


Реальная Unit-экономика внедрения AI: где мы сэкономили, а где сожгли бюджет на API
«Реальная Unit-экономика внедрения AI» — это разбор кейса, как агентство пыталось автоматизировать обработку отзывов через GPT-4 и столкнулось с неожиданными издержками. Автор честно показывает, где AI помог сократить ФОТ, а где сжёг бюджет на токенах. В материале — разбор ошибок naive RAG, переход на векторные базы, сравнение стоимости ручного и автоматизированного ответа, а также реальные цифры по CPA и выводы о том, когда AI всё ещё экономически невыгоден.
83 открытий6К показов

На пике хайпа вокруг ChatGPT казалось, что оптимизация ФОТ (фонда оплаты труда) – дело одного спринта. Задача выглядела элементарно: уволить джунов-копирайтеров, нанять одного промпт-инженера и подключить OpenAI API.
Спойлер: мы никого не уволили.
Вместо слепой веры в «волшебную таблетку» мы посчитали реальную стоимость генерации ответов, сравнили её с зарплатами и нашли точку безубыточности. Ниже – цифры, наши архитектурные ошибки и итоговая экономика проекта.
Проблема масштабирования
Специфика SERM (управления репутацией) – это потоковая обработка текста. Представьте клиента с сетью на 50 филиалов, которому ежедневно падает от 100 до 300 отзывов. На каждый нужно ответить уникально, потому что антиспам-фильтры поисковиков банят копипаст.
Раньше мы решали эту задачу линейным расширением штата. Больше отзывов – больше копирайтеров. Но это тупиковый путь: люди на рутине выгорают, Tone of Voice «гуляет», а ФОТ растет быстрее прибыли. Автоматизация через LLM казалась единственным логичным выходом.
Фаза 1. Как мы сжигали бюджет (Naive RAG)
