


Реверс-инжиниринг для начинающих: продвинутые концепции программирования

В статье будут рассмотрены массивы, указатели, динамическое распределение памяти, программирование сокетов (сетевое программирование) и многопоточность.
7К открытий8К показов

В первой части мы рассмотрели базовые концепции программирования, такие как циклы и условный оператор, в этой статье будем рассматривать более сложные темы, необходимые для реверс-инжиниринга.
Примечание Для дизассемблирования в этой статье используется IDA Pro, но многие её функции (например блок-схемы, перевод в псевдокод и т. д.) можно найти в качестве надстроек в бесплатных дизассемблерах (radare2). Более того, для лучшего понимания имена некоторых дизассемблированных переменных были изменены с «v20» на имена, которые были у них в С. Также в этой статье исполняемый файл был скомпилирован в 64-битной версии, а для дизассемблирования используется 64-битная версия IDA Pro. Это на случай, если вы захотите повторить всё самостоятельно, потому что это может повлиять на конечный результат (например, на массивах будет сильное различие 32 и 64-битных версий, а также в 64-битной версии регистры становятся в два раза больше).
Массивы
Итак, начнём с массивов. Сначала рассмотрим код на Си:
Эти 12 строк кода превращаются в довольно внушительный блок машинного кода. Давайте рассмотрим его детально:

При инициализации массива с константным размером компилятор просто инициализирует длину массива через локальную переменную.
Во время компиляции будет выделено место только под одно значение массива litArray[0], которое и будет использоваться (можно увидеть на скриншоте ниже). Такой приём позволяет компилятору значительно увеличить производительности приложений.
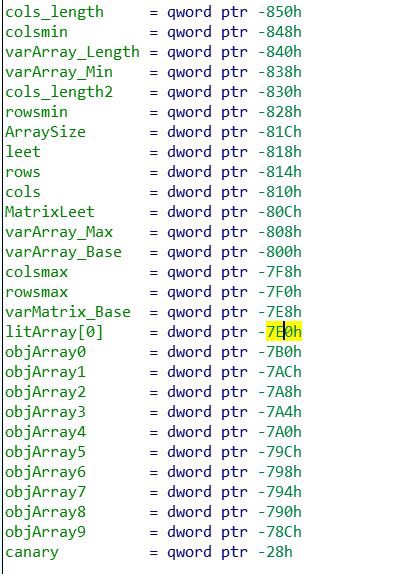
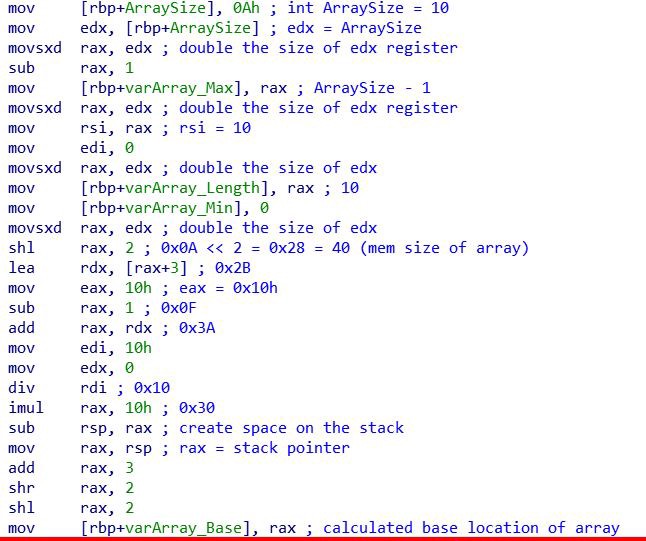
Сначала длина массива сохраняется в локальную переменную ArraySize, затем вычисляется максимальное и минимальное индексное значение, а также длина всего массива, а затем под неё выделяется память.
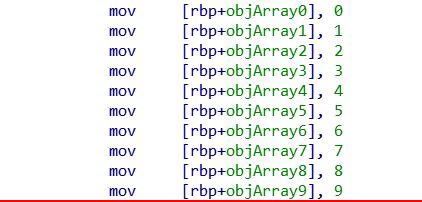
При объявлении массива с предопределёнными значениями компилятор сохраняет каждое значение в свою переменную, которая представлена индексом массива (например objArray4 = objArray[4]).
Так же как и с предопределёнными значениями, компилятор создаёт новую переменную для указанного индексного значения при инициализации элемента массива через индекс.
При извлечении элемента массива значение элемента берётся по указанному индексу и записывается в нужную переменную.

