AI ноябрь: дайджест релизов от Anthropic, Meta, Alibaba и российских команд
Обзор недавних релизов AI-моделей: от генераторов изображений и видео до думающих LLM и инструментов для сегментации

Ноябрь выдался плотным по релизам: крупные компании обновили флагманы, а open-source сообщество выложило несколько моделей, которые конкурируют с закрытыми решениями по качеству и при этом запускаются локально.
В подборке — обзор ИИ-инструментов для генерации изображений и видео, обновления языковых моделей с акцентом на код и агентов, специализированные инструменты для сегментации и снятия цензуры, а также свежие релизы от российских команд.
Больше новостей каждый день про искусственный интеллект, нейросети, машинное обучение — в НЕЙРОКАНАЛЕ.
Языковые модели и мультимодальные решения
В ноябре релизнулись сразу два гиганта: GPT 5.1 и Google Gemini 3, информацию найдете в отдельных наших статьях: Вышла ChatGPT-5.1: теперь можно подстроить тон и характер ИИ под себя и Google Gemini 3: полный обзор всех функций и как получить доступ в РФ.
Поехали дальше.
Claude Opus 4.5
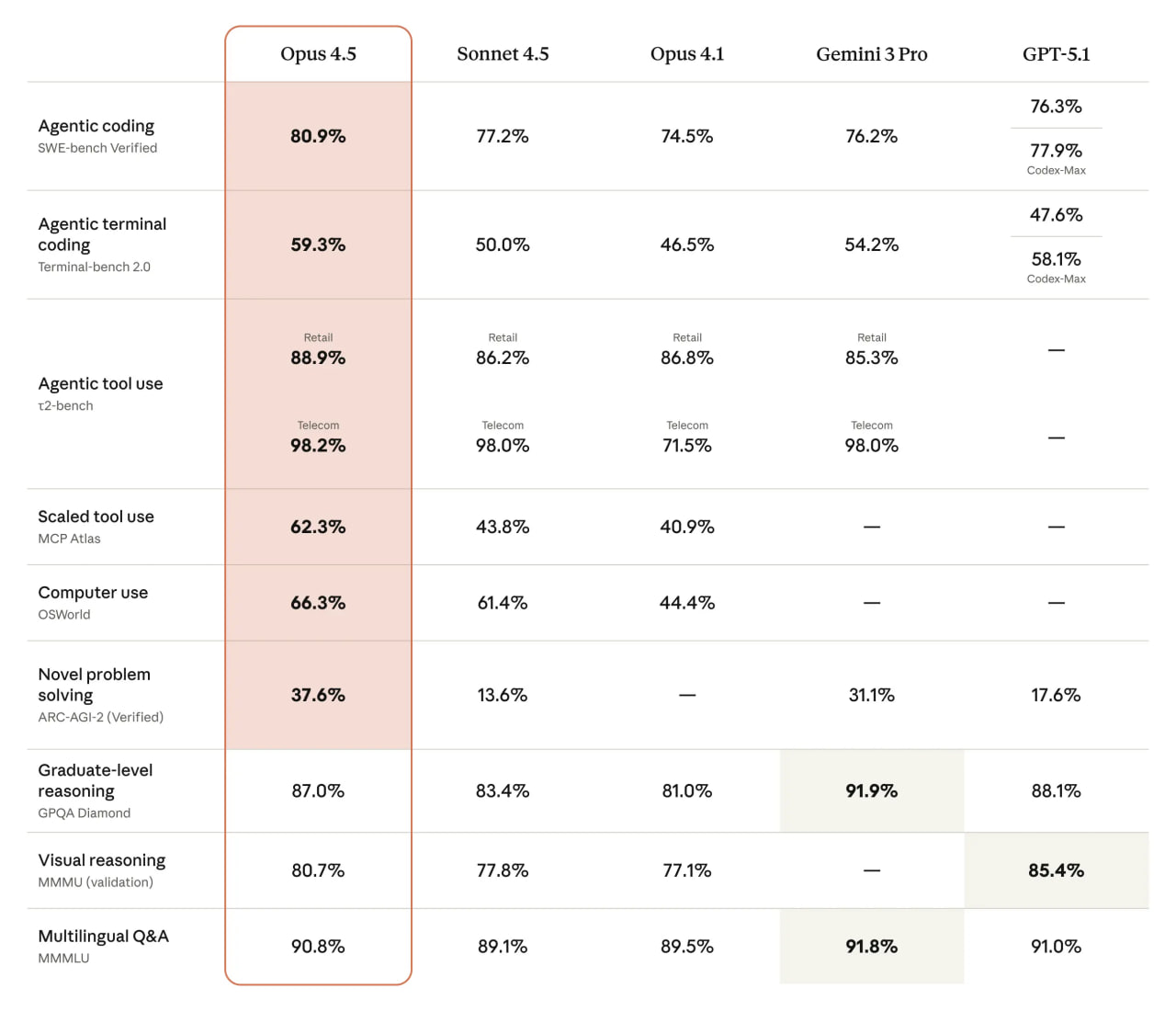
Anthropic выкатили новый флагман — Claude Opus 4.5. Это тот же топовый Opus, но с упором на реальные рабочие сценарии: сложная разработка, агенты, автоматизация офиса, таблички/презентации и длинные исследования. По их внутренним тестам Opus 4.5 стал ощутимо умнее в кодинге и сложных задачах, чем Sonnet 4.5 и прошлый Opus, при этом ест в разы меньше токенов за ту же задачу.
Что за модель и чем она интересна
