


Зачем аналитикам данных знать SQL

Эксперт «Нетологии» рассказывает, что такое SQL, как работать с SQL командами и, главное, зачем это всё нужно аналитикам данных.
26К открытий27К показов

Рассказывает Ирина Хомутова, эксперт и методолог курса SQL «Нетологии»
Что такое SQL?
Если коротко, это мощный инструмент для анализа и преобразования данных, который позволяет разработчикам обращаться к различным базам данных.
И если мы хотим анализировать данные — нам нужно их откуда-то получать, а получаем мы их, как правило, из баз данных. Не всегда это видно невооружённым взглядом, но читаем ли мы новости, переводим деньги со счёта на счёт, запрашиваем выписки по счёту, делаем покупки в интернет-магазине или просто знакомимся с ценами конкурентов — всё это мы делаем, обращаясь к различным базам данным.

И вот перед тем, как мы получаем привычное «читабельное» представление нужной информации, данные извлекаются из хранилищ. И чаще всего это происходит именно с использованием SQL. В широком смысле SQL не является языком программирования, хотя и существует такое устоявшееся заблуждение. На самом деле он больше похож на самую обычную английскую речь.
Кто такие аналитики данных и с чем они работают?
Аналитики данных — своего рода экспериментаторы, которые владеют инструментарием для соединения потоков данных из различных источников, а также выдвигают гипотезы и проверяют их. Вот тут-то им и нужны базы данных и язык, позволяющий точно формулировать к ним запрос. Правильное получение исходных данных — это искусство, гарантирующее высокую вероятность того, что в поведении исследуемых объектов установятся причинно-следственные связи. Именно качество данных позволяет выбирать наиболее подходящие гипотезы.
Помимо SQL, аналитику данных необходимо знать инструменты статистического анализа данных: это и узкоспециализированные пакеты — SPSS, Statistika, и различные языки программирования — SAS, R, Python, обладающие функциональностью для анализа и визуализации данных, и совсем легковесные решения типа Gretl. А самый популярный набор инструментов у аналитиков, это, пожалуй, Python + SQL.
Часто нужно представить данные наглядно и понятно для бизнеса, а иногда и самому оценить, какие факторы, влияющие на данные, являются значимыми, а какие нет, какие причины отклонений созависимы. Когда необходимо строить прогнозы, аналитики вместо того чтобы работать напрямую с базами, работают с датасетами (таблицами данных) с помощью различных пакетных решений.
При этом в каждой индустрии свои стандарты анализа, зависящие от чувствительности данных: для госструктуры набор инструментов будет одним (исходя из жёстких ограничений доступов), для НКО — другим, для диджитал-стартапа — третьим.
Откуда брать данные и что делать с SQL командами?
В организациях есть свои хранилища данных и при необходимости к ним можно получить доступ. Это происходит и при разграничении прав пользователей, и при работах по разработке баз данных. С помощью Python, зная адрес сервера и данные для подключения к нему, можно импортировать нужные библиотеки и писать запросы уже внутри используемой программы.
Примеры библиотек: для ODBC — pyodbc, PostgreSQL — psycopg2, MySQL — mysql.connector и т. д.
Ваша программа-«получатель данных», в свою очередь, может находиться внутри облачного решения на основе jupiter notebook. А к полученным данным вы примените дальнейшие выкладки и/или построите графики (как минимум, библиотеки: pandas, numpy, matplotlib и т.д.).
Аналитические функции
Считается, что в базах данных каждая строка запроса должна обрабатываться независимо от других. Практика диктует нам иные задачи, в которых часто необходимо группировать строки и вычислять для них общие показатели, используемые для оценки признаков строк внутри группы.
Примеры:
- вычислить частоту общения друзей друг с другом (например, необходимо определить максимально близкие контакты внутри выделенных кругов): тогда мы будем искать процентные соотношения длительности переговоров, частоты переписок и телефонных разговоров, количество географических пересечений, посещений общих ресурсов и т.д.,