Первая итерация была наивной: мы подключили GPT-4, написали системный промпт с инструкциями («Ты вежливый саппорт...») и начали скармливать модели отзывы.
Экономика рухнула почти сразу. Проблема оказалась в оверхеде на токенах. Для адекватного ответа модели нужен контекст: адреса филиалов, телефоны, условия возврата, скрипты вежливости. Мы передавали этот статический контекст в System Prompt при каждом запросе.
Математика получилась убийственной:
- входящий отзыв – всего 50 токенов
- сгенерированный ответ – около 100 токенов
- но инструкция с правилами компании – 1500 токенов
Мы платили за 1650 токенов, чтобы получить 100 полезных. КПД транзакции составлял ничтожные 6%. На объемах в десятки тысяч запросов ежемесячный счет за API опасно приблизился к зарплате квалифицированного разработчика.
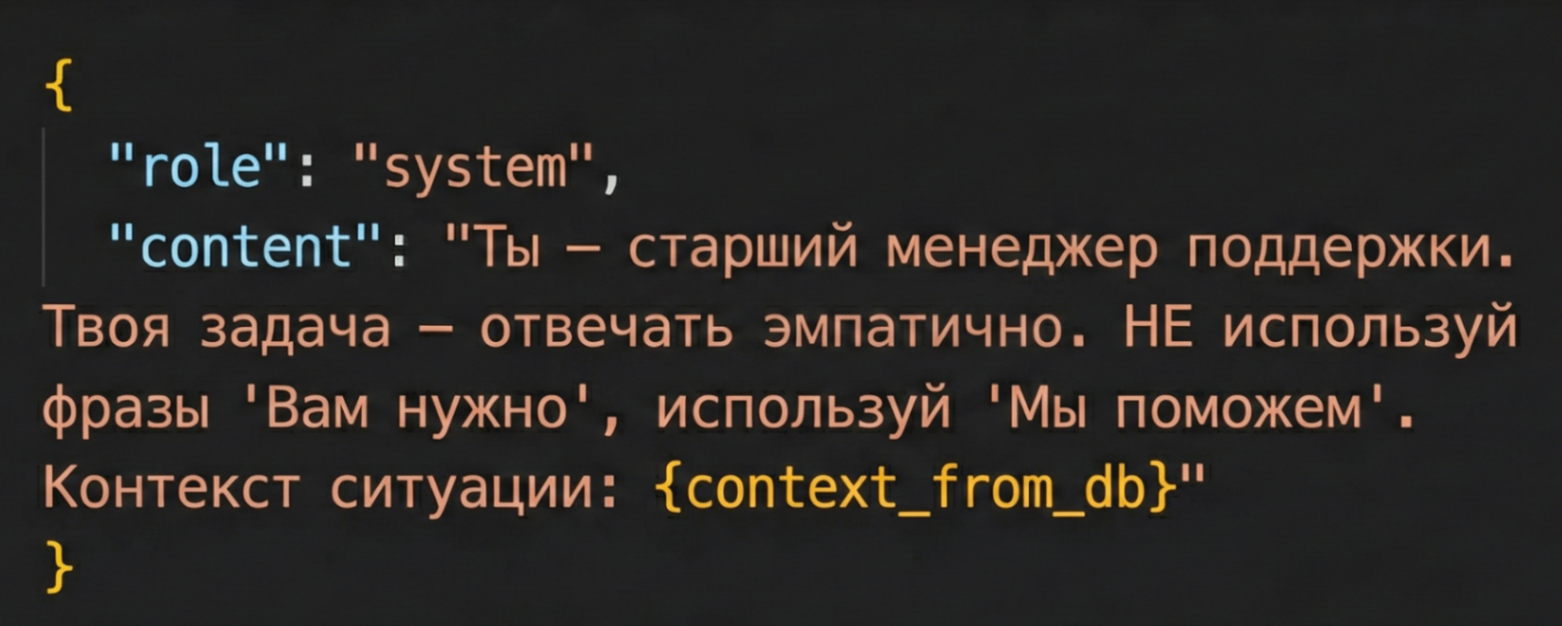
Пример неоптимизированного промпта. Передача статического контекста в каждом запросе убивает экономику.
Вторая проблема – галлюцинации. Без жестких ограничений модель начинала фантазировать. На жалобу об отсутствии парковки AI радостно отвечал: «Приносим извинения! Мы уже строим подземный паркинг, открытие в следующем месяце». Для бизнеса это прямой риск судебного иска за введение потребителя в заблуждение.
Фаза 2. Смена архитектуры
Решение «в лоб» оказалось экономически несостоятельным. Нам пришлось перестраивать процесс и внедрять RAG (Retrieval-Augmented Generation).
Логика изменилась. Вместо того чтобы скармливать нейросети весь устав компании, мы сначала ищем в векторной базе знаний фрагмент, релевантный конкретному отзыву. Если клиент пишет про доставку, в промпт попадает только блок правил о доставке.
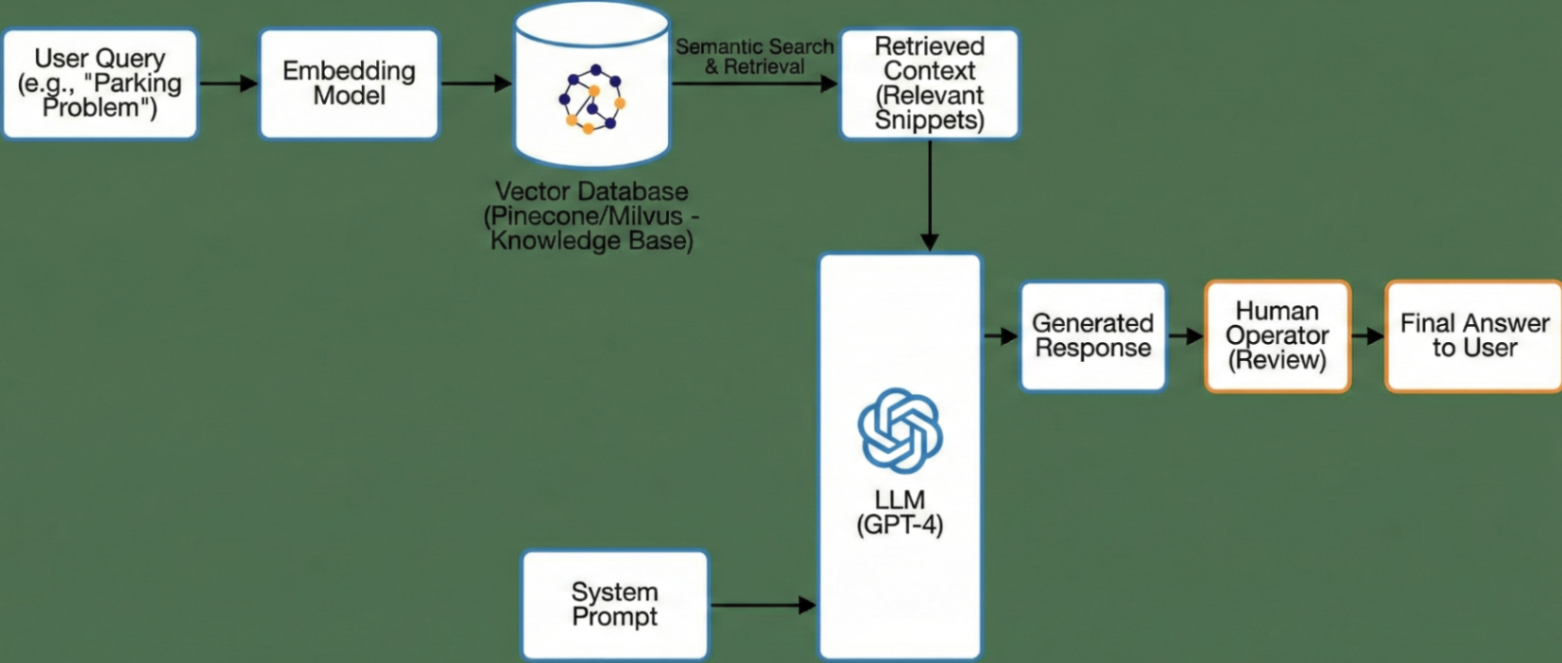
Архитектура RAG. Поиск релевантного контекста через Vector DB перед генерацией снижает объем входных токенов.
