Разбираемся в типах NoSQL СУБД

В этой статье мы познакомимся с 4 основными типами NoSQL баз данных: ключ-значение, документоориентированной, колоночной и графовой.

В этой статье мы познакомимся с разными типами NoSQL СУБД.
Всего есть 4 основных типа:
- Хранилище «ключ-значение» — в нём есть большая хеш-таблица, содержащая ключи и значения. Примеры: Riak, Amazon DynamoDB;
- Документоориентированное хранилище — хранит документы, состоящие из тегированных элементов. Пример: CouchDB;
- Колоночное хранилище — в каждом блоке хранятся данные только из одной колонки. Примеры: HBase, Cassandra;
- Хранилище на основе графов — сетевая база данных, которая использует узлы и рёбра для отображения и хранения данных. Пример: Neo4J.
База данных типа «ключ-значение»
Отсутствие схемы в базах данных «ключ-значение», например, Riak, — это как раз то, что вам нужно для хранения данных. Ключ может быть синтетическим или автосгенерированным, а значение может быть представлено строкой, JSON, блобом (BLOB, Binary Large Object, большой двоичный объект) и т.д.
Такие базы данных как правило используют хеш-таблицу, в которой находится уникальный ключ и указатель на конкретный объект данных. Существует понятие блока (bucket) — логической группы ключей, которые не группируют данные физически. В разных блоках могут быть идентичные ключи.
Производительность сильно вырастает за счёт кеширующих механизмов, которые работают на основе маппингов. Чтобы прочитать значение, вам нужно знать как ключ, так и блок, поскольку на самом деле ключ является хешем (блок + ключ).
В модели «ключ-значение» нет ничего сложного, так как реализовать её проще простого. Не лучший способ, если вам нужно только обновить часть значения или сделать запрос к базе данных.
Если поразмыслить о теореме CAP, то становится довольно очевидно, что такие хранилища хороши в плане доступности (Availability) и устойчивости к разделению (Partition tolerance), но явно проигрывают в согласованности данных (Consistency).
Пример: посмотрим на набор данных, представленных таблицей ниже. Здесь ключ — это название страны, а значение — список адресов в этой стране:

База данных такого типа позволяет читать и записывать значения с помощью ключа следующим образом:
Get(key)возвращает значение, связанное с переданным ключом;Put(key, value)связывает значение с ключом;Multi-get(key1, key2, ..., keyN)возвращает список значений, связанных с переданным ключами;Delete(key)удаляет запись для ключа из хранилища.
И хотя базы данных типа «ключ-значение» могут пригодиться в определённых ситуациях, они не лишены недостатков. Первый заключается в том, что модель не предоставляет стандартные возможности баз данных вроде атомарности транзакций или согласованности данных при одновременном выполнении нескольких транзакций. Такие возможности должны предоставляться самим приложением.
Второй недостаток в том, что при увеличении объёмов данных, поддержание уникальных ключей может стать проблемой. Для её решения необходимо как-то усложнять процесс генерации строк, чтобы они оставались уникальными среди очень большого набора ключей.
Riak и Dynamo от Amazon — самые популярные СУБД данных такого типа.
Документоориентированная база данных
Данные, представленные парами ключ-значение, сжимаются как хранилище документов схожим с хранилищем «ключ-значение» образом, с той лишь разницей, что хранимые значения (документы) имеют определённую структуру и кодировку данных. XML, JSON и BSON — некоторые из стандартных распространённых кодировок.
В следующем примере можно увидеть данные в виде «документа» который отображает названия определённых магазинов. Обратите внимание, что, хотя все три примера содержат местоположение, они отображают его по-разному:
Одним из ключевых различий между хранилищем «ключ-значение» и документоориентированным является то, что последний включает метаданные, связанные с хранимым содержимым, что даёт возможность делать запросы на основе содержимого. Например, в указанном примере можно попробовать найти все документы, в которых «City» равно «Noida», что вернёт все документы, связанные с магазинами в этом городе.
Apache CouchDB — пример документоориентированной СУБД. CouchDB использует JSON для хранения данных, JavaScript в качестве языка запросов с использованием MapReduce и HTTP для API. Данные и отношения не хранятся в таблицах так, как в традиционных реляционных базах данных, а по сути являются набором независимых документов.
Тот факт, что такие базы данных работают без схемы, делает простой задачей добавление полей в JSON-документы без необходимости сначала заявлять об изменениях.
Couchbase и MongoDB — самые популярные документоориентированные СУБД.
Колоночная база данных
В колоночных NoSQL базах данных данные хранятся в ячейках, сгруппированных в колонки, а не в строки данных. Колонки логически группируются в колоночные семейства. Колоночные семейства могут состоять из практически неограниченного количества колонок, которые могут создаваться во время работы программы или во время определения схемы. Чтение и запись происходит с использованием колонок, а не строк.
В сравнении с хранением данных в строках, как в большинстве реляционных баз данных, преимущества хранения в колонках заключаются в быстром поиске/доступе и агрегации данных. Реляционные базы данных хранят каждую строку как непрерывную запись на диске. Разные строки хранятся в разных местах на диске, в то время как колоночные базы данных хранят все ячейки, относящиеся к колонке, как непрерывную запись, что делает операции поиска/доступа быстрее.
Пример: получение списка заголовков нескольких миллионов статей будет трудоёмкой задачей при использовании реляционных баз данных, так как для извлечения заголовков придётся проходить по каждой записи. А можно получить все заголовки с помощью только одной операции доступа к диску.
Модель данных
- Колоночное семейство — структура, которая может легко группировать колонки и суперколонки;
- Ключ — постоянное имя записи. У ключей может быть разное количество колонок, поэтому база данных может расширяться неравномерно;
- Пространство ключей — определяет самый внешний уровень организации, как правило, имя приложения/базы данных.
- Колонка — имеет упорядоченный список элементов — кортежей с именами и значениями.
Самыми известными примерами являются Google BigTable и HBase с Cassandra, вдохновлённые BigTable.
BigTable представляет собой высокопроизводительное, сжатое и проприетарное хранилище данных от Google. У него есть следующие атрибуты:
- Разреженность — некоторые ячейки могут быть пустыми;
- Распределённость — данные разделены между многими узлами;
- Постоянство — хранится на диске;
- Многомерность — более 1 измерения;
- Сопоставление — ключ и значение;
- Отсортированность — сопоставления обычно не сортируются, но этот случай — исключение.
Двумерная таблица, состоящая из строк и колонок, является частью реляционной системы баз данных.

