


Amazon представила компилятор NNVM для фреймворков машинного обучения
Новости
Компания Amazon открыла код компилятора NNVM, разработанного для компиляции высокоуровневых графов вычислений в набор машинных кодов.
917 открытий935 показов
На данный момент существует широкий выбор фреймворков для разработки алгоритмов машинного обучения. Также есть возможность запускать код на огромном количестве устройств: от мобильных телефонов до облачных дата-центров. Это разнообразие является проблемой для разработчиков ИИ.
Во-первых, необходимо поддерживать на должном уровне работу многих фреймворков. Во-вторых, нужно гарантировать высокую производителность на разном железе, используя портируемый код, который подойдёт как для запуска в веб-браузере, так и на видеокартах дата-центров. В-третьих, необходимо убедиться, что работа фреймворков будет обеспечена на ещё не вышедшем железе.
Компилятор всему голова
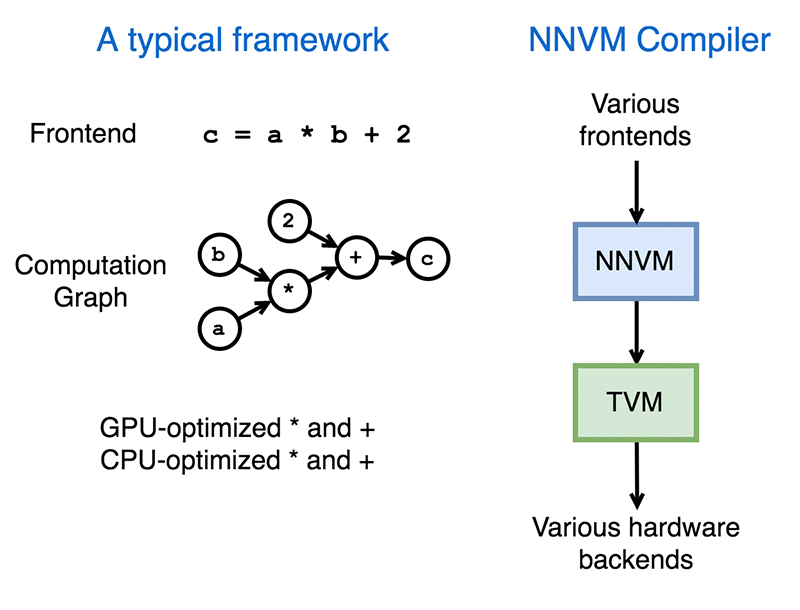
Amazon считает, что ключом к решению подобных проблем является используемый компилятор. Группа исследователей Вашингтонского университета и AWS представили свой подход в виде компилятора NNVM, основанный на применении стека TVM. Его целью является предоставление многократно используемой цепочки инструментов для компиляции описания высокоуровневых нейронных сетей из фреймворков глубинного обучения в низкоуровневые коды, используемые в бэкенде.
Компилятор NNVM
Целью компилятора является представление входных данных из разных фреймворков в качестве стандартизированных вычислительных графов с последующим их переводом в исполняемые графы.
