


СУБД 2026: что выбирают российские компании

57 открытий325 показов

Российский рынок СУБД за последние годы изменился. Компании ищут решения, которые закрывают требования по импортозамещению, сертификации и работе с персональными данными, но при этом не уступают по функциональности привычным системам.
В этой подборке — четыре системы управления базами данных, которые закрывают разные сценарии: от транзакционных нагрузок до аналитики петабайтных хранилищ. Каждый продукт решает свой класс задач — одни оптимизированы под OLTP с частыми операциями чтения-записи, другие под OLAP с обработкой миллиардов строк, третьи дают задержки в миллисекунды для real-time систем.
1. РЕД База Данных: реляционная СУБД с режимом встраивания
Тип: реляционная СУБД общего назначения, OLTP
РЕД База Данных — реляционная OLTP-система общего назначения, которая включена в реестр российского ПО и имеет сертификат ФСТЭК России по 4 классу защиты. Команда разрабатывает продукт параллельно с Firebird уже 20 лет: общие ошибки исправляются в обеих ветках, доработки переносятся между проектами.
Где используют
Один из публичных кейсов — АИС ФССП России. СУБД работает с терабайтными базами данных, скорость обработки запросов сопоставима с другими реляционными OLTP-системами на рынке.

Два режима работы
РЕД База Данных может работать как классическая серверная СУБД или в режиме встраивания — без выделенного сервера, как SQLite. В встраиваемом режиме функциональность сохраняется полностью, кроме сетевого доступа. Это позволяет использовать одну СУБД и для серверных задач, и для локальных приложений.
Поддерживаются Windows, Linux (включая РЕД ОС, Альт Линукс, AstraLinux, ROSA) и Android. Архитектуры: x86_64 (Intel, AMD), Эльбрус (e2k), Байкал (aarch64), ARM.
Отказоустойчивость и репликация
Есть три режима репликации: синхронная, асинхронная и адаптивная. Адаптивная репликация переключается в асинхронный режим при проблемах со связью и возвращается обратно после восстановления. Отказоустойчивый кластер включён в текущую версию, шардинг планируется в версии 6.
Механизм записи страниц БД позволяет СУБД восстанавливаться сразу после сбоя без длительной фазы recovery, которая есть в системах с журналом упреждающей записи. Поддерживаются логический бэкап, файловый бэкап консистентной БД и инкрементальные бэкапы.
Сборка мусора и метаданные
Сборка мусора работает автоматически в разных режимах и не требует блокировки таблицы. Механизм сборки промежуточных версий снимает проблему версионного сервера и длительных транзакций. Метаданные можно обновлять на лету, без блокировки таблицы для запросов.
Многопоточная архитектура позволяет запускать множество транзакций в рамках одного подключения и поддерживать несколько подключений одновременно.
Интеграция и инструменты
В экосистеме РЕД Базы Данных есть два основных инструмента:
РБД Эксперт для разработки и администрирования баз данных
РБД Монитор для мониторинга.
СУБД имеет сертификаты совместимости с 80+ продуктами: медицинские информационные системы, банковское ПО, СКАДА-системы, системы резервного копирования. Полная совместимость с другими продуктами РЕД СОФТ (РЕД Виртуализация, РЕД ОС, РЕД Платформа и другие) позволяет собирать инфраструктуру на базе одного вендора.