Эту таблицу можно представить в виде BigTable-сопоставления следующим образом:
- Внешние ключи «3PillarNoida», «3PillarCluj», «3PillarTimisoara» и «3PillarFairfax» являются аналогами строк.
- «address» и «details» — колоночные семейства.
- В колоночном семействе «address» есть колонки «city» и «pincode».
- В колоночном семействе «details» есть колонки «strength» и «projects».
На колонки можно ссылаться с помощью колоночного семейства.
Графовая база данных
В графовой базе данных вы не найдёте строгого формата SQL или представления таблиц и колонок, вместо этого используется гибкое графическое представление, которое идеально подходит для решения проблем масштабируемости. Графовые структуры используются вместе с рёбрами, узлами и свойствами, что обеспечивает безиндексную смежность. При использовании графового хранилища данные могут быть легко преобразованы из одной модели в другую.
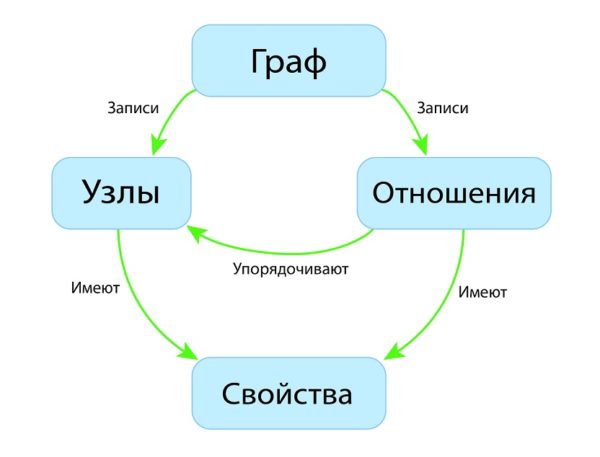
- Такие базы данных используют рёбра и узлы для представления данных.
- Узлы связаны между собой определённым отношениями, представленными рёбрами между ними.
- У узлов и отношений есть некоторые свойства.
Далее описаны некоторые особенности графовой базы данных на основе примера ниже:
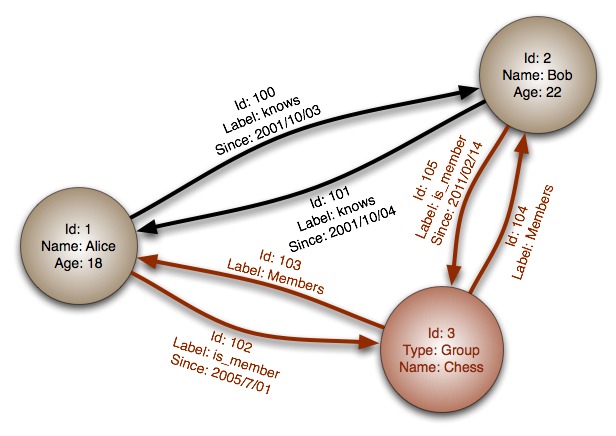
Помеченный, направленный, атрибутированный мультиграф: граф содержит узлы, которые помечены определёнными свойствами и которые имеют связи друг с другом, что представлено направленными рёбрами. Например, связь «Элис знает Боба» выражена ребром с некоторыми свойствами.
Хотя реляционные базы данных могут скопировать поведение графовых, рёбрам потребуется соединение (JOIN), что дорого обойдётся.
Пример использования
Любой рейтинг «Рекомендовано вам», который можно увидеть на разных сайтах, зачастую составляется исходя из того, как другие пользователи оценили продукт. Графовые базы данных отлично подходят для такого случая.
InfoGrid и Infinite Graph — самые популярные графовые базы данных. InfoGrid позволяет соединять множество рёбер (Relationships) и узлов (MeshObjects), что упрощает представление набора информации со сложными взаимными ссылками.
InfoGrid предлагает два типа баз данных:
- MeshBase — подходящий вариант для автономного развёртывания;
- NetMeshBase — подойдёт для больших распределённых графов и имеет дополнительные возможности для взаимодействия с другими похожими NetMeshBase.
Смотрите также: SQL против NoSQL на примере MySQL и MongoDB

56К открытий57К показов

Рассказали о мерах безопасности в 1С-Битрикс, которые обеспечат надежную работу всей системы. И показали, как настроить встроенные средства защиты и журналирования.

IT-блогер Learn with Lukas рассказал о 10 бесплатных онлайн-платформах для изучения SQL.

Рассказали об операторе UPDATE SQL, разобрали синтаксис оператора и рассмотрели его использование на практических примерах.
Рассказали, как удалить дубликаты в огромной базе данных, и о том, как обработать большой объем данных невысокого качества.