Переход занял две недели работы бэкенда и потребовал развертывания Vector DB (мы тестировали Pinecone и Milvus). Результат того стоил: System Prompt «похудел» с 1500 до 300 токенов, а стоимость одной транзакции упала в 4 раза.
Unit-экономика: человек vs API
Давайте сравним себестоимость одного ответа в рублях (цены усредненные, включая налоги и инфраструктуру).
1. Ручной труд (Junior-копирайтер). Если сложить зарплату, налоги, стоимость рабочего места и лицензий, один сотрудник обходится компании примерно в 80 000 руб/мес. При средней выработке 70 ответов в день, Cost per Action (CPA) одного ответа составляет ~50 рублей.
2. Гибридная схема (GPT-4o + Оператор). Стоимость токенов (Input + Output) с учетом RAG и затрат на серверы составляет около 3-4 рублей. Но выпускать ответы без проверки нельзя – риск галлюцинаций слишком высок. Поэтому мы ввели роль оператора-валидатора. Один человек с AI-помощником проверяет до 500 ответов в день. Стоимость его работы в пересчете на единицу контента – около 8 рублей. Итоговый CPA: ~12 рублей.
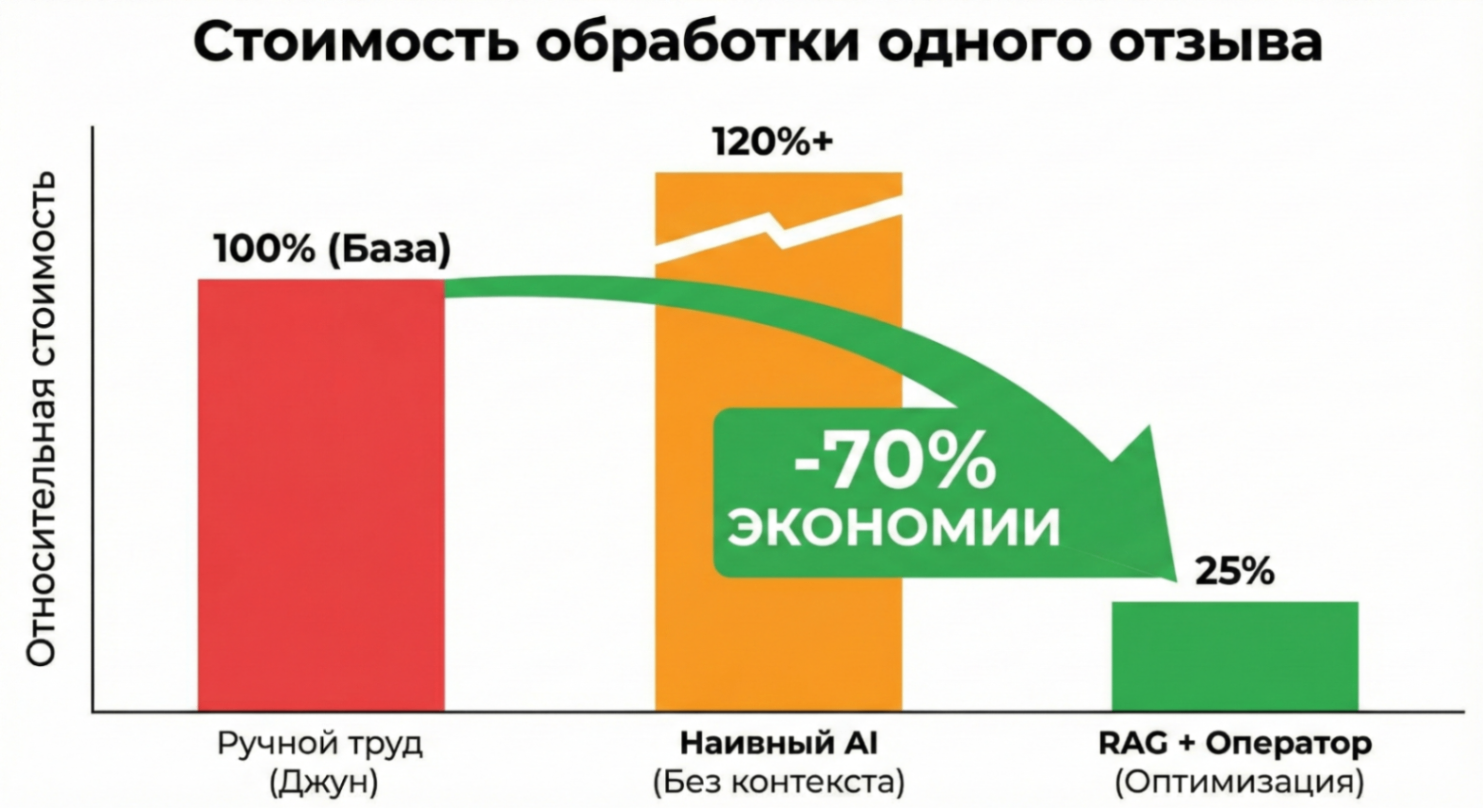
Сравнение стоимости обработки одного отзыва (RUB). Оптимизированный RAG с валидацией дешевле ручного труда на 70+%.
Ограничения технологии
Даже с такой экономикой есть сценарии, где мы сознательно запрещаем использование AI.
Во-первых, это сарказм и скрытая агрессия. LLM до сих пор плохо считывают контекст вроде: «Доставка – просто ракета, ждал всего три недели». Модель реагирует на слова-триггеры («ракета», «спасибо») и выдает: «Мы рады, что вы оценили скорость!». Для репутации бренда это катастрофа. Sentiment analysis помогает, но не дает 100% гарантии, поэтому такие отзывы фильтруются и уходят на ручную обработку.
