


Google Gemini 3: полный обзор всех функций и как получить доступ в РФ

Реальные возможности модели: как она работает с текстом, изображениями и кодом, что такое режим Deep Think, как получить доступ из РФ
9К открытий18К показов

Всем привет! Google только что выкатил Gemini 3, и я успел его потестировать. Поехали разбираться, что это за зверь и стоит ли заморачиваться.
18 ноября 2025 года Google официально представил Gemini 3 — мультимодальную модель, которую компания называет «самой умной» из всего, что они делали. Кстати, это первый раз, когда новую версию Gemini запустили одновременно в поиске Google и в приложении — раньше такого не было.
Но давайте без воды. За два года Gemini прошёл путь от простого чтения текстов и картинок до понимания контекста на уровне «чтения ситуации». А Gemini 3 Pro уже тестируют больше 650 миллионов человек в месяц, плюс 13 миллионов разработчиков активно юзают его в работе. Звучит внушительно, но что конкретно умеет модель?
Что такое Gemini 3 и почему о нём все говорят

Gemini 3 — это целое семейство нейросетей от Google DeepMind. Сейчас доступна версия Gemini 3 Pro, а скоро добавится режим Gemini 3 Deep Think для ещё более сложных задач.
Вот что бросается в глаза сразу: модель разработана на трансформерной архитектуре с разреженной смесью экспертов (Mixture-of-Experts). Это значит, что для разных задач активируются разные части сети — получается быстрее и эффективнее. Google обучал модель исключительно на своих чипах TPU, что тоже любопытно.
Лично я заметил, что Gemini 3 лучше понимает, что именно ты хочешь, даже если промпт не идеальный. Меньше приходится переформулировать — модель просто схватывает контекст. Это экономит время, особенно когда работаешь над несколькими проектами одновременно.
Gemini 3 Pro поддерживает окно контекста в 1 миллион токенов, что позволяет ему обрабатывать целые книги, длинные видео или огромные массивы кода за один раз. Для сравнения — это как если бы вы могли показать модели всю вашу переписку за год и попросить найти конкретную деталь.
Бенчмарки: как Gemini 3 обошёл конкурентов