- сравнить зарплаты сотрудников внутри отделов, вычислить рейтинги,
- узнать топ-N заказчиков в сечении по услугам или продуктам,
- узнать загруженность соседних точек продаж и т. д.
На помощь приходят аналитические функции SQL — мощный инструмент, который помогает разгрузить клиента от большого объёма процедурного кода, СУБД — от сложных и порой малоэффективных запросов, уменьшить время на разработку и получить при этом желаемый результат.
Функции для статистических расчётов включают в себя как стандартные агрегирующие функции (используются для получения обобщающих значений), так и расширения, характерные для конкретных СУБД.
Рассмотрим примеры, основанные на классическом тренировочном датасете Postgres.
Мы хотим обслуживать без очереди пассажиров, входящих в топ-5 по суммарному чеку за перелёт. Для этого вычисляем и выводим определённый список, чтобы спланировать дальнейшую работу:
На неделю получили примерно такой список:
Посмотреть список
На данный момент этот блок не поддерживается, но мы не забыли о нём!Наша команда уже занята его разработкой, он будет доступен в ближайшее время.
Рассмотрим наш запрос внимательнее. Что тут есть:
- Предложение
over— то, что как раз-таки синтаксически отличает оконную функцию от обычной или агрегатной функции. - Внутри over-предложения
partition byуказывает, что строки нужно разделить по группам или разделам, объединяя в соответствии с указанным в нём выражением (подобноgroup byна уровне запроса, за исключением того, что его аргументы всегда являются просто выражениями, а не именами выходных столбцов или числами). - Оконная функция вычисляется по строкам, попадающим в один раздел с текущей строкой.
- Указание
order byопределяет порядок, в котором оконная функция обрабатывает строки раздела.
Оконные функции общего назначения в большинстве СУБД позволяют узнать:
- номер текущей строки в её разделе;
- ранг: относительный/абсолютный, с пропусками или без;
- значения: в первой/последней или n-ой строке;
- значение соседа текущей строки со смещением вверх/вниз
Для Postgres оконные функции:
row_number()— номер текущей строки в её разделе, начиная с 1;rank()— ранг текущей строки с пропусками; то же, что иrow_numberдля первой родственной ей строки;dense_rank()— ранг текущей строки без пропусков; эта функция считает группы родственных строк;percent_rank()— относительный ранг текущей строки, вычисляется по формуле:percent_ rank = (rank - 1) / (Nстрок - 1);cume_dist()— относительный ранг текущей строки:(число строк, предшествующих или родственных текущей) / (общее число строк);ntile(число_групп)— ранжирование по целым числам от 1 до значения аргумента так, чтобы размеры групп были максимально близки;lag(значение [, смещение [,значение_по_умолчанию]])— значение для строки, положение которой задаётся смещением от текущей строки к началу раздела;lead(значение [, смещение [,значение_по_умолчанию]])— значение для строки, положение которой задаётся смещением от текущей строки к концу раздела;first_value()— значение, вычисленное для первой строки в рамке окна;last_value()— значение, вычисленное для последней строки в рамке окна;nth_value()— значение, вычисленное для n-oй строки в рамке окна.
Если же мы говорим об агрегатных функциях, то они работают как оконные тогда и только тогда, когда за их вызовом следует предложение over; в противном случае они останутся обычными агрегатными.
Таким образом, на основе нескольких точных запросов аналитик может самостоятельно написать техническое задание на рекомендательную систему или сделать MVP для проверки продуктовых гипотез без привлечения специалистов по машинному обучению.

26К открытий27К показов

Экс-консультант стал программистом за 100 дней с помощью ChatGPT и Python — собрал портфолио, прошел собеседование и получил работу без курсов и Leetcode

Исследователи обнаружили, что база данных DeepSeek была открыта для внешнего доступа. В ней хранились история чатов, API-ключи и логи работы сервиса

