


A/B тестирование на примере онлайн-кинотеатра KION
Разбираемся, как проводить A/B-тестирование на примере онлайн-кинотеатра: инструкции со скринами, расчёты и результат.
7К открытий14К показов

Александр Труфанов
Руководитель направления Продуктовой аналитики МТС Медиа/KION
На примере фичи Autoplay разберёмся в том, как проводится A/B-тестирование. Autoplay в KION — это фича по вовлечению пользователей. Когда человек заканчивает смотреть какой-то фильм, мы не отправляем его на витрину, в поиск, в фильтры или ещё куда-то, а предлагаем новую ленту, похожую на то, что он только что просмотрел.
Для контекста: как работает Autoplay
Фильмы и сериалы на KOIN размечены с точки зрения контента. И когда начинаются титры и пользователь думает, чем ему заняться дальше, система подбирает и выдаёт ему рекомендации.
Выходит превьюшка: «уважаемый пользователь, скоро начнётся следующий фильм», — и постер, а титры сворачиваются в маленький экран сбоку. Также появляются две кнопки: «смотреть фильм» и «смотреть титры».
Как подбирается лента? Мы берём единицу контента и смотрим, что ещё смотрели пользователи вместе с ней. Потом на основе этих знаний строим предиктивные модели и решаем, какие фильмы могут понравиться зрителю.
Другой способ — использовать модель p2p – person by person. Есть два человека, которые посмотрели какое-то количества контента. Среди их истории просмотра мы находим пересечения и делаем вывод, что вкусы двух людей похожи. И предполагаем, что если одному человеку понравился конкретный фильм, то и второму он покажется интересным.
Как проводить A/B-тестирование
Мы выдвигаем гипотезу, берём две группы зрителей — А и В. У группы А функционал остаётся без изменений, группе B мы выкатываем новый функционал и смотрим, как она себя повела и есть ли разница с группой A. На основе этого решаем, внедрять фичу или нет.
Гипотезы
У нас есть команда — продакт-менеджер и аналитик. Они изучают продукт, определяют, какие метрики хотелось бы нарастить, и выдвигают гипотезу, которая, по идее, должна в этом помочь.