Погнали по цифрам. Gemini 3 Pro набрал 1501 балл на LMArena — это выше, чем у Gemini 2.5 Pro (1451 балл), и он возглавил таблицу лидеров.
На тесте Humanity’s Last Exam, который считается одним из самых жёстких для ИИ, Gemini 3 Pro выдал 37,5% точности без использования инструментов. Для сравнения: GPT-5.1 набрал 26,5%, а предыдущий лидер Grok 4 остановился на 25,4%. Разница больше 12 процентных пунктов — это серьёзный отрыв.
По GPQA Diamond (научные знания уровня PhD) Gemini 3 показал 91,9%, обогнав GPT-5.1 (88,1%) и Claude Sonnet 4.5 (83,4%). А в математике на MathArena Apex модель достигла 23,4%, что стало новым рекордом среди фронтирных моделей.
В визуальном мышлении Gemini 3 просто разнёс конкурентов. На ARC-AGI-2 он набрал 31,1% — это в 6 раз выше, чем у Gemini 2.5 Pro (4,9%), и значительно превосходит Claude (13,6%) и GPT-5.1 (17,6%). На ScreenSpot-Pro, который тестирует понимание интерфейсов, результат 72,7% против 36,2% у Claude и жалких 3,5% у GPT-5.1.
По кодингу: на SWE-Bench Verified Gemini 3 получил 76,2%, почти сравнявшись с GPT-5.1 (76,3%), хотя Claude Sonnet 4.5 всё ещё чуть впереди с 77,2%. Зато на Terminal-Bench 2.0 для агентного кодинга Gemini 3 показал 54,2%, опередив Claude (42,8%) и GPT-5.1 (47,6%).
Я протестировал модель на задаче с анализом сложного технического документа — Gemini 3 справился за 2 минуты, Gemini 2.5 потратил больше 4 минут. Разница чувствуется, когда дедлайны поджимают.
Gemini 3 Deep Think — режим для самых сложных задач
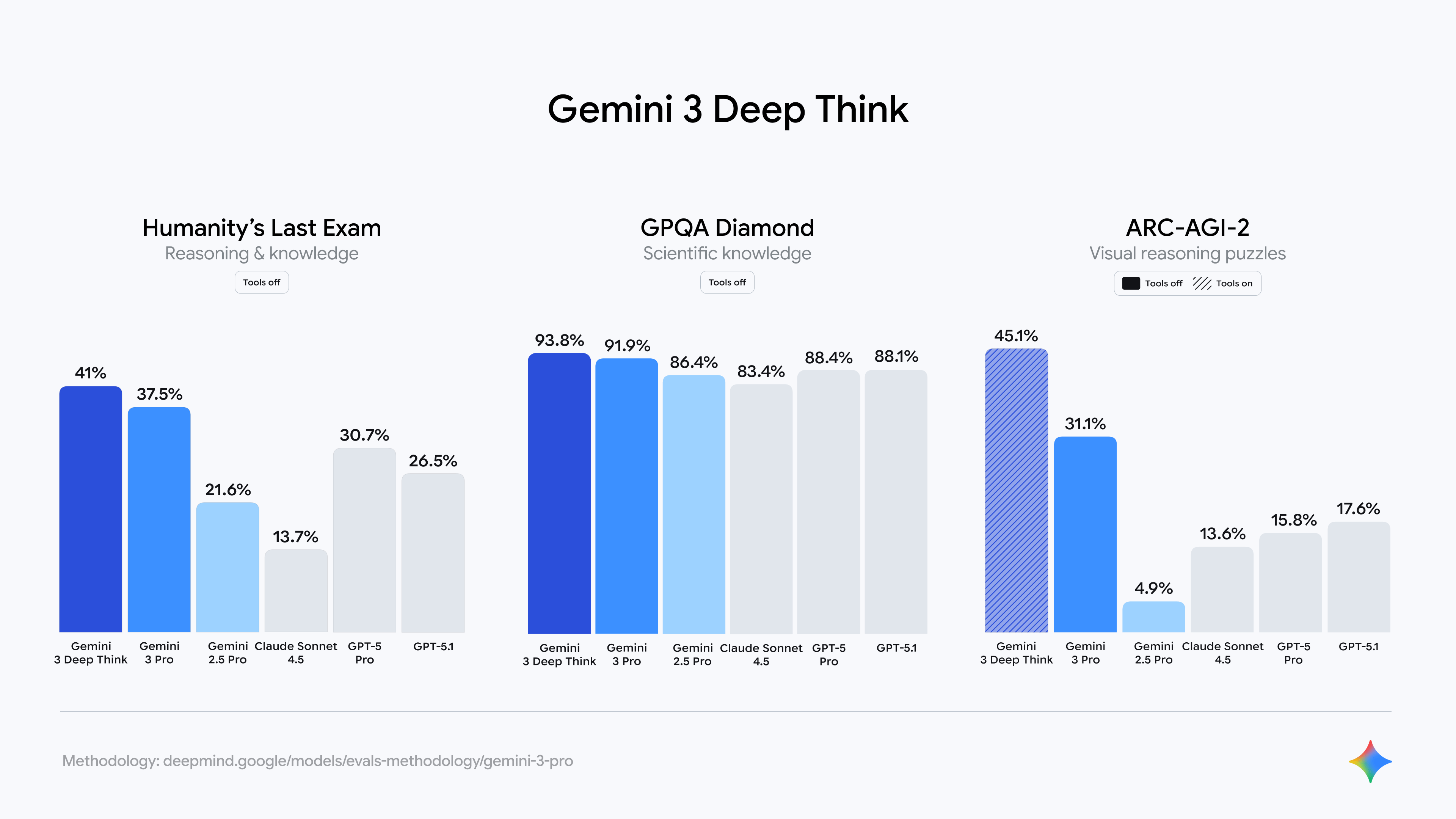
Если Gemini 3 Pro вам мало, есть Deep Think. Этот режим включает усиленные способности рассуждения: модель внутри «обдумывает» несколько вариантов решения, используя параллельные цепочки рассуждений и самопроверку.
На Humanity’s Last Exam Deep Think выдаёт 41,0% без инструментов (против 37,5% у базовой версии). По GPQA Diamond — 93,8% против 91,9%. И главное: на ARC-AGI-2 с выполнением кода Deep Think достиг 45,1% — абсолютный рекорд для этого теста.
Deep Think умеет динамически выделять ресурсы под задачу: если запрос простой, модель думает меньше и отвечает быстрее; если сложный — берёт больше времени на анализ. Разработчики могут вручную настроить «бюджет мышления» через API.
Правда, пока что Deep Think доступен только для тестировщиков безопасности, а подписчикам Google AI Ultra его обещают в ближайшие недели. Я ещё не пробовал, но судя по отзывам, режим особенно хорош для научных расчётов и многошаговых задач.
Мультимодальность: текст, картинки, видео и код