Главный фокус — инженерка и агенты. В SWE-подобных задачах и «реальных» бенчмарках на терминале и офисную автоматизацию Opus 4.5 обходит не только Sonnet, но и конкурентов, при этом часто решает задачи за меньшее число шагов и с меньшим количеством попыток. В Anthropic даже прогоняли модель через свой хардкорный домашний экзамен для performance-инженеров: в отведённые 2 часа Opus 4.5 набрал балл выше любого кандидата-человека (с оговоркой, что это только про технику, а не про софт-скиллы).
Второй интересный апдейт — параметр effort в API: low, medium и high. Смысл примерно такой же как у ChatGPT, тут мы примерно уже привыкли к подобным параметрам.
В Claude Code улучшили планирование: модель сначала уточняет требования, собирает plan.md, а потом уже исполняет план; добавили поддержку в десктопном приложении, чтобы гонять несколько сессий (агентов) параллельно — один чинит баги, другой рыскает по GitHub, третий обновляет доку. В пользовательских продуктах: длинные диалоги больше не упираются в стену контекста, Claude сам компактно сворачивает историю, есть Claude для Chrome и расширенный доступ к Claude для Excel, где Opus 4.5 показывал +20% к точности и +15% к эффективности на внутренних финансовых задачах.
Где и как установить
Модель уже доступна как claude-opus-4-5-20251101 по цене $5/$25 за миллион токенов, и Anthropic явно позиционирует её как актуальную замену для всех задач.
В Cursor новая модель доступна бесплатно по сниженной цене первые две недели.
Kimi K2 Thinking
Kimi K2 Thinking — новая открытая думающая LLM от китайской Moonshot AI.
