


Обучение нейросети с подкреплением. Прямиком из 2005
Рассказываем, как обучать нейросеть с подкреплением: поощрять за правильные действия и наказывать за неверные шаги. На примере из 2005 года!
1К открытий2К показов
Да, это так называется: “обучение с подкреплением”, но когда я начинал писать этот проект, в 2005 конечно терминов не знал. Да, май 2005-го, омг, сам в шоке. Суть этого метода обучения в том, что сетка поощряется за хороший результат и наказывается за плохой результат. В общем случае, метод не требует наличия целевой функции, и поэтому отлично подходит для моей задачи. Возможно кстати, это единственно подходящий к этой задаче метод.
Сама задача звучит так: создать симуляцию среды, запустить в нее нейронные сетки, позволить им мутировать, наследовать веса, жить, и со временем, из поколения к поколению, повышать свою адаптированность к среде. Задача максимум – чтобы сетки стали такими крутыми, что им пришлось бы адаптироваться к своим соседям. Увидеть коэволюцию в компьютерной симуляции – вот программа максимум. Эта положительная обратная связь в природе порождает самые интересные виды существ и их взаимодействия. Это фрактальность, кучеряшки выросшие из элементарных правил естественного отбора. Мне было бы интересно их понаблюдать и поиграть с ними. Но до этого пока далеко.
И да, имеется в виду эволюция поведения, а не эволюция физических параметров существ. Почему? По двум причинам:
- Чтобы получить эволюцию физических параметров, ну там, количество конечностей или способность к терморегуляции, эти самые параметры программисту надо напрограммировать в своих программах. Это максимально скучно, согласитесь. А эволюция/коэволюция поведения существ способна удивить программиста, хочется верить.