Gemini 3 изначально заточен под работу с разными форматами. Вы можете загрузить фотографию рукописного рецепта на другом языке, и модель переведёт его в цифровой вид. Или дать ссылку на часовую лекцию по физике — Gemini 3 сгенерирует интерактивные флешкарты или визуализацию на коде.
Реальный пример: я загрузил видео с игры в пикклбол (да-да, такой вид спорта), и модель проанализировала технику, указала на ошибки и составила план тренировок для улучшения формы. Попробуйте такое с обычным чат-ботом — не выйдет.
На MMMU-Pro (мультимодальное понимание) Gemini 3 показал 81,0%, а на Video-MMMU — 87,6%. По точности фактов на SimpleQA Verified результат 72,1% — новый стандарт для LLM.
Ещё один кейс: загрузил 2-минутный видео ролик игры в теннис. Gemini 3 не только понял что там происходит и посчитал счет, а дал совет как тренер топ уровня. Модель не просто «видит» или «слышит» — она связывает информацию между форматами.
Генеративный UI: когда ИИ создаёт интерфейсы под запрос
Одна из самых крутых фишек Gemini 3 — генеративные пользовательские интерфейсы (Generative UI). Модель не просто выдаёт текст, а генерирует целые веб-страницы, игры, инструменты и приложения прямо под ваш запрос. Или например если вы захотел сделать анимацию на сайте в стиле ретро вейв.
Технически это работает так: Gemini 3 использует встроенные инструменты (веб-поиск, генерацию изображений), плюс детальные системные инструкции, плюс постобработку для устранения типичных ошибок. В итоге получается динамический интерфейс, который адаптируется под задачу.
Например, если вы спросите, как работает микробиом, для ребёнка 5 лет модель создаст одну версию интерфейса, а для взрослого — совсем другую. Или попросите план путешествия — получите интерактивную карту с маршрутами, бюджетом и рекомендациями.
В поиске Google AI Mode теперь может строить калькуляторы ипотеки, где вы меняете процентную ставку и первоначальный взнос в реальном времени. Или симуляции по физике, когда вы изучаете какую-то тему. Это не просто ответ на вопрос — это полноценный инструмент под вашу задачу.
Лично мне зашло. Попросил создать галерею постов для соцсетей — получил готовую вёрстку с превью и фильтрами. Раньше пришлось бы собирать это вручную из нескольких инструментов.
Vibe coding и Google Antigravity — разработка на стероидах