Что за модель и чем она интересна
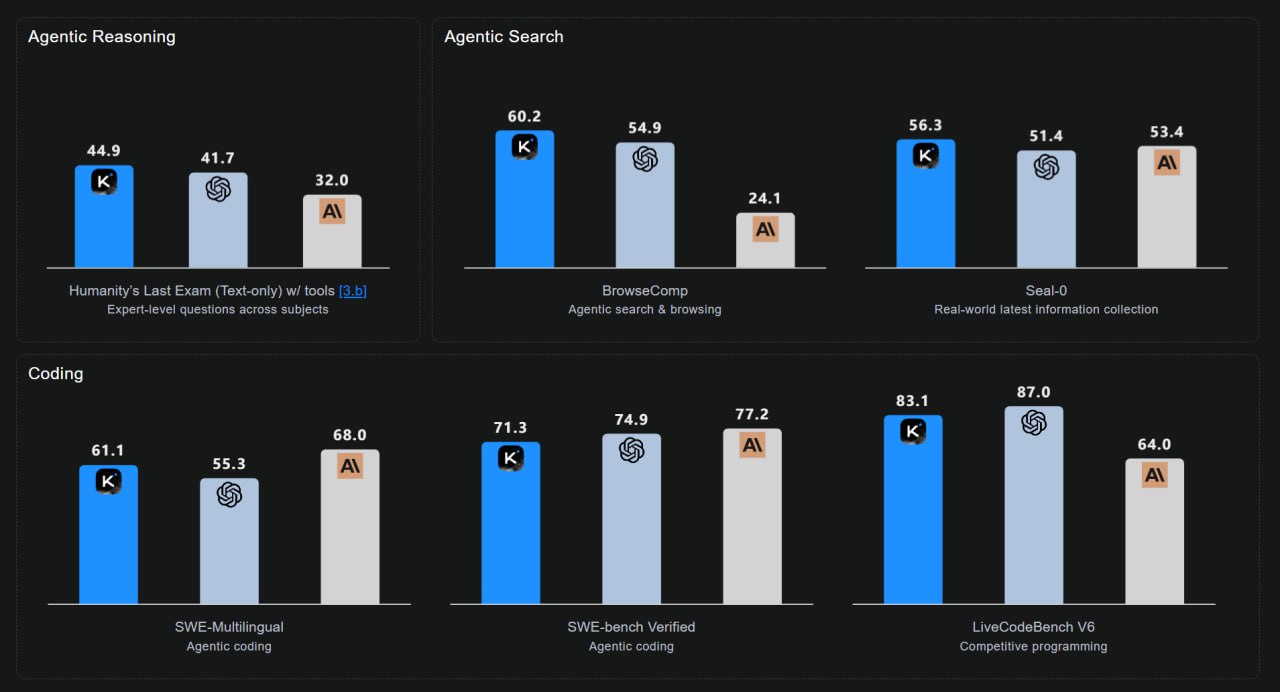
Под капотом MoE с 1 трлн параметров и 32B активных, 256к контекст и нативный INT4 для скорости и экономии памяти.
Весов выложили примерно на 600 ГБ — они компактнее прежнего K2 как раз из-за INT4. Запуск локально требует 8х GPU уровня A100/H100 80–96 ГБ. Проще использовать через облако: есть официальный API на платформе Moonshot и доступ через OpenRouter.
Где и как потестить
Попробовать модель можно в веб-интерфейсе Kimi или через Hugging Face Space, если не хочется возиться с железом. По языкам акцент на английский и китайский, но модель хорошо себя показывает на мульти-язычных бенчмарках вроде SWE-Multilingual; явного отдельного заявления про русский в карточке нет, так что качество русского лучше проверять на своих задачах.
На Reddit модель хвалят за креативность: пишут, что «лучше Sonnet 4.5» и заметно дешевле, и вообще неожиданно сильно для недорогой открытой модели. Возможно, локальные LLM скоро догонят лидеров и крупным игрокам придётся резко снижать цены или выкатывать что-то на порядок сильнее.
P.S. Moonshot AI — это 月之暗面 (Yue Zhi Anmian, «тёмная сторона Луны»), основаны в марте 2023 года и быстро выстрелили благодаря чатботу Kimi и ставке на длинный контекст. Компания базируется в Пекине и часто упоминается среди «AI-тигров» Китая, конкурирующих на глобальном рынке.
Генерация изображений
FLUX.2-dev
FLUX.2-dev — новая флагманская модель от Black Forest Labs для генерации и редактирования картинок по тексту, с открытыми весами, но под некоммерческой лицензией. Это 32-миллиардный трансформер с современным качеством рендера, который умеет как обычный text-to-image, так и аккуратное редактирование по одной или нескольким референс-картинкам.
Что за модель и чем она интересна
FLUX.2-dev — это продвинутый Photoshop на стероидах: одна модель, которая и рисует с нуля, и меняет стиль, объект или персонажа по тексту без доп. обучения, опираясь сразу на несколько референсов. За счёт архитектуры rectified flow трансформера и длинного контекста по тексту и картинкам она хорошо держит композицию, цвета (вплоть до hex-кодов) и надписи, поэтому сейчас её и двигают как новый топ среди открытых генераторов.