Во-вторых, юридические риски. Любые досудебные претензии, угрозы жалобами в госорганы или требования компенсаций – это зона ответственности юристов. Риск автоматического ответа здесь превышает любую потенциальную экономию.
Итог
Внедрение AI в процессы агентства оказалось задачей не творческой, а сугубо математической.
Мы трансформировали роли: перестали нанимать джунов для написания текстов, а текущих сотрудников переквалифицировали в операторов-валидаторов. Их выработка выросла кратно, как и зарплата.
Главный вывод: без правильной архитектуры (RAG) и токеномики использование мощных моделей убыточно. Себестоимость производства контента у нас снизилась на 70%, но расходы на API и облачную инфраструктуру стали второй по величине статьей бюджета после ФОТ. И это тот компромисс, который выгоден бизнесу.

83 открытий6К показов

10 ИИ-сервисов для учёбы и работы в IT: генераторы кода, текстовые ассистенты, детекторы AI-контента и исследовательские инструменты. Сравниваем возможности, лимиты и сценарии применения.

Как перевести проект на Laravel. Показываем основные преимущества использования Ларавел. Рассматриваем пошаговую инструкцию нюансы переноса ✔ Tproger

В статье представлен список из ТОП-5 сайтов, где можно бесплатно скачать шаблоны резюме для устройства на работу в 2025 году. Вы найдёте удобные и современные варианты оформления, которые помогут вам произвести хорошее впечатление на работодателя. Статья будет полезна всем, кто хочет грамотно составить резюме.

Пост о перспективах создания высокоточных, не галлюцинирующих, соответствующих этике и безопасных ИИ-агентов. Будущее или реальность?