Поддерживаются популярные языки и фреймворки: Java (Spring, Hibernate, Liquibase, FlyWay), NodeJS, Python (Django, SQLAlchemy), Ruby (Active Record), GO (GORM), C, C++, .NET, Rust, QT, ODBC, OLE DB, PHP, Erlang.
Доступность и поддержка
Продукт представлен в облаках VK Cloud и Яндекс Облако. Для VK Cloud есть бесплатная версия для тестирования. Покупка через интеграторов, лицензирование поядерное — минимум 2 ядра на установку. Для разработчиков прикладного ПО предусмотрена отдельная лицензия без ограничений.
Техническая поддержка работает на двух уровнях: стандартном и расширенном. Для пользователей доступны техническая документация и база знаний, статьи на Хабре, каналы на RuTube и Дзен, чат в Telegram с разработчиками. Ежегодно проводится конференция, посвящённая Firebird, где можно пообщаться с командой напрямую.
Что будет в версии 6
Шестая версия запланирована на 2026 год с фокусом на производительность и новые функции. В релиз войдут: геометрические типы данных, гетерогенные запросы, ROW-тип данных, партиционирование, катастрофоустойчивый кластер, восстановление на точку во времени, создание и удаление индексов без блокировки, улучшенные JSON-функции, новые методы доступа (HASH/MERGE OUTER JOIN, HASH GROUP BY), общий кеш метаданных и поддержка TRUNCATE.
2. Postgres Pro: форк PostgreSQL с российской разработкой и встроенным кластером
Тип: реляционная СУБД общего назначения на базе PostgreSQL
Postgres Pro — российская разработка на основе PostgreSQL. Компания объединяет 70% российских контрибьюторов PostgreSQL, входит в ТОП-5 мировых разработчиков этой СУБД. Продукт включён в реестр российского ПО, сертифицирован ФСТЭК России. На рынке 10 лет, в команде более 400 специалистов.
Где используют
- Один из масштабных кейсов — миграция ГИС ГМП Федерального казначейства на Postgres Pro Shardman. Система обрабатывает платежи национального масштаба и работает в распределённой архитектуре.
- «Авито» перенесли базы данных 1С с Microsoft SQL Server на Postgres Pro Enterprise. Объём данных — более 10 ТБ. Платформа обрабатывает 220 млн объявлений ежемесячно, обслуживает 62 млн пользователей и до 10 сделок в секунду.
- Газпромбанк мигрировал ключевую АБС с Oracle на Postgres Pro Enterprise. Проект потребовал перестройки архитектуры и детального тестирования под пиковыми нагрузками.
- «Росатом» развернул автоматизированную систему управления финансами и перенёс СЭД на Postgres Pro Enterprise Certified. Решение обслуживает более 250 предприятий атомной отрасли.
Редакции и специализация
Линейка включает пять основных редакций:
- Postgres Pro Enterprise — флагманская версия для высоконагруженных систем с более чем 100 дополнительными функциями относительно PostgreSQL. Поддерживает до 10 000 одновременно работающих пользователей.
- Postgres Pro Enterprise для 1С — оптимизирована под платформу 1С. Ускоряет ключевые операции, закрыть месяц можно до 10 раз быстрее по сравнению с базовыми решениями.
- Postgres Pro Enterprise Certified — сертифицированная ФСТЭК версия Enterprise со встроенными средствами защиты.
- Postgres Pro Standard — улучшенная версия PostgreSQL с повышенной производительностью и полнотекстовым поиском.
- Postgres Pro Certified — сертифицированная ФСТЭК версия Standard.