- В перспективе хочется попробовать уже обученную сетку посадить на железку с колесами и камерами, чтобы посмотреть как она освоится с физическим “телом”.
Архитектура приложения простая, плюс-минус сохранялась во всех реинкарнациях приложения:
Все интересное происходит в функци processCreatures().
В функции processWorld() мы поощряем или наказываем существо, в зависимости от ситуации.
Для примера: в первой реализации приложения существа подбирали функцию sin(). Мир для каждого существа генерировал случайный инпут “x”, далее существо делала расчет своей сети, получая выход, скажем “o”. Далее мир сравнивал инпут с целевым значением, расчитывая ошибку=abs(sin(x)-o).
Далее мир наказывал существ, у которых получилась максимальная ошибка. У всех существ было определенная стартовая энергия, и с каждой итерацией, эта энергия уменьшалась, в зависимости от ошибки. Те существа, которые ошибались чаще других, не доживали до репродуктивного возраста. Существа, которые давали больше правильных ответов, в соответствующий момент своей жизни размножались. В соответствующий момент они создавали свои полные копии с небольшими мутациями, с управляемой вероятностью и силой мутаций.
Эту версию приложения я набегами мучил: проверял, отлаживал, переписывал. В итоге кое-что вымучил.
Далее копирую куски из дневника.
В общем, удалось прикрутить визуальное отображение результатов обучения сети.
В любой момент можно остановить симуляцию, получить список существ, ткнуть в каждое существо, и посмотреть насколько его результаты совпадают с целевой функцией sin().
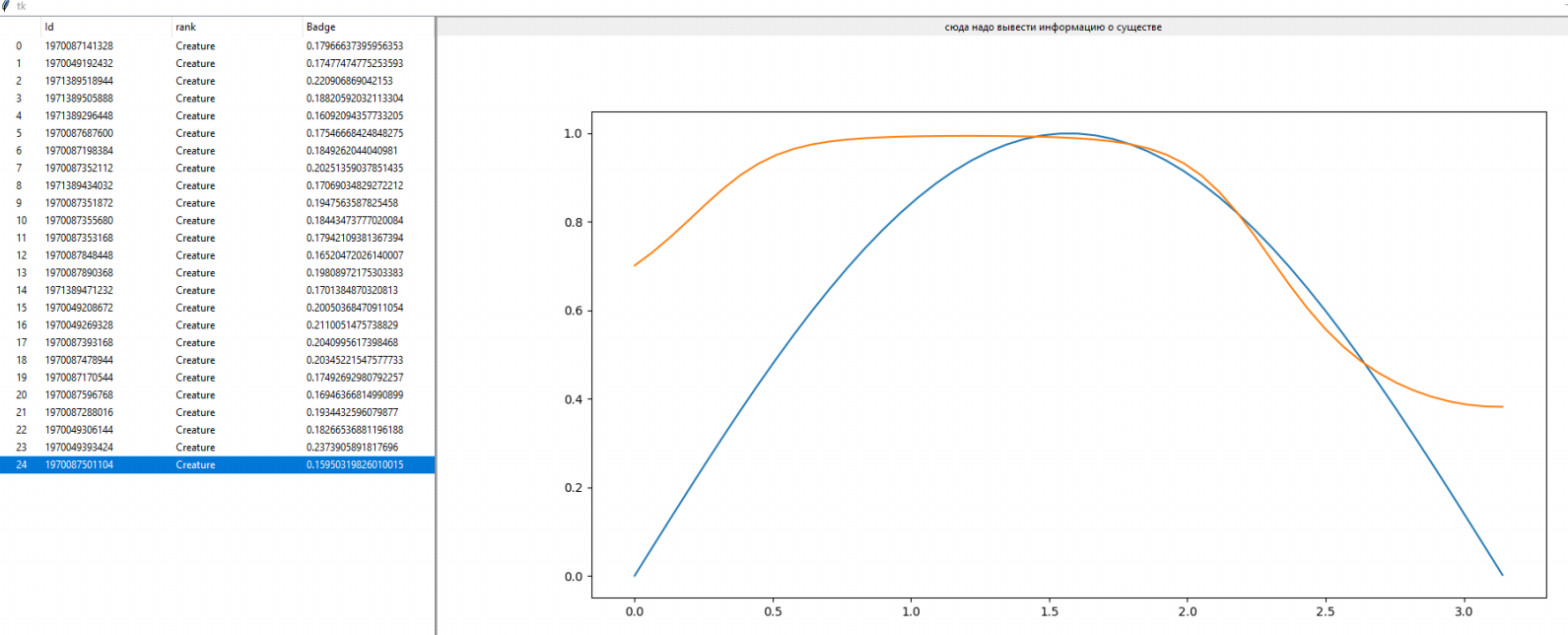
Обнаружилось:
1. В целом обучение быстро, в пределах пары минут, находит сетку, которая одним крылом облизывает синусоиду.

