


Архитектура микросервисов: как избежать 7 типичных ошибок — разбор реальных кейсов


7 типичных ошибок в архитектуре микросервисов: разбор реальных кейсов
886 открытий3К показов

Архитектура микросервисов — не панацея от всех бед. Она не гарантирует успеха, но точно показывает слабые места в процессах команды. Некоторые компании проходят этот путь с блестящим результатом. Другие оказываются в ситуации, которую эксперт Крис Ричардсон, автор книги «Microservice Patterns», метко называет «микросервисы съели моё приложение» — когда технологию незаслуженно назначают причиной собственных провалов.
Правда в том, что микросервисы не собираются стаями, чтобы атаковать ни в чём не повинные проекты. Проблемы возникают из-за неверных архитектурных решений или когда вы игнорируете явные сигналы, что что-то пошло не так.
Разберём семь провальных сценариев, которые допускают команды при переходе на микросервисы. Вы узнаете, как избежать этих ловушек и построить систему, которая будет по-настоящему гибкой и масштабируемой.
Зачем вообще нужны микросервисы
Архитектура микросервисов — это не универсальное решение, а альтернативный подход к построению систем.
Микросервисы подходят не для всех проектов. Они оправданы, когда:
- система действительно большая и сложная;
- разные компоненты требуют разного масштабирования;
- команды могут работать независимо;
- нужно использовать разные технологии для разных задач.
Монолит часто лучше для:
- небольших проектов с четкими границами;
- команд до 10 человек;
- ситуаций, когда важна простота развертывания;
- проектов с неясными требованиями.
Представьте монолит как специализированный магазин. Все товары в одном помещении. Покупатель быстро находит нужное. Владелец легко управляет ассортиментом.
Микросервисы работают иначе. Это сеть специализированных магазинов, расположенных в одном торговом центре. Хлебный магазин, мясная лавка, овощной павильон. Каждый работает независимо. Если в хлебном магазине ремонт, мясная лавка продолжает работать.
Конкретные преимущества микросервисов:
- Независимое развертывание. Можно обновлять один сервис без остановки всей системы.
- Масштабируемость. Сервисы с высокой нагрузкой масштабируются отдельно от остальных.
- Технологическая гибкость. Разные сервисы можно писать на разных языках и технологиях.
- Устойчивость к ошибкам. Если один сервис упадёт, это не приведёт к коллапсу всей системы.
Но эти преимущества работают только при правильной реализации. На практике слишком часто команды создают систему, где сервисы так тесно связаны, что преимущества независимости теряются. Возникает ситуация, когда каждый сервис по отдельности прост, но вместе они создают сложную для управления конструкцию. Проблема в одном сервисе при такой реализации отражается на всех остальных. Внесение изменений требует согласования с несколькими командами. Нет ни гибкости микросервисов, ни предсказуемости монолита. Вместо этого получается наихудший из вариантов.
Далее мы рассмотрим наиболее типичные антипаттерны, которые встречаются в практике разработки. Стоит изучить эти ошибки, чтобы не допускать их в своих проектах.