На этом этапе мы формулируем, какое изменение хотим увидеть и сколько пользователей нам нужно вовлечь в исследование, чтобы это изменение было статистически значимым.
В эксперименте с Автоплеем мы предположили, что благодаря фиче пользователь будет дольше оставаться на платформе и посмотрит больше фильмов. А ещё решили, что она избавит человека от «мук выбора».
Главными метриками стали TVTU (total view time на юзера) и количество просмотренного контента за сессию.
Создание фичи
На основе гипотезы команда пишет техническое задание и описывает, что мы хотим увидеть, когда зритель приходит на платформу и пробует новый функционал.
Например, мы хотим знать, как часто пользователь видит кнопки с предложением перейти к Следующему контенту, как часто он на них кликает или же как часто срабатывает Autoplay. При этом нам важно, с какого контента на какой происходит переход.
ТЗ уходит разработчикам, созданная фича — тестировщикам, а после возвращается к нам. И начинаются эксперименты.
Важное замечание. Чтобы фича работала, контент нужно размечать. Так что в эксперименте мы обращали внимание только на размеченные фильмы: в основном это были originals.
A/B-тестирование на примере онлайн-кинотеатра
Мы подготавливаем дашборды, по которым смотрим, как протекает эксперимент, и следим за всеми метриками. И отбираем две группы пользователей: одной фича будет доступна, другой — нет. Для последнего используется Firebase, софт, который рандомно бьёт людей на группы.
Сначала определяем название эксперимента и описание, куда обычно вставляем ссылку на confluence.
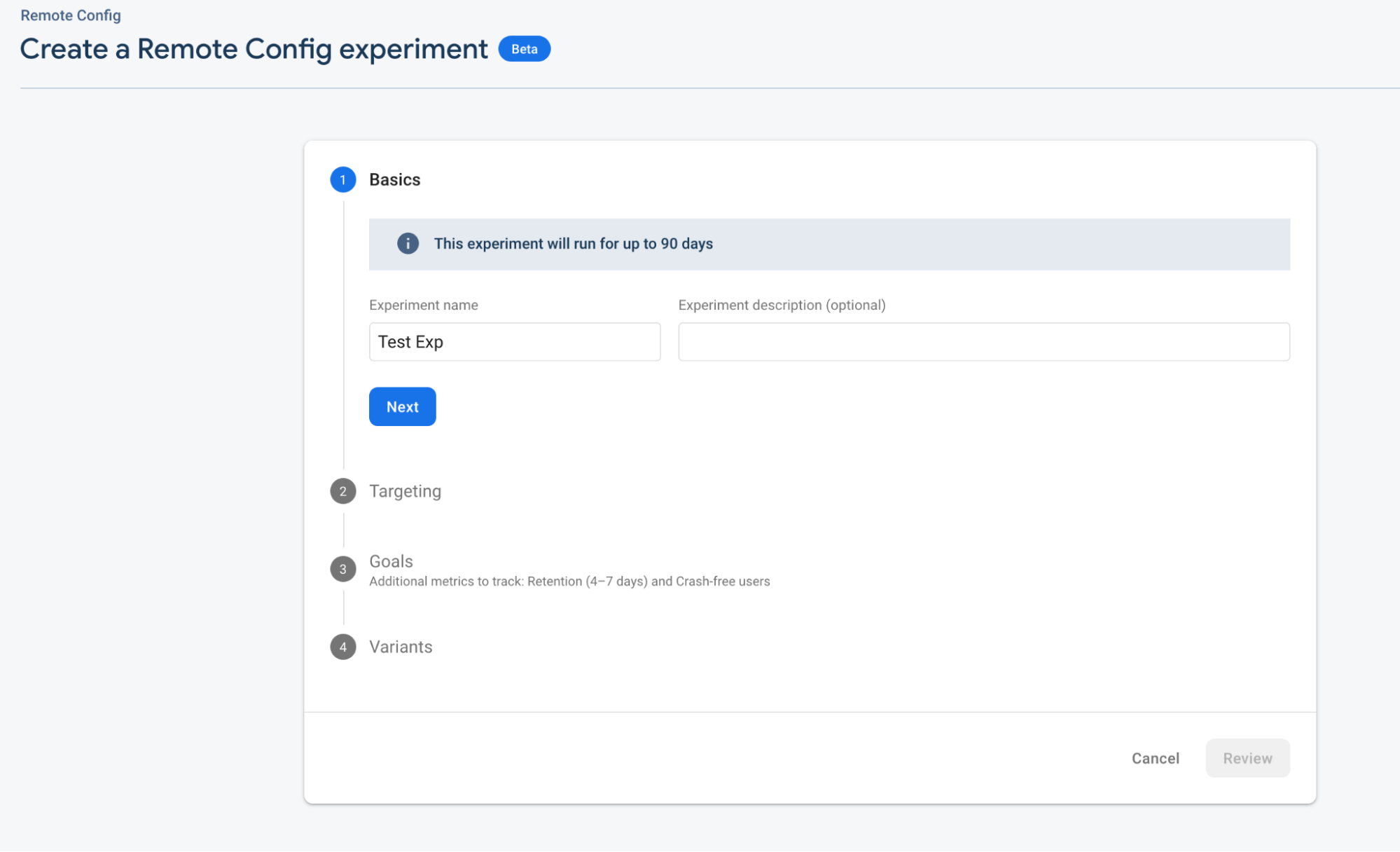
Далее выбираем платформу на, которой хотим провести эксперимент, и версию приложения. Мы запускаем тесты отдельно на каждой платформе, потому что результаты могут отличаться из-за интерфейса, аудитории и так далее.
Так же выбираем процент аудитории, которую будем задействовать.
У каждого эксперимента есть свой ключ, который помогает понять, к какой группе относится зритель — А или В (то есть будет ли ему доступна фича или нет). По этому ключу мы выкатываем новую версию приложения. Так работают A/B тесты.