Где и как потестить
Самый простой вариант — официальный Space на Hugging Face: там можно вводить текст, загружать картинки и сразу смотреть результат в браузере. Плюс модель уже подключили в облачные сервисы вроде Cloudflare Workers AI и сторонние хостинги, так что можно дёргать её по API без своего железа.
Как запустить локально и какое железо нужно
Для локального запуска есть официальный репозиторий и поддержка в Diffusers: можно тянуть оригинальные веса или квантованные варианты (4-бит, GGUF) для экономии видеопамяти. В реальности модель огромная (32B параметров), поэтому комфортный минимум — RTX 3090/4090 с 24 ГБ VRAM; с квантованием и оффлоадом её можно завести примерно на 16–18 ГБ, но будет ощутимо медленнее и с ограничениями по размеру картинок и батчам. Не забудьте, что лицензия FLUX [dev] не даёт права использовать открытые веса в продакшн-продуктах напрямую — для коммерции у них отдельный FLUX.2 Pro по API. Все дополнительные подробности на HF.
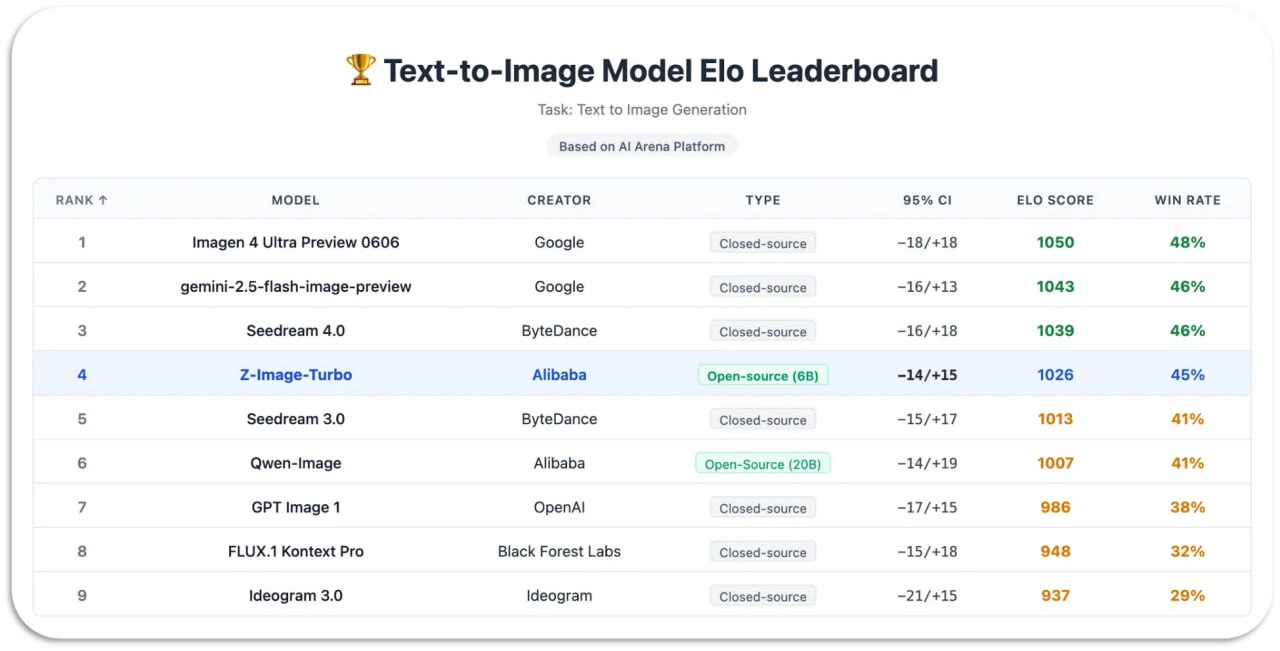
Z-Image-Turbo
Z-Image-Turbo — новая открытая текст-в-картинку модель от Alibaba, всего 6B параметров, но по качеству и пониманию промптов её уже сравнивают с куда более тяжёлыми монстрами. Это турбо-версия семейства Z-Image: дистиллированная, работает всего за 8 шагов диффузии и даёт очень быстрый отклик при сохранении фотореализма, аккуратного света/материалов и хорошей работы с текстом в кадре.