Ошибка 1: Распределенный монолит
Команды хотят получить преимущества микросервисов, но не могут отказаться от мышления в стиле монолита.
В чем проблема: Вместо независимых сервисов получается система, где все компоненты жёстко связаны. Это и есть распределённый монолит.
Реальный кейс: Консультант IBM Холли Каммингс описывает проект, где команда жаловалась: «каждый раз, когда мы меняем один микросервис, ломается другой». Сервисы были распределены по разным репозиториям, но использовали идентичные копии сложной объектной модели. Изменение одного поля требовало синхронного обновления всех сервисов. Команда потеряла преимущества монолита — компилятор больше не проверял типы, — но не получила преимуществ микросервисов — независимости развёртывания.
Как избежать:
- Проектируйте сервисы вокруг бизнес-доменов, а не технических слоев. Интерфейсы сервисов должны быть узкими и специфичными. Например, сервис заказов сам управляет своими данными, логикой и API для операций с заказами.
- Откажитесь от общих библиотек с моделью данных. Каждый сервис должен владеть своими данными и иметь свою модель.
- Используйте подход, когда клиенты сервиса задают ожидания от его API. Для этого подходят инструменты вроде Pact. Такой метод проверяет совместимость сервисов без громоздких интеграционных тестов.
Распределённый монолит — это худший из возможных сценариев. Вы получаете сложность распределённых систем без преимуществ модульности.
Ошибка 2: Чрезмерное дробление сервисов (декомпозиция)
Стремление сделать сервисы как можно меньше приводит к противоположному эффекту. Система дробится на сотню мелких компонентов, которыми невозможно управлять.
В чем проблема: Каждый микросервис — это отдельное приложение со своей базой данных, зависимостями и пайплайном развёртывания. Чрезмерное дробление увеличивает сложность управления, мониторинга и эксплуатации. Растут сетевые издержки — латентность становится узким местом, работа системы замедляется.
Реальный кейс: Компания Gilt перешла на микросервисы в 2015 году и столкнулась с проблемой излишнего дробления. Изначально они создали более 450 микросервисов для платформы электронной коммерции. Многие сервисы были настолько малы, что выполняли лишь одну простую функцию. Это привело к экспоненциальному росту операционных расходов. Команда тратила больше времени на координацию взаимодействия между сервисами и устранение сетевых сбоев, чем на разработку новой функциональности. В итоге они провели рефакторинг, объединив сервисы с высокой связностью, что значительно упростило систему и ускорило разработку .
Как найти баланс:
- Объединяйте функциональности с высокой связностью. Если два компонента постоянно общаются, возможно, они должны быть одним сервисом.
- Ориентируйтесь на функциональную связность. Сервис должен иметь чёткую зону ответственности в бизнес-логике.
- Оценивайте операционные расходы, прежде чем создавать новый сервис. Спросите себя: готовы ли мы поддерживать ещё одну базу данных, ещё один конвейер развёртывания?
Сервис должен быть достаточно автономным, чтобы его могла поддерживать одна команда. Ему необходимо решать конкретную бизнес-задачу. Если сервис слишком мал, он не принесет реальной пользы, но потребует полноценных затрат на поддержку. Золотая середина — когда команда полностью владеет одним или несколькими логически связанными сервисами и может развивать их без постоянной координации с другими.
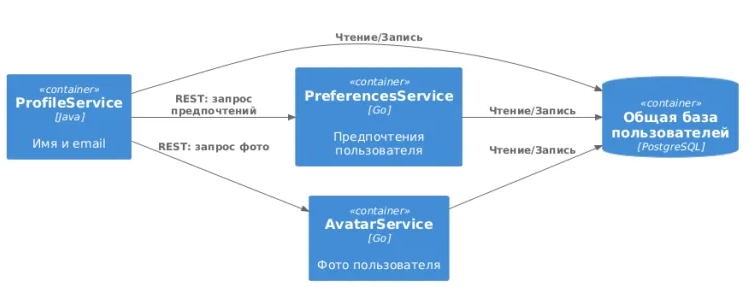
Ошибка 3: «Болтливые» микросервисы
Микросервисы много общаются друг с другом. Мелкозернистые API вынуждают делать десятки вызовов для одной операции. Это создаёт каскады зависимостей, где сбой одного сервиса вызывает цепную реакцию.
В чем проблема: При такой структуре возникает следующий сценарий провала:
- Частые взаимодействия — сервисы обмениваются множеством мелких запросов, генерируя насыщенный сетевой трафик.
- Каскад вызовов — один пользовательский запрос запускает длинную цепочку обращений к разным сервисам.
- Мелкозернистые API — для выполнения одной бизнес-транзакции требуется множество вызовов.
Реальный кейс: Команда Amazon Prime Video столкнулась с проблемой производительности своей системы мониторинга видео. Изначально они построили архитектуру на основе микросервисов, где каждый этап обработки видео (метаданные, детекция дефектов, анализ качества) был отдельным сервисом.
Система состояла из множества «болтливых» сервисов, которые постоянно обменивались сообщениями через AWS Step Functions. Это привело к резкому росту затрат и проблемам с производительностью из-за постоянной сериализации/десериализации данных между сервисами. В итоге команда консолидировала несколько сервисов в единый монолит, что снизило затраты на 90% и улучшило производительность .
Решение:
- Используйте асинхронную коммуникацию через очереди событий.
- Проектируйте крупнозернистые API, которые охватывают полный бизнес-контекст за один вызов.
- Внедряйте архитектурные паттерны типа API Gateway для агрегации данных и Backend For Frontend для оптимизации под конкретные клиенты.