2. Постепенно, уже медленнее, отрезок, на котором существо более-менее точно попадает в синусоиду, расширяется. Если погонять симуляцию сутки и более, будет получено довольно точное попадание в синусоиду, за исключением маленьких отрезков по краям.Ну, практически sin().
3. Так как на всем отрезке случайные числа выбрасываются равномерно, то чем больше уже обученный отрезок, тем меньше вероятность, что в конкретной итерации существо будет тестироваться на необученных кусках отрезка. Так как разные существа получают – каждый свое задание, то получается, что слишком малое число существ получает задание на необученном отрезке. В общем, это ведет к тому, что процесс обучения сети на хвостовых отрезках слева и справа, становится все медленнее и медленнее.
4. Возможно это также как-то связано с особенностью конкретной конфигурации нейронной сети, у меня тут было три слоя: [5,5,1]. Возможно это избыточно, и поэтому так долго затягивалась сходимость.
5. А, еще заметил влияние констант мутаций (вероятность и сила мутаций) – на обучение. Прямо видно, когда сетка упирается в эти константы и ее начинает колбасить у синусоиды – чуть выше, чуть левее, чуть ниже и т.д. При желании – можно понизить эти значения, и получить более точное попадание в синусоиду, но симуляция будет крутиться дольше, раз мутаций меньше и из значения – ниже.
В общем, процесс обучения в том виде как он задумывался реализован, и он дает предсказуемый, понятный процесс отбора сетей, постепенно улучшая сходимость.
Все довольно предсказуемо и можно тут поставить точку, на данной версии evol.py.
Почему не надо упираться в более точную сходимость, в точное попадание в синусоиду?
Потому что это синтетическая задача – обучиться синусу можно, но, предположительно в том отборе, которому я хочу научить существа, в этом наборе задач, такая точность не потребуется.
По идее, существо, которое хотя бы начинает ковылять примерно в сторону еды, уже будет заметно приспособленнее, чем существо которое просто плутает бесцельно.
А более точное обучение приведет к тому, что существа будут действовать с хирургической точностью, выигрывая у тех, кто замешкался. Наверное это круто, но как-то больше заряжает именно стадия перехода существа от бесмысленного блуждания к ползанию в сторону еды.
Итог: процесс вот такого обучения – существа, еда, кормление за успешные действия (угадывание синуса), потребление энергии в каждую итерацию, размножение, получение на вход – каких-то данные, расчет и калькуляция выходов – вот это все реализовано в симуляции.
Конец цитаты из дневника.
Помню, тут был приятный момент, чувство завершенного этапа.
Попережёвываю еще пару моментов… Я же довольно длительное время мусолил именно сходимость к sin(), и вообще сначала я наивно думал, что механика такова, что она неизбежно ведет к постепенному неуклонному увеличению адаптации. Да, я думал про мутагенный шум, но решил для себя, что все равно должно сходиться. Потому что по алгоритму, пищу получают всегда самые приспособленные, мутанты как бы отбракуются по умолчанию. Это допущение мне дорого стоило. Много-много человеко-часов. Это решение было ментальной ловушкой. Я все время не доверял коду, искал несуществующую логическую ошибку. Я вычислял среднюю на популяцию ошибку и каждый раз при запуске я надеялся увидеть уменьшение ошибки до 0.3, потом до 0.1, потом до 0.05 и так далее, до чисел, близких к нулю. Там график в tkinter Дениска написал, как обычно со своими итераторами-генераторами, и визуально я всегда ждал, что кривая ошибки сползёт вплотную к нулю. Много раз переписывал, вычитывал и отлаживал, но этого не удавалось добиться. Помню пару запусков длинной в неделю, представляете 168 часов непрерывной работы симуляции? Да, бывает, упарываюсь.)))
В конце концов, в пыли очередного рефакторинга, я вывел наглядно синусоиды – и стало видно что их “колбасит” у оптимума. И тогда я догадался, что проблемы с алгоритмом нет, это просто мутагенный шум. Изначально было неправильно надеяться, на бесконечную сходимость.
Можно, наверное, добиваться лучшей сходимости, манипулируя в режиме runtime переменными вероятность мутации и сила мутации. Но я уже плюнул и решил, что этот инсайт уже достаточно полит моим потом. Намного более интересно поиграть с существами ползающими по карте. Об этом дальше.
Так, для себя отмечу, хочется еще написать про пост о всяких граблях, на которые наступилось, пост про целевую функцию, и пост про то, что начатую работу не надо заканчивать.

1К открытий2К показов

Исследователи проверили, как ИИ проходит Super Mario Bros. Claude 3.7 справился лучше всех, а GPT-4o и Gemini 1.5 Pro показали слабые результаты

OpenAI достигла оценки $500 млрд, став самой дорогой частной компанией в истории и обогнав SpaceX, благодаря росту доходов и пользователей
Microsoft предупредила: агентный ИИ в Windows 11 может быть уязвим к XPIA-атакам и скачивать вредоносные файлы без ведома пользователей

Южная Корея запретила загрузку китайского ИИ DeepSeek из-за передачи данных ByteDance. Это уже третья страна, заблокировавшая приложение