


DeepMind научили ИИ играть в Quake III Arena по-человечески
Новости
ИИ играл как в одиночку, так и собираясь в команды с людьми. DeepMind научил агентов использовать различные тактики и ориентироваться на местности.
1К открытий1К показов
Исследователи из DeepMind — подразделения Alphabet в сфере изучения ИИ — опубликовали в своем блоге запись об очередной разработке, призванной научить ИИ лучше играть в видеоигры. На этот раз специалисты видоизменили Quake III Arena и ее режим «Захват флага» и заставили агентов обучаться этой игре.

Подробнее об исследовании DeepMind
Авторы выбрали именно «Захват флага», чтобы ИИ самостоятельно обучился механикам игры в процедурно-генерируемом мире. Агенты играли как в одиночку, так и собираясь в команды, в том числе вместе с людьми. Кроме того, ИИ научился использовать такие тактики, как защита базы, ожидание противника и следование за напарником:

Разработчики использовали метод обучения с подкреплением, а ИИ не получал никакой дополнительной информации, кроме картинки на экране. Команда агентов обучалась с каждым матчем, получая позитивный отклик при победе. При этом у каждого из них была собственная внутренняя награда. ИИ основан на паре рекуррентных нейронных сетей, быстрой и медленной, каждая из которых изучает переход от набранных очков к внутренней награде.
По итогам исследования авторы обнаружили, что агенты ИИ не только выигрывали чаще, чем люди, но также были более сплоченными. Согласно полученным данным, у ИИ коэффициент Elo, отвечающий за шанс выигрыша, выше человеческого:
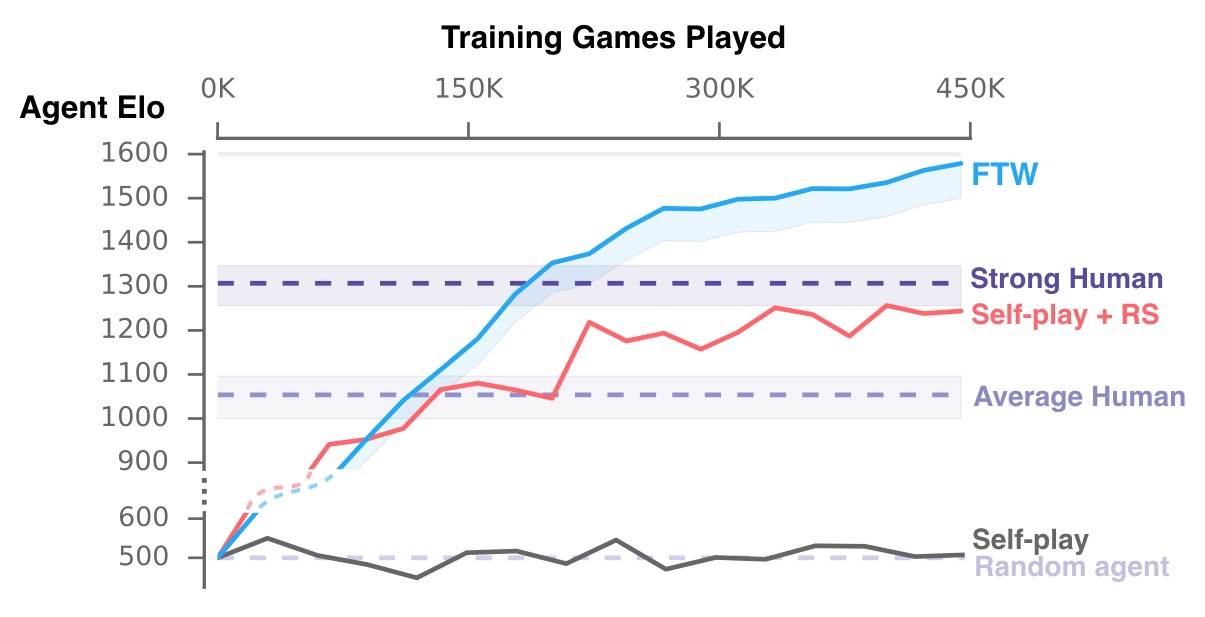
Авторы утверждают, что в будущем будут развивать технологии одновременного обучения с подкреплением нескольких агентов ИИ, а также уделять большее внимание объединению агентов и людей в команды для большей эффективности. Более детальное описание разработки можно получить в техническом документе.
Это не первое исследование возможностей ИИ для победы в видеоиграх. Предыдущей работой команды DeepMind был ИИ, обученный проходить игры по роликам на YouTube.

1К открытий1К показов

ИИ-ассистент, оптимизирующий клиентский сервис, для поддержки клиентов в Service Desk/Help Desk от Upservice. Обзор на нейропощника.

Московский суд восстановил сотрудницу, уволенную из-за внедрения ИИ. Увольнение признано незаконным — это первый подобный прецедент в России

Пост о перспективах создания высокоточных, не галлюцинирующих, соответствующих этике и безопасных ИИ-агентов. Будущее или реальность?

Акции и прибыль NVIDIA падают из-за новой экономической политики США. Рассказываем, что происходит с рынком чипов и при чем здесь Китай.