Google называет Gemini 3 лучшей моделью для «vibe coding» — когда ты описываешь, что хочешь получить, а модель генерирует полноценный код с интерактивом и богатой визуализацией.
Gemini 3 Pro возглавил WebDev Arena с 1487 баллами Elo. На LiveCodeBench Pro (задачи с Codeforces и IOI) результат 2439 баллов, что выше GPT-5.1 (2243) и значительно опережает Claude (1418).
Вместе с запуском модели Google выпустил Google Antigravity — новую платформу для агентной разработки. Это не просто IDE, а инструмент, где ИИ-агенты работают параллельно в редакторе, терминале и браузере.
Как это работает: вы даёте один промпт, агент разбивает его на подзадачи, пишет код, тестирует его в браузере, создаёт отчёты о прогрессе и даже делает walkthrough финального продукта. Antigravity использует Gemini 3 Pro, Gemini 2.5 Computer Use (для контроля браузера) и Nano Banana (редактирование изображений).
Я попробовал создать простое веб-приложение — Antigravity справился за 15 минут, включая отладку. Обычно на это ушло бы часа два минимум. Платформа доступна на Mac, Windows и Linux, пока в бесплатном превью.
- Попробовать можно тут >> Google Antigravity <<
Агентные возможности: Gemini Agent для реальных задач
С Gemini 2 Google начал эру агентных ИИ — моделей, которые могут выполнять многошаговые задачи автономно. Gemini 3 поднял эту планку ещё выше.
На бенчмарке Vending-Bench 2, который тестирует долгосрочное планирование через управление виртуальным бизнесом, Gemini 3 заработал $5478,16 за симулированный год — намного больше, чем Claude ($3838,74) или GPT-5.1 ($1473,43). Модель не сбивалась с задачи, последовательно использовала инструменты и принимала решения весь год.
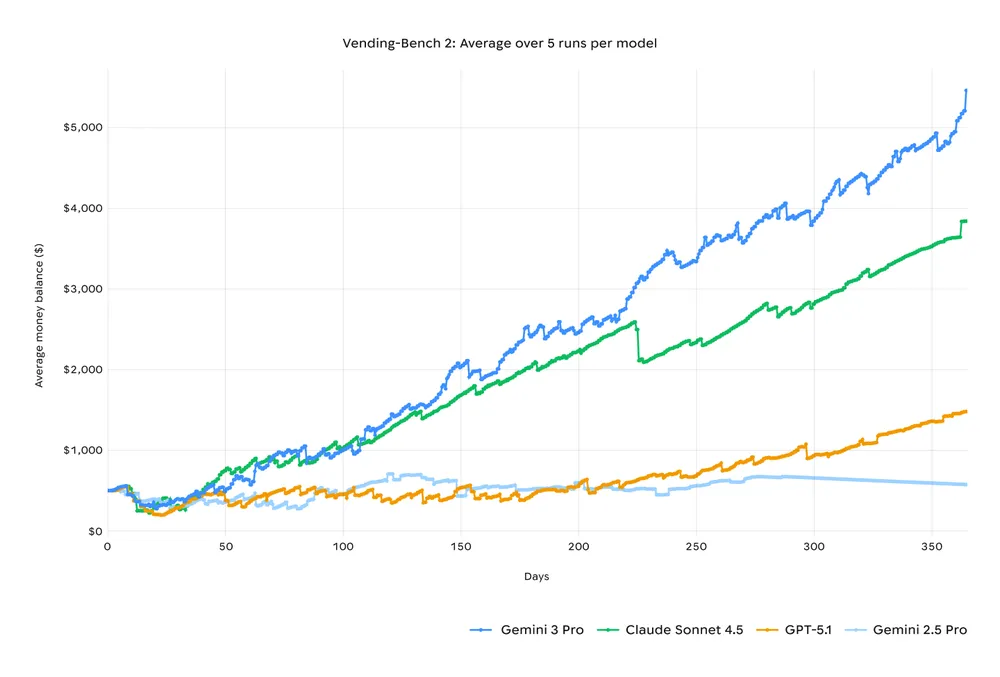
Что это значит для вас? Gemini Agent в приложении Gemini теперь может не просто давать советы, а делать работу за вас. Например, раньше вы спрашивали, как почистить почтовый ящик, и получали общие рекомендации. Теперь Gemini Agent сам организует вашу почту.
Агент использует Deep Research, Canvas, доступ к вашим приложениям Google (Gmail, Calendar) и живой веб-браузинг. При этом вы остаётесь в контроле: перед критическими действиями (покупка, отправка сообщений) модель запросит подтверждение. Можете в любой момент взять управление на себя.
Gemini Agent доступен сегодня для подписчиков Google AI Ultra в США. Я ещё не пробовал (нахожусь не в штатах), но ребята, кто тестировал, говорят, что это экономит кучу времени на рутине.
Как получить доступ к Gemini 3: бесплатные и платные варианты
Gemini 3 Pro доступен всем через приложение Gemini (gemini.google.com) прямо сейчас. Бесплатная версия даёт базовый доступ к модели, но с лимитами на количество запросов.
Чтобы использовать модель чаще и получить доступ ко всем фишкам, нужна подписка:
Google AI Pro — $19,99 в месяц или $199,99 в год. Включает:
- Больше доступа к Gemini 3 Pro
- Deep Research на базе Gemini 3 Pro
- Ограниченный доступ к генерации видео через Veo 3.1 Fast
- NotebookLM с расширенными функциями
- 2 ТБ облачного хранилища Google One
- Бесплатный пробный месяц
Google AI Ultra — $249,99 в месяц. Включает всё из Pro, плюс:
- Расширенный контекст и приоритетный доступ к Gemini 3 Deep Think
- Премиум-функции Flow для видео
- Доступ к бета-версиям новых функций
- При запуске действует скидка 50% на первые 3 месяца
ВАЖНО! есть способ практически бесплатно получить подписку, способом поделился в Телеге >> ИИздатый канал <<
Gemini 3 vs GPT-5 и Claude: кто кого
Сравним Gemini 3 с главными конкурентами — GPT-5.1 от OpenAI и Claude Sonnet 4.5 от Anthropic.

