


Пет-проект на React. Как мы «озвучивали» интернет

Создали пет-проект на React, который может озвучивать любой текстовый контент и делать из этого что-то наподобие подкастов.
4К открытий4К показов
Меня зовут Антон Малыгин. Я iOS-разработчик с опытом работы около 10 лет.
На протяжении всей карьеры я всегда занимался своими пет-проектам, собственно, после одного такого проекта, эта карьера и началась.
Какие-то из них доходили до релиза и успешно работали, один даже сейчас работает. Какие-то или вообще не видели свет, или видели его недолго.
Да, мне не удалось заработать миллионы, создать успешный стартап, но я получил ценный опыт, в том числе и в разработке с другой стороны — backend.
Сегодня я расскажу как раз про такой проект, который мы смогли довести до релиза, но прожил он недолго.
Идея
Дело было в 2018 году. Каждые выходные я ездил за рулем по разным делам и слушал радио или музыку, что, в конце концов, надоедало, и хотелось послушать что-то интеллектуальное или интересное. В метро по пути на работу я обычно читаю: статьи на разные темы, новости и т.д. В это же время, мы с коллегой думали над разными идеями своего проекта, перебирали, обсуждали. И вот примерно таким образом родилась идея — озвучивать любой текстовый контент и делать из этого что-то наподобие приложения подкастов.
Мы разделились так — я делал backend, коллега — мобильные клиенты на ReactNative и web-версию на React.
Первая версия
К тому моменту у меня был опыт Scala/Go на других пет-проектах. Поэтому стек был выбран именно такой.
Мне нравится использовать в своих проектах новые методики, недоступные в обычной работе, извлекая профессиональную пользу из проекта. Поэтому было принято решение разделить проект на микросервисы, используя Docker. Получилась примерно такая схема, где каждый модуль, кроме Text-to-Speech, — это отдельное приложение в контейнере.