Что за модель и чем она примечательна
По технике там интересная смесь: single-stream Diffusion Transformer, который в одном трансформере обрабатывает и текст, и семантику, и изображение, плюс дистилляция через Decoupled-DMD и дообучение DMDR, чтобы в 8 шагов выжать максимум качества. В результате модель выдаёт картинку за ~секунду на H800 и нормально живёт на обычной 16 GB видеокарте, так что её реально крутить локально, а не только в облаке.
Где и как потестить
Потестить можно вообще без установки — есть официальные Spaces на Hugging Face, где Z-Image-Turbo крутится как веб-демка. Если хочется интегрировать в свой код, то поддержка уже влетела в diffusers: ставите свежий diffusers с GitHub, берёте ZImagePipeline.from_pretrained("Tongyi-MAI/Z-Image-Turbo", torch_dtype=torch.bfloat16) и дальше работаете как с обычным text-to-image пайплайном.
Плюс модель уже завезли в ComfyUI и на хостинги вроде Replicate, так что можно выбирать между локальным инференсом и API.
Генерация видео
HunyuanVideo-1.5
HunyuanVideo-1.5 — новая открытая модель от Tencent для генерации видео по тексту или картинке, причём она умещается всего в ~8,3 млрд параметров и при этом даёт качество уровня топовых закрытых сервисов. Модель понимает английский и китайский, умеет делать видео до 1080p.
Сочетает три вещи:
- Качество картинки
- Плавное движение
- Вменяемые требования к железу
В техотчётах и обзорах её уже сравнивают с Runway Gen-3 и другими лидерами — по человеческим оценкам Hunyuan часто не хуже, а иногда и лучше других открытых моделей, при этом работает быстрее за счёт оптимизаций внимания (SSTA) и двухступенчатой схемы «база + супер-резолвер».
Где и как потестить
Проще всего попробовать модель в демо на Hugging Face Space: есть готовый интерфейс для image-to-video и связанных чекпоинтов (480p, 720p и апскейлеры — смотрите в карточке на HF, там куча spaces поднято). Если хочется больше контроля, у модели есть нативная поддержка в ComfyUI — ставите нужные ноды, подгружаете чекпоинты HunyuanVideo-1.5 и собираете свой граф для text-to-video или image-to-video.
Как запустить локально и какое железо нужно
Локальный запуск делается через официальный репозиторий Tencent-Hunyuan/HunyuanVideo-1.5: нужен Python 3.10+, CUDA, PyTorch и видеокарта NVIDIA с поддержкой CUDA. При агрессивном оффлоаде и тюнинге пайплайна модель можно завести даже на ~14–16 ГБ видеопамяти (уровень RTX 4070/4070 Ti), но будет медленно; комфортнее всего ей на картах с 24+ ГБ (RTX 3090, 4090 и т.п.), а для длинных роликов 720p без offload по-прежнему полезны 48–80 ГБ или несколько GPU.
Специализированные решения
SAM 3
Выложили SAM 3 — это новая версия модели, которая по текстовому или визуальному запросу находит, выделяет и трекает нужные объекты на картинках и видео. Главный сдвиг: модель понимает абстрактные «концепты» вроде «жёлтый автобус» или «люди в касках» и сразу сегментирует все такие объекты, а не один, как в старых SAM.
Новое для этой версии:
- Promptable Concept Segmentation: пишешь фразу или даёшь пример-картинку, и SAM 3 находит и сегментирует все экземпляры этого класса, в том числе по кадрам видео.
- Объединены текстовые и визуальные подсказки: можно и написать «автомобиль», и прокликать мышкой спорные объекты в одном и том же интерфейсе.
- Открытый словарь: модель не привязана к фиксированному списку классов и работает с любыми осмысленными запросами, которые можно визуально приземлить.
Выводы простые: базовую задачу «найти и аккуратно вырезать любые объекты по запросу» по сути закрыли, и большинству из нас нет смысла писать свои сегментаторы с нуля. Задача смещается в сторону адаптации SAM 3 под свой домен, построения пайплайнов разметки и интеграции такого зрения в агенты и продукты, особенно там, где нужна тонкая работа с конкретными классами объектов.
Код в репозитории, веса на Hugging Face.
