


История одного пет-проекта: как я утомился от SQL и создал ИИ-сервис для обучения
Я работаю с дата — SQL запросы, базы данных и всё такое. Но мне захотелось чего-то нового и я создал проект на стыке ИИ и образования
283 открытий3К показов

Я — дата-инженер, но мне наскучила ежедневная рутина с сотнями строк SQL-запросов. Захотелось сделать какой-то творческий интересный проект. Подумал, почему бы не создать собственный пет-проект, который можно «пощупать» руками и, возможно, поделиться с другими и принести им пользу.
У меня в голове появилась идея AI тьютора. Это синергия двух популярных сегодня концепция: онлайн-обучения и ИИ. По сути, я создал сервис генерации образовательного контента с возможностью проверить знания и доступом к умному виртуальному помощнику.
Концепция такая: человек получает готовую обучающую программу в виде списка тем, загружает её в мой сервис. На выходе получает готовый структурированный курс с контентом от нейросети. Задумку удалось не просто реализовать, она эволюционировала и обросла дополнительными фичами.
Что получилось
Основной функционал сервиса — генерация курсов. Можно отыскать в сети готовую программу и вставить в промпт, а можно сформулировать пожелание, что хотелось бы изучить, своими словами. Например, «Хочу курс, обучающий рационально распоряжаться финансами, преумножать, накапливать, инвестировать и т.д. Мне нужны инструменты и знания по части планирования расходов и финансовой грамотности».
В ответ AI, используя заранее описанный в скрипте промпт, формирует список уроков.
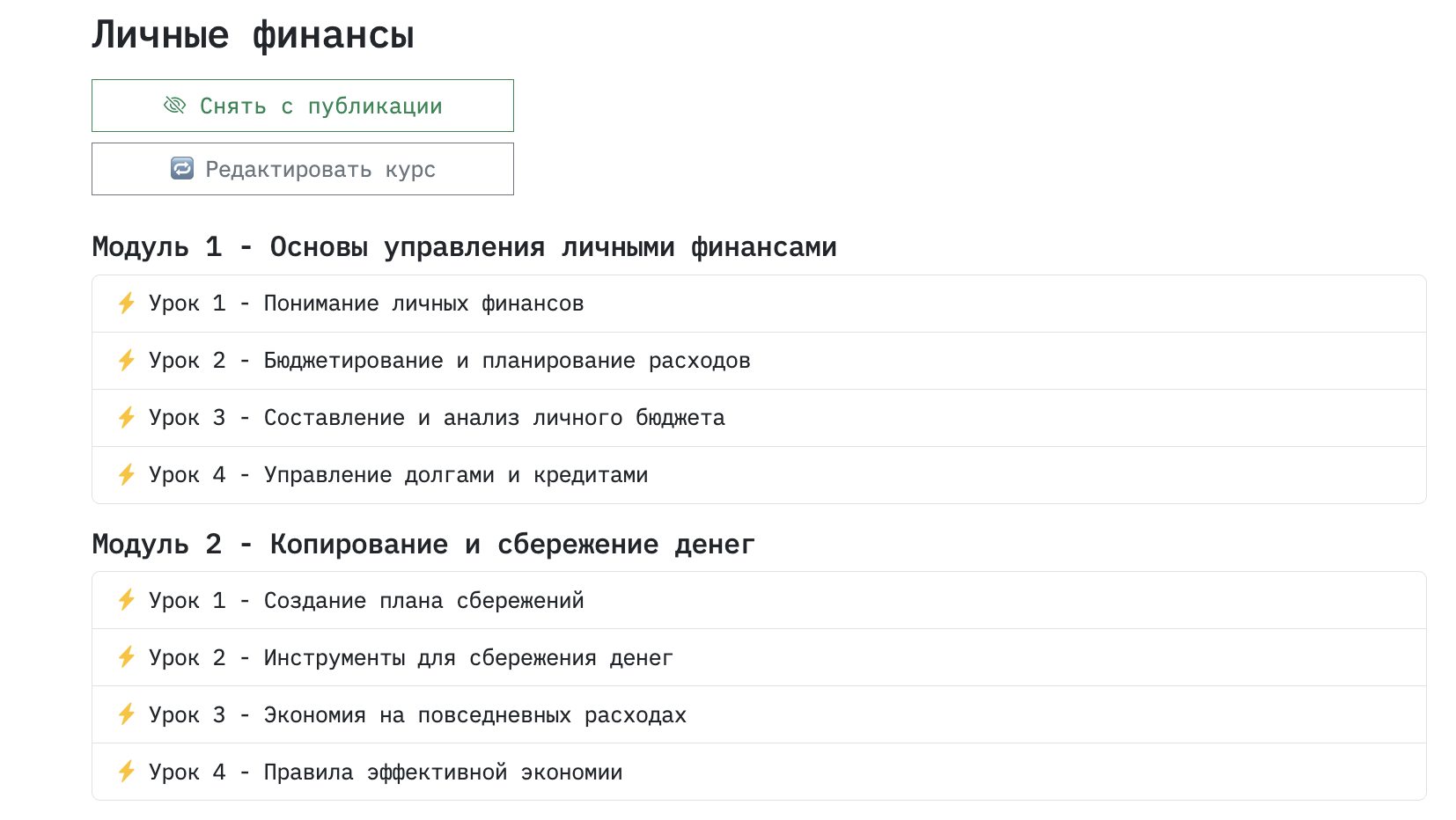
