


ИИ от Uber превзошёл человека в Montezuma’s Revenge
Новости
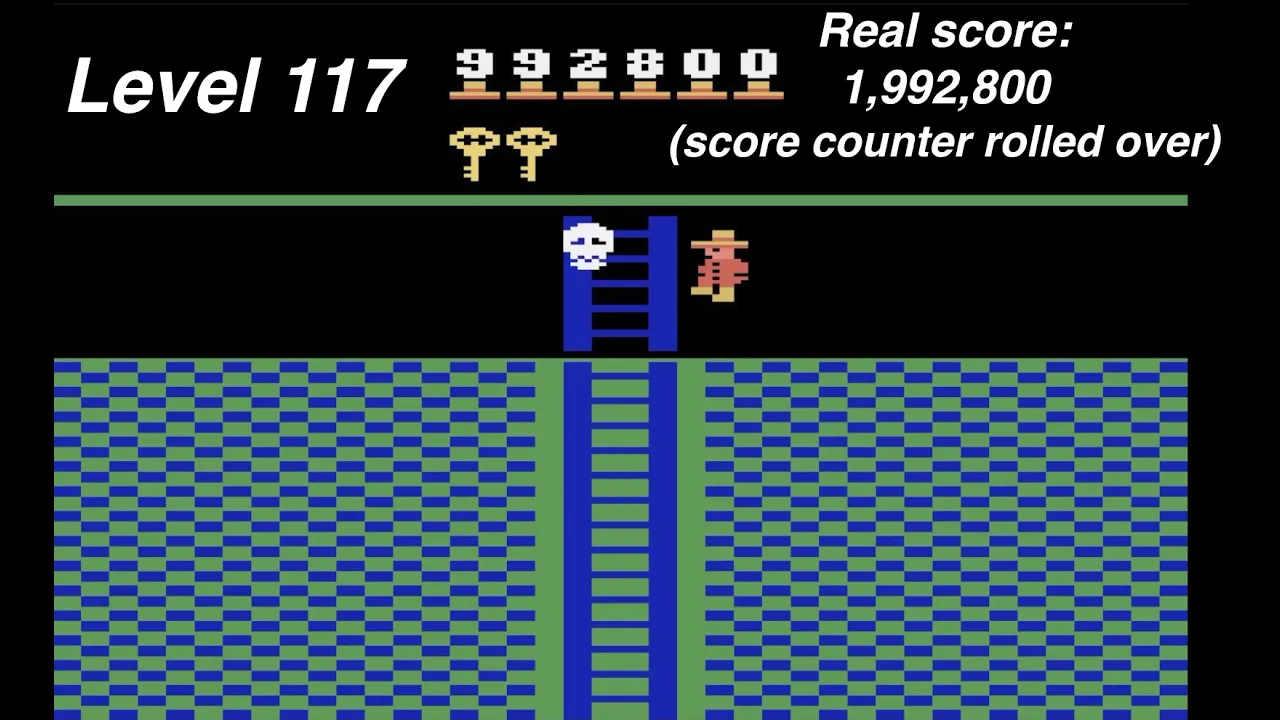
ИИ смог максимально набрать свыше 2 млн очков и 400 тысяч в среднем. Для сравнения, другие ИИ набирают порядка 10–17 тысяч очков.
972 открытий980 показов

Искусственный интеллект Go-Explore от компании Uber набрал в игре Montezuma’s Revenge большое количество очков, превосходящее на несколько порядков показатели других ИИ, а также живого игрока.
Что известно?
Сообщается, что Go-Explore набрал более 2 миллионов очков в игре Montezuma’s Revenge и дошёл до 159 уровня. Средние же его показатели составляют 400 тысяч баллов. Для сравнения, обычные ИИ-модели набирают в среднем 10 070, а максимально 17 500 очков. Для человека наибольший показатель равен 1 219 200.
Кроме того, в игре Pitfall ИИ Go-Explore также показал впечатляющие результаты. Средний балл системы составил более 21 000, что намного превосходит показатели человека в этой игре. Причём он набрал несколько очков с первой попытки, чего не могли добиться другие алгоритмы. В этой игре Go-Explore прошёл 40 уровней.
Разработчики заявили, что их алгоритм радикально отличается от других систем машинного обучения и превосходит все современные ИИ. Предполагается, что этот машинный интеллект станет основой для будущих «умных» роботов.
Как это работает?
Главным отличием Go-Explore является то, что этот ИИ умеет не только исследовать игровые пространства, но также определять в игре «перспективные места», которые содержат дополнительные награды. Определяя и запоминая их, в случае необходимости, ИИ возвращается к ним для получения дополнительных очков.

Другие системы, хотя и способны так же определять локации с бонусными очками, забывают о перспективных местах, пытаясь быстрее добраться до конца уровня. В случае же с Go-Explore, система сначала проводит разведку территории, а затем проходит уровни, собирая максимум наград.
В начале ноября 2018 года разработчики из OpenAI сообщили о результатах исследования машинного обучения с подкреплением, которое базируется на вознаграждении за правильные предсказания. Учёные представили метод тренировки ИИ-агентов RND (Random Network Distillation) без опоры на демонстрационные видео или другие обучающие материалы. Тестирование RND-агентов проводили на игре Montezuma’s Revenge.

972 открытий980 показов
Senior-разработчик объяснил, почему ИИ-помощники не заменят программистов: они ускоряют рутину, но не отвечают за архитектуру и защиту
Что такое Reinforcement Learning. Показываем, как работает Reinforcement Learning. Рассматриваем пошаговую инструкцию и основные нюансы

OpenAI представила GPT-4.1 — модель точнее GPT-4o, лучше пишет код, поддерживает до 1 млн токенов и стоит в разы дешевле для разработчиков

Паттерны проектирования архитектуры ПО. Показываем виды паттернов и их особенности. Рассматриваем пошаговую инструкцию и основные нюансы ✔ Tproger