Компилятор поддерживает модели в форматах OpenML (фреймворки Keras и Caffe), Apache MXNet и используемого Facebook и Microsoft открытого формата ONNX (Open Neural Network Exchange), при помощи которого передаются модели для обучения в фреймворках Caffe2, PyTorch и CNTK (Cognitive Toolkit). Результатом компиляции является код для различных бекэндов, включая вычислительные ядра CUDA, OpenCL и Metal. Также возможна генерация кода LLVM, на основе которого формируются машинные инструкции для архитектур x86 и ARM или представление WebAssembly.
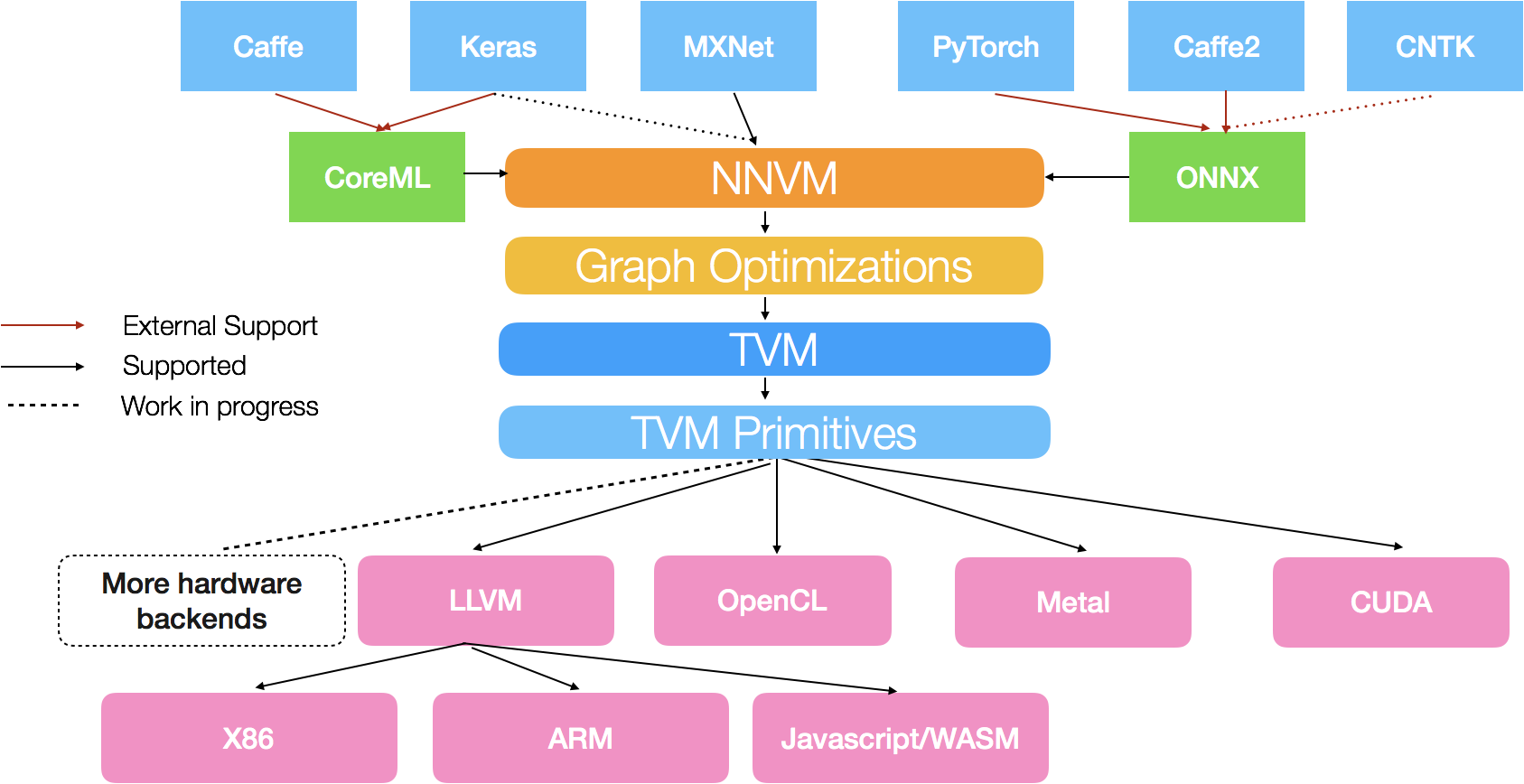
Процесс компиляции кода
- Формирование промежуточного графа вычислений на основе входных данных, полученных из фронтенд-интерфейсов фреймворков;
- Оптимизация графа и выделение в нём операторов с подпрограммами обработки данных;
- Компиляция операторов в исполняемые модули и развёртывание для различных бэкендов с минимальными зависимостями.
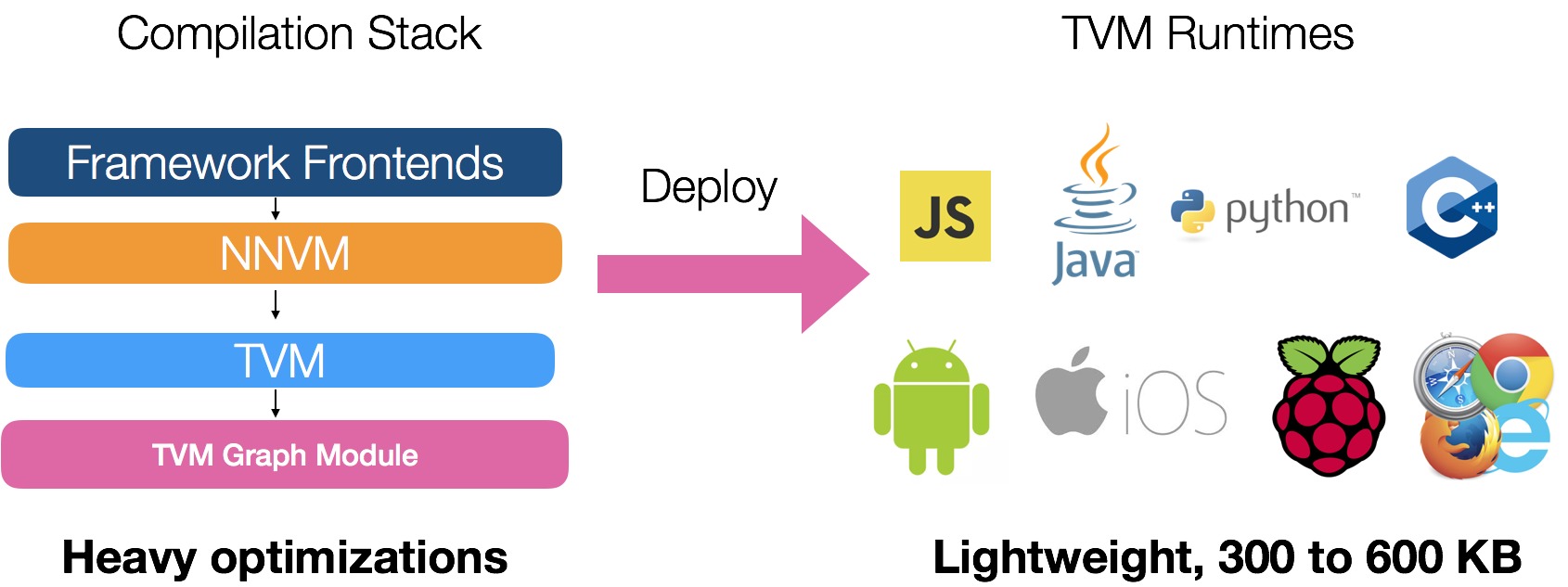
Полученные после компиляции модули могут быть сгенерированы в необходимый код на разных языках программирования: С++, Python, JavaScript, Java, Objective-C — для дальнейшего использования на мобильных платформах, видеокартах, серверах и в веб-браузерах.
Производительность компилятора
Сотрудники Amazon сравнили в производительности фреймворк MXNet и новый компилятор NNVM на двух разных аппаратных кофигурациях: ARM-процессор на Raspberry Pi и видеопроцессор Nvidia в облачных сервисах Amazon.