При создании матрицы сначала её размер устанавливается в соответствии со значениями row и col. Затем рассчитываются максимальный и минимальный индексы для строк и столбцов, которые используются для расчёта базового местоположения и общего размера матрицы в памяти.
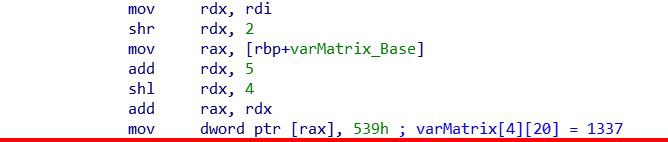
При вводе в матрицу сначала определяется местоположение желаемого элемента массива с использованием базового местоположения матрицы. Затем содержимое указанного элемента массива устанавливается на желаемое входное значение (т.е. 1337).
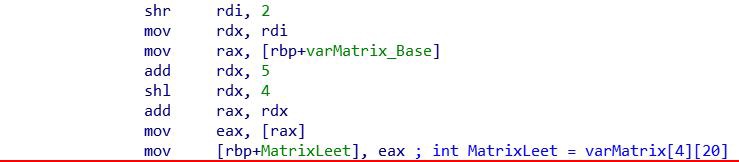
При извлечении значения из матрицы происходят такие же вычисления, как и при внесении значения в неё. Однако при этом ничего не записывается — содержимое извлекается и записывается в нужную переменную (например MatrixLeet).
Указатели
Теперь, когда мы понимаем, как массивы используются и выглядят в машинном коде, давайте перейдём к указателям.
Давайте сразу разберёмся в машинном коде:
Сначала мы присваиваем переменной num значение 10.
Затем указателю pointer присваивается адрес переменной num.
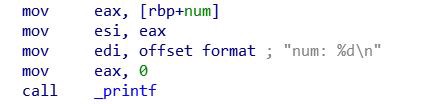
Вывод переменной num на экран.
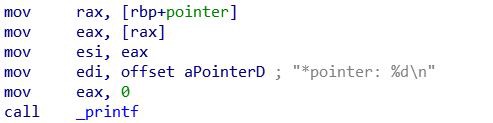
Вывод переменной pointer на экран.

Вывод адреса переменной num происходит с помощью инструкции lea (загрузка результирующего адреса) вместо mov.

Вывод адреса переменной num через указатель pointer.