BiHA: встроенный отказоустойчивый кластер
BiHA (Built-in High Availability) — встроенный отказоустойчивый кластер, работает «из коробки» без внешних компонентов. При сбое основного узла система автоматически переключается на реплику. Механизм не требует отдельной настройки Pacemaker, Corosync или других решений для управления кластером — всё интегрировано в ядро СУБД.
Масштабирование: Shardman и Citus
Для горизонтального масштабирования доступны две технологии:
Postgres Pro Shardman — распределённая СУБД с автоматическим управлением шардами. Данные распределяются по узлам, система сама отслеживает топологию и балансирует нагрузку. Использовался в проекте миграции ГИС ГМП.
Citus — расширение для распределённых запросов и параллельной обработки. Подходит для аналитических задач и работы с большими объёмами данных.
Proxima и управление жизненным циклом данных
Proxima — встроенный пулер соединений и прокси-сервер. Оптимизирует управление подключениями, снижает накладные расходы на создание новых сессий.
ILM (Information Lifecycle Management) — управление жизненным циклом данных. Позволяет автоматически перемещать старые или редко используемые данные на более дешёвые носители без остановки системы.
Миграция с Oracle и других СУБД
Postgres Pro включает инструменты для упрощённой миграции с Oracle: поддержка PL/SQL-совместимого языка, эмуляция пакетов Oracle, совместимость типов данных.
Экосистема инструментов
Postgres Pro Enterprise Manager (PPEM) — графическая платформа для управления кластерами, мониторинга производительности и резервного копирования. Интерфейс позволяет управлять несколькими инстансами одновременно.
Postgres Pro Backup Enterprise — инструмент для инкрементального резервного копирования. Поддерживает восстановление на точку во времени (PITR) и сжатие данных.
Техническая поддержка и документация
Техническая поддержка работает 24/7, два уровня: базовая и расширенная. Расширенная включает решение задач, требующих изменений в ядре СУБД. Доступен портал техподдержки с личным кабинетом и базой знаний.
Документация включает книги, курсы, демобазу для обучения, глоссарий и HOW-TO видео. Для студентов и вузов есть отдельные программы.
Доступность
Продукты доступны через интеграторов и дистрибьюторов. Лицензирование поядерное. Для разработчиков прикладного ПО предусмотрены отдельные условия. Можно протестировать через личный кабинет на сайте.
Компания проводит регулярные мероприятия: PGPro TechDay, PGMeetup по шардированию и другим техническим темам.
3. Tarantool DB: in-memory СУБД для real-time систем
Тип: NoSQL in-memory СУБД, key-value/документная
Tarantool DB — российская in-memory СУБД с открытым кодом, разработка VK. Включена в реестр отечественного ПО (№ 23005 от 28.06.2024), сертифицирована ФСТЭК России. Основной фокус — системы реального времени с требованиями к задержке в единицы миллисекунд.
Где используют
- Tarantool применяют как кэш-слой для автоматизированных банковских систем и дисковых СУБД. Вместо полной замены core-систем создаётся быстрый промежуточный слой, который снижает нагрузку на основное хранилище.
- В банковской архитектуре СУБД работает как оперативное хранилище между клиентскими приложениями и базовой АБС. Это позволяет обрабатывать запросы без обращения к медленным дисковым системам.
- В телекоме и ритейле используют для организации «золотой записи» клиента, цифрового профиля, единой авторизации и real-time биллинга. В e-commerce — для обработки потоков событий и маркетинга в реальном времени.
Drop-in замена Redis
В поставке есть механизм замены Redis с минимальными изменениями кода. Поддерживаются 60+ команд Redis, типы данных Redis, Redis ACL для управления доступом и настройки, совместимые с Redis.
Есть логирование событий и шифрование TLS. Переход с Redis на Tarantool не требует переписывать клиентское приложение — достаточно изменить конфигурацию подключения.
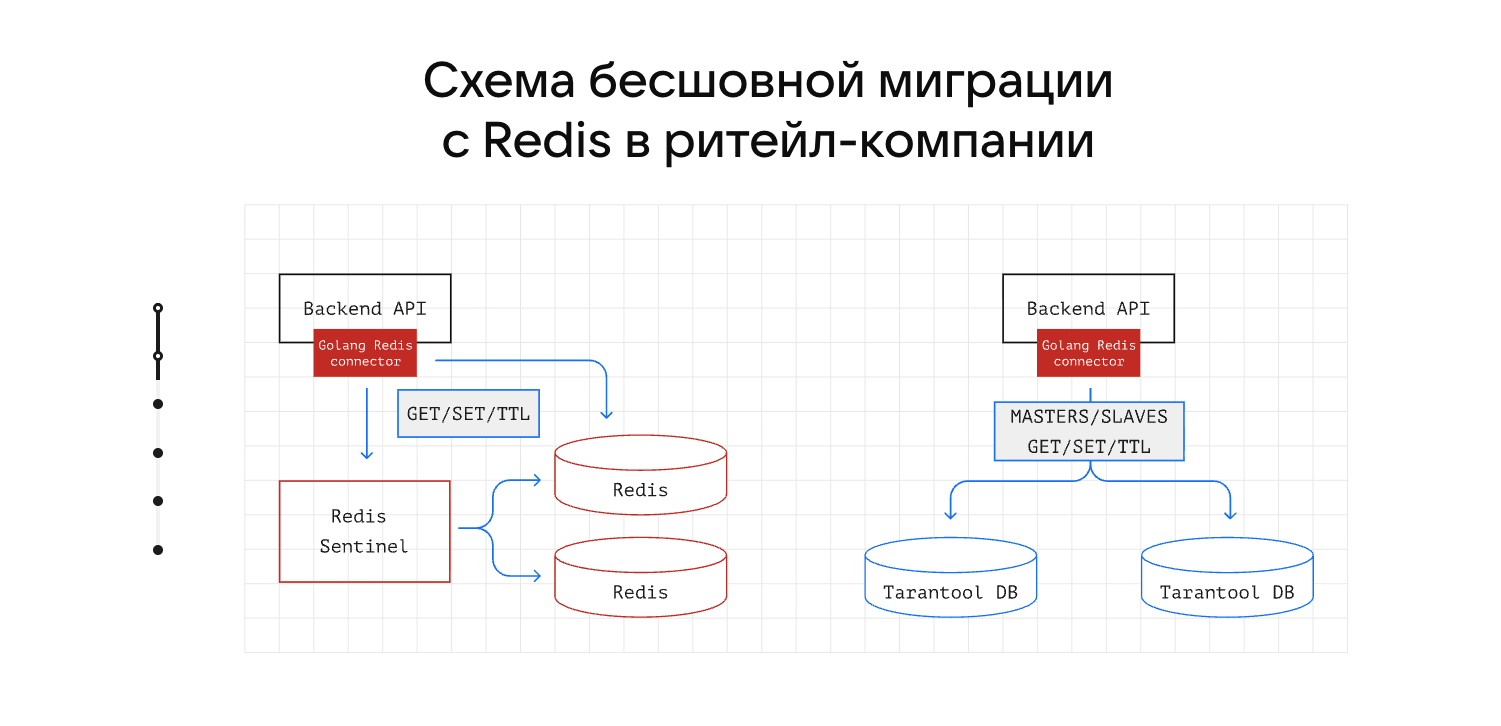
Схемы данных и работа с памятью
