


400 тысяч GitHub-репозиториев, 1 миллиард файлов, 14 ТБ кода: пробелы или табуляция?
Новости Отредактировано
17К открытий17К показов
Разработчик из Google Фелипе Хоффа решил получить ответ на один из самых популярных вопросов среди программистов: что же лучше, пробелы или табуляция? И получил, проанализировав 400 тысяч репозиториев на GitHub.
Правила:
- Источник данных: GitHub-файлы, хранящиеся в BigQuery.
- Рейтинг имеет значение: были отобраны только 400 тысяч репозиториев с наибольшим количеством звёзд, полученных с января по май 2016 года.
- Никаких маленьких файлов: в каждом файле должно быть не менее 10 строк, начинающихся с пробела или символа табуляции.
- Никаких дубликатов: дублирующиеся файлы участвуют лишь один раз, вне зависимости от того, в скольких репозиториях они находятся.
- Один голос на файл: в некоторых файлах используются и пробелы, и табуляция — в таком случае выбирается более часто используемый метод.
- Языки: рассматриваются файлы с расширениями: .java, .h, .js, .c, .php, .html, .cs, .json, .py, .cpp, .xml, .rb, .cc, .go.
Числа

Принцип работы
Использовалась уже существующая таблица [bigquery-public-data:github_repos.sample_files], в которой указаны файлы из 400 000 топовых репозиториев. Из неё было извлечено содержимое файлов с вышеупомянутыми расширениями:
Этот запрос занял прилично времени, так как происходило объединение таблицы в 190 миллионов строк с таблицей в 70 миллионов строк. Но вы можете не беспокоиться насчёт его запуска, поскольку автор выложил результат в [fh-bigquery:github_extracts.contents_top_repos_top_langs].
В таблице [contents] каждый уникальный файл отображается один раз. Чтобы увидеть общее число файлов и их размер, используйте:
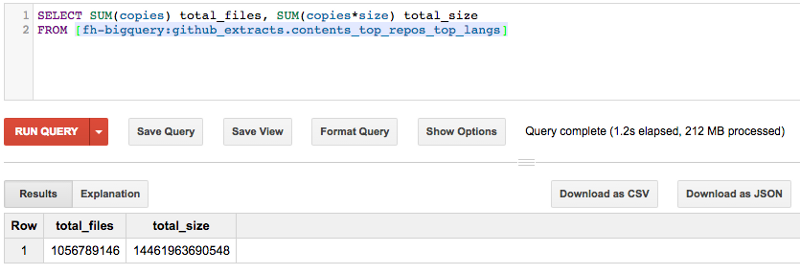
Для получения рейтинга по вышеобозначенным правилам введите:
Проанализировать 133 гигабайта кода за 16 секунд? Да, BigQuery это может ?
На данный момент этот блок не поддерживается, но мы не забыли о нём!Наша команда уже занята его разработкой, он будет доступен в ближайшее время.
А какой способ создания отступов предпочитаете вы?
Пробелы
Табуляция

17К открытий17К показов

Топ-10 CI/CD инструментов для DevOps: подробный обзор Jenkins, GitLab CI, CircleCI, werf, Argo CD и других. Критерии выбора, сравнение возможностей и сценариев применения. Как автоматизировать пайплайны для облачных и Kubernetes-проектов. Гайд для DevOps-инженеров по настройке эффективной доставки кода.

Разработчица изучила 900 open source ИИ-проектов и выявила ключевые тренды: оптимизация инференса, сжатие моделей и рост ИИ-агентов

Показываем, какими инструментами пользуются внутри айтишных команд и какие можно использовать для себя здесь и сейчас или внедрить в свою команду.
История о том, как попытка автоматизировать рутину привела к открытию и прокачке моих технических навыков в DevOps.