


🔥 На GitHub выложили исходный код алгоритма рекомендаций X. Разобрались, что там внутри
Новости
Интересный прецедент — нечасто такое происходит в бигтехе
11К открытий26К показов

Компания X (экс-Twitter) опубликовала исходники алгоритма, отвечающего за рекомендации в ленте «Для вас», поиске и уведомлениях.
Репозиторий уже собрал почти 65 000 звезд на GitHub. Разбираемся, как он устроен и какие интересные модули лежат внутри.
Что делает этот алгоритм
Алгоритм отвечает за то, какие посты и аккаунты вы видите на всех основных страницах в X: от рекомендаций и трендов до пушей. Внутри — десятки сервисов и моделей, взаимодействующих между собой.
Например, компонент home-mixer собирает кандидатные твиты из разных источников (например, через search-index, tweet-mixer, user-tweet-entity-graph) и ранжирует их при помощи легкой и тяжелой нейросети (light-ranker, heavy-ranker).
После этого подключаются фильтры (например, visibility-filters), которые убирают нежелательный контент и скрытые посты.
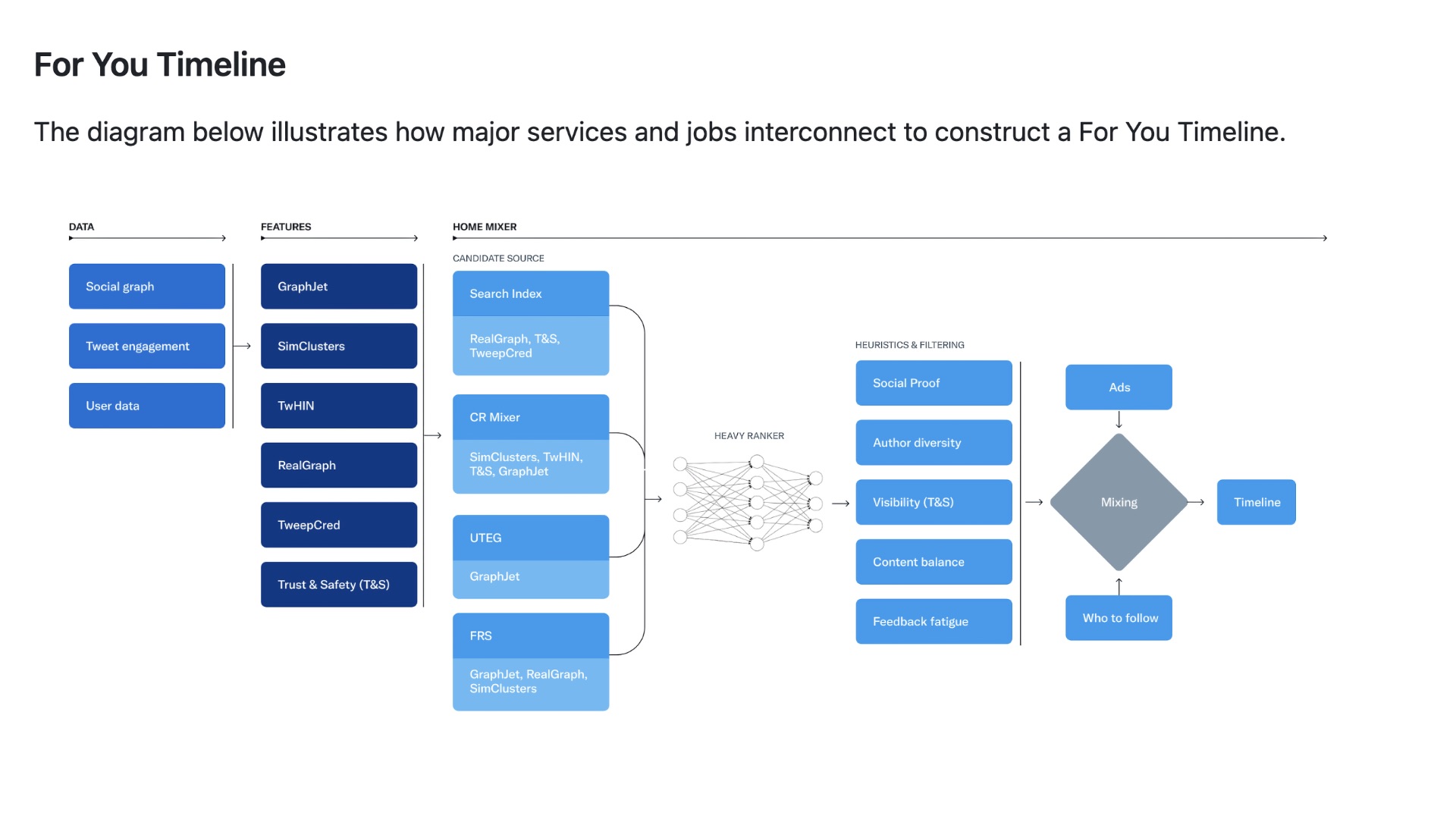
Из чего это все собрано
Проект построен на Scala (66%), Java (20%) и Rust. Некоторые модули используют Python и даже TensorFlow v1 (например, twml). Базовые компоненты включают:
- Данные —
tweepypie,unified-user-actions,user-signal-service - Модели —
SimClusters,TwHIN,real-graph,tweepcred,trust-and-safety-models - Фреймворки —
navi(на Rust),product-mixer,representation-scorer,representation-manager
Также присутствуют специфические компоненты для пушей — сервис pushservice, ранжирующие модели pushservice-light-ranker и pushservice-heavy-ranker, предсказывающие, откроет ли пользователь уведомление.
Почему это важно
Во-первых, X остается одной из крупнейших социальных платформ в мире, и понимание ее алгоритмов дает представление о принципах ранжирования и фильтрации контента.
Во-вторых, открытый код — это редкость в мире коммерческих рекомендаций, особенно на таком масштабе.
Разработчики предлагают сообществу вносить улучшения через пул-реквесты, участвовать в программах по поиску уязвимостей и разрабатывать на базе кода собственные сервисы.
Что это значит для разработчиков
Этот проект — хорошее поле для изучения реального промышленного машинного обучения. Особенно интересны:
- плотные графовые эмбеддинги в
TwHIN - модели репутации и социальной близости в
real-graphиtweepcred - многозадачные модели в
pushservice-heavy-ranker
Проект можно собрать с помощью Bazel, хотя полноценной инфраструктуры для тестов пока нет.

11К открытий26К показов

Meta* анонсировала Edits — видеоредактор, конкурирующий с CapCut. Приложение выйдет на iOS и Android, предложив мощные инструменты для контента
Объяснили, почему Python пользуется большой популярностью. До этого мы публиковали материал от ChatGPT, а эта статья написана человеком.

Apple выпустила Swift SDK для Android — теперь на Swift можно писать нативные Android-приложения и переносить код между платформами

Исследование Positive Technologies выявило, что ИБ-специалисты имеют менее недели на установку апдейтов. Вирусы и хакеры активно эксплуатируют уязвимости в WinRAR, Fortinet и Spring Framework. Эксперты рекомендуют инвентаризацию активов и системы управления уязвимостями для защиты IT-компаний.