


Что такое RAG: почему о нём говорят все ML-инженеры, с чего начать и что простое можно сделать


RAG стал настоящим трендом среди ML-инженеров — и не зря. Он позволяет моделям не просто генерировать текст, а опираться на актуальные документы, инструкции и базы знаний. Это снижает количество «галлюцинаций» и делает ответы точными. Рассказываем, как он работает, чем отличается от обычной языковой модели, как собрать простой RAG-пайплайн и использовать его в своих проектах.
2К открытий5К показов

Зачем нужен RAG
Retrieval-Augmented Generation — это генерация, дополненная поиском. Перед тем, как ответить, модель идёт в базу знаний, вытаскивает нужные фрагменты, и формулирует ответ на их основе. Иными словами, вы даёте модели шпаргалку с актуальным контекстом, поэтому она отвечает точнее, опираясь на факты из ваших источников, а не на общие знания из обучения.
Представьте, что у вас онбординг нового сотрудника. Он умён, но не следит за новостями, не знает о новых проектах и ситуации в компании, зато отвечает с полной уверенностью, даже если ошибается. Если же дать ему внутренние документы и инструкции, сотрудник будет действовать строго по ним. RAG превращает модель в умного помощника, который знает контекст именно вашей компании или проекта.
RAG — это идеальная основа для персональной поисковой системы, чат-ботов с ответами на типовые вопросы, ИИ-консультантов на сайте и агентов, которым нужна не общая информация из интернета, а конкретные данные и внутренняя база знаний.
Как устроен RAG: пайплайн и компоненты
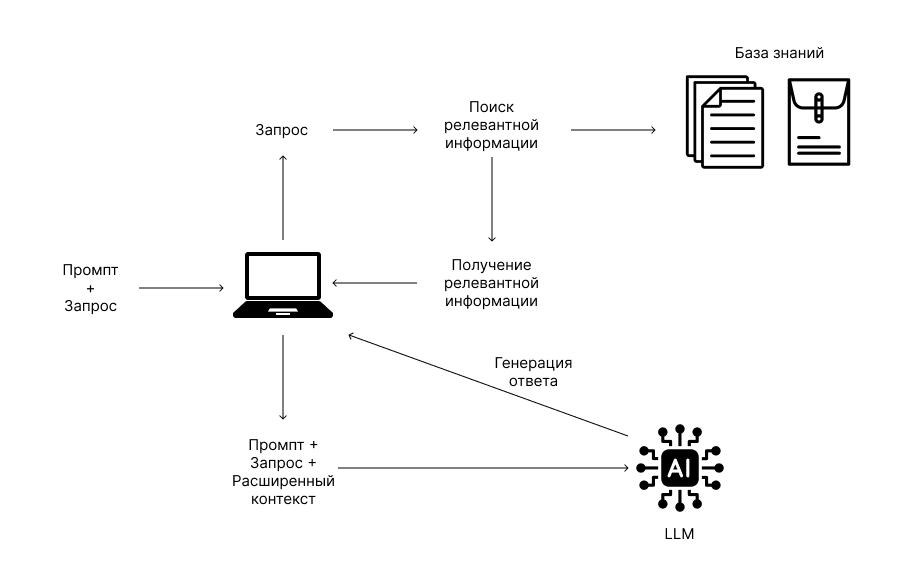
- Сначала готовим данные — всё то, чего нет в обучающих данных модели: документация, отчёты, письма, базы знаний, PDF и т.д. Чтобы RAG заработал, большие тексты нужно превратить в удобные для LLM-модели кусочки. На этапе индексации документы делятся на чанки — небольшие фрагменты: абзацы или предложения. Каждый чанк конвертируется в эмбеддинг — вектор, где зашит его смысл. Эти фрагменты собираются в специальное векторное хранилище — библиотеку знаний, которую может воспринять языковая модель.
- Следующий этап (retrieval) — поиск релевантных документов. Когда пользователь вводит запрос, система тоже превращает этот запрос в вектор и ищет в базе похожие по смыслу фрагменты.
- Далее модель подставляет найденную информацию к запросу пользователя (augmentation). Результат с дополнительным контекстом из базы подается на вход LLM, чтобы она отвечала с опорой на конкретные данные.
- Финальный этап — генерация (generation). LLM генерирует ответ, опираясь на информацию из найденных фрагментов и исходный запрос. Иногда к этому этапу добавляют проверку и проставление ссылок на источники — документы из базы, которые использовались для ответа.
Чем RAG отличается от обычной LLM

Доступ к актуальным данным. По умолчанию LLM общего характера знает только то, чему её успели научить, и не в курсе, что изменилось в мире после последнего апдейта. Она создана, чтобы решать широкий круг задач, но не имеет доступа к вашим документам, внутренней wiki или руководствам, которые не опубликованы в интернете.
Контроль над источниками. RAG помогает модели не фантазировать и не сыпать общими фразами, а опираться на реальные данные. Вместо абстрактных ответов из чертогов нейросетевого разума — ссылка на конкретный документ из вашей базы. Так вы всегда понимаете, откуда взялась информация, и можете ей доверять.
Меньше галлюцинаций. Когда LLM не находит ответ в своих обучающих данных, она может «выдумывать» факты, чтобы выдать хоть какой-то ответ и угодить пользователю. С RAG это случается намного реже — модель опирается на реальные документы, а не на догадки.

