


SQL-запросы, которые вы рано или поздно погуглите, часть 2
Разобрали на примерах самые популярные SQL-запросы, связанные с модификацией таблиц, изменением записей и условиями.
1К открытий4К показов
Это продолжение статьи о популярных запросах, которые вы рано или поздно погуглите. Посмотрите первую часть по ссылке. На сей раз я использую таблицу subject_selection, которая описывает изучаемые студентами предметы:
Запросы исполнены на диалекте BigQuery.
WHERE + LIKE: найти все таблицы с определенным столбцом
Допустим, администратор университетской базы данных управляет большим хранилищем и уже не тратит усилия на запоминания всех структур таблиц. Он хочет вспомнить, в каких наборах упоминались студенты.
Во многих СУБД на базе SQL существует information_schema с метаданными, к которой можно обращаться с запросами. Вот так, к примеру, она выглядит в BigQuery (документация):
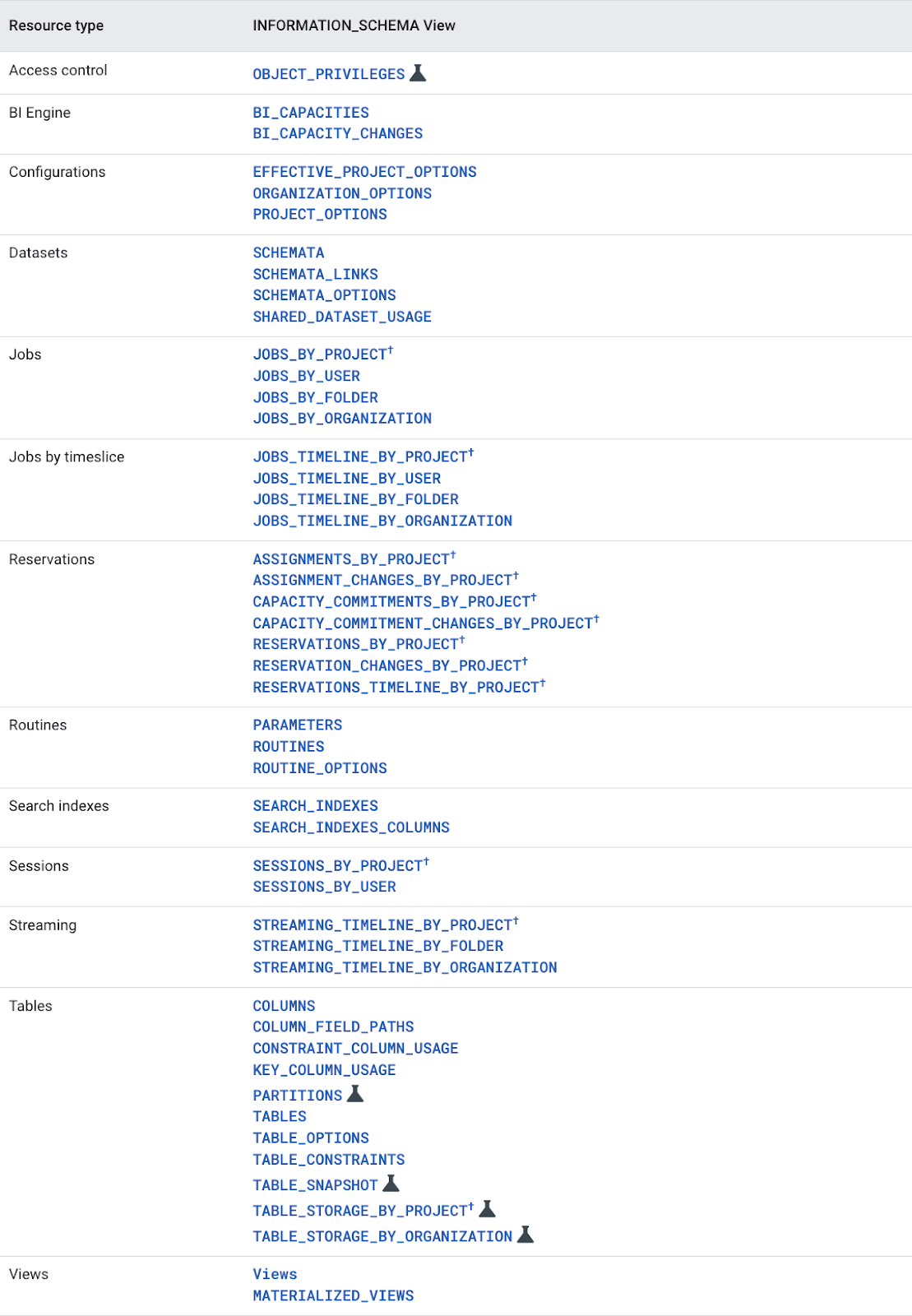
Вы также можете обратиться к:
- резервной копии таблицы (TABLE_SNAPSHOT);
- перечню запросов, выполненных определенным сотрудником (JOBS_BY_USER);
- частоте использования расшаренных датасетов (SHARED_DATASET_USAGE).
Чтобы получить искомый список таблиц, содержащими столбец с подстрокой ‘student’, нужно запустить такую команду:
В результате мы получим список с 20+ параметрами. Располагая также данными о типе столбца, возможности пропусков в нем и прочих интересных настройках вы сможете управлять своими данными на новом уровне: ведь по любому из полей можно производить фильтрацию, модификацию и проч.:

UPDATE + SET: Внести изменения в объединенную таблицу
Допустим, к данным о студентах и предметах для оценки качества обучения ВУЗ попросил добавить имя преподавателя:
Таблица teachers
Предварительно добавим столбец teacher_name в subject_selection (в документации BigQuery вы найдете шесть способов это сделать). И «сдружим» UPDATE и JOIN:
Обратите внимание:
- Строки 1 и 3: таблицы обзавелись псевдонимами s и t, так оператор SET получит понятную инструкцию, а разработчик — лаконичность;
- 2: мы просим заполнить новый пустой столбец именами учителей из teachers;
- 4: задаем правило сопоставления: вставлять Ф.И.О. только там, где известно имя преподавателя.
Вот так выглядит результат. Теперь руководство факультета может организовать ведение дипломов, ведь знает, с каким студентом какой преподаватель работал.
GROUP BY: Группировать ряды по двум столбцам
Перед деканатом встала задача организовать обучение так, чтобы на каждый предмет приходило достаточно студентов.
GROUP BY X помещает всех, у кого одинаковое значение в столбце X, в одну категорию. Наглядно выглядит группировка в Apple Numbers, потому продемонстрирую скриншотом предметную категоризацию в ней:
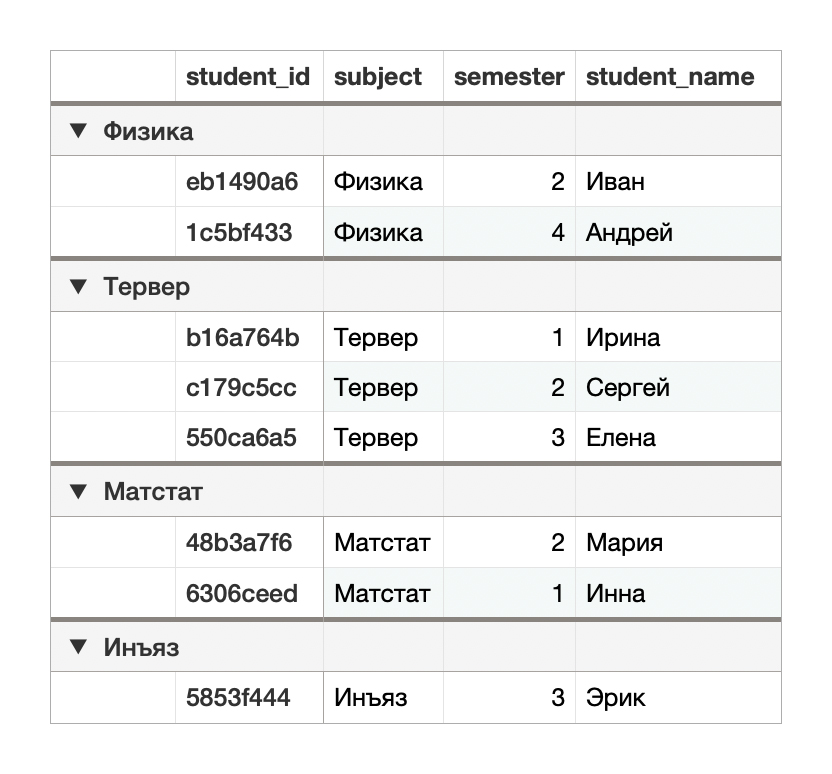
Чтобы сделать такое с помощью SQL, добавим столбец под названием student_count.
- 6: сгруппируем записи и по предмету, и по семестру
- 4: подсчитаем число студентов для каждого сочетания «предмет – семестр»
В результате мы получим представление — несохраненный пока результат вычислений. Первые два столбца описывают сочетания предметов и семестров, третий — число учеников:
В реальной жизни записей в базах, конечно, больше. И потому с помощью такого запроса деканат может организовать, например, равномерное наполнение аудиторий.
STRING_AGG: Объединение нескольких рядов
Если в рекламный отдел учебного заведения верстает рекламные проспекты для абитуриентов, то им для этого понадобится перечень предметов. Чтобы извлечь его из teachers в виде строки, поможет агрегирующая функция STRING_AGG:
Мы получим таблицу с одной ячейкой:
PARTITION BY + оконная функция: Выделение последней записи в группе
Если университет захочет узнать, на каких студентах преподавание предмета завершилось, поможет оконная функция. Про нее любят спрашивать на собеседованиях на должность дата-аналитиков и дата-инженеров.
Давайте пошагово разберем, что происходит в запросе:
- 2-я строка: SELECT s.* выбирает все столбцы исходной subject_selection (можно и меньше при желании);
- 1: оператор WITH создает так называемое обобщенное табличное выражение, то есть в целом позволяет исполнить функцию в третьей строке и навесить условие в седьмой;