Вывод адреса переменной pointer происходит с помощью инструкции lea вместо mov.
Динамическое распределение памяти
В этой статье будут рассмотрены следующие виды динамического распределения памяти:
- malloc.
- calloc.
- realloc.
malloc — динамическое выделение памяти
Сначала разберёмся в коде:
Прим. перев. В оригинале статьи выделяется 11 байтов, хотя правильно будет 12. В конце строки ещё добавляется символ с кодом 0.
В этой функции выделяется место под 11 символов с помощью malloc(), а затем в выделенное пространство памяти копируется «Hello World».
Теперь давайте посмотрим на машинный код:
Примечание Во время сборки вы можете увидеть инструкции «nop». Эти инструкции были специально размещены на этапе подготовки к статье, чтобы различные части кода было проще понимать.
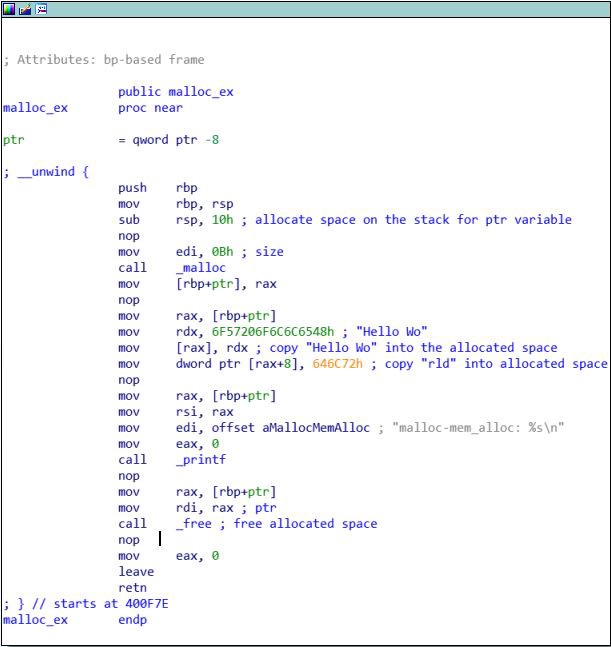
При использовании malloc() размер выделенной памяти (0x0B) сначала перемещается в регистр edi. Затем системная функция _malloc вызывается для выделения памяти. Выделенная область памяти затем сохраняется в переменной ptr. Потом строка «Hello World» разбивается на «Hello Wo» и «rld», поскольку она копируется в выделенное пространство памяти. Наконец, вновь скопированная строка «Hello World» выводится на экран, а выделенная память освобождается с помощью функции _free.
calloc — динамическое чистое выделение памяти
Посмотрим на код:
Как и в методе malloc(), место для 11 символов выделяется, а строка «Hello World» копируется в указанное пространство. Затем вновь перемещённый «Hello World» распечатывается, и выделенное пространство памяти освобождается.
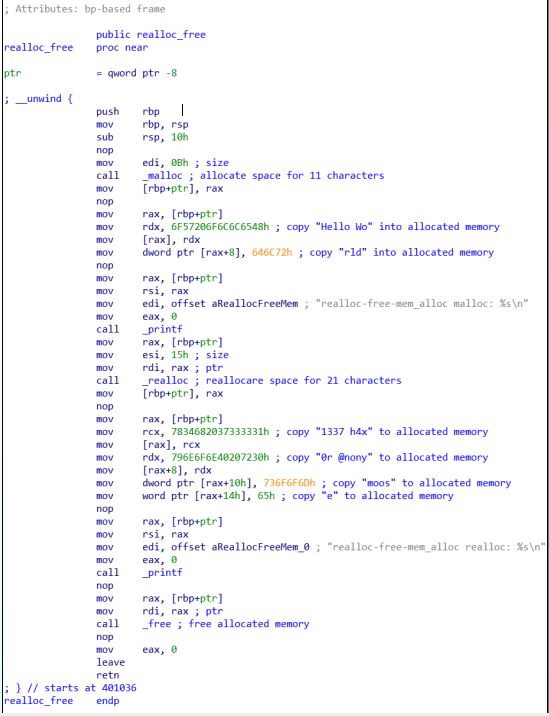
Динамическое распределение памяти через calloc() выглядит почти идентично динамическому распределению памяти через malloc() в машинном коде.
Во-первых, пространство для 11 символов (0x0B) выделяется с помощью системной функции _calloc. Затем строка «Hello World» разбивается на «Hello Wo» и «rld„, поскольку она копируется во вновь выделенную область памяти. Затем вновь перемещённая строка “Hello World» выводится на экран, а выделенная область памяти освобождается с помощью функции _free.
realloc — динамическое перераспределение памяти
Сначала посмотрим код.
В этой функции память для 11 символов выделяется с помощью malloc(). Затем «Hello World» копируется в только что выделенное пространство памяти, прежде чем указанное расположение памяти перераспределяется, чтобы соответствовать 21 символу.
Прим. перев.: Должно быть 22 символа. Снова автор забыл символ с кодом 0, используя realloc()
Наконец, «1337 h4x0r @nonymoose» копируется в только что перераспределённое пространство. Наконец, после вывода на экран память освобождается.
Теперь посмотрим машинный код:
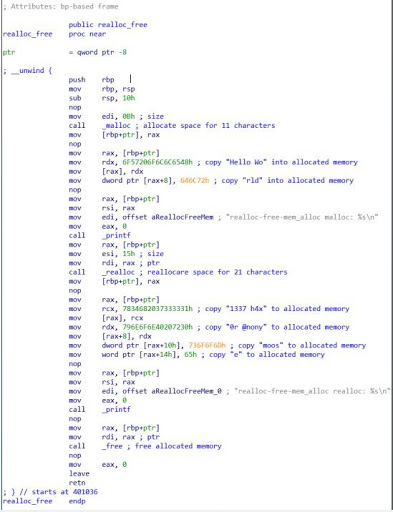
Сначала память выделяется с помощью malloc(). Затем, после вывода на экран только что перемещённой строки «Hello World», вызывается realloc() для переменной ptr (которая представляет переменную mem_alloc в коде), а также передаётся новый размер 0x15 (21 в десятичном виде). Затем «1337 h4x0r @nonymoose» разбивается на «1337 h4x„, “0r @nony», «moos» и «e„, поскольку он копируется в только что перераспределённое пространство памяти. Наконец, пространство освобождается с помощью функции _free.
Программирование сокетов
Далее мы рассмотрим программирование сокетов, разобрав очень простую систему клиент-серверного TCP-чата.
Прежде чем мы начнём разбирать код сервера или клиента, важно указать следующую строку кода в верхней части файла:
Эта строка определяет константу PORT как 1337. Эта константа будет использоваться как на клиенте, так и на сервере в качестве сетевого порта, используемого для создания соединения.
Серверная часть
Сначала посмотрим на код:
Сначала создаётся файловый дескриптор сокета server с доменом AF_INET, типом SOCK_STREAM и кодом протокола 0. Далее настраиваются параметры сокета и адрес. Затем сокет привязывается к сетевому адресу (порту), и сервер начинает прослушивать указанный порт с максимальной длиной очереди 3. После получения соединения сервер принимает его в переменную sock и считывает переданное значение в переменную value.
Наконец, сервер отправляет строку serverhello по соединению до возврата функции.
Теперь давайте разберём его в машинном коде:
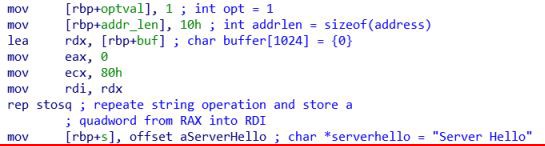
Сначала создаются и инициализируются переменные сервера.