Затем можно попасть в каждый отдельный урок и сгенерировать лекцию. Можно просто нажать кнопку, а можно написать дополнительные пожелания, которые в скрипте подтянутся к промпту.
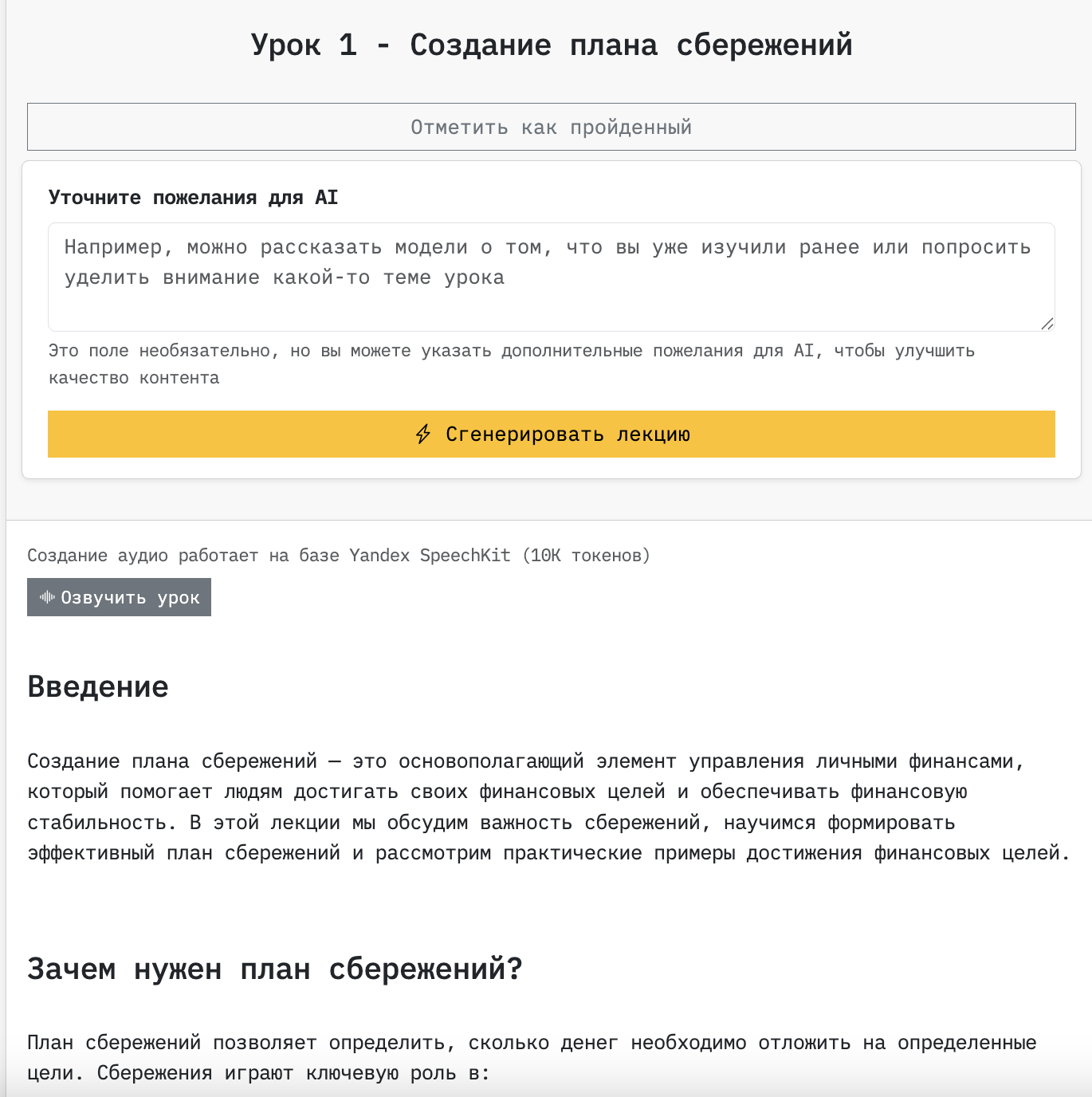
Внутри каждого урока есть возможность задать вопросы по теме лекции. Вместе с вопросами в контекст подтягивается содержимое лекции, чтобы AI понимал, к какому именно фрагменту урока относятся вопросы.
Так же можно сгенерировать проверочные задания, которые рандомно создадутся нейросетью на основе контента лекции.
Не так давно я добавил функционал озвучки лекций с помощью Yandex Speechkit. Звучит вполне сносно, если, конечно, контент — не англоязычный.
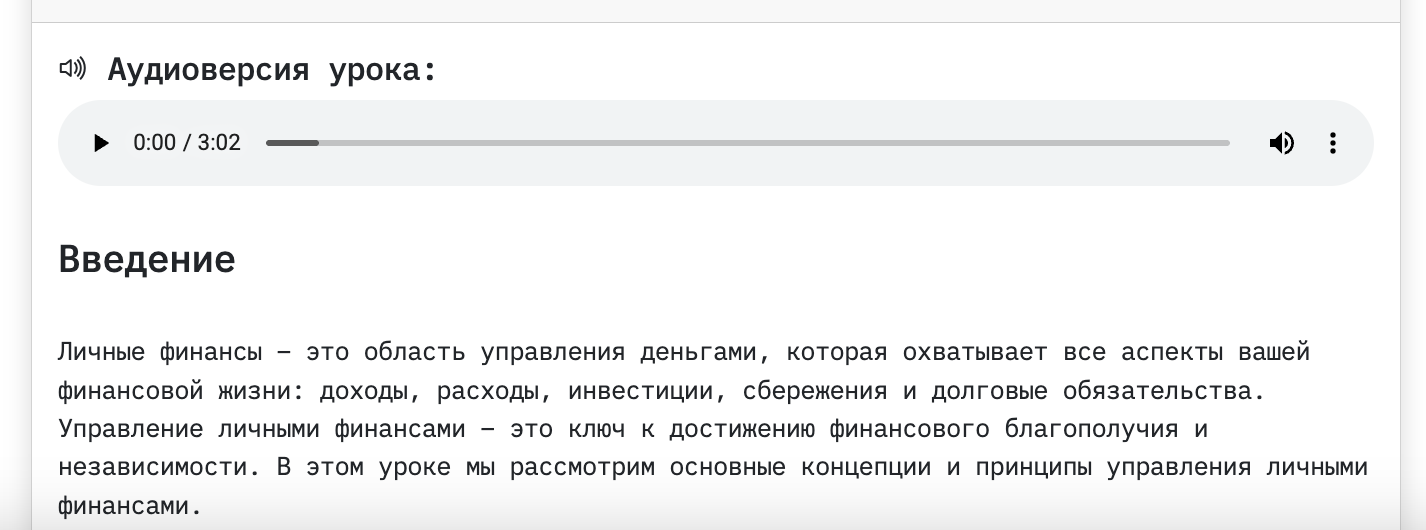
Вобщем, содержание уроков получается адекватным. Особенно, если тема — гуманитарная.