По точности и структуре: Gemini 3 выигрывает в задачах, где нужна чёткая структура, форматирование и последовательность. GPT-5 лучше в глубоких рассуждениях и адаптивности — он справляется с неоднозначными промптами и крайними случаями логики.
По скорости: Gemini 3 обрабатывает мелкие задачи за 12 секунд, GPT-5 — за 25 секунд. На средних задачах разрыв 2 минуты против 4, на крупных — 15 минут против 32. Если вы работаете с несколькими проектами, скорость критична.
По мультимодальности: Gemini 3 сильнее в визуальных задачах и создании интерактивных интерфейсов. GPT-5 выдаёт отличный текст и хорош в научном анализе, но для визуалов придётся использовать другой инструмент.
По кодингу: На SWE-Bench Verified GPT-5.1 и Gemini 3 почти на одном уровне (76,3% и 76,2%), но Gemini 3 доминирует в визуальных проектах и SVG-генерации. Claude Sonnet 4.5 чуть впереди по кодингу (77,2%), но отстаёт по агентным задачам.
Практический пример: если вы создаёте лендинг, GPT-5 напишет классный текст и структуру, но для дизайна придётся переключиться на другой инструмент (45 минут, три инструмента). Gemini 3 сделает HTML/CSS с анимациями и дизайном сразу (20 минут, один инструмент).
Для контент-мейкеров, делающих YouTube-превью, Gemini 3 — очевидный выбор: генерация визуалов, итерации в реальном времени, экспорт готовых файлов. Для разработчиков, работающих с тяжёлыми кодовыми базами, лучше использовать оба: GPT-5 для логики, Gemini 3 для визуалов.
Imagen 4: Прорыв, который научился писать

Google представил Imagen 4, и это, кстати, самый продвинутый их генератор изображений на сегодняшний день. Тут я офигел, когда увидел, что он не просто рисует в 2K, но и научился правильно рендерить текст. Это ж была главная боль вообще всех предыдущих версий!
Что тут реально круто:
- Текстуры и Реализм: Отрисовывает всё, от шерсти животных до капель воды, максимально реалистично.
- Гибкие форматы: Может генерить картинки под сторис (9:16) или под панорамы.
- Типографика без боли: Наконец-то правильно вписывает надписи и шрифты. Это идеально для презентаций, в общем-то, или каких-нибудь постеров.
Короче, если сравнить с Imagen 3, разница в деталях просто огромная. Imagen 3 делал такие “мягкие” картинки, а Imagen 4 выдаёт резкие, насыщенные детали. Помню, ещё в марте об этом говорили, что Google сильно работает над детализацией. И вот, буквально вчера обновление вышло.
И ещё момент: они анонсировали Imagen 4 Fast, который в 10 раз быстрее Imagen 3. Это позволяет тестить десятки концептов за минуты, а не часы. Серьёзно?! Кто вообще принимает такие решения, которые так ускоряют работу?! (Ну, в хорошем смысле, конечно).
По сути дела, его можно юзать прямо в Google Docs или Slides.
Nano Banana: Редактирование, которое думает