Подробное сравнение технологий API для разработчиков. Разбираем сильные и слабые стороны GraphQL, gRPC и tRPC на реальных кейсах. Практические рекомендации по выбору технологии для вашего проекта.
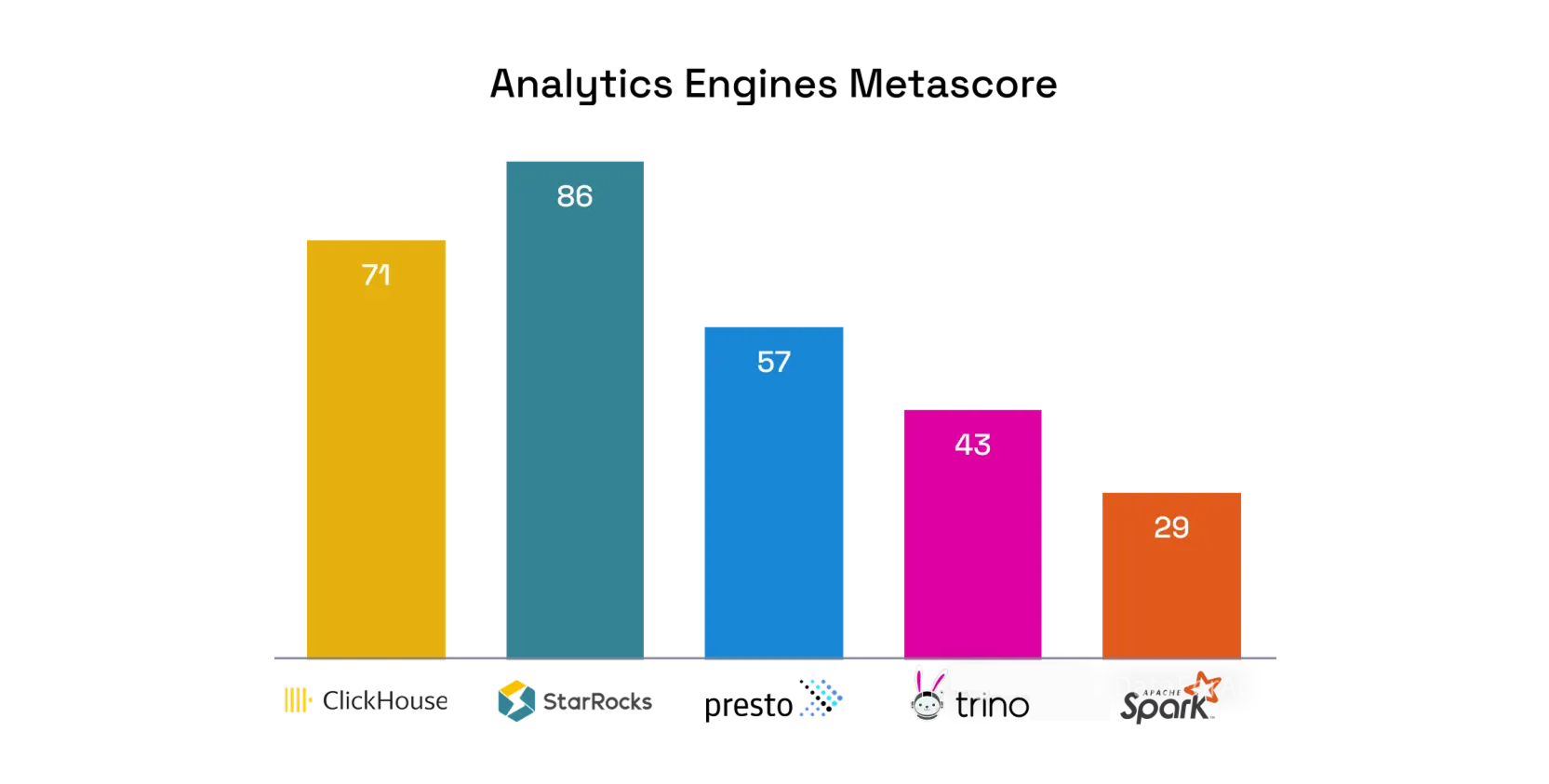
Эволюция от Hadoop к cloud‑native и ИИ‑архитектурам. Многомерное сравнение Spark, Presto, Trino, ClickHouse и StarRocks по скорости, масштабируемости, кэшам, SQL/Python, HA и др.