В случае видеокарт Nvidia для фреймворка MXNet в качестве бекэнда использовалась библиотека cuDNN на графическом ускорителе Nvidia K80. Компилятор NNVM показал ускорение в 1,2 раза для наборов данных ResNet18 и MobileNet.
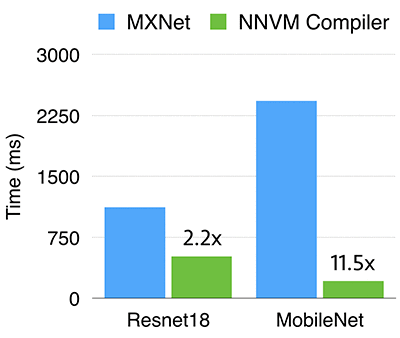
На Raspberry Pi демонстрируемые результаты ещё лучше. Скорость обработки ResNet18 у NNVM в 2,2 раза выше, а MobileNet — в 11,5 раз. Это связано главным образом с тем, что в MXNet глубина свёртки не оптимизирована (из-за отсутствия подобных операторов в библиотеке dnn), тогда как NNVM использует прямую генерацию эффективного кода.
Код компилятора и инструкция по его использованию доступны на GitHub.

917 открытий935 показов

Как рекламные алгоритмы понимают, что вы захотите купить, еще до того, как вы об этом подумали

AWS запускает новый бесплатный тариф: до $200 кредитов и 6 месяцев тестирования без списаний — старый план закроют 15 июля

Как покупали онлайн в 2001 году, когда не было маркетплейсов? История первых интернет-магазинов — от Amazon и eBay до Ozon и Утконоса. Почему россияне не доверяли онлайн-покупкам и какие прогнозы не сбылись? Подробный разбор зарождения e-commerce с цифрами и фактами.

Microsoft снова нанимает после массовых сокращений, но теперь ИИ решает, кого брать. Компания делает ставку на AI-first сотрудников