Heretic
Heretic — новая утилита, которая автоматически снимает цензуру (safety alignment) с трансформерных языковых моделей без дообучения и ручного тюнинга, поэтому её можно накинуть поверх уже готовой LLM. Автор позиционирует её как способ убрать цензурные фильтры у модели, не тратя время и деньги на новый RLHF или fine-tuning.
Что за модель и чем она интересна
Чтобы понять, что она делает, полезно вспомнить, как вообще появляется цензура в моделях: на этапе дообучения модель заставляют отказываться от части запросов, и она начинает отвечать шаблонно в духе «я не могу помочь с этим», даже если технически умеет решить задачу. Heretic как раз нацелен на то, чтобы убрать этот «слой воспитания» и вернуть исходное поведение модели, не трогая её базовые знания и архитектуру трансформера.
Разбор работы по шагам:
- Сначала загружается модель и подбирается тип данных (dtype) и размер батча, который стабильно работает на вашей GPU/CPU и не падает по памяти.
- Затем берётся два набора промптов: harmful (на них модель обычно отвечает отказами) и harmless (обычные запросы), и многократно прогоняются через модель, измеряя частоту отказов и поведение на нормальных запросах.
- После этого запускается направленная абляция (abliteration): TPE-оптимизатор перебирает параметры, которые определяют, какие направления/нейроны/головы ослабить, чтобы минимизировать одновременно и отказы, и KL-дивергенцию между новой и исходной моделью на безопасных промптах.
- В финале найденные правки применяются к весам, а потом предлагается сохранить результат, залить на Hugging Face или сразу открыть чат и посмотреть, как модель ведёт себя в диалоге.
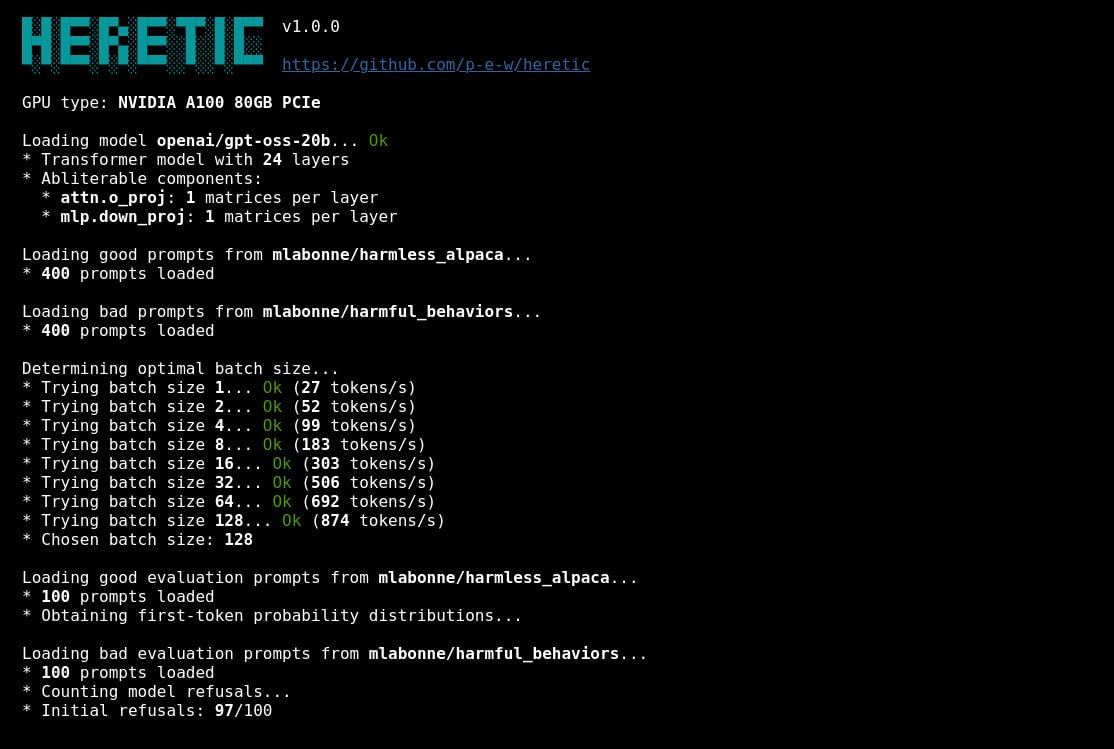
На примере google/gemma-3-12b-it: оригинальная модель отказывается в 97 из 100 вредных промптов, при этом KL-дивергенция по безопасным запросам равна 0 по определению, а вручную abliterated-версии снижают отказы до 3 из 100, но поднимают KL до 1.04 и 0.45. Автоматически полученная версия p-e-w/gemma-3-12b-it-heretic тоже даёт 3 отказа из 100, но при этом KL всего 0.16, то есть поведение на нормальных запросах уходит от исходной модели заметно меньше.