Сервисы должны обмениваться данными минимально необходимое количество раз. Каждый лишний вызов между сервисами увеличивает задержки и создаёт новые точки отказа. Вместо потока мелких запросов проектируйте взаимодействие вокруг завершённых операций. Один запрос должен передавать все данные, необходимые для выполнения следующего шага бизнес-процесса.
Ошибка 4: Игнорирование сквозной функциональности
Команды часто откладывают на потом реализацию системных компонентов: логирование, аутентификацию, кеширование, мониторинг, поэтому разработка быстро останавливается.
В чем проблема: Разработка бизнес-сервисов начинается до подготовки общесистемных компонентов. В результате каждый сервис изобретает собственные способы логирования и аутентификации. Приходится переделывать готовый код, чтобы добавить единый стандарт.
Реальный кейс: Команда, создающая микросервисы на Go, разработала единый подход к обработке ошибок и логированию. Они используют структурированное логирование с обязательным контекстом — идентификаторами пользователей, транзакциями, следами запросов. При необходимости специалисты сразу находят корневые причины проблем, не переключаясь между десятками лог-файлов.
Правильный подход:
- Сначала создайте базовые сервисы для логирования, кеширования, управления пользователями и мониторинга.
- Разработайте стандарты и библиотеки для их использования. Командам не придётся дублировать функциональность.
- Внедрите централизованное логирование с самого начала. Без него невозможно отлаживать распределённую систему.
Наблюдаемость как основа стабильности
Современные микросервисные системы требуют полноценной наблюдаемости (observability). Это не просто мониторинг, а понимание, что именно происходит внутри системы, без дополнительных вопросов к разработчикам.
Три столпа наблюдаемости:
- Логи — записи о конкретных событиях с временными метками и контекстом.
- Метрики — числовые показатели, отслеживаемые во времени (загрузка CPU, latency, error rate).
- Трассировка — отслеживание пути запроса через распределённую систему.
Ошибка 5: Нечеткие границы сервисов
Сервисы без чётких границ начинают обрастать несвязанной функциональностью. Order Service вдруг получает отчётность, а Payment Service — нотификации. На выходе — монстр с размытой ответственностью.
В чем проблема: Нарушается принцип единой ответственности. Сервисы становятся большими и сложными. Их трудно тестировать и поддерживать. Код дублируется — разные команды реализуют одинаковую функциональность в разных сервисах.
Реальный кейс: Компания Kong (тогда еще Mashape) начала декомпозицию монолита в 2013 году. Монолитное приложение, написанное на Java, объединяло функциональность маркетплейса API, включая биллинг, аналитику и управление каталогом. В процессе декомпозиции команда столкнулась с трудностями, которые позже были признаны классическими ошибками.
Первоначально четкие границы между компонентами со временем размылись, что привело к серьезным проблемам:
- Сложность развертывания. Любое небольшое изменение требовало полного переразвертывания всей системы.
- Размытие границ. Компоненты маркетплейса стали переплетаться, границы ответственности стерлись.
- Технический долг. Система становилась все сложнее для поддержки и развития.
Попытка исправить ситуацию переходом на микросервисы изначально ухудшила положение. Команда, разделенная на две части (одна поддерживала монолит, другая разрабатывала новую архитектуру), столкнулась с трудностями координации. В итоге процесс разработки замедлился, а не ускорился.
Как избежать:
- Используйте Domain-Driven Design (DDD). Определяйте Bounded Context — чёткие границы бизнес-доменов.
- Перед созданием сервиса документально зафиксируйте его зону ответственности. Что он делает? Какими данными владеет?
- Сопротивляйтесь искушению добавить «ещё одну маленькую функцию» в существующий сервис. Часто лучше создать новый, но для начала нужно разобраться с конкретной задачей продукта.
Антипаттерн Entity Service
Частный случай размытых границ — создание сервисов по принципу «одна сущность — один сервис». Это кажется логичным: сервис пользователей, сервис заказов, сервис товаров. Но на практике такой подход создаёт ещё больше проблем. Entity Service (сервис одной сущности) часто превращается в обычный CRUD-интерфейс к базе данных. Вся бизнес-логика перемещается в вызывающие сервисы, которые вынуждены делать десятки вызовов для выполнения одной операции.
Альтернатива: Создавайте сервисы вокруг бизнес-операций, а не данных. Вместо общего «сервиса пользователей», который отвечает за всё подряд, выделите отдельные сервисы с конкретными зонами ответственности:
- сервис регистрации — создает новые учетные записи;
- сервис аутентификации — проверяет логины и пароли;
- сервис управления профилем — обновляет личные данные.
Каждый такой сервис содержит и данные, и логику своей операции. Названия сразу показывают, что сервис делает. Такой подход помогает избежать «божественных» сервисов, которые знают слишком много.
Ошибка 6: Смешивание баз данных
Общая база данных для нескольких микросервисов — это красный флаг. Сервисы теряют независимость. Изменение схемы данных одним сервисом ломает остальные.
