


Безопасное исполнение ненадёжного кода
Методы безопасного исполнения ненадёжного кода. Рассматриваются уровни изоляции кода, методы ограничения ресурсов процесса, проблемы жёсткого лимитирования и подходы к их решению. Обсуждаются вопросы управления песочницами, а также использование инструментов контейнеризации.
372 открытий6К показов

Мы привыкли к тому, что ведем разработку, используя лучшие инженерные практики, включая настройку CI/CD-конвейера. Сначала код проходит многоэтапные стадии проверки и тестирования, а только потом попадает в production-среду.
Давайте представим ситуацию, что нужно запустить код, минуя все эти стадии. Прям в production-среде. На первый взгляд — бред! Но если подумать, то на самом деле, не такая уж редкость. Например, некоторые системы предоставляют своим пользователям возможность расширять функциональность за счет прикладных скриптов. Наш любимый CI/CD-конвейер зачастую построен на пользовательских скриптах.
С одной стороны, для большинства подобная постановка вопроса — крайность. С другой, появляется возможность рассмотреть проблему с разных ракурсов. Уверен, что какие-то части общего решения, о котором пойдёт речь далее, могут быть использованы повторно и в других проектах.
Предлагаю по частям разобрать проблему безопасного исполнения ненадёжного кода. Последовательно рассмотрим вопросы, ответы на которые поворотные в выборе целевой архитектуры. Большая часть статьи касается разработки, но в конце сделаны важные акценты относительно администрирования и развертывания.
Ненадёжный код
Для начала определимся, что же считать ненадёжным кодом? На самом деле ответ зависит от решаемой задачи, правил и процессов, принятых в компании:
- Код, который не прошел CI, review и т.п.
- Код из ненадёжного или неизвестного источника.
- Закрытый (проприетарный) код.
- Код, содержащий уязвимости.
- Код, использующий запрещенные функции.
- Любой код, который написал коллега:)
Чтобы отделять код разрабатываемого приложения от ненадёжного, первый буду называть кодом приложения, а второй — ненадёжным или внешним кодом. Необходимость запуска ненадёжного кода в некоторых случаях буду называть задачей.
Уровни изоляции кода
Можно выделить три варианта запуска внешнего кода — три уровня изоляции. Каждый следующий увеличивает дистанцию между кодом приложения и запускаемым кодом. Чем выше уровень изоляции, тем меньше вероятность, что запускаемый код нанесет вред приложению и системе.
Уровень 1: тот же процесс
Запуск внешнего кода в адресном пространстве процесса приложения.
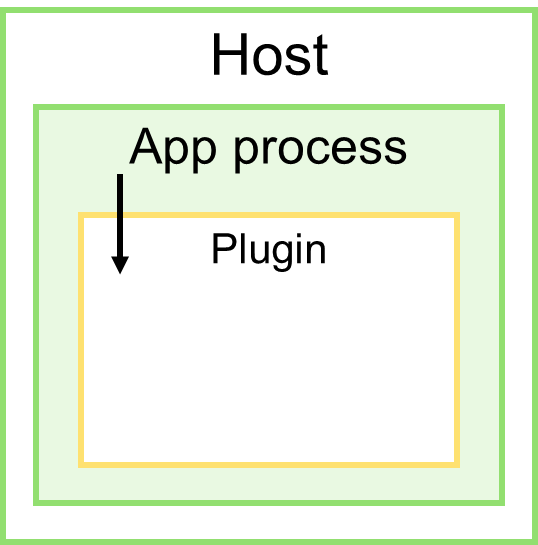
Такой способ определяет самый слабый уровень изоляции, поскольку запущенный код теоретически имеет доступ ко всему тому, к чему имеет доступ код самого приложения.
Примером может служить использование интерпретаторов скриптов (Rhino, IronPython, Jython и т.п.), визуальных языков программирования (workflow-движков) или подключение модулей расширения (плагинов).
Способов защиты на этом уровне не так много. Пожалуй, самым эффективным выступает (self-sandboxing), при котором приложение делает самозапрет на доступ к некоторым ресурсам системы. Например, сразу после инициализации — самозапрет на доступ к файловой системе.
Дополнительно запускаемый код можно подвергать строгому (синтаксическому) анализу, запрещая использование определенных функций, модулей, пакетов и т.п. Некоторые интерпретаторы имеют точки расширения, которые позволяют контролировать процесс исполнения. Если такой возможности нет, можно воспользоваться одной из техник самоизоляции — фильтрацией системных вызовов.
Что же касается плагинов, то они призваны расширять возможности приложения, поэтому их использование изначально не предполагает сильной изоляции. Здесь можно предложить усилить контроль взаимодействия на уровне контракта (API). В идеале — если плагины будут публиковаться в некоторый центральный репозиторий, которому вы доверяете и который может производить дополнительные проверки и тестирование до этапа запуска кода плагина.
Уровень 2: отдельный процесс
Запуск внешнего кода на той же машине, но в отдельном процессе ОС.
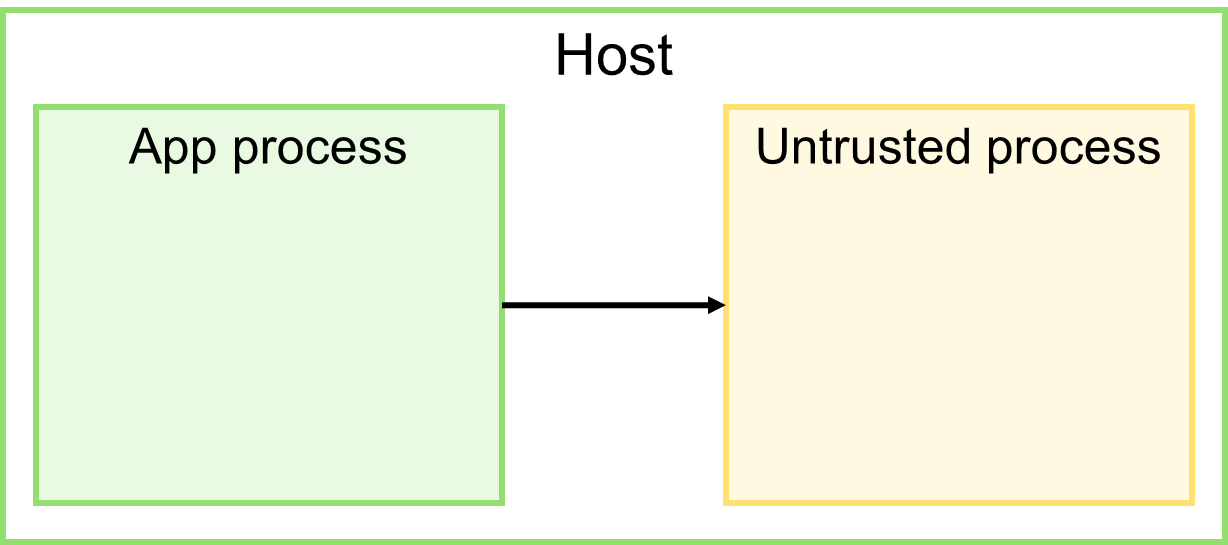
Поскольку и приложение, и внешний код взаимодействуют в рамках одного узла, используя локальные ресурсы ОС (оперативная память, файловая система и т.п.), скорость межпроцессного взаимодействия очень высокая.
Этот уровень изоляции предполагает использование широкого арсенала возможностей. Как минимум, внешний код может быть запущен от имени менее привилегированного пользователя, с ограниченным доступом к ресурсам ОС. Сильные способы изоляции ограничивают ресурсы с помощью средств ОС или инструментов контейнеризации. Однако, чем сильнее контроль, тем больше накладных расходов на запуск и исполнение процесса, что при решении некоторых задач неприемлемо дорого или неоправданно сложно.
Уровень 3: отдельная машина
Запуск внешнего кода на отдельной машине — песочнице.
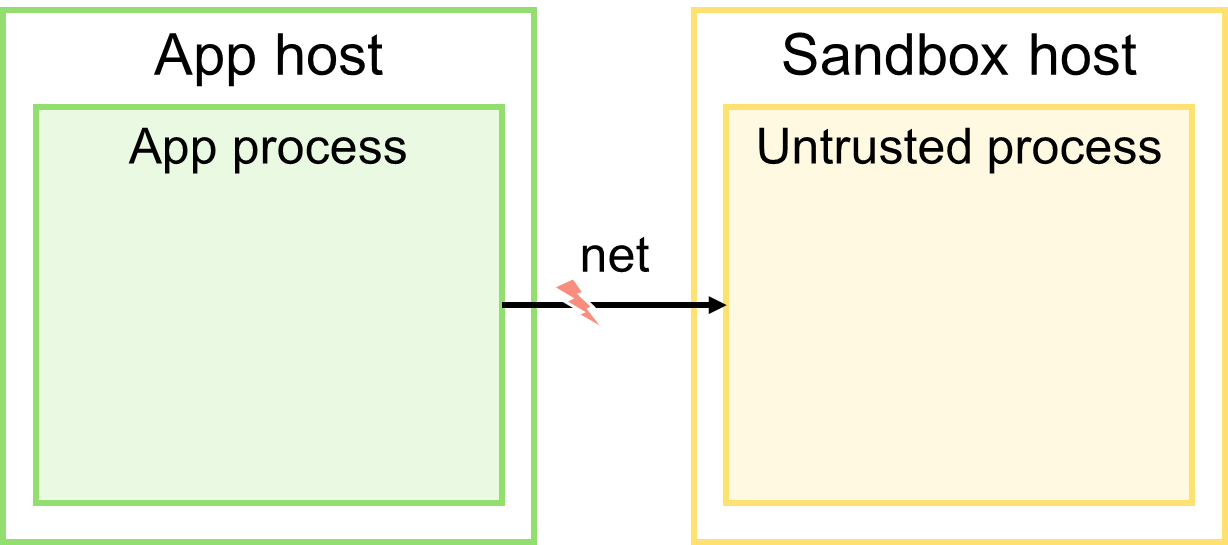
Это максимальный уровень изоляции из всех возможных. Здесь появляется возможность ограничить ресурсы самой песочницы (CPU, память, дисковое пространство, доступ к сети и т.п.). Если в результате исполнения внешнего кода песочница выйдет из строя, приложение продолжит свою работу.
Самый главный недостаток этого подхода — необходимость сетевого взаимодействия между узлом, на котором работает приложение, и песочницей. Передача входных данных в песочницу, запуск процесса внутри, ожидание окончания его исполнения, получение выходных данных — всё это сетевые обращения. Так существенно замедляется процесс исполнения, а само взаимодействие подвержено сетевым сбоям, что ведёт к нестабильности системы и получаемых результатов.
Использование песочницы
Предположим, требуется максимальный уровень изоляции ненадёжного кода, следовательно, нужно остановиться на варианте запуска на отдельной машине. Если так, то для принятия последующих архитектурных решений нужно ответить на следующую пару вопросов.
Пересоздание или переиспользование песочницы
Песочницу требуется пересоздавать перед исполнением каждой задачи, если требуется особенное окружение (например, определенная версия ОС, пакетов или ресурсов) или идентичность этого окружения (для стабильности получаемых результатов). Схожие вопросы возникают, например, при интеграционном тестировании: каждому тесту нужны свои предустановки.
Переиспользование песочницы становится возможным, если задачи могут исполняться в одном окружении и не оказывают влияния друг на друга (предыдущая задача не портит результаты последующей). Продолжая аналогию с интеграционным тестированием: всем тестам нужны одинаковые предустановки, и тесты могут запускаться повторно на одном стенде, демонстрируя один и тот же результат.
Основным преимуществом пересоздания песочницы выступает стабильность получаемых результатов. К недостаткам относится медленный запуск и перерасход ресурсов. На пересоздание песочницы уходят десятки секунд или даже минут, следовательно, большая часть ресурсов будет тратиться именно на это. Существует множество техник ускорения пересоздания, благодаря которым можно сократить время запуска. Прежде всего, сюда можно отнести backup/restore (snapshot песочницы, базы данных и т.п.). Также если поток задач небольшой и ресурсы позволяют, можно попробовать организовать пул песочниц и создавать их заранее.
Ставка на переиспользование делается в случае, когда поток задач большой и нужно сократить время ожидания их запуска. При этом возрастает вероятность получения нестабильных результатов и, возможно, требуется производить какую-то очистку окружения до или после исполнения очередной задачи.
Последовательное или параллельное исполнение
Теперь осталось ответить на вопрос, как именно можно или нужно исполнять задачи: последовательно или параллельно. Последовательное исполнение требуется в следующих случаях:
- важен порядок следования и исполнения задач;
- задачам нужен эксклюзивный доступ к определенному ресурсу;
- задачи ёмкие и их совместное исполнение вызовет нехватку ресурсов;
- задачи могут мешать исполнению друг друга из-за борьбы за ресурсы.
Например, шаги установки и настройки ПО; шаги CI/CD-конвейера; рендеринг изображения на GPU; интенсивные вычисления. Все эти задачи, скорее всего, придётся исполнять последовательно.
В остальных случаях допустимо параллельное исполнение. Яркой аналогией может служить одна из лучших практик в тестировании: тесты не должны оказывать влияние друг на друга, а порядок их запуска не должен иметь значения.
Последовательное исполнение обеспечивает стабильность получаемых результатов, однако приводит к низкой пропускной способности и дороговизне масштабирования (песочница обходится дороже процесса ОС). Параллельное исполнение, напротив, увеличивает пропускную способность системы и улучшает утилизацию ресурсов песочницы, но одновременно повышает вероятность нестабильных результатов. Более того, при параллельном исполнении появляется шанс перегрузить песочницу или вывести её из строя таким образом, что приведет к увеличению времени исполнения всех запущенных задач или потере результатов их работы.
На практике было замечено, что при параллельном исполнении, несмотря на увеличенную общую пропускную способность, время исполнения каждой отдельной задачи увеличивается. Если уровень параллелизма становится больше числа CPU-ядер, время исполнения начинает деградировать намного сильней.
Управление песочницами
Допустим, переиспользование песочниц возможно. В таком случае необходимо определить способ управления ими. Можно выделить два подхода, основанные на принципах микросервисной архитектуры, но адаптированные к специфике рассматриваемой проблемы.
Оркестрация
Оркестрация предполагает, что приложение совмещает две роли: оркестратор исполнения и оператор песочниц. Оркестратор координирует процесс исполнения кода: выбор подходящей песочницы, загрузка в неё входных данных, запуск удалённого процесса, получение результатов его работы и т.п. Оператор, в свою очередь, отслеживает доступные песочницы и их состояние.
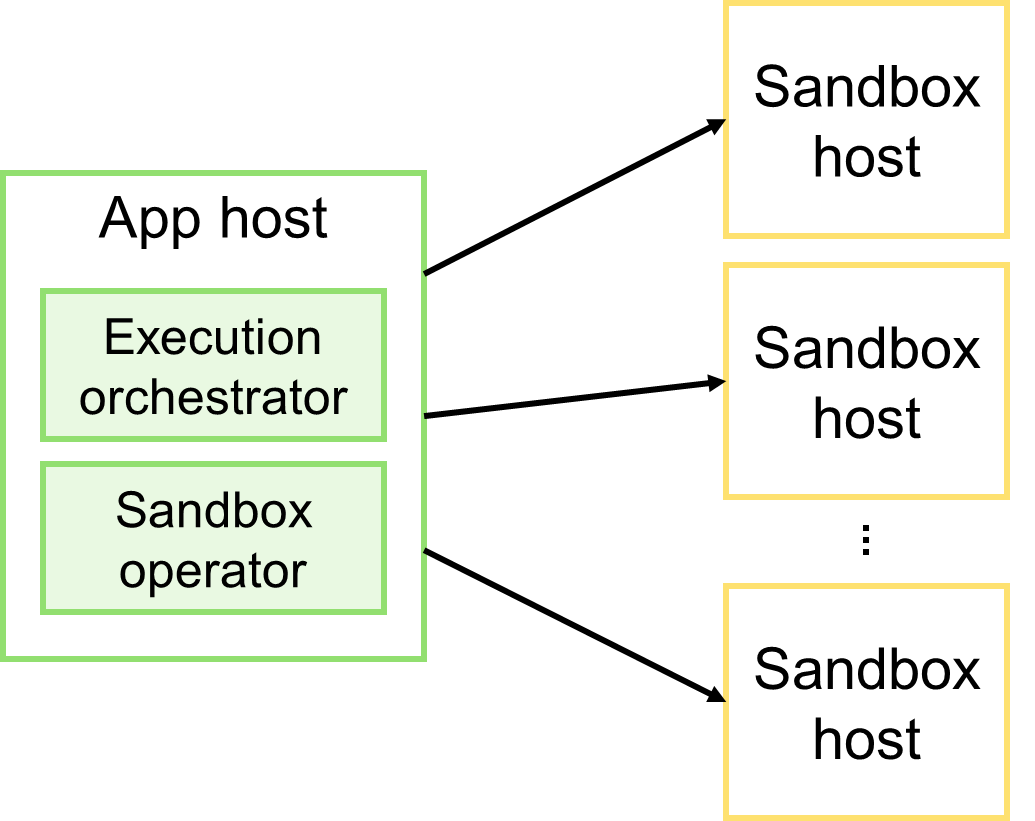
Основное преимущество оркестрации в контексте решаемой проблемы — её простота и ясность. Код легко читается и сосредоточен в одном месте. Однако у этого решения есть и недостатки. Рассмотрим их в порядке от простого к сложному.
- Синхронное взаимодействие. Так или иначе, для результата приложение вынуждено ожидать окончания исполнения задачи. Для продуктивного использования ресурсов приходится прибегать к техникам асинхронного программирования: пока задача исполняется, приложение будет занято полезной работой. Это малозаметный недостаток в языках со встроенной поддержкой концепции асинхронного программирования. Для упрощения работы с асинхронным кодом в Java я создал небольшую вспомогательную библиотеку asynchronizer, снабдив её подробной документацией.
- Отслеживание доступности песочниц. Поскольку хотелось бы, чтобы количество песочниц менялось в зависимости от нагрузки на систему, придётся отслеживать их доступность. Это прямая обязанность оператора песочниц, которую можно выделить в отдельный discovery-сервис (например, на базе Netflix Eureka), либо реализовать как часть приложения с использованием инфраструктурных механизмов (например, Kubernetes API). Важно отметить, что оператор песочниц не имеет отношения к бизнес-логике приложения.
- Отслеживание загруженности песочниц. Оркестратор исполнения должен выбрать подходящую стратегию балансировки, основанную на состоянии песочниц, предоставляемых оператором. На практике наилучшую эффективность демонстрирует алгоритм Least connections, с помощью которого можно выбирать наименее загруженные песочницы. Для этого достаточно вести учёт количества задач, исполняемых каждой песочницей. Конечно, это не серебряная пуля, а лишь частное наблюдение, поэтому в идеале нужно предусмотреть несколько стратегий балансировки и выбрать наилучшую по результатам нагрузочного тестирования.
- Неопределённость результата, если нет ответа от песочницы. Песочница может быть недоступна по различным причинам, включая не только проблемы с сетью, но и падения песочницы из-за ненадёжного кода. К сожалению, в общем случае эта проблема не имеет решения, так как делать повторные запуски (retries) может быть опасно. Всё, что остаётся, это использовать таймауты и откладывать неуспешную задачу на потом.
Ещё один существенный минус, который стоит упомянуть, это возможный побочный эффект, возникающий при масштабировании системы и проявляющийся в виде перегрузки песочниц. Для наглядности рассмотрим конкретный пример.
Для отслеживания нагрузки на песочницы экземпляр приложения ориентируется на количество задач в каждой из доступных песочниц. Предположим, что было принято решение увеличить количество экземпляров приложения. Этот экземпляр исполняет 5 задач в двух песочницах (3 процесса в одной и 2 в другой). Известно, что каждая песочница может вынести максимум 4 параллельных задачи.
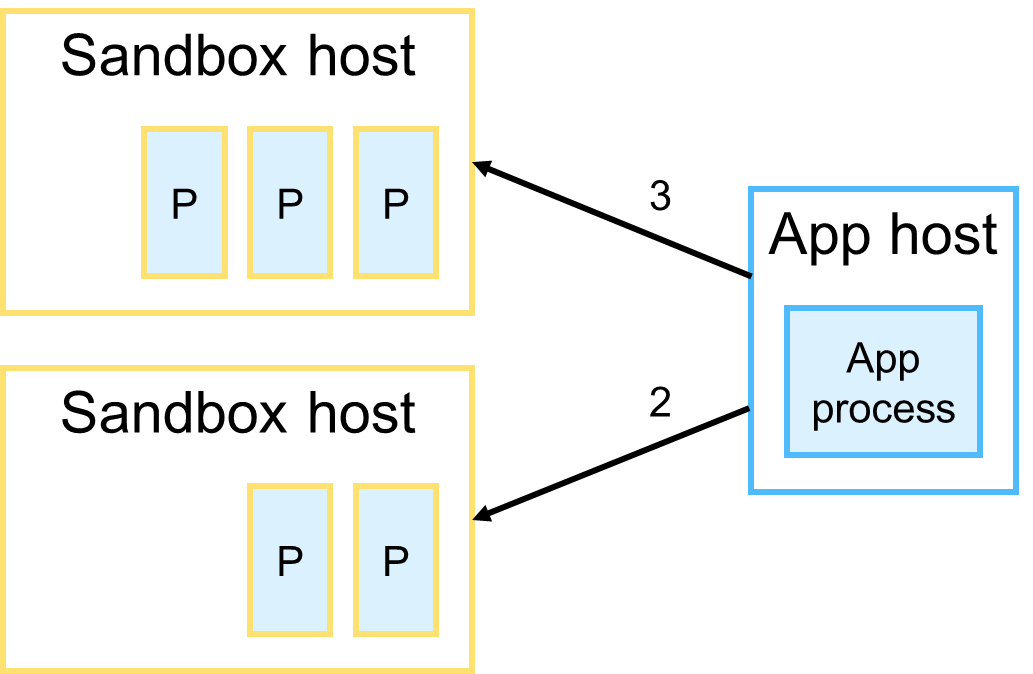
Добавив новый экземпляр приложения, неизвестно, сколько задач исполняет каждая песочница. Такая ситуация может произойти по разным причинам.

Вполне очевидно, что новый экземпляр приложения направит очередную задачу в первую попавшуюся песочницу, чем может спровоцировать её перегрузку. В итоге результат исполнения будет испорчен или потерян из-за падения песочницы.
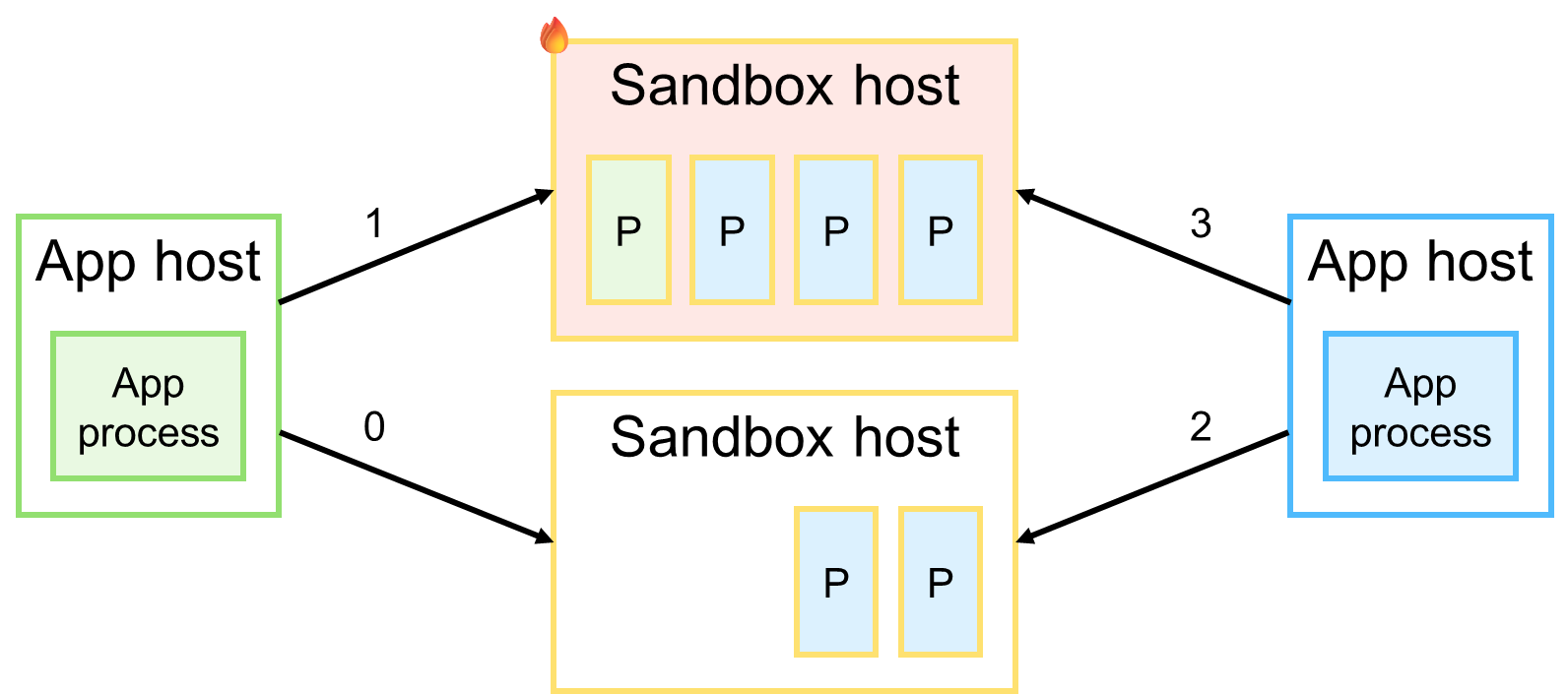
В качестве решения можно предложить два способа, каждый из которых уменьшает вероятность возникновения перегрузок, но не избавляет от них.
- Для контроля количества исполняемых задач в песочнице использовать распределённый счётчик (например, на базе Redis). Проблема в том, что распределённый счётчик имеет латентность и на момент запуска задач может выдать устаревшее значение. Кроме того, в системе появляется еще один инфраструктурный компонент, который не несёт бизнес-пользы.
- Выделить каждому экземпляру приложения эксклюзивное подмножество песочниц. Подобное решение существенно усложнит deployment-скрипты и процесс масштабирования, а также снизит степень утилизации выделенных ресурсов, ведь нет никаких гарантий того, что экземпляр приложения сможет хорошо нагрузить все выделенные ему песочницы.
Кстати, после доклада на TechLeadConf 2025 мне задали интересный вопрос: Можно ли при балансировке нагрузки на песочницы учитывать не только количество исполняемых задач, но и процент загрузки CPU, памяти и прочих ресурсов? Если у кого-то возник такой же вопрос, то отвечу, что это не имеет смысла, поскольку ситуация в песочнице может поменяться мгновенно. Полученный практический опыт и нагрузочное тестирование показали, что простой подсчёт задач работает эффективно.
Самоорганизация
В микросервисной архитектуре подобный подход принято называть хореографией, однако чтобы не возникало неправильных ассоциаций, предлагаю использовать термин самоорганизация.
Ключевой момент в архитектуре — это появление двух очередей: очередь задач на исполнение (Task Queue) и очередь результата их исполнения (Result Queue). Все поступающие задачи приложение направляет в первую очередь, а результаты — во вторую. Дополнительно появляется роль агента — микросервиса, который исполняется в рамках узла песочницы и координирует исполнение поступающих задач.
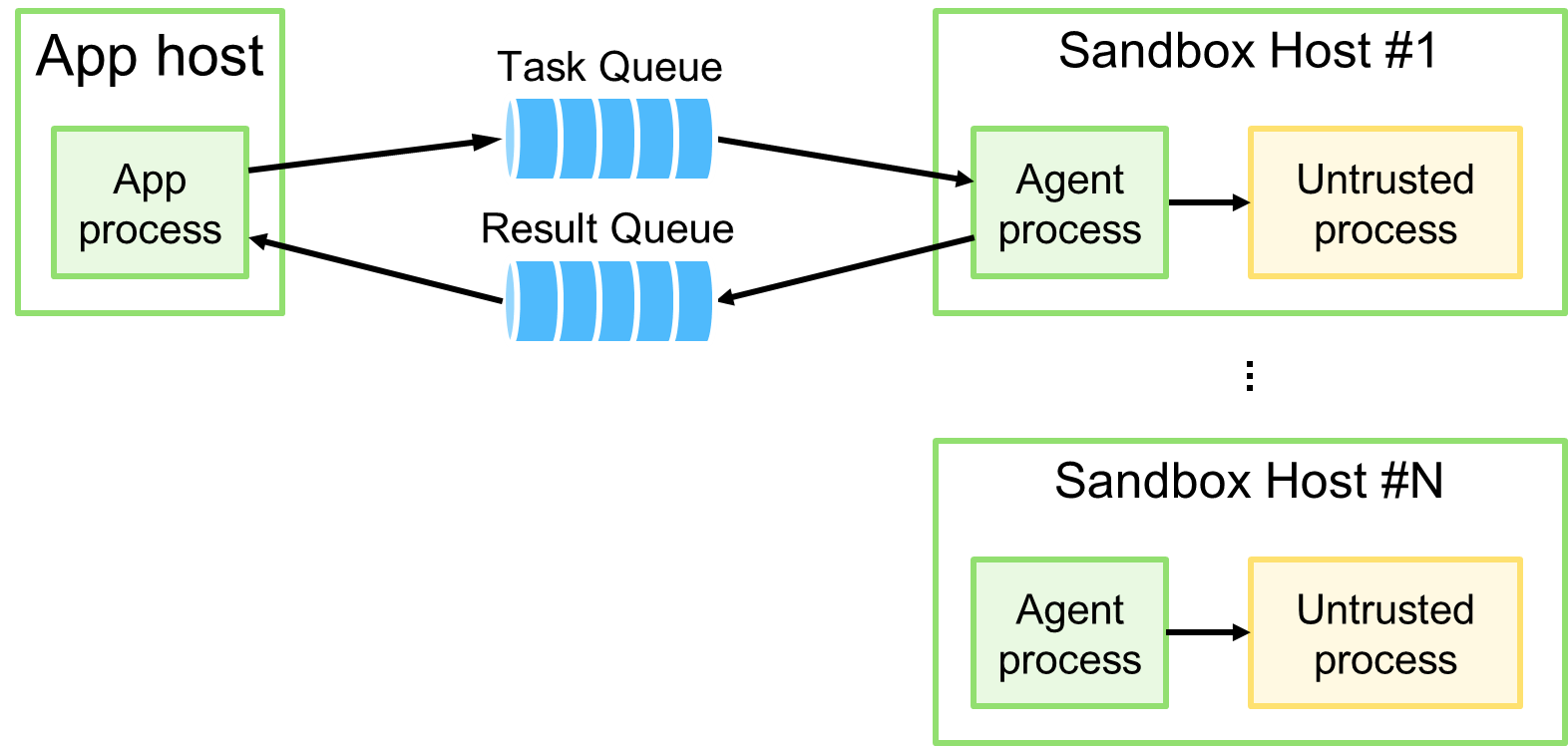
Основной недостаток самоорганизации — распределённый процесс обработки задач. Учитывая простоту алгоритма обработки, это не так существенно. Стоит отметить преимущества этой архитектуры.
- Максимальная изоляция ненадёжного кода. Ненадёжный код, как и в случае с оркестрацией, по-прежнему работает в песочнице в рамках отдельного процесса ОС.
- Скорость и стабильность взаимодействия. Никаких проблем с сетью из-за локальности взаимодействия между агентом и песочницей.
- Контролируемая нагрузка на песочницы. Агент, выступая в роли консюмера очереди задач, может точно контролировать степень параллелизма и выбирать новые задачи только тогда, когда он закончил обрабатывать предыдущие.
- Минимум инфраструктурного кода. Очереди избавляют от необходимости иметь оператор песочниц, отслеживать их состояние и осуществлять балансировку нагрузки.
- Простота масштабирования. Приложение и песочницы масштабируются независимо друг от друга без негативных побочных эффектов.
Запуск процесса ОС
К запуску процесса ОС, в рамках которого будет исполняться ненадёжный код, нужно подойти с особой осторожностью. Здесь важно ответить как минимум на три вопроса.
- Как ограничить права доступа к ресурсам. Самое простое решение — запуск процесса от имени пользователя с ограниченными правами (на доступ к ресурсам ОС).
- Как ограничить объем используемых ресурсов. Для запускаемого процесса нужно определить доступные ресурсы и возможные действия.
- Как осуществлять анализ поведения и результатов исполнения. Наличие и решение этой проблемы целиком и полностью зависит от специфики проекта. Здесь невозможно предложить универсального решения.
Рассмотрим варианты ограничения ресурсов процесса ОС.
Ограничение ресурсов процесса
Ресурсы процесса могут быть ограничены на трех уровнях:
- Лимиты узла. Физические ограничения машины, на которой исполняется процесс. В частном случае можно говорить об инфраструктурных лимитах, определённых для Docker/Kubernetes контейнера.
- Лимиты контейнера. Программные лимиты, задаваемые выбранным инструментом контейнеризации (cgroup, Docker, Bubblewrap, ProcessSandbox и т.п.).
- Лимиты процесса. Программные лимиты, задаваемые средствами ОС. На этом уровне можно осуществлять гибкую настройку вариантов запуска и исполнения.
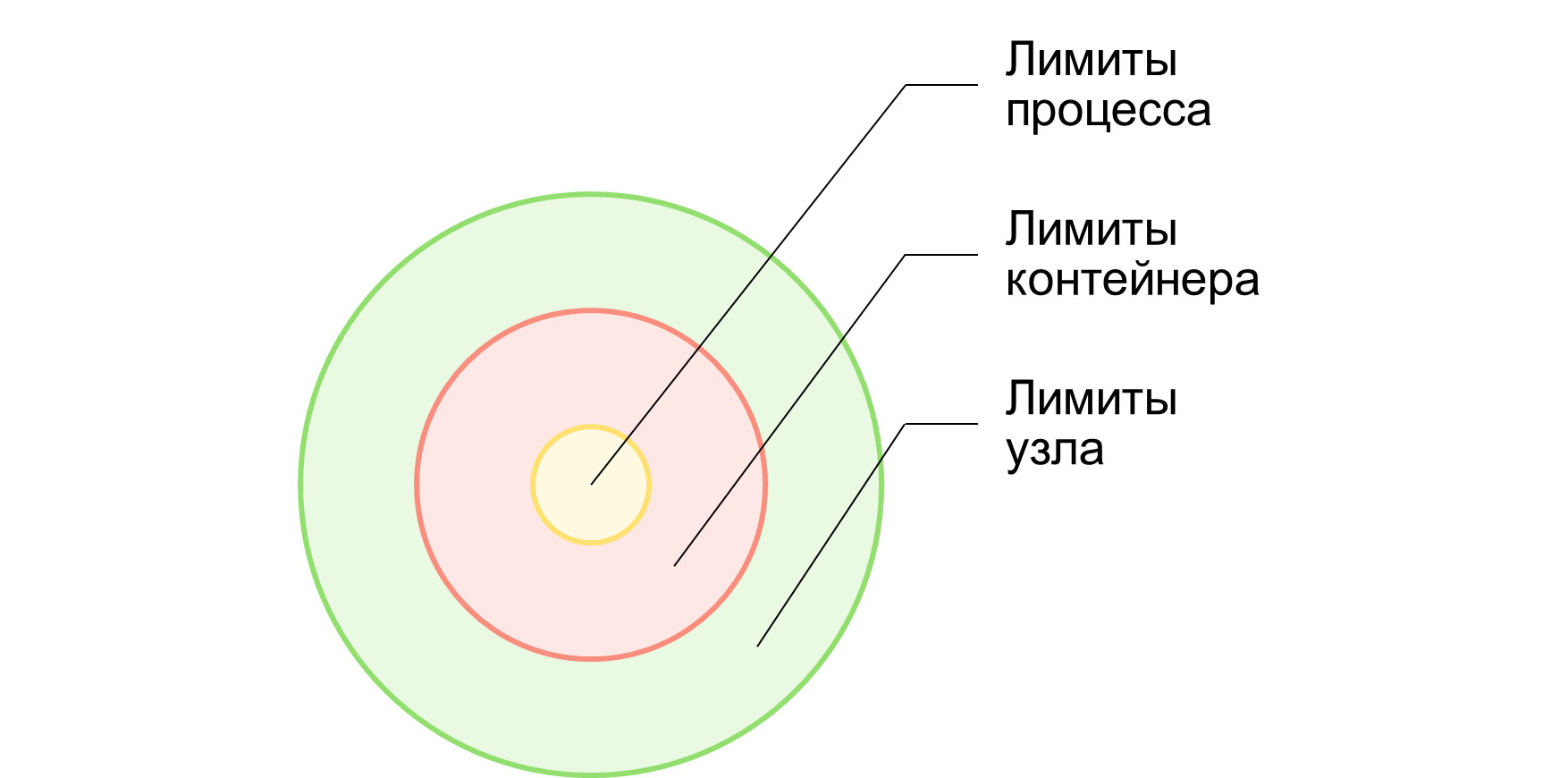
Можно использовать все три уровня лимитирования, либо какой-то определенный.
Между тем, важно отметить некоторые трудности, которые могут возникнуть при использовании инструментов контейнеризации.
Например, для использования cgroup или Docker внутри Kubernetes-контейнера нужно эскалировать привилегии контейнера, что в общем случае небезопасно в контексте исполнения ненадёжного кода. Более того, практика показала, что легковесных rootless-средств, предоставляемых ОС, вполне достаточно, чтобы снять большую часть рисков. В частности, Linux API позволяет не только лимитировать CPU и память, но и блокировать доступ к некоторым возможностям самой ОС. Например, можно наложить фильтр, который запретит вызов определённых системных функций.
Проблемы жёсткого лимитирования
Рассмотренные выше способы лимитирования задают жёсткие границы (hard limit), нарушение которых замедляет исполнение процесса, либо приводит к его принудительному завершению. При этом поведение наблюдаемого процесса и системы сильно варьируется в зависимости от того, какой лимит был превышен. Например, превышение по использованию CPU может привести к троттлингу (throttling), приостановке работы или принудительному завершению; превышение по использованию памяти заканчивается принудительным завершением со стороны ОС (OOM Killer) либо самостоятельным падением процесса (с ошибкой Out Of Memory).
Подобная вариативность осложняет анализ поведения и результатов исполнения. В этом случае можно использовать подход с программной мягкой границей (watchdog limit). Суть заключается в запуске дополнительного следящего потока (или процесса) ОС, который контролирует поведение и расход ресурсов у наблюдаемого. Как только детектируется превышение одного из лимитов, производится принудительное завершение наблюдаемого процесса, но уже не со стороны ОС, а со стороны приложения.
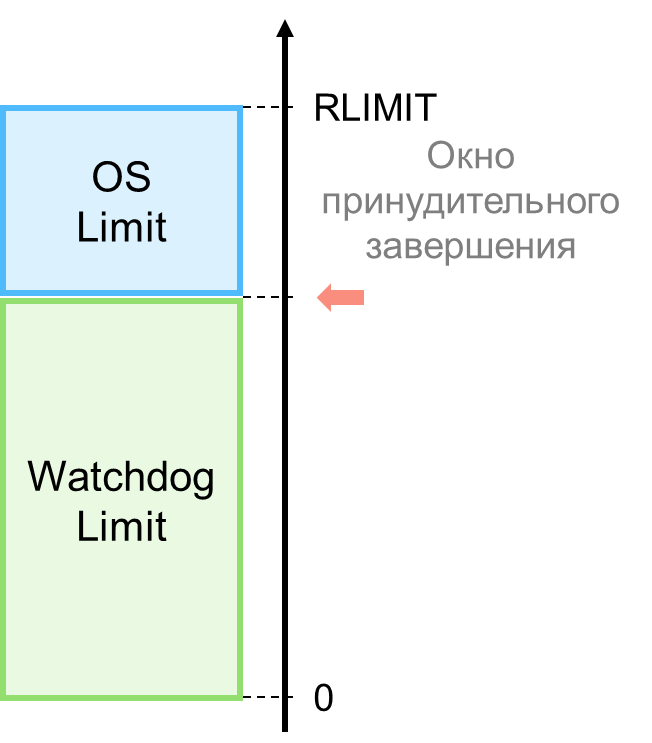
Такой подход имеет несколько преимуществ.
- Точное определение причин принудительного завершения. Жёсткие лимиты чуть выше мягких, благодаря чему для исполняемого кода создаётся иллюзия отсутствия каких-либо лимитов. Между тем, если лимиты всё-таки нарушаются, процесс всё равно будет завершен (либо со стороны приложения, либо гарантированно со стороны ОС). Но подобный дополнительный контроль со стороны приложения оставляет для него гораздо больше шансов понять причину принудительного завершения наблюдаемого процесса.
- Возможность гибкого лимитирования ресурсов. Приложение (или агент), ответственное за запуск наблюдаемого процесса, может обратиться к средствам ОС (в частности, к Linux API) и гибко настроить параметры запуска и исполнения. Как минимум, жёстко определить лимиты по CPU и памяти; наложить ограничения на объем I/O; создать запрет на вызов некоторых системных функций (например, запрет использования сетевых операций или файловой системы) и т.п.
Такой подход я назвал watchdog и в целях иллюстрации реализовал его в виде .NET-библиотеки ProcessSandbox. Помимо прочего, на странице проекта подробно рассмотрена проблематика контроля и анализа поведения процесса ОС со стороны прикладного кода.
Итоговая схема лимитирования может выглядеть так, как показано на рисунке ниже. Вместо тяжеловесных инструментов контейнеризации используется легковесный rootless-инструмент (watchdog) на базе средств ОС и только.
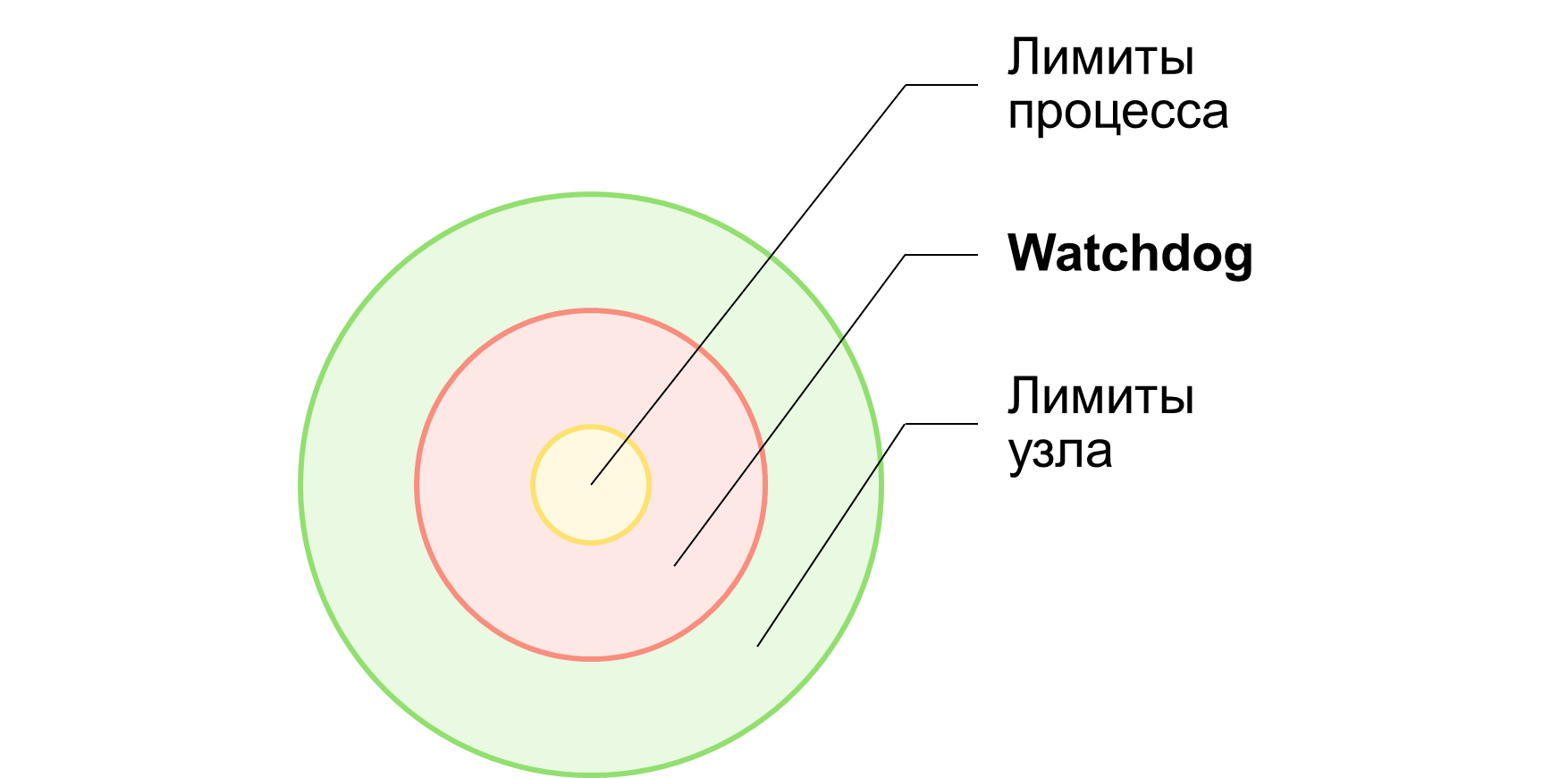
Для задач, где не нужен анализ поведения процесса и тонкая настройка лимитов, можно воспользоваться готовым инструментом — утилитой.
Многоконтейнерные поды
Зная, что контейнеры одного Kubernetes-пода работают на одном и том же узле, можно попытаться решить проблему нестабильности сетевого взаимодействия приложения и песочницы, разместив их контейнеры в одном поде.
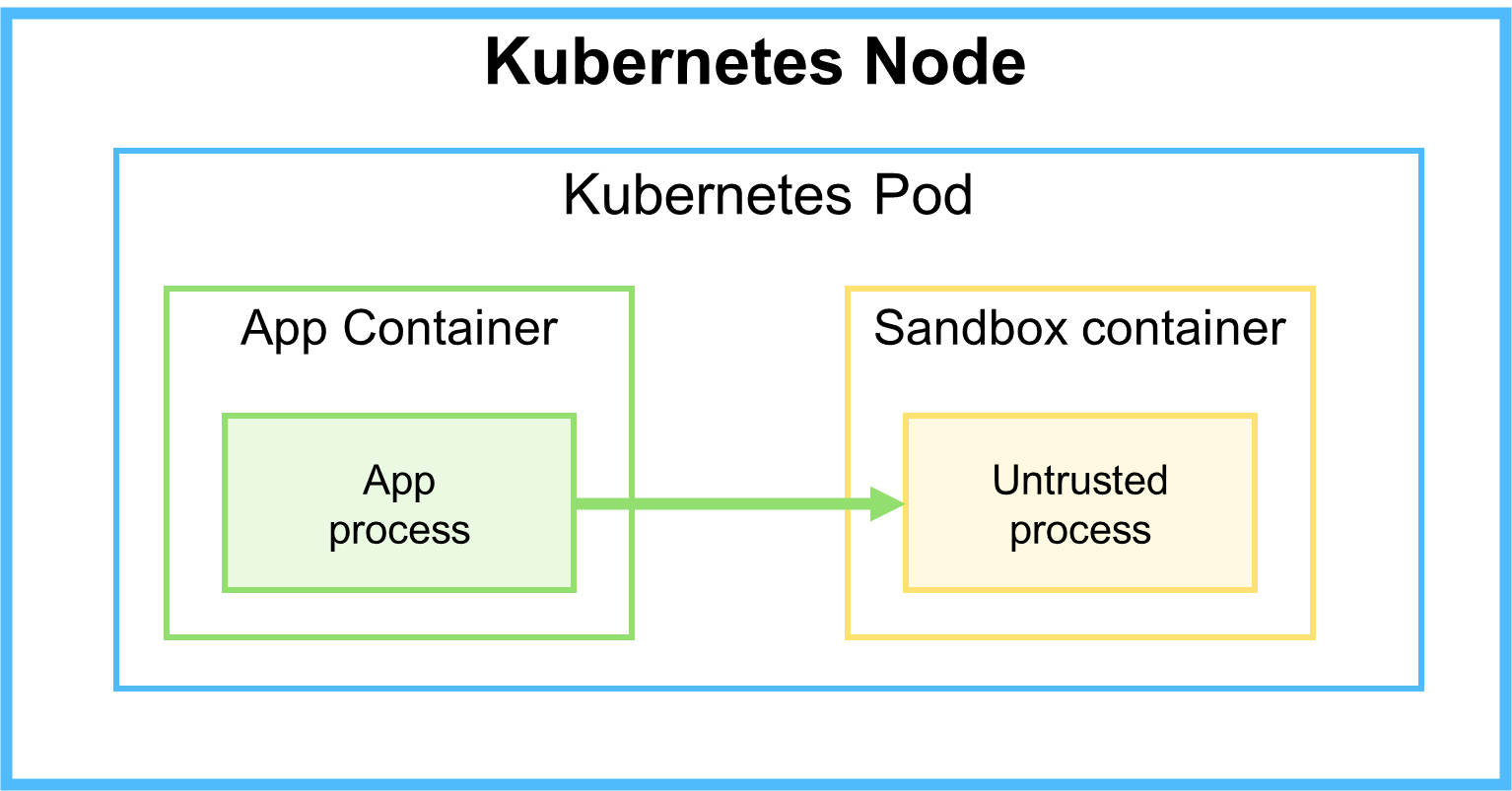
Несмотря на всю заманчивость данной идеи, она несёт ряд недостатков.
- Плохая масштабируемость. Соотношение приложение-песочница всегда один к одному. Однако не исключено, что в некоторых случаях это вполне приемлемо.
- Плохая утилизация ресурсов. Сможет ли приложение достаточно нагрузить песочницу, если количество песочниц будет в избытке; и наоборот, нужно ли столько же экземпляров приложения, сколько и песочниц.
- Возможность перегрузки песочницы. В распоряжении экземпляра приложения только одна песочница, которая может не справиться с потоком задач, обрабатываемых приложением.
- Риск нарушить работоспособность приложения. Выход песочницы из строя скорее всего приведет к перезапуску всего пода. Более того, если приложение и песочница обмениваются файлами через общий раздел (shared volume), это может стать уязвимым местом.
Образ для песочницы
Основные моменты, которые следует учесть при создании (Docker) образов песочниц:
- Заменить init-процесс на tini, чтобы не превысить лимит по PIDs.
- Создать непривилегированного пользователя, ограничив ему права на доступ к ресурсам.
- Регулярно сканировать версии образов и пакетов на наличие уязвимостей.
Инфраструктура исполнения
Основные моменты, которые следует учесть при настройке инфраструктуры исполнения:
- Обеспечить быстрый (пере)запуск песочниц. Нужно быть готовым к тому, что песочницы будут падать. Если речь идет о Kubernetes, то улучшить время запуска может подходящая настройка Image Pull Policy. При этом лучше не использовать тег `latest`, а указывать конкретную версию или хэш-код образа, чтобы не тратить время на попытки определения последней версии при каждом запуске.
- Установить приемлемый лимит на PIDs. Необходимо контролировать число активных процессов в системе. Особо вредоносный код может попытаться создать очень много дочерних процессов, поэтому при отсутствии лимита на PIDs узел быстро будет выведен из строя. Важно отметить, что лимит задаётся для пользователя, а не для запускаемого процесса. По этой причине он должен быть разумно большим.
- Установить лимиты на ресурсы узла. В Kubernetes для каждого контейнера нужно указать, как минимум, лимиты по CPU и памяти. Значения лимитов лучше всего определить в ходе нагрузочного тестирования или путём сбора метрик приложения.
Заключение
Как можно заметить, задача исполнения ненадёжного кода всегда решается в комплексе, начиная с анализа, продолжая разработкой и заканчивая вопросами уровня DevOps. Думаю, что многие техники и инструменты применимы и к коду самого приложения.
Я постарался показать последовательность шагов по направлению к целевой архитектуре, которая будет отвечать требованиям бизнеса и справляться с ненадёжным кодом. Если вам интересна данная тематика, подписывайтесь на мой Telegram-канал Архитектоника в ИТ (@arch_and_dev). Буду рад поделиться опытом.

372 открытий6К показов

Какие требования аналитика и клиента могут не совпасть на этапе разработки сайта. Почему излишние хотелки могут перегрузить сайт. На что стоит обратить внимание при разработке.

Популярные фреймворки для веб-разработки. Показываем основные виды фреймворков. Рассматриваем пошаговую инструкцию по использованию ✔ Tproger

Подборка лучших Telegram-каналов для DevOps: разборы реальных инцидентов, практика, новости облаков и контейнеризации. Источники, которые экономят время и помогают расти профессионально.

Как выучить SQL с нуля в 2025? Сравниваем 6 платформ: SYNC STUDY, SQL Academy, Karpov Courses и другие. Бесплатные и платные курсы, задачи из реальной аналитики, поддержка PostgreSQL. Советы по выбору для новичков и профессионалов.