Tarantool поддерживает несколько схем: key-value, таблицы и документы. Данные хранятся в оперативной памяти с возможностью сжатия для экономии ресурсов.
Для сохранности предусмотрена упреждающая журнализация (WAL) и создание снимков состояния БД. При сбое система восстанавливается быстро благодаря механизму быстрого восстановления.
CRUD-операции работают с объектами в кластерном хранилище. Поддерживаются вторичные индексы и управление временем жизни данных (TTL). Справочники можно хранить прямо в кластере.
Репликация и шардирование
Доступна синхронная и асинхронная репликация. Шардирование (сегментирование данных) встроено в платформу — не нужны внешние инструменты для горизонтального масштабирования.
Failover для отказоустойчивости работает автоматически: при падении узла система переключается на реплику. Управление кластером реализовано через собственную технологию Tarantool.
API и интеграция
Для работы с данными из бизнес-приложений есть коннекторы на Java и Go. API поддерживает чтение и запись данных в кластерное хранилище.
Метрики мониторинга экспортируются в Prometheus и Grafana. Развёртывание возможно в Kubernetes. Поддерживаются российские ОС: Astra Linux и РЕД ОС.
Экосистема продуктов
Помимо Tarantool DB, в экосистеме есть:
- Tarantool Enterprise Edition — коммерческая версия с расширенной поддержкой
- Tarantool CDC — Change Data Capture для синхронизации с другими системами
- Tarantool Graph DB — графовая база данных
- Tarantool Queue Enterprise — система очередей
- Tarantool Column Store — колоночное хранилище для аналитики
- Tarantool Clusters Federation — управление федерацией кластеров
- Tarantool Kubernetes Operator — оператор для Kubernetes
- Tarantool Cloud Edition — облачная версия
Горизонтальное масштабирование
Переход с вертикального масштабирования (более мощное железо) на горизонтальное (больше узлов) снижает расходы на оборудование. Создание копий данных с быстрым доступом распределяет нагрузку между серверами.
Встроенные инструменты шардирования автоматически распределяют данные по узлам. Не нужно вручную настраивать балансировку или разбивать таблицы.
Документация и поддержка
Техническая документация доступна на русском языке. Есть руководства по началу работы для Enterprise Edition и Community Edition, документация по модулям и Data Grid.
Сообщество общается в Telegram, VK, GitHub и Stack Overflow. Есть блог с техническими статьями.
4. ClickHouse: колоночная СУБД для аналитики
Тип: колоночная OLAP-СУБД для онлайн-аналитической обработки
ClickHouse — колоночная СУБД для аналитических задач, доступна как open-source проект и облачный сервис. Разработка началась в Яндексе, сейчас развивается как независимый проект. Основной фокус — обработка больших объёмов данных в режиме реального времени с возвратом результата за время менее секунды.
OLAP vs OLTP
ClickHouse решает задачи онлайн-аналитической обработки (OLAP): SQL-запросы со сложными вычислениями, агрегациями и арифметикой по миллиардам и триллионам строк. Аналитические запросы обрабатывают большие объёмы данных, в отличие от транзакционных (OLTP), которые читают и записывают несколько строк за запрос.
Колоночное хранение
Таблицы хранятся как набор столбцов: значения каждого столбца располагаются последовательно. Это затрудняет восстановление отдельных строк (между значениями строк появляются разрывы), но операции над столбцами — фильтрация, агрегация — выполняются значительно быстрее, чем в построчной базе.
При выполнении запроса с диска читаются только те столбцы, которые требуются. Если в таблице 100 столбцов, а запрос обращается к пяти, остальные 95 не загружаются в память. В построчной СУБД даже при обращении к одному столбцу приходится загружать данные всей строки, так как блоки на диске содержат значения всех столбцов вместе.
Производительность
На примере реальных данных веб-аналитики: запрос по 100 миллионам строк с фильтрацией и группировкой выполняется за 92 миллисекунды. Пропускная способность — около 1 миллиарда строк в секунду или около 7 ГБ данных в секунду.
