


ИИ AlphaGo от Google DeepMind стал полностью самообучаемым
Новости Отредактировано
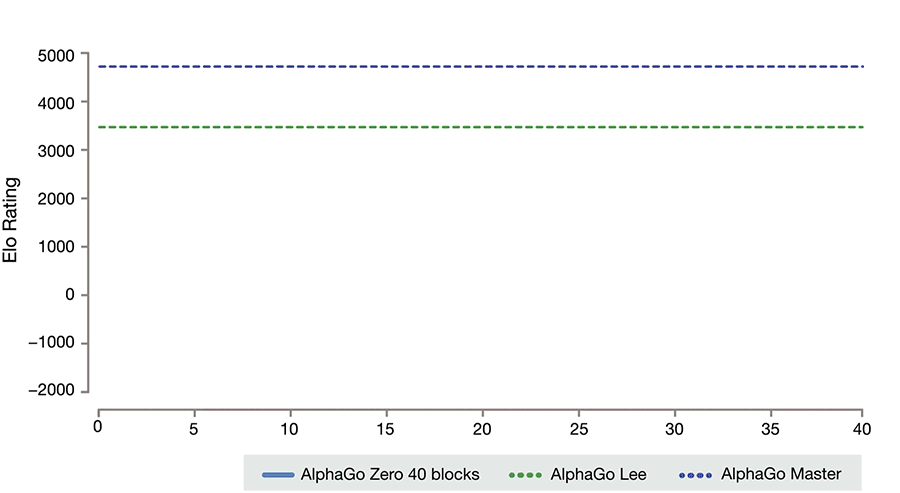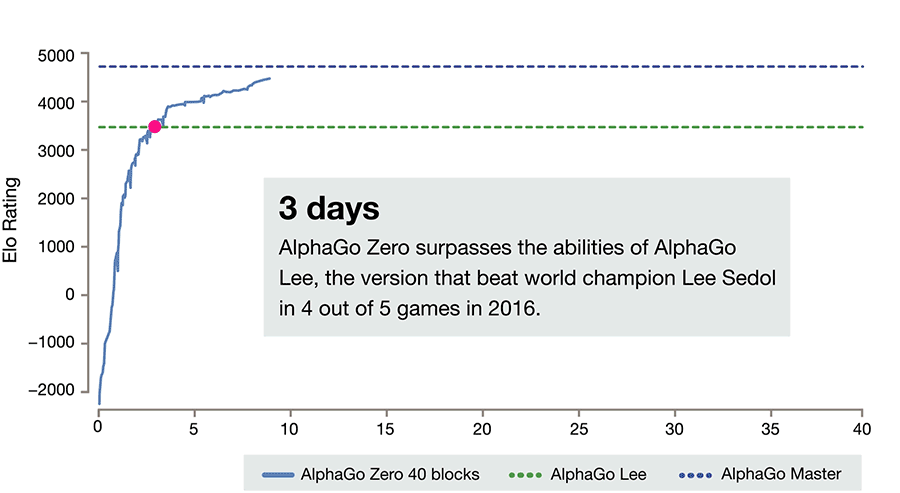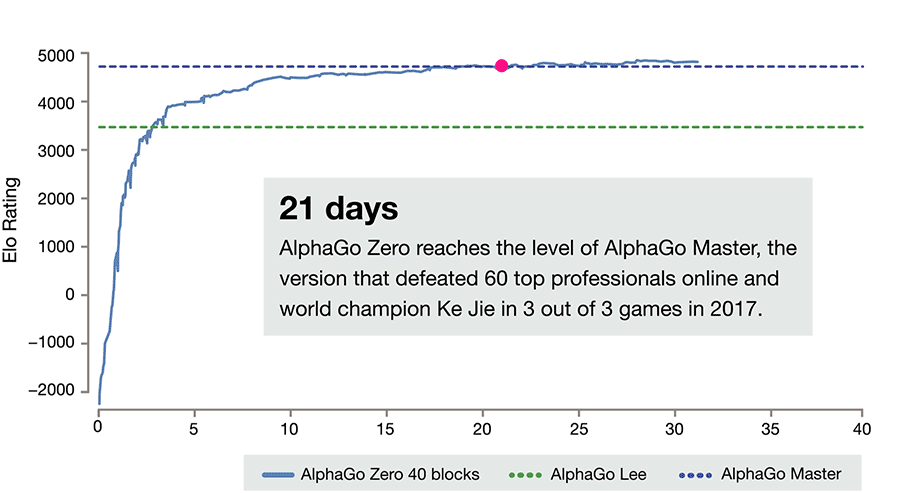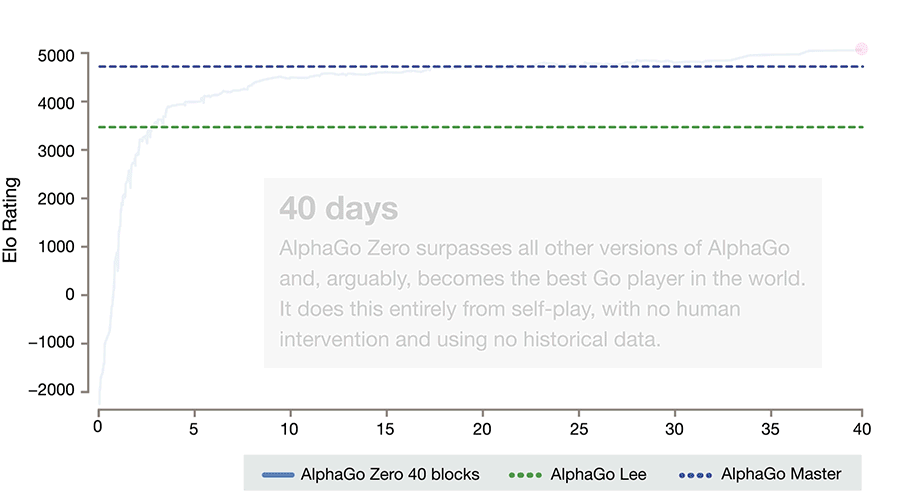
Модифицированная версия искусственного интеллекта AlphaGo Zero обучилась игре го с нуля за три дня, а через три недели уже обыграла ИИ, ставший чемпионом мира.
4К открытий4К показов
Исследования ИИ быстро продвигаются в самых разных областях, от распознавания речи и классификации изображений до генетики и открытия новых видов лекарств. Во многих случаях это специализированные системы, которые используют огромное количество человеческих знаний и данных.
Однако для некоторых задач человеческие знания могут быть слишком дорогостоящими, ненадёжными или просто недоступными. Поэтому давняя цель исследований ИИ заключается в том, чтобы обойти этот шаг, создавая алгоритмы, которые достигают сверхчеловеческой производительности в самых разных и сложных областях без человеческого участия.
Компания DeepMind, британское подразделение Google, опубликовала статью в научно-популярном журнале Nature, демонстрирующую значительные шаги навстречу данной цели.
AlphaGo Zero
Эта статья представляет миру проект AlphaGo Zero, являющийся потомком AlphaGo, первой в мире компьютерной программы, победившей человека-чемпиона в игру го. Zero является еще более мощным и, возможно, самым сильным игроком го в истории.