В чем проблема: Единая база данных создает скрытую связность между сервисами. Невозможно выбрать оптимальную СУБД для конкретного сервиса — все используют одно решение. Затрудняется горизонтальное масштабирование.
Реальный кейс: Крис Ричардсон описывает классическую проблему, возникающую при использовании общей базы данных. В этом сценарии сервисы OrderService и CustomerService напрямую обращаются к таблицам друг друга в единой базе данных.
Это создает тесную связность на уровне разработки и времени выполнения:
- Зависимость разработки. Разработчик, вносящий изменения в OrderService, должен согласовывать изменение схемы таблиц с командой, отвечающей за CustomerService, что значительно замедляет работу.
- Блокировки времени выполнения: Длительная транзакция в CustomerService, которая удерживает блокировку на таблице ORDERS, может полностью заблокировать работу OrderService.
Такой подход лишает микросервисы их ключевых преимуществ — независимости развертывания и масштабирования.
Правила работы с данными:
- У каждого сервиса должна быть собственная база данных. Сервис владеет своими данными — другие сервисы получают доступ только через его API.
- Используйте шаблон Saga для управления распределёнными транзакциями вместо двухфазного коммита.
- Реализуйте CQRS (Command Query Responsibility Segregation) для отделения операций записи от операций чтения, когда это необходимо.
Общая база данных создаёт жесткую зависимость между сервисами. Изменение схемы данных в одном месте может сломать функциональность в другом. Команды теряют возможность независимо развивать свои сервисы — любая правка требует согласования со всеми участниками.
Такая архитектура лишает микросервисы их главного преимущества — автономности, и напоминает жизнь в студенческом общежитии. Вместо независимых компонентов получается система, где всё связано невидимыми нитями зависимостей.
Ошибка 7: Неготовность организации
В чем проблема: Микросервисы требуют изменений в структуре команды и процессах. Если продолжать работать как с монолитом, ничего не получится.
Реальный кейс: в одной из компаний команда разрабатывала микросервис, но была вынуждена тесно интегрировать его с унаследованным монолитом. Они зависели от его цикла выпуска, что свело на нет все преимущества независимой разработки. Проект в итоге закрыли.
Какие организационные изменения помогут:
- Перейдите к командам по сервисам — небольшим автономным группам, которые полностью владеют своими сервисами (You Build It, You Run It).
- Внедрите культуру DevOps — автоматизацию сборки, тестирования и развёртывания для каждого сервиса.
- Наладьте независимые циклы выпуска. Возможность развёртывать сервисы без координации с другими командами — ключевое преимущество микросервисов.
Успешный переход на микросервисы требует изменения мышления всей команды. Разработчики должны стать ответственными за свои сервисы на протяжении всего жизненного цикла — от проектирования до эксплуатации в продакшене.
Что меняется:
- Ответственность. Разработчики отвечают не только за написание кода, но и за работоспособность сервиса в продакшн.
- Коммуникация. Команды должны чётко определять контракты между сервисами и соблюдать их.
- Экспертиза. Появляется потребность в специалистах по DevOps, наблюдаемости, распределенным системам.
Микросервисы — это не про технологии, а про архитектуру и организацию работы. Без правильной культуры даже самая совершенная техническая реализация обречена на провал.
Чек-лист для вашего перехода
Прежде чем переходить на микросервисы, проверьте себя по этому списку:
- вы определили бизнес-проблему, которую будете решать микросервисами (а не просто хотим «быть как Netflix»);
- спроектировали границы сервисов на основе бизнес-доменов — DDD, Bounded Context;
- у каждого сервиса будет собственное хранилище данных;
- предусмотрели кросс-каттинговые сервисы — логирование, аутентификацию, мониторинг;
- готовы к организационным изменениям — автономные команды, DevOps;
- выбрали правильный уровень детализации сервисов (не слишком мелкий);
- продумали межсервисную коммуникацию — асинхронную, через события.
Netflix, Amazon и Uber прошли этот путь. Они не избежали ошибок, но выстроили процессы для развития сложных систем. Микросервисы — это эволюция архитектуры и команды. Начинайте с малого, не бойтесь менять решения. Главный критерий успеха — скорость доставки ценности пользователям без поломок продакшена. Если этот показатель растет — вы на правильном пути.

886 открытий3К показов

Сбой AWS обрушил работу крупнейших сервисов — от Fortnite и Steam до Perplexity и Duolingo. Проблема затронула ключевой регион Вирджинии

Какая модель ChatGPT нужна именно вам в каждой конкретной задаче? OpenAI наконец-то объяснила разницу между GPT‑4o, 4.5 и другими

Выбираем, какие игры от читателей Tproger заслуживают лидерства в номинациях за лучший геймплей, лучший казуал, 2D и 3D-графику.
Собрали дайджест из материалов по Python с 15 по 30 апреля. Узнайте, как подключить AutoGPT проекту, как изменился Django и как обучить GPT-4.