Heretic уже поддерживает большинство моделей, включая часть мультимодальных и несколько MoE-архитектур, но пока не работает с SSM/гибридными сетями, моделями с неоднородными слоями и некоторыми экзотическими вариантами attention. Код можно посмотреть в репозитории.
Open-dLLM
Open-dLLM — открытый «всё-в-одном» проект по диффузионным LLM: здесь есть и сырые данные, и обучение, и чекпойнты, и оценка, и инференс, а не только скрипты вывода и веса. В отличие от проектов вроде LLaDA и Dream, которые ограничивались инференсом и весами, Open-dLLM раскрывает весь стек и делает результаты воспроизводимыми.
Авторы прямо позиционируют проект как «самый открытый» релиз dLLM на сегодня. Внутри также есть отдельный вариант для генерации кода — Open-dCoder — чтобы можно было сразу потрогать dLLM на практической задаче программирования.
Что за модель и чем она интересна
Полноценный конвейер предобучения на открытых данных, скрипты вывода, наборы для оценки (HumanEval, MBPP и задачи на вставку кода), опубликованные веса и контрольные точки на Hugging Face и прозрачные конфиги для воспроизводимости результатов. Сам open-dcoder-0.5B уже лежит на Hugging Face и готов к использованию как компактная диффузионная модель для кода.
По цифрам, компактный Open-dCoder 0.5B даёт Pass@1/Pass@10 на HumanEval 20.8/38.4 и на MBPP 16.7/38.4, что для полумиллиардной модели выглядит неплохо рядом с более крупными диффузионными собратьями на задачах автодополнения кода.
Где и как потестить
Поставьте зависимости и запустите пример sample.py — этого достаточно, чтобы увидеть, как работает диффузионная модель на тексте и коде.
Российские разработки
GigaTTS
GigaChat выпустил модель для синтеза речи GigaTTS. Она звучит почти как реальный человек. И нравится слушателям в 2-4 раза чаще, чем старая версия. Под капотом — GigaChat 3b, токенизатор, адаптер к LLM и 30 тысяч часов данных.
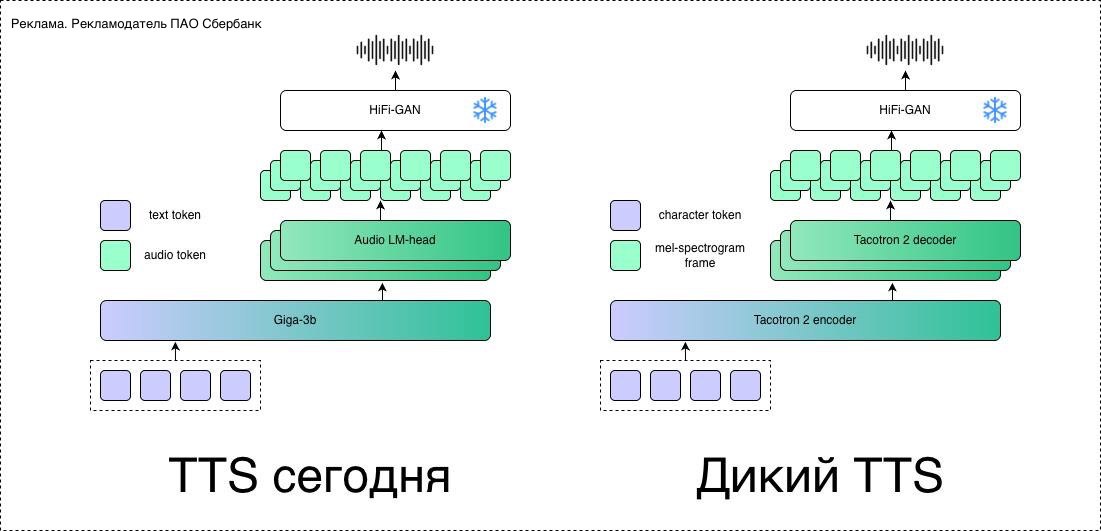
GigaTTS использует уникальные голоса телефонных операторов и инструктивный синтез разных эмоций. Она умеет клонировать голоса, а также озвучивать тексты любой длины в multi-turn режиме.