Затем создаётся файловый дескриптор сокетов server с помощью системной функции _socket. Параметры для функции — протокол, тип и доменное имя передаются с помощью регистров edx, esi и edi соответственно.

Затем вызывается _setsockopt для задания параметров сокета в файле дескриптора “server».

Инициализируется серверный адрес с помощью adress.sin_family, address.sin_addr.s_addr и address.sin_port.

После того как сервер был сконфигурирован, он привязывается к интернет-адресу с помощью _bind.

После привязки сервер слушает сокет, передав файловый дескриптор server. Максимальная длина очереди равна 3.

Как только соединение установлено, сервер принимает соединение сокета в переменную sock.

Затем сервер считывает переданное в переменную value сообщение с помощью _read.
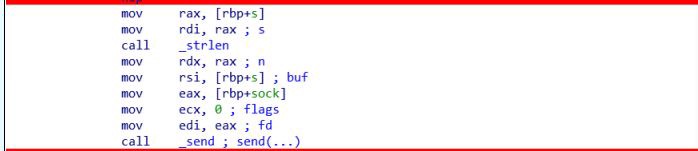
В конце концов, сервер отсылает сообщение serverhello через переменную s в машинном коде.
Клиентская часть
Сначала разберёмся в коде:
Сначала создаётся файловый дескриптор сокета sock с помощью переменной домена AF_INET типа SOCK_STREAM и кода протокола 0. Затем memset используется для заполнения области памяти server_addr нулями до того, как информация об адресе будет установлена с помощью server_addr.sin_family и server_addr.sin_port. До того как клиент подключится к серверу, информация об адресе преобразуется из текстового в двоичный формат с использованием inet_pton. После подключения клиент отправляет строку helloclient и затем принимает ответ сервера в переменную value. Наконец, переменная value выводится на экран, и происходит возврат из функции.
Теперь разбёремся в машинном коде:

Сначала инициализируются локальные переменные клиента.