- 3: PARTITION BY создает сегментированные по дисциплине подтаблицы, ORDER BY упорядочивает по убыванию каждую из них по номеру семестра;
- 3: ROW_NUMBER() временно нумерует строки подтаблиц по порядку;
- 5: мы указываем исходную таблицу;
- 6: накладываем условие: «Порядковый номер записи в каждой подтаблице равен единице» (то есть запись последняя).
В результате мы получили список студентов, что слушали предмет в крайнем семестре:
MERGE + USING + WHEN MATCHED: Вставка в таблицу или обновление в случае существования
Представим, что преподавательский состав обновился. Пусть хранилище само выделит незнакомые имена:
↑ Временный перечень новых учителей new_teachers
Когда речь заходит о базах с тысячами записей, ручная редактура перестает быть оптимальным решением. Если вы хотите дополнить данные новыми сроками без наводнения дубликатами, воспользуйтесь вставкой UPSERT (‘update + insert’). Однако BigQuery опять выделяется: вместо этого приходится расписывать условие на пять строк:
Что здесь происходит:
- Строки 1-2: объединяем новый и старые листинги учителей и присваиваем им псевдонимы t и nt;
- 3: задаем столбец, на базе которого произведем сопоставление (teacher_id);
- 4–8: добавляем условие:
- если совпадение по ID найдено, вставляем имя преподавателя в соответствующую ячейку;
- если совпадения нет, добавляем дисциплину в перечень.
Информатика и физика в предметах были, так что там обновятся имена учителей. А вот астрономия — новичок, так что будет добавлена новой строкой:
В результате мы сэкономим администратору базы данных время. Ему не придется выискивать уже существующие записи.
Заключение
Теперь вы знаете, как:
- искать по метаданным хранилища;
- группировать по нескольким столбцам;
- обновлять с JOIN;
- объединять ячейки в строку;
- выделять записи из групп;
- и добавлять новые строки без дубликатов.
Делитесь в комментариях, какие запросы вам чаще всего приходилось гуглить (или какие бесят больше всего).

1К открытий4К показов

Иван Якунин, продуктовый аналитик команды Fintech Marketplace, рассказал про то, как в Авито работают с Vertica, и на примерах объяснил, что такое проекции, и когда их стоит использовать.

Экс-консультант стал программистом за 100 дней с помощью ChatGPT и Python — собрал портфолио, прошел собеседование и получил работу без курсов и Leetcode

Сравниваем 5 VPS-провайдеров, которые стабильно работают под нагрузкой в 2025 году. Разбираем стоимость, примеры использования, производительность и uptime.

Как подключиться к базе данных. Показываем основные запросы к базам данных. Рассматриваем пошаговую инструкцию по использованию ✔ Tproger