Nano Banana — это не отдельная модель, а такое прозвище, которое прижилось для Gemini 2.5 Flash Image. Кстати, даже Google стал его использовать.
Почему я считаю, что это бомба:
- Правки через промпты: Загружаешь фотку, пишешь текстом, что изменить — и он делает.
- Контекстуальные изменения: Модель не просто накладывает фильтр, она анализирует освещение, глубину и композицию. Вот, представь, ты загружаешь фото кота на подоконнике. Пишешь: “Добавь снег за окном”. Nano Banana не просто добавит снег, он скорректирует освещение на коте, добавит холодные оттенки. Обычный фоторедактор так не умеет, в общем-то.
- Сохранение персонажей: Если работаешь с портретом, он сохранит черты лица между правками.
Вообще, можно было бы сказать, что… хотя нет, давайте лучше с примера начнём. Сначала я подумал, что это просто маркетинговый ход. Проверил — нет, всё в порядке. Тогда полез смотреть, как это работает технически, и вот тут-то… по сути дела, модель использует огромную базу знаний Gemini, чтобы понимать реальные взаимосвязи между объектами.
Veo 3.1: Видео с нативным звуком
Veo 3.1 — это свежайшая версия видеогенератора от Google, вышла в октябре 2025. Это эволюция Veo 3, и главные фишки тут — звук, точность промптов и контроль над персонажами.
Смотри, какая штука. Знаешь, почему это важно? Сейчас объясню.
Ключевые апгрейды:
- Натуральный Звук: Улучшились диалоги, синхронизация губ стала почти идеальной, и звуковые эффекты стали реалистичнее. У Veo 3 диалоги иногда звучали приглушённо. Тут Veo 3.1 даёт чистый, чёткий звук.
- Кинематографическая точность: Он лучше понимает сложные команды типа “кран-шот”.
- Консистентность персонажей: Одежда, черты лица, причёска — всё сохраняется между кадрами. Это критично для создания многокадровых историй.
Вообще, можно было бы сказать, что… хотя нет, давайте лучше с примера начнём. Ты наверняка сейчас думаешь: а зачем мне это вообще надо? Отвечаю: потому что появились новые функции управления.
- Ingredients to Video: Загружаешь референсы (персонажей, объекты) — модель сохраняет их идентичность в видео.
- Scene Extension: Можешь продлить видео, добавляя новые клипы, которые плавно продолжают предыдущий. Так можно собрать ролики длиной до 60+ секунд.
Слушайте, я уже в третий раз пытаюсь объяснить эту концепцию. Давайте просто… вот есть пример: хочешь ролик, как корабль садится на планету. Загружаешь референс корабля (Ingredients to Video), генерируешь 8 секунд. Потом используешь Scene Extension, чтобы добавить посадку. Получается 16-секундный ролик с визуальной и звуковой непрерывностью. Правда, это очень удобно.
Как это всё работает с Gemini 3
По сути дела, эти инструменты не существуют отдельно — они встроены в экосистему Gemini 3.
Ладно, с этим разобрались. Теперь про другое.
- Интеграция с Google Antigravity: Эта новая платформа для разработки использует Gemini 3 Pro для кодинга, Gemini 2.5 Computer Use для контроля браузера, а Nano Banana — для визуала. Агент может сам писать код, проверять его и генерить картинки одновременно и автономно.
- Мультимодальный контент: Ты создаёшь презентацию. Gemini 3 даёт текст и структуру. Imagen 4 рисует логотипы с правильным текстом. Nano Banana редактирует фото. Veo 3.1 делает демо-ролик с озвучкой. Всё это в Google Workspace, без переключения между инструментами. Это просто охренеть.
Безопасность и ответственный подход
Google заявляет, что Gemini 3 — их самая безопасная модель на сегодня. Модель прошла самый обширный набор тестов безопасности из всех ИИ Google.
Что конкретно улучшилось:
- Снижена подхалимская тональность (sycophancy) — модель реже говорит то, что вы хотите услышать, вместо правды
- Повышена устойчивость к prompt injections (попыткам взлома через промпты)
- Улучшена защита от злоупотреблений через кибератаки
Google работал с независимыми экспертами, включая UK AISI, Apollo, Vaultis, Dreadnode и других. Тестировали модель по критическим доменам из Frontier Safety Framework — внутреннего стандарта безопасности Google.
Для Deep Think режима Google берёт дополнительное время на проверки перед запуском для широкой аудитории. Это правильный подход, учитывая мощность модели.
