


Поднимаем Full Spring стенд микросервисов из монорепозитория в Kubernetes
Как поднять стенд микросервисов в Kunernetes из монорепозитория, чтобы быстрее зарелизить микросервисы на стенд для экспериментов.
2К открытий4К показов
Статья ориентирована на тех разработчиков, кто разбил рабочий монолит на микросервисы и теперь думает, как быстрее зарелизить микросервисы на стенд для экспериментов.
В статье основной упор делается на приготовление одного из рецептов CI в монорепозитории, прохождение по стадиям настройки Spring Cloud Gateway, в конце добавлена щепотка мониторинга — подключение Sentry к микросервисам.
Данная статья является продолжением статьи:
Код статьи размещён в монорепозитории:
Автор: Александр Леонов, руководитель группы разработки одной из распределенных команд Usetech.
Дисклеймер:
Данная статья рассчитана на разработчиков, которые волей судьбы или желания работают с деплоем приложений на стенд. Решения, предложенные в статье, не претендуют на использование в работе, они предназначены для экспериментов и общего понимания картины переноса монолита на микросервисы.
Итак, у нас есть проект какого-то абстрактного магазина, например, мы продавали книги. Раньше он из себя представлял обычный Spring бэкенд, который крутился на 8080 порту. Однако, со временем пришёл заказ на размещение эксклюзива, который будет иметь при релизе у читателей ажиотаж. В таком случае, мы начинаем бояться, а не завалит ли это одно произведение весь магазин? Нужно его как-то масштабировать в случае нагрузки. Причём полностью масштабировать мы его не хотим, т. к. знаем, что только часть оформления заказов будет под высокой нагрузкой. Поэтому из всех идей, нам приходит в голову перевести монолит на микросервисы.
Для начала проведём подготовку со стороны кода, выделив в отдельные модули важные части (будем дробить по бизнес-ценности), затем изолируем модули друг от друга и сделаем их самостоятельными. Spring Boot приложениями. В итоге, проект будет выглядеть так:
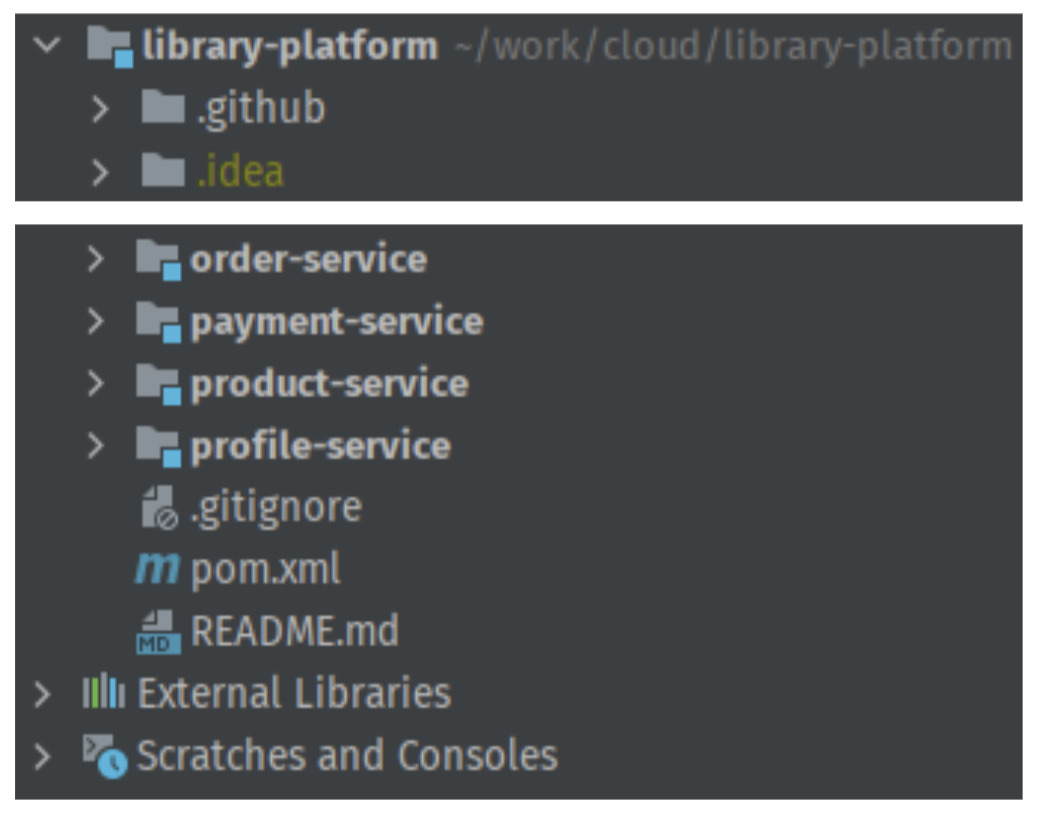
Отлично, теперь у нас есть 4 отдельных разрозненных микросервиса, которые разные и под которые нужно переделывать фронт. Но нам, по возможности, этого бы не хотелось, поэтому пришла идея использовать Spring Cloud Gateway. Но не стоит сразу с места в карьер. В теории, если успех магазина по продаже книжек зайдёт, то его можно будет развести до целой платформы и потом продавать другим разработчикам сертификаты о её знании. Для того, чтобы безболезненно внедрять микросервисы, нам нужно хранить их конфигурации в одном месте, всё равно уже в монорепозитории делаем. Так как проект учебный, то почему бы не использовать стандартный Spring Config Service. Добавим к нашим разрозненным сервисам config-service и вынесем в специальную папку config все отличающиеся части application.yml файлов сервисов, унифицировав оставшиеся к одному стандартному виду, который будет тянуть всё содержимое из сервиса конфигурации.
В итоге получается вот такая структура:

Новый сервис по коду — обычный spring boot application, но с особенностями:
1) В помнике присутствуют две зависимости:
2) Над стартером приложения размещена аннотация @EnableConfigServer
Рассмотрим application.yml нового config-service:
Рассмотрим конфигурацию order-service, которую мы будем подгружать из конфиг сервиса config/order-service.yml:
А теперь увидим изменённый application.yml внутри сервиса order-service:
Всё, теперь order-service будет подгружать конфигурацию из config-service. Помимо плюсов, стоит отметить, что будут минусы при написании тестов, т. к. нам нужно будет или поднимать config-service или копировать содержимое части order-service.yml в application-test.yml. Но мы пока о тестах не думали, поэтому вывели все конфигурации сервисов в наш config-service.
Отлично, теперь у нас есть одна точка отказа, правда вероятность этого крайне мала, т. к. менять конфигурацию мы будем редко и в случае проблемы сразу же это обнаружим.
Отлично, унифицировав наши микросервисы, давайте избавимся от необходимости вносить правки на фронте, применяя один API Gateway для взаимодействия со всеми сервисами. Для этого создадим новый сервис — gateway-service, который будет использовать Spring Cloud Gateway и крутится на 8080 порту, как наш старый монолит.
Из особенностей gateway-service можно выделить только:
1) наличие необходимых зависимостей
2) наличие в конфиге application.yml необходимых перенаправлений на сервисы:
Отлично, теперь наши сервисы работают внешне как один бэкенд, фронт переделывать не нужно. Но, как теперь из монорепозитория собирать артефакты по сервисам отдельно, чтобы полностью не собирать проект?
Нам поможет сборка отдельных модулей maven + одна из стратегий CI в монорепозитории через деплой по коммиту в отдельную ветку, созданную под отдельный сервис. Это проще для понимания, нежели чем стратегия определения изменений в конкретных директориях модулей.
Итак, напишем наш ci файл. Как и раньше будем использовать github-ci. В итоге, получим такой конфиг сборки артефактов наших сервисов и упаковки их в образы, в docker-hub:
.github/workflows/maven.yml (по стандартному шаблону github):
Ура, мы сделали CI из монорепозитория только тех сервисов, которые будем править. Но есть одно но: сервисы за нашим Spring Cloud Gateway не будут масштабироваться автоматически, т. к. выше мы их завязали на порты, т. е. Нам нужно будет править ещё и Spring Cloud Gateway. Давайте поднимем свой service discovery и подружим его со Spring Cloud Gateway. В свободном доступе все предлагают использовать Eureka, её и будем использовать.
Добавим ещё один сервис discovery-service, который будет ничем иным, как Eureka Server со следующими приметами:
1) Над стартером используется аннотация @EnableEurekaServer
2)
3) во все существующие сервисы добавим над стартером аннотацию: @EnableDiscoveryClient
и зависимость в помники:
Теперь переделаем наш конфиг gateway-service:
Ура, вот теперь мы можем не трогать Spring Cloud Gateway при масштабировании наших сервисов. Работа через Eureka это, конечно, хорошо, но мы бы хотели стенд на kubernetes (т. к. монолит деплоился раньше туда). К тому же, там просто чудесные средства масштабирования приложений из коробки. В таком случае, давайте переведем наши сервисы в k8s:
Создадим пространство имён:
В принципе на этом этапе, можно забыть про Eureka, т. к. далее мы всё равно переделаем наш gateway-service для работу с Kubernetes абстракцией под. Если бы не было Kubernetes, то Eureka была бы незаменимой вещью, но тут она может отдохнуть и остаться в конфигах, в памяти о былых заслугах.
Обновленный gateway-service.yml:
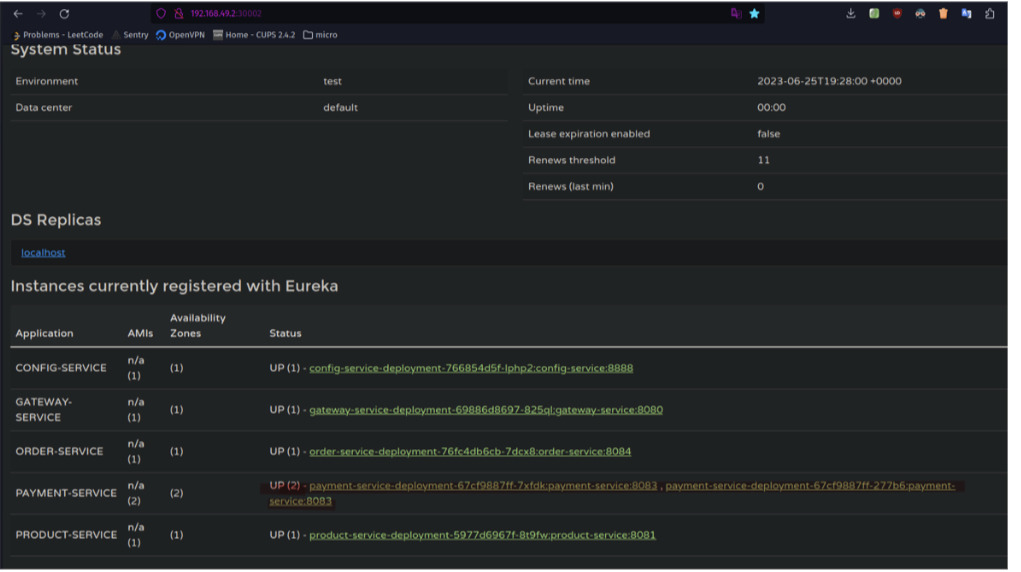
Готово, давайте задеплоим наши поды, отмасштабируем payment-service и проверим, что всё работает, как мы задумывали:

Т.к. у нас ещё жива Eureka давайте проверим, что она видит 2 поды:
Постучимся через API Gateway к нашему сервису:
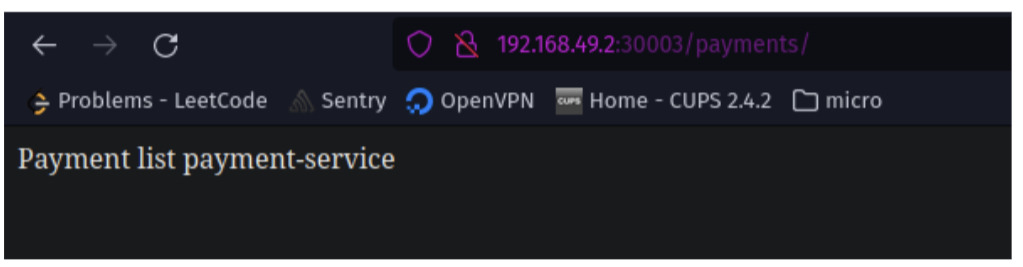
Супер, а теперь постучимся за детализацией несуществующих платежей и проверим, что балансер Kubernetes распределяет трафик по двум подам:


Итого, из 6 минус идентификаторов — 2 ушли в ошибку на одной поде, 4 на второй (основная).
Мы достигли цели, осталось накрутить мониторинг Sentry, для наработки навыка работы с фоном ошибок в домашних условиях.
1) Зарегистрируемся в https://sentry.io/
2) Создадим своё пространство, в нём создадим Spring Boot проект:
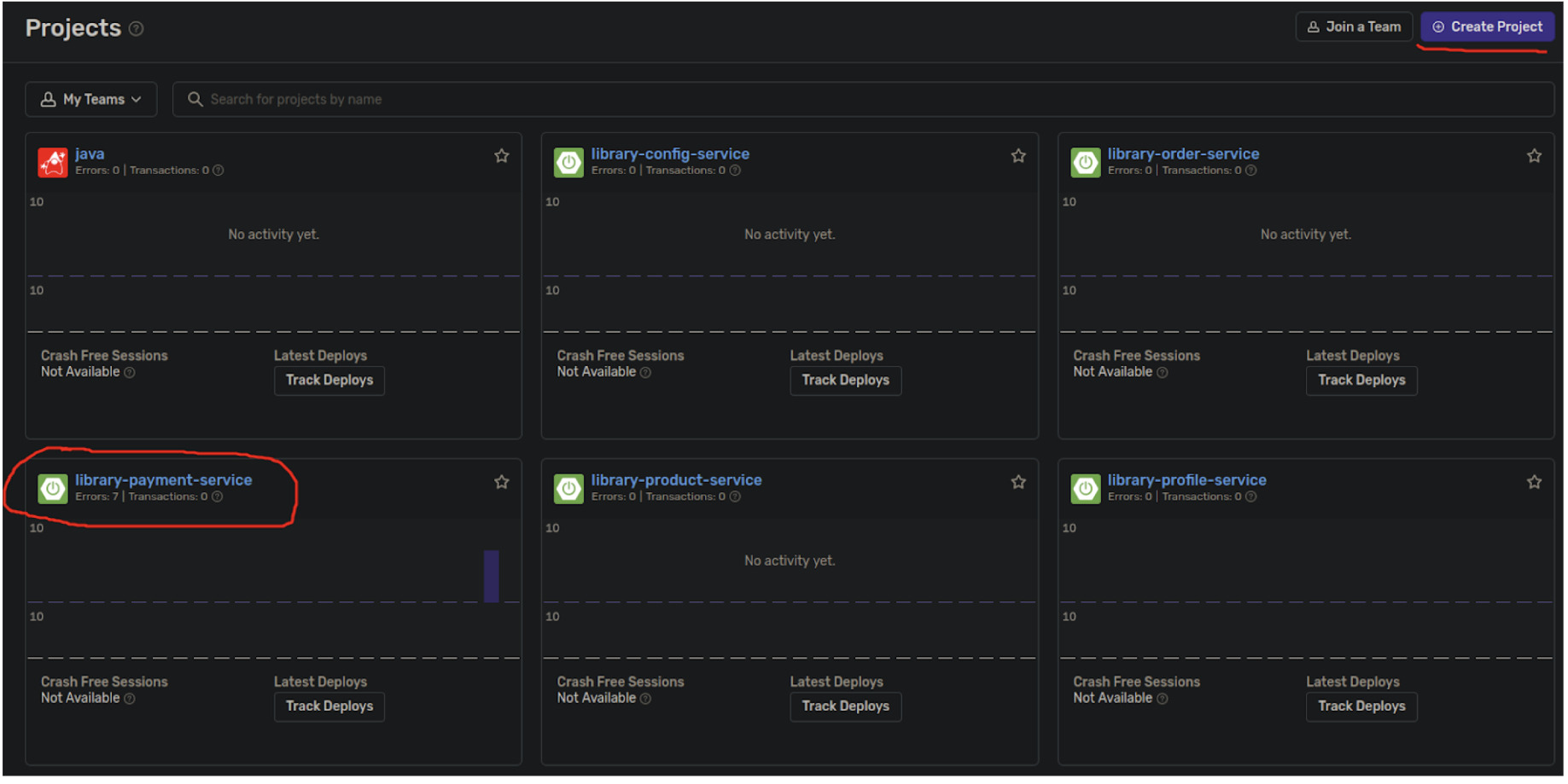
3) Добавим нужные зависимости в pom.xml по инструкции и dsn путь для отправки ивентов в payment-service.yml (см. код проекта по ссылке) + сделаем выставление значений через переменные среды в deployment файле payment-service.yaml k8s, для замены значений на лету.
Всё, теперь посмотрим как выглядит фон ошибок по нашим двум подам payment-service:

Отлично, мы подняли свой стенд микросервисов из дробленого монолита с деплоем из монорепозитория и мониторингом Sentry. Конечно, можно продолжить улучшать то, что уже есть: пирамида тестов, безопасность через sso, зеркалирование трафика kubernetes, внедрение Vault конфигов, но это потом.
Надеюсь, статья была полезной и интересной. Спасибо за уделенное время!

2К открытий4К показов

Подробное сравнение Serverless и Kubernetes: архитектура, масштабирование, стоимость, безопасность. Какой подход выбрать для MVP, high-load и гибридных приложений?

Микросервисы — это не всегда решение. Эксперт разобрал главные минусы: хаос в архитектуре, рост затрат, сложная отладка и непредсказуемость системы

Что приходит на смену классическим техлидам и продакт-менеджерам в IT: рассказываем, зачем нужны Technical Owner и Unit-лид, какие проблемы они решают в реальной разработке и как меняются роли в командах.

Даже самая идеальная микросервисная архитектура может упасть. В статье обсудим зарубежный материал, где автор рассказывает о проблеме Context Collapse.