Что под капотом?
По умолчанию я использовал open-source модель Qwen2.5-32b, которую спустя время сменил на Qwen3-32b. При этом пользователь может в личном кабинете подключить свой аккаунт от другой более продвинутой и быстрой модели для генерации более качественного контента. Например, GPT от OpenAI. Лично я тестировал разные варианты и все они +- одинаково справлялись с генерацией текстов. Но GPT от Open AI, конечно, справляются с задачей немного быстрее — примерно на 20-30.%

После регистрации каждый пользователь может пользоваться сервисом бесплатно. На каждого юзера установлен лимит токенов, которые расходуются из моего личного аккаунта на Alibaba, а далее можно подключать свою модель в личном кабинете и не зависеть ни от чего. То есть, вы самостоятельно генерируете контент, и платите сам за себя, а не мне. Так что, можно сказать, что сервис условно-бесплатный.
Запросы к LLM идут с заранее прописанными промптами, в которые вставляется пользовательский ввод. Единственное, что из-за ограничений OpenAI для РФ пришлось хостить сервис в Digital Ocean. Забавно, что изначально он вообще был установлен просто дома на подоконнике на Raspberry Pi. Потом пару раз заглючил провайдер. Я посмотрел на это и решил, что потратить 1000р в месяц не жалко, если сервис будет работать стабильно. К тому же, не пришлось организовывать отдельный прокси, чтобы запросы в OpenAI отрабатывали корректно. Я, конечно, такой вариант тоже протестировал и в целом он оказался рабочим. Но иностранное облако оказалось более простым и изящным решением.
Сложности
Основная проблема — стриминг ответов на страницу из-за проблем с LLM. Когда стоит флаге stream=True, а запуск происходит через Nginx + Runserver, то всё работает нормально, ответ модели выводится на страничке. Но в случае uvicorn и gunicorn решение не работает. Весь ответ на каком-то этапе буферизируется и потом кучно попадает на фронтенд. То есть, у нас одни и и те же конфиг nginx, бекенд и JS на странице. Но без Runserver ничего не стримится. Моих знаний пока не достаточно, чтобы разобраться, в чём же именно причина.
Одной из версий решения я рассматриваю создать отдельный микросервис, отвечающий исключительно за стриминг и уже к нему обращаться на фронте, чтобы получать желаемый результат. GPT советует также развернуть параллельно сервис Fast API, но я пока не успел протестировать эту гипотезу на практике.
Сам сервис написан на классическом варианте стека: Django + Jinja Templates. Нет никакого модного фронтенд-фреймворка, т.к. я вообще в них ничего не понимаю. Вся эта история задумывалась как учебный пет-проект, который неожиданно перерос в нечто большее.
Дальнейшие планы
Внедрить возможность выдавать доступ к курсам определённым юзерам по email. Сейчас можно опубликовать курс для всех в общую библиотеку. Но есть мнение, что не всем пользователям захочется делиться созданным контентом со всеми подряд.