Дескриптор файла сокета «sock» создается путём вызова системной функции _socket и передачи информации о протоколе, типе и домене через регистры edx, esi и edi соответственно.

Переменная server_address (в машинном коде «s») заполняется нулями (0x30) с помощью системного вызова _memset.

Потом настраивается адресная информация сервера.

Затем адрес переводится из текстового в двоичный формат с помощью системной функции _inet_pton. Обратите внимание, что, поскольку в коде явно не указан адрес, предполагается localhost (127.0.0.1).
Клиент подключается к серверу с помощью системного вызова _connect.
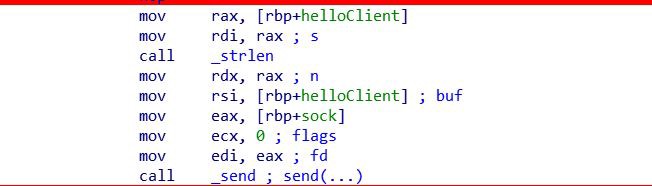
После подключения клиент отправляет строку helloClient на сервер.
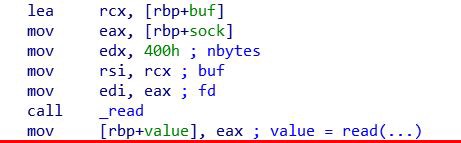
Наконец, клиент получает ответ сервера в переменную value с помощью системного вызова _read.
Многопоточность
Наконец, мы рассмотрим основы потоков в C.
Во-первых, давайте посмотрим на код:
Как вы можете видеть, программа сначала печатает «This is before the thread», затем создаёт новый поток, который указывает на функцию *mythread(), используя функцию pthread_create(). По завершении функции *mythread() (после сна длиной в 1 секунду и вывода на экрана «Hello from mythread») новый поток присоединяется к основному потоку с помощью функции pthread_join() и выводится на экран «This is after the thread».
Теперь давайте разберём машинный код:
Сначала программа печатает «This is before the thread».

Затем создаётся новый поток с помощью системного вызова _pthread_create. Этот поток получает mythread() в качестве аргумента.

Как вы можете видеть, функция mythread() просто спит одну секунду перед выводом «Hello from mythread».
Примечание Внутри функции mythread() вы увидите два нопа. Они были специально размещены для облегчения навигации на этапе подготовки этой статьи.

После возврата из функции mythread() новый поток соединяется с основным потоком с помощью функции _pthread_join.
Наконец, на экран выводится «This is after the thread» и происходит возврат из функции.
Заключение
В статье мы рассмотрели массивы, указатели, динамическое распределение памяти, программирование сокетов (сетевое программирование) и многопоточность. Понимание этих аспектов существенно поможет вам продвинуться в изучении реверс-инжиниринга.

7К открытий8К показов

В этой статье разберём, что происходит в сфере кибербезопасности сейчас, какие навыки нужно качать специалисту по ИБ и куда расти.
Искусственный интеллект продолжает становиться все «интеллектуальнее», а новые инструменты удивляют своей мощью. Рассказываем о пяти решениях, которые уже переворачивают рынок.

Актуальные требования к обработке персональных данных в 2025 году. Как разработчикам соблюдать закон и избежать штрафов. Практические советы по защите информации в коде и архитектуре приложений.
Обзор познакомит с RBAC Wizard — удобным инструменте для тех, кому периодически нужно проводить аудит прав доступа в кластере Kubernetes.