Где уже доступен Gemini 3 и что дальше
Gemini 3 Pro стартовал 18 ноября 2025 года сразу на нескольких платформах:
- Gemini app (gemini.google.com) — для всех пользователей
- AI Mode в Google Search — для подписчиков AI Pro и AI Ultra
- AI Studio — для разработчиков
- Vertex AI — для корпоративных клиентов
- Google Antigravity — новая платформа для агентной разработки
- Сторонние платформы: Cursor, GitHub, JetBrains, Manus, Replit и другие по API
Gemini 3 Deep Think придёт для Google AI Ultra подписчиков в ближайшие недели после финальных проверок безопасности.
Google обещает выпустить дополнительные модели в линейке Gemini 3 в ближайшее время. Судя по истории релизов, можно ожидать Gemini 3 Flash (быстрая версия для простых задач) и специализированные варианты для конкретных задач.
Стоит ли переходить на Gemini 3: мой вердикт
Лично я уже использую Gemini 3 Pro для рабочих задач. Вот что реально зашло:
Скорость. Разница в 2-3 раза по сравнению с предыдущей версией ощущается каждый день. Когда работаешь над несколькими проектами, это критично.
Понимание контекста. Модель реже требует уточнений и переформулировок. Схватывает, что ты хочешь, с первого раза.
Мультимодальность. Возможность работать с текстом, изображениями, видео и кодом в одном месте экономит кучу времени. Не надо прыгать между инструментами.
Визуалы. Если вы делаете контент, дизайн или веб-разработку, способность Gemini 3 генерировать интерактивные интерфейсы — это просто находка.
Минусы тоже есть. Бесплатная версия ограничена по запросам. Подписка за $20 в месяц — не всем по карману. И если вы из России, придётся заморачиваться с сервисом из 3 букв и виртуальными картами.
Для кого Gemini 3 подойдёт:
- Разработчики, которым нужен быстрый кодинг и агентные инструменты
- Контент-мейкеры, работающие с визуалами и мультимедиа
- Аналитики и исследователи, обрабатывающие большие объёмы данных
- Студенты (бесплатный доступ на год)
Если вы работаете с текстом и вам нужна глубина анализа, GPT-5 может быть лучше. Если важна безопасность и длинные диалоги, посмотрите на Claude. Но для комплексных задач, где нужны и текст, и визуалы, и код — Gemini 3 сейчас впереди.
Как начать пользоваться Gemini 3 прямо сейчас
Шаги простые:
- Заходите на gemini.google.com (если из России — через VPN с IP США)
- Регистрируете Google-аккаунт или логинитесь в существующий
- В приложении Gemini выбираете модель «Thinking» в селекторе — это и есть Gemini 3 Pro
- Для полного доступа оформляете подписку AI Pro (стартует от $19.99/мес) P.S в телеге рассказываю как почти бесплатно ее получить;) https://t.me/+P11a40bYbZ4zZGNi
Для разработчиков:
- Заходите в AI Studio для тестирования моделей
- Регистрируетесь в Google Antigravity для агентной разработки
- Подключаете Gemini 3 через API в Vertex AI, если работаете в энтерпрайзе
Если хотите протестировать без подписки, используйте бесплатную версию в Gemini app — она даст базовое представление о возможностях модели.
Gemini 3 — это серьёзный шаг вперёд в мире ИИ. Google не просто улучшил цифры на бенчмарках, но создал инструмент, который реально экономит время и делает работу проще. Я уже перевёл часть задач на эту модель и пока что доволен.
Попробуйте сами — первый месяц бесплатно, так что терять нечего. Если зайдёт — останетесь, если нет — отмените подписку.
P.S. В моем телеграм-канале вы найдете еще больше новостей из мира ИИ, лайфхаков и полезной информации. Подписывайтесь на ИИздатый канал а у меня на сегодня все!

9К открытий18К показов

Подборка лучших нейросетей и ИИ-сервисов для написания эссе и сочинений в 2025 году: создавайте грамотные, структурированные тексты быстро и бесплатно с помощью умных инструментов.

Мы сделали МТС True Tabs — платформу, с которой можно автоматизировать большинство рабочих задач без помощи профессиональных разработчиков. Рассказываем, как она выглядит и чем хороша — все на примерах разных наших команд.
Разработчица с помощью ИИ за 3 дня портировала Mac OS 7 на x86 без исходников: система запускается в QEMU с рабочим Finder и GUI

Микросервисы — это не всегда решение. Эксперт разобрал главные минусы: хаос в архитектуре, рост затрат, сложная отладка и непредсказуемость системы