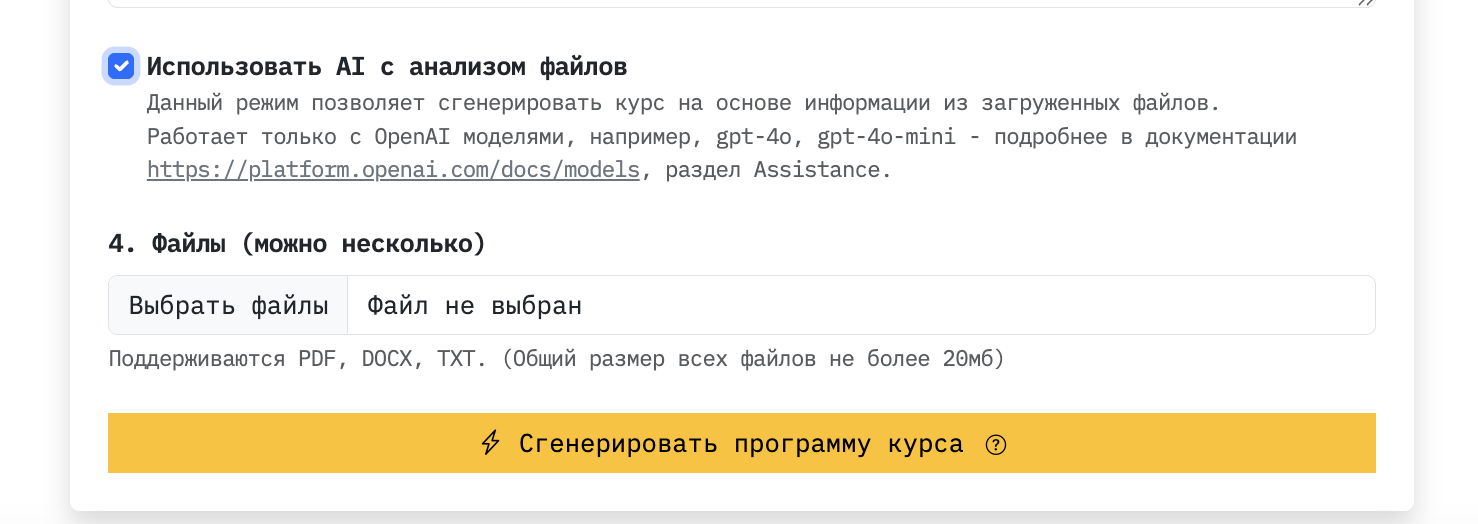
Двигаться в сторону RAG. Сейчас это реализовано, но полноценно я им ещё не пользовался. Если в личном кабинете добавить свою GPT- модель, то можно создавать курс на основе загруженных файлов. Под капотом используется OpenAI Assistants API.
Сейчас есть редактор уроков, что позволяет полученный от ИИ контент самостоятельно отредактировать через WYSIWYG редактор. Но стоило бы ещё проработать создание авторских курсов, когда пользователь использует свои заметки и дорабатывает их с помощью нейросети. Затем, конечно же, финально правит полученный результат в редакторе, дополняя видео, картинками или файлами. Вуаля: курс можно опубликовать в библиотеку или поделиться с конкретными пользователями с помощью ссылки. Ну или выгрузить в PDF — эта функция доступна уже сейчас.
Если вам интересно, мой сервис уже можно протестировать . Для этого авторизуйтесь через google-почту и на open source-модели qwen 3 сгенерируйте парочку курсов на любую тему. Поделитесь в комментариях, как всё прошло и что получилось в итоге;
В будущем планирую написать вторую часть статьи и рассказать, что происходит в сервисе на уровне кода.

283 открытий3К показов

ИИ-ассистент, оптимизирующий клиентский сервис, для поддержки клиентов в Service Desk/Help Desk от Upservice. Обзор на нейропощника.

Как найти работу в IT- сфере, когда все ее уже давно нашли? В статье расскажем, кто востребован, куда берут без опыта, как составить резюме и пройти собеседование
Microsoft сделала функцию Think Deeper на базе модели OpenAI o1 совершенно бесплатной для всех пользователей, в том числе и Copilot

Claude Haiku 4.5 сгенерировал больше всего кода, но занял лишь 7-е место в тесте на рефакторинг — уступив GPT-5 и Claude Sonnet 4.5