API — основной модуль, который непосредственно разрабатывался мной. Основной стек — Scala, PlayFramework, Akka.
Это единое приложение, которое состояло из нескольких частей:
- API — обычный RestAPI, обработка http запросов, выдача ответов.
- Простенький Crawler, который получал из БД список сайтов, по которым надо пройтись (новости, статьи) и достать оттуда нужный контент — текст, картинку, краткое описание.
- Сервис для работы с Text-to-Speech от разных провайдеров.
Первые проблемы начались при создании парсера. Сначала мы хотели просто сделать парсинг нескольких сайтов, что я сделал с помощью scala-scraper. Но, во-первых, писать парсер под каждый сайт — плохо масштабируемое решение, а во-вторых, мы придумали фичу, когда пользователь может озвучить самостоятельно любую статью или новость, с любого сайта. Поэтому нам нужно было универсальное решение. Лучшее, что мы смогли найти — это readability.
Таким образом, я создал отдельный сервис в докер-контейнере на основе readability.
Он устроен так: на вход ему передается html-страница, после чего он возвращает чистый текст статьи или новости, естественно, без тегов и любой лишней информации.
Следующая задача — озвучить текст. Здесь можно выделить 3 проблемы:
- У каждого API TTS есть ограничение на размер текста для одного запроса.
- Не каждый сервис мог отдавать mp3, например, с ogg были проблемы со стандартным плеером на клиентах.
- Кроме конвертации в нужный формат, нужно было склеить озвученные части в один файл.
Первое, что нужно сделать после получения текста — разбить его на цельные части, состоящие из одного или нескольких предложений. Для этого я использовал очень полезный пакет icu4j. Пример кода из проекта:
Этот trait расширяет мой класс и создает массив строк из текста, размер которых не превышает заданный лимит, где каждая строка — это одно или более предложений.
Далее я создал интерфейс и 3 класса для работы с определенным API TTS.
Каждый класс получает на вход массив строк из кода выше и озвучивает их, получая несколько файлов. Потом склеивает их в один и конвертирует в mp3, если необходимо. Для этого шага я использовал ffmpeg. Очень полезная тула, о существовании которой я не знал.
На следующем шаге этот файл загружался в Object Storage. В первой версии я решил использовать довольно неплохое self-hosted решение — Minio. Там же хранилась вся статика, например, картинка/обложка для трека.
Каждый модуль (Web-приложение, readability, Minio и postgres) поднимался в отдельном docker контейнере и все это работало на одной тачке за 10$ в DigitalOcean.
В итоге эта архитектура имела 2 основные проблемы:
- Озвучивание прямо зависело от длины текста, что логично, и могло занимать очень много времени. Например, более минуты.
- Высокие требования к ресурсам, если мы ожидали, что одновременно что-то озвучивать и слушать будут, по крайней мере, более 10 человек.
Оптимизация и вторая версия
Решение первой проблемы в лоб — озвучивание всего контента сразу после парсинга. Плюсы:
- Простое в реализации решение
Минусы:
- Очень дорого (не забываем, что озвучивание — платный сервис)
- Не решает проблему, когда пользователь хочет озвучить статью по своей ссылке, потому что ему все равно приходилось ждать долго
Второй вариант, как это и было реализовано в итоге, озвучивать по требованию, но не использовать один файл для трека.
Плюсы:
- Пользователь может начать прослушивать неозвученный контент с минимальным ожиданием
- Озвучиваем по требованию, а значит на этапе MVP сильно экономим, потому что озвучивается только то, что запросили пользователи
Минусы:
- Сложность реализации
Путем беглого исследования решений, мы остановились на стриминге с помощью формата HLS.