Предыдущие версии AlphaGo обучались игре по предоставленным им тысячам игр любителей и профессионалов го. Новый ИИ AlphaGo Zero пропускает этот шаг и обучается игре, просто-напросто играя в неё против себя, начиная с совершенно случайной игры. При этом он быстро превзошёл человеческий уровень игры и победил бывшего чемпиона AlphaGo со счётом 100:0.
Сам себе учитель
Подобный результат стал возможным благодаря использованию подхода обучения с подкреплением. Именно в таком виде обучения AlphaGo Zero становится своим собственным учителем. Система начинает самообучение с нейронной сетью, которая ничего не знает о го. Затем ИИ играет против себя, объединяя свою нейронную сеть с мощным алгоритмом поиска. С течением времени нейронная сеть настраивается и обновляется для прогнозирования ходов и возможного победителя игры.
Обучение продолжается несколько итераций подряд, в каждой из которых производительность системы увеличивается, что приводит к появлению более точных нейронных сетей и всё более сильных версий AlphaGo Zero.
Данный подход является более мощным, чем используемые в AlphaGo, потому что он больше не ограничивается пределами человеческого знания. Вместо этого он может научиться всему у самого сильного игрока в мире: чемпиона мира AlphaGo.
Отличия Zero от своего предшественника
- AlphaGo Zero использует только чёрные и белые камни с доски Go в качестве входных данных, тогда как обучение AlphaGo включало в себя небольшое количество функций, написанных программистами специально;
- Zero использует только одну нейронную сеть, а не две. AlphaGo мог обращаться к базе игр мастеров го, в его наборе была нейронная сеть, которая имитировала их стиль, а вторая нейронная сеть оценивала качество позиций для определения победителя в каждый момент игры;
- AlphaGo Zero не использует быстрые, случайные игры, как другие программы и алгоритмы, чтобы предсказать, какой игрок выиграет от текущей позиции на доске. Вместо этого он полагается на свою нейронную сеть для оценки позиций.
Эти алгоритмические изменения делают новую версию системы более мощной и эффективной по сравнению с предыдущей версией алгоритма:
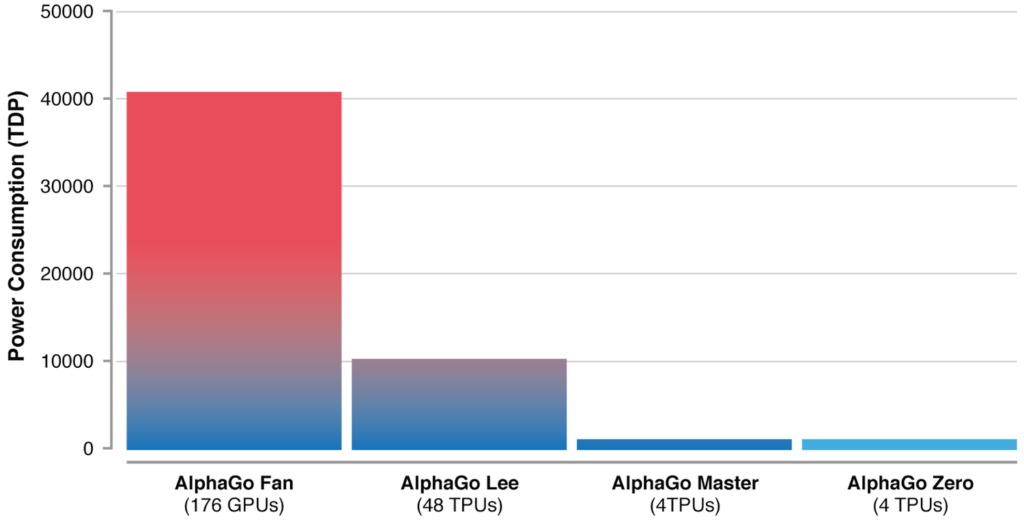
Качественный прорыв
После всего лишь трёхдневного обучения AlphaGo Zero смог победить версию AlphaGo, которая победила 18-кратного чемпиона мира Ли Седоля. После 40 дней самостоятельной подготовки AlphaGo Zero стал даже более сильным, чем версия AlphaGo, известная как «Мастер» и побеждавшая лучших игроков мира, в том числе номера один в рейтинге игроков го Кэ Цзе.
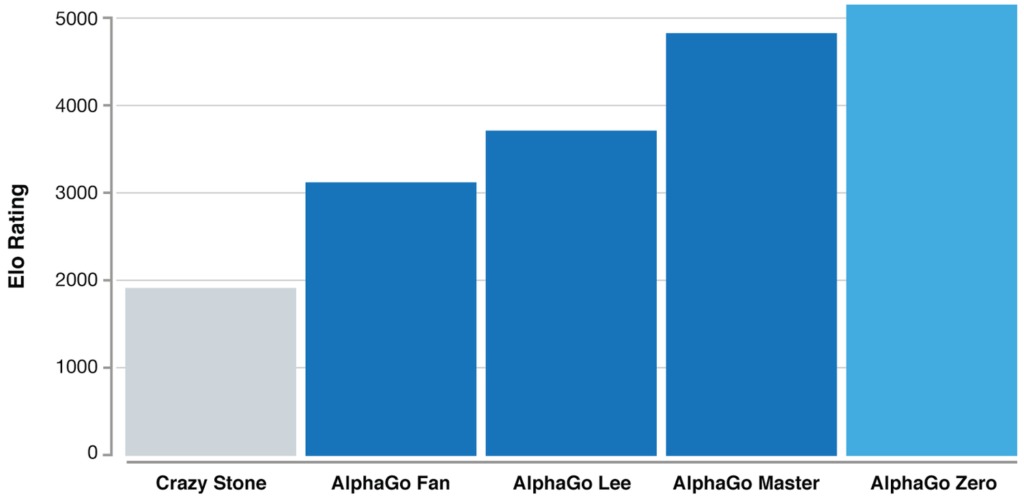
Данный график демонстрирует меру относительных уровней квалификации игроков в таких играх, как го. Это является показателем того, что AlphaGo становится все более сильным с каждым этапом развития проекта.
Польза самообучения
За время миллиона сыгранных партий «AlphaGo против AlphaGo» система постепенно изучила игру го с нуля, накопив тысячи лет человеческих знаний в течение всего лишь нескольких дней. AlphaGo Zero также обнаружил новые знания, разработал нетрадиционные стратегии и необычные подходы к решению задач, которые превзошли те методы, которые AlphaGo использовал в играх против Ли Седоля и Кэ Цзе .

Миссия ИИ
DeepMind говорят, что подобные моменты креатива, продемонстрированные ИИ, доказывают важность его использования. Он способен улучшить человеческую изобретательность и помочь в решении некоторых наиболее важных задач, стоящих перед человечеством.

Если подобные методы смогут быть применены к таким структурированным проблемам, как свёртывание белков, снижение потребления энергии или поиск революционно новых материалов, то достигнутые в этих сферах технологические прорывы положительно повлияют на общество.

4К открытий4К показов

Как понять, что Excel больше не справляется: признаки, что вашей команде пора внедрять систему автоматизации поддержки

W3C впервые с 2004 года обновила PNG: теперь формат поддерживает HDR, анимации (APNG) и EXIF-метаданные — это крупнейший апдейт за 20 лет

Половину кода в Google теперь пишет ИИ: автодополнение, автофиксы и генерация исправлений стали нормой. Что ждёт разработку дальше

Apple не смогла выпустить ИИ Siri из-за хаоса в команде AI/ML — только теперь проектом занялись Федериги и новое подразделение Intelligent Systems