Приблизительные вычисления
ClickHouse может жертвовать точностью ради производительности. Некоторые агрегатные функции вычисляют приблизительное количество различных значений, медиану и квантили. Запросы можно выполнять по выборке данных для быстрого получения приблизительного результата.
Агрегацию можно выполнять с ограниченным числом ключей вместо всех. При смещённом распределении ключей это даёт достаточно точный результат при меньших затратах ресурсов по сравнению с точным расчётом.
SQL и стандарт ANSI
ClickHouse поддерживает декларативный язык запросов на основе SQL, который во многих случаях соответствует стандарту ANSI SQL. Поддерживаются GROUP BY, ORDER BY, подзапросы в FROM, JOIN, оператор IN, оконные функции и скалярные подзапросы.
Синтаксис знаком разработчикам, работавшим с реляционными СУБД, но внутренняя логика выполнения запросов отличается из-за колоночного хранения.
Репликация и целостность данных
Используется асинхронная мультимастерная схема репликации для избыточного хранения данных на нескольких узлах. После записи на любую доступную реплику остальные реплики в фоновом режиме получают копию. Система поддерживает одинаковое состояние данных на разных репликах.
Восстановление после большинства сбоев выполняется автоматически или полуавтоматически в сложных случаях. Ролевое управление доступом (RBAC) реализовано через SQL-запросы, аналогично стандарту ANSI SQL и популярным реляционным СУБД.
Адаптивные алгоритмы соединения
ClickHouse адаптивно выбирает алгоритм соединения таблиц: начинает с быстрых хеш-соединений и переходит к merge-соединениям, если в запросе участвует более одной крупной таблицы. Система сама определяет оптимальную стратегию на основе характеристик данных.
Сценарии использования
ClickHouse применяют для веб-аналитики, логирования событий, мониторинга инфраструктуры, анализа временных рядов, обработки данных с датчиков IoT. Везде, где нужно агрегировать большие объёмы данных с низкой задержкой.
Типичный паттерн — сбор событий в реальном времени (клики, просмотры, логи) и построение дашбордов с обновлением каждые несколько секунд. ClickHouse обрабатывает миллиарды записей и возвращает результаты агрегации быстрее, чем традиционные хранилища данных.
Open-source и облако
Проект доступен на GitHub под лицензией Apache 2.0. Есть коммерческое облачное предложение ClickHouse Cloud с управляемой инфраструктурой. Можно развернуть на собственных серверах или использовать облачный вариант без управления кластером.
Выбор СУБД зависит от типа задач и архитектуры проекта. Для транзакционных систем с частыми операциями чтения-записи подходят РЕД База Данных и Postgres Pro — обе работают по модели OLTP, поддерживают ACID и совместимы с существующими инструментами разработки. Tarantool закрывает сценарии, где критична задержка в миллисекунды: кэширование, сессии, real-time биллинг. ClickHouse и Arenadata DB решают аналитические задачи, но по-разному: первый оптимизирован под скорость отдельных запросов с колоночным хранением, второй — под корпоративные хранилища данных с MPP-архитектурой и полной совместимостью с PostgreSQL.

57 открытий325 показов

Apple добавила в iOS 18.1 функцию автоматической перезагрузки iPhone раз в 4 дня для повышения безопасности данных. Нововведение усложняет работу полиции по вскрытию устройств

Electronic Arts объявила об отмене разработки The Sims 5, сфокусировавшись на продолжении развития The Sims 4. Планируется внедрение многопользовательского режима и запуск программы Creator Kits для продажи пользовательского контента

Стартует турнир за звание лучшего языка программирования в 2023 году среди читателей Tproger. Кто же победит в этом году?

Агрессия, ложь, ЧСВ и равнодушие — семь ошибок кандидатов, из-за которых тимлиды сразу закрывают интервью. Как не испортить впечатление и пройти собеседование.