Больше новостей от команды разработки — в канале @gigadev_channel.
Kandinsky 5.0
Kandinsky 5.0 — новая линейка визуальных моделей в open source.
Сбер опубликовал в открытом доступе всю линейку Kandinsky 5.0: Video Pro, Video Lite, Image Lite и токенизаторы K-VAE 1.0. Полный open source: код, веса, лицензия MIT.
Video Pro (Text-to-Video / Image-to-Video)
Флагман, генерирующий HD-видео до 10 секунд с гибким управлением движением камеры. Обучалась на 520 млн изображений и 250 млн видео, а на финальном этапе, доучивалась на датасете сверх-качественных видеороликов, тщательно отобранных профессиональными художниками и дизайнерами.
Нативно понимает русские и английские промпты, генерирует надписи на латинице и кириллице. Лучшая открытая модель в мире, превосходит Wan 2.2-A14B в Text-to-Video [SBS 59:41] и Image-to-Video [SBS 53:47], а также достигает паритета с Veo 3 по визуальному качеству и динамике [SBS 54:46].
Video Lite (Text-to-Video / Image-to-Video)
Компактные модели генерации видео, оптимизированные для запуска на GPU от 12 ГБ VRAM. Обучалась на 520 млн изображений и 120 млн видео, хорошая консистентность и качество динамики. Лучшая среди небольших и быстрых моделей, значительно превосходит в 7 раз большую по количеству параметров Wan 2.1-14B как в Text-to-Video [SBS 67:33], так и Image-to-Video [SBS 64:36].
Image Lite (Text-to-Image / Image Editing)
HD-генерация и редактирование изображений. Претрейн Text-to-Image модели был сделан на 520 млн изображений, включая датасет русского культурного кода ~1 млн изображений. Image Editing был дополнительно дообучен на 150 млн пар. Для достижения финального качества был проведено SFT дообучение на 150 тыс изображений, а также на 20 тыс. пар — для Editing.
Нативно понимает русские и английские промпты, генерирует надписи на латинице и кириллице. Значительно превосходит FLUX.1 [dev] по Text-to-Image [SBS 63:37] и находится в паритете по качеству с FLUX.1 Kontext [dev] по Image Editing [SBS 54:46].
K-VAE 1.0 (2D / 3D)
Вариационные автоэнкодеры для диффузионных моделей, сжимающие входные данные в формате 8x8 (изображения) и 4x8x8 (видео). Сравнение на открытых датасетах показывает, что модели более качественно восстанавливают исходный сигнал (+0.5dB PSNR), чем лучшие open-source альтернативы (Flux, Wan, Hunyaun), обладающие той же степенью сжатия.
Где и как потестить
Все модели линейки доступны на GitHub, Gitverse и HuggingFace. Читайте подробнее в техническом репорте.
Вместо заключения
Ноябрь показал, что разрыв между закрытыми и открытыми моделями продолжает сокращаться: появились конкуренты флагманам в генерации изображений и видео, а китайские команды выложили свои мощные LLM.
Российские разработки тоже двигаются: Kandinsky 5.0 получил сравнения с мировыми лидерами, а GigaTTS вышел на новый уровень натуральности речи.
Приятно видеть, что появляется больше вариантов для локального запуска и интеграции в продукты. Не забывайте следить за обновлениями API у крупных игроков вроде Anthropic, OpenAI и Google.









![Обложка: Как стать аналитиком данных за 6–12 месяцев [гайд]](https://media.tproger.ru/uploads/2025/12/1c7c4818-f579-4330-b4fe-56704d1972e0.jpg)