В двух словах HLS — это файл-плейлист определенного формата и набор файлов с контентом, в нашем случае mp3. HLS очень хорошо вписывался в нашу логику с озвучкой, потому что, по факту, у нас уже получался набор mp3 файлов, и можно было их не склеивать, а просто привести к формату HLS. Возможно, в отдельной статье я расскажу подробнее нюансы HLS.
Теперь нужно было решить вторую проблему — с производительностью, не покупая дорогой тариф в DigitalOcean. Плюс хотелось бы получить легкое администрирование и заложить возможность масштабируемости.
В итоге родилась такая архитектура, которая добавляла +8$ к тарифу:
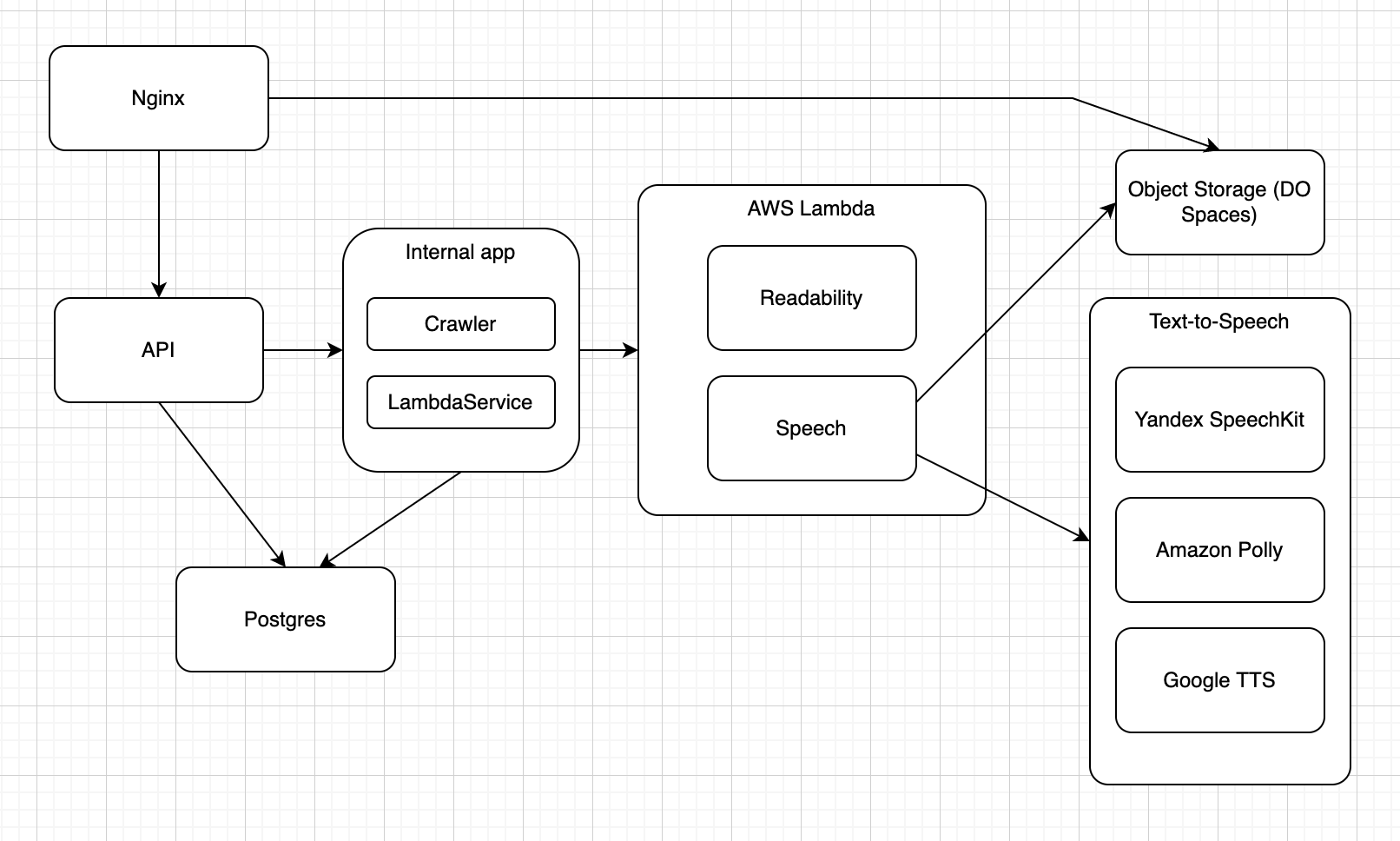
Первое — вынесение ресурсоёмких операций в такой замечательный сервис, как AWS Lambda. Туда переехали readability и, вынесенный из основного приложения, слой, отвечающий за взаимодействие с API TTS. Тут есть нюанс: пришлось переписать эту часть на Go из-за особенностей работы Lambda. Так как это «функция», а не запущенный процесс, есть зависимость от «холодного» старта. Поэтому jvm тут очень сильно отнимает производительность. Разработчики Lambda, конечно, делали некую оптимизацию, например, поддерживали функцию в «запущенном» состоянии какое-то время, но не было никаких гарантий, когда будет происходить «холодный» или «горячий» старт. В итоге по бенчмаркам Js или Go сильно опережали решение на JVM.
Плюсы Lambda — огромный бесплатный лимит на количество вызовов функций. Для проекта на стадии MVP получалось вообще бесплатно. И не нужно было заботиться о масштабируемости, потому что нет никакого процесса, а есть только вызов функций, работу которых гарантирует AWS.
Следующий модуль, который переехал из vps — Object Storage. Выбор пал на DigitalOcean Spaces, это аналог S3, с одинаковым интерфейсом, так что можно было использовать AWS SDK для работы с ним и переход с Minio оказалось достаточно простым. Основное преимущество Spaces — понятный тариф с ежемесячным платежом и огромным лимитом, которого с головой хватало для MVP.
Следующий шаг — разделение API и InternalApp (модуль, в котором живет Crawler, обработка/добавление контента и взаимодействие с Lambda).
Таким образом, теоретически, можно будет горизонтально масштабировать API, плюс появляется некая отказоустойчивость, если возникли проблемы с добавлением контента или Crawler-ом.
Последний шаг — доставка клиенту статики (картинки, HLS-playlist и треки). В данном случае можно обойтись без обращений к API, а использовать Nginx, который в любом случае и так используется.
Nginx отдает картинки, делая редирект на Spaces, а с HLS проверяет, есть ли HLS-playlist в Spaces, если есть, то редиректит туда. А если нет, то отправляет дальше в API.
В результате, пользователь мог начать слушать неозвученный текст уже через 3-5 секунд, независимо от длины текста. И все это при минимальной нагрузке, потому что вся основная работа происходила в Lambda. Ну а с озвученным текстом, при повторном просшу проблем не было изначально.
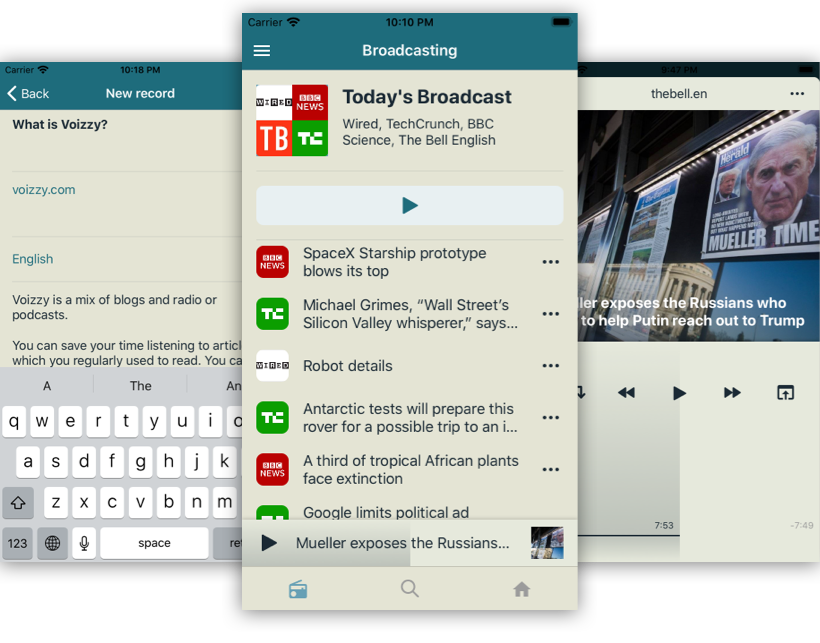
Проект дошел до релиза iOS приложения в AppStore и выглядел так:
Была и простенькая веб версия. Но так как это был пет-проект, а нас было всего двое, не хватило времени и ресурсов продолжить его развивать. Пришлось его закрыть.
Для меня это было один из самых интересных проектов, потому что пришлось решать довольно нестандартные, по-моему мнению, проблемы, тем более в качестве backend-разработчика.

4К открытий4К показов

Мы разобрали самые популярные из них, чтобы понять, какие сценарии использования они предлагают и чем могут быть полезны техническим командам.

С 2026 года Android разрешит установку только проверенных приложений: верификация станет обязательной для всех источников, включая APK

Разработчик показывает, как из простого приложения сделать дорогостоящее — за счет трат на сервера, инфраструктуру и многое другое.
Как реализовать надежное взаимодействие с API в Java. Примеры кода, механизм retry и рекомендации для повышения отказоустойчивости системы