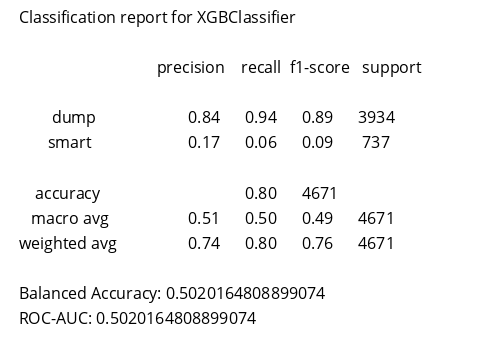
Balanced Accuracy: 0.5020164808899074
—————————————————————————
CPU times: user 336 ms, sys: 12.8 ms, total: 348 ms
Wall time: 144 ms
Наибольшую точность и скорость показал метод XGBoosting. В дальнейшем будем использовать для экспериментов с подбором гиперпараметров.
XGBoosting model подбор
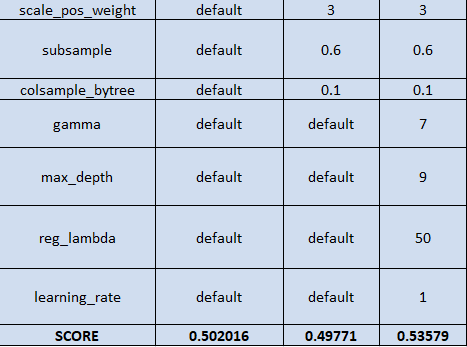
Выводы
Постепенный подбор гиперпараметров позволяет значительно улучшить качество модели. Исследованные данные не обладают достаточной корреляцией, чтобы можно было построить точные прогнозы, но даже с учетом отсутствия зависимостей, за счет подбора параметров удается получить прогнозную точность.
Очевидным преимуществом бустинга является то, что он может создавать модели с высокой точностью прогнозирования по сравнению почти со всеми другими типами моделей. Одним из потенциальных недостатков является то, что подогнанную усиленную модель очень трудно интерпретировать.
В дальнейшем следует больше внимания уделить данным и расширить информационное поле по социальному поведению, так как данных извлеченных для данного исследования явно недостаточно.
Заключение
Проведенные исследования показывают недостаточность данных для построения уверенных прогнозов. В целом, направление исследования социального поведения в сети интернет во много отражает нашу индивидуальность, вместе с тем, количество друзей и подписчиков-последователей скорей всего имеют слабую корреляцию с тем какой у нас интеллект.
Необходимо расширять диапазон данных и добавлять новые сведения: количество фотографий, количество историй, количество видео, количество лайков, количество репостов, и общая виральность информации.
Команда М. Козинского в течении 10 лет ушла в более тщательное изучение всего профиля социальной сети. Наличие большого количества категориальных данных позволяет тренировать более точные модели для определения типа личности. Стоит также проверить гипотезу с корреляцией данных большой пятерки с данными социальной сети ВКонтакте. Но это уже другая история.

2К открытий4К показов

Выберите лучшие нейросети для написания курсовой работы. Ознакомьтесь с нашим списком лучших ИИ, которые сделают процесс создания диплома проще и быстрее!

Кирилл Васильев, руководитель кластера кросс-функциональных команд в RuStore, рассказывает, как создать популярное приложение.

Приложение Sora от OpenAI побило рекорд ChatGPT: 1 млн скачиваний за 5 дней, вирусные ИИ-видео и функция Cameo с лицами пользователей

Sony запатентовала ИИ, предсказывающий действия игроков для улучшения отклика и снижения задержек в играх, но технология вызвала споры среди геймеров