Спустя определённое количество времени, мы смотрим метрики и делаем вывод, есть ли разница в поведении людей на платформе и насколько она заметна. В нашем случае тесты проводились месяц.
Расчёты
Чтобы определить, сколько нам держать эксперимент, мы выбираем MDE (minimal detectible effect) — минимальный эффект, который мы ожидаем увидеть благодаря нашим изменениям. Далее подставляем в стандартную формулу расчёта необходимого количества наблюдений:
def sample_size(var, mde, alpha, beta):
# Total samples needed N_test + N_control
n = 2 * 2*((z_alpha + z_beta)**2)*var/(mde**2)
return n
Где:
var — дисперсия метрики.
z_alpha — z значеие относящиеся к вероятности совершить ошибку первого рода (обычно 0.05 и для него z_value = 1.96).
z_beta — z значеие относящиеся к вероятности совершить ошибку второго рода (обычно 0.2 и для него z_value = 0.84).
mde — минимальная разница в метрике, которую хотим заметить.
В итоге получаем необходимое количество наблюдений в обеих группах. Понимая сколько примерно пользователей заходит в день, можем примерно прикинуть как долго нужно держать эксперимент.
Дальше считаем статистическую значимость получившихся изменений в метрике.
Т-тест
Мы запускаем стандартный Т-тест и смотрим на значение p_value — меньше ли оно определенной границы, (обычно берётся 0,05). Если да, фиксируем статистически значимое изменение в метрике. Если нет, то утверждать, что есть разница, нельзя.
Важно помнить, что если эксперимент не прокрасился это не значит, что вообще нет эффекта. Возможно он просто меньше выбранного нами MDE.
Отдельно стоит отметить как мы проверяем, что можем доверять Т-тесту — как и любому другому тесту для нашей метрики. Учитывая, что распределение TVTU крайне ненормальное.
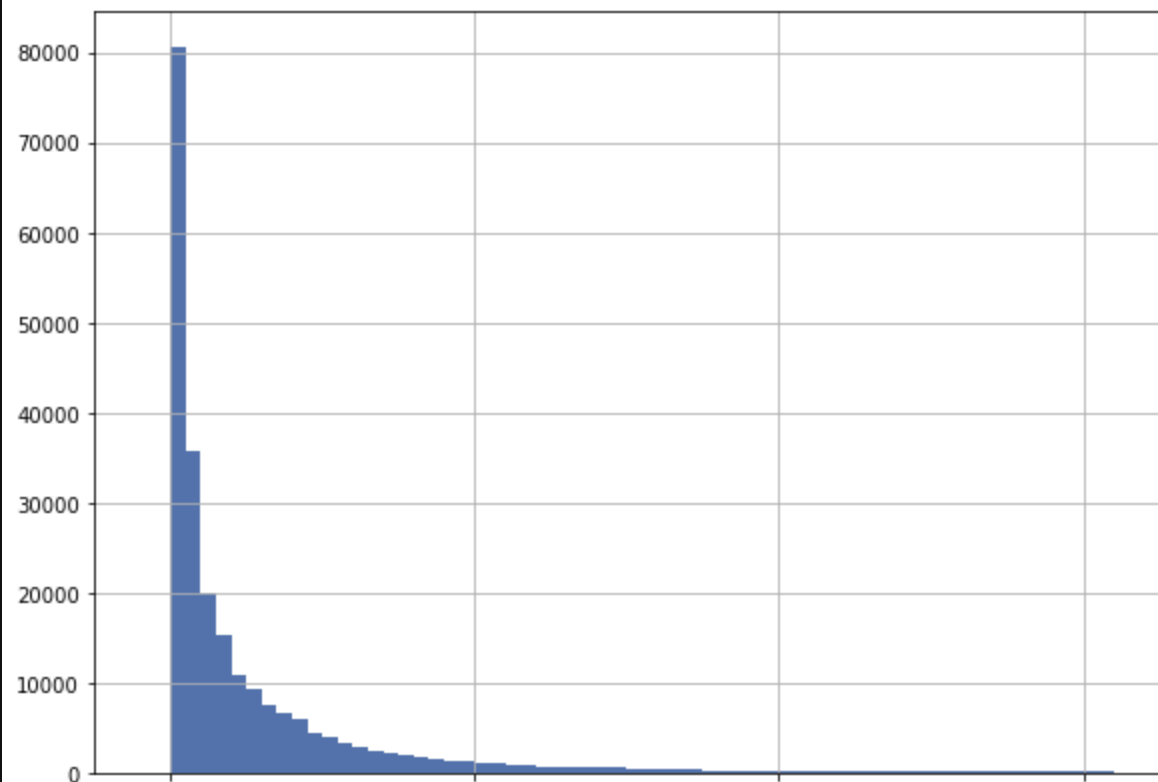
Для этого мы берём значение этой метрики у необходимой части пользователей (например только у пользователей тестируемой платформы) до эксперимента, когда нет разбиения на А и В группы. Далее рандомно бьём этих пользователей на A и В группы, проводим на них Т-тест и фиксируем значение p_value. Если оно меньше принятого нами (например.0,05), то фиксируем в отдельном счетчике, что эксперимент прокрасился.
Повторяем 10000 раз, каждый раз рандомно разбивая на А и В группы. Если число прокрасившихся экспериментов примерно 5%, то тесту (как и будущим экспериментам) можно доверять.
Если прокрашиваться будет меньше 5%, то это не так критично. Но это значит что метрика не такая чувствительная и мы реже будем фиксировать эффект, там где он реально есть.
Но если прокрашиваться будет значительно чаще установленных 5%, то и в реальных экспериментах мы будем получать ошибки чаще, нежели рассчитывали.
В качестве примера можем взять экспоненциальное распределение, которое похоже на TVTU:

Результаты
Согласно A/B тестированию на примере реализованного автозапуска, наша гипотеза сработала: пользователи вовлечены, больше половины из них досматривают фильмы, которые предложил Autoplay.
Общий TVT изменился не сильно, всего на 3,8%, потому что не все пользователи добрались до размеченного контента и увидели фичу. Но результаты среди групп, которые смотрели размещённый контент, отличные. Мы рассчитывали минимум на плюс 5%. Но TVTu сессий оказался выше на 21%. А TVT VOD — выше на 23%.
Самыми сильными были изменения на Android TV.

7К открытий14К показов

Рассказываем, какие базовые шаги нужно обязательно сделать, чтобы разрабатываемое ПО было безопасным.

Рассказываем, зачем вообще разработчику английский в ИТ и как некоторые мидлы умудряются работать без него.

Написали инструкцию, после которой вы перестанете бояться тестовых заданий и будете с уверенностью их проходить.
%%excerpt%% В июле нейросети успели написать научную статью в соавторстве с человеком, предсказать структуру 200 млн белков, а ещё дать футбольным фанатам надежду на крепкий сон.