Конфиденциальность. RAG можно запускать на open-source моделях. Все корпоративные документы остаются внутри вашей инфраструктуры, и нет необходимости загружать их на сервера сторонних компаний. Модель будет обращаться к ним локально или через безопасный внутренний сервер.
Гибкость в специализированных задачах. RAG легко адаптировать под конкретную область: просто добавьте нужные документы и инструкции в базу знаний. Модель начнёт решать специфические задачи, не требуя дорогого дообучения.
Быстрое обновление. Не нужно заново переобучать LLM при каждом изменении данных. Достаточно обновить документы и проиндексировать их в базе знаний, и модель сразу начнёт работать с актуальной информацией.
RAG vs файнтюн
Fine-tuning (тонкая настройка) — это процесс, при котором уже обученную языковую модель дополнительно обучают на новых примерах, чтобы она изменила своё поведение и лучше справлялась с конкретной задачей, стилем или областью знаний.
Многие бегут дообучать свои модели, хотя это нужно не для всех задач. Fine-tuning — дорогой процесс: необходимы качественные данные, вычислительные ресурсы и люди, которые знают, как его делать. Выбирайте файнтюн, если нужно перестроить «мышление» модели: заставить говорить нужным тоном, погрузить во внутренние процессы компании или решить задачи специфическим способом, который уже был определён в примерах.
Сегодня LLM могут входить в курс дела «на лету» — на основе переданного контекста и хорошо сформулированных инструкций. Если вы снабдите модель нужной информацией в промпте, она сможет разобраться в новой для себя области без дообучения. Для этого подходят модели с большим контекстом (например, от Google или Qwen) и тщательно продуманный промпт.
Для стартапов и пилотов, особенно когда данные постоянно меняются — берите RAG и подгружайте документы или их фрагменты в контекст модели. В отличие от файнтюна, RAG может настроить обычный инженер: понадобится лишь пара библиотек и несколько дней на разбор документации и примеров. Кроме того, есть готовые сервисы, которые берут на себя часть задач по обработке данных. Например, у Cloud.ru есть решение, где достаточно закинуть свои документы, чтобы получать релевантные фрагменты по запросу.
С чего начать новичку
Совет эксперта: Даниил Соловьев, разработчик X5 Tech, рекомендует новичкам начать с его бесплатного курса на Stepik со всеми основами и практическими примерами и обратить внимание на свежие книги и статьи по теме RAG:
📘 RAG-Driven Generative AI with LlamaIndex — Amazon
Автор: Denis Rothman. Практическое руководство по созданию RAG-систем с использованием фреймворков LlamaIndex, Deep Lake и Pinecone.
📗 AI Engineering: Building Applications with Foundation Models — Amazon
Автор: Chip Huyen. Хорошо структурированное руководство по основным аспектам создания систем генеративного ИИ.
📝 Retrieval-Augmented Generation for Large Language Models: A Survey — ArXiv
Авторы: Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Meng Wang, Haofen Wang. Обзор эволюции RAG-подходов, компонентов и методов оценки.
И ещё несколько ресурсов от Tproger, чтобы закрепить знания и сразу попробовать реализовать идеи на практике:
- Введение в RAG от Microsoft.
- Руководство от Mistral.
- Руководство от Google по RAG-агентам.
- MTEB — бенчмарк для эмбеддинговых моделей.
- RTEB (beta) — LLM-бенчмарк на извлечение информации.
- GitHub — NirDiamant/RAG_Techniques — репозиторий с расширенными методами RAG.
- Code a simple RAG from scratch — хорошая статья для новичков, которая помогает понять структуру RAG.
- YouTube: RAG Fundamentals and Advanced Techniques – Full Course — основы RAG от freeCodeCamp.org.
Что учесть при внедрении RAG
1. Подготовка данных. Начните вычитывать и удалять противоречия и неточности в своей базе знаний. Золотое правило ML — «garbage in, garbage out»: если данные плохие, LLM не сможет хорошо отвечать. Если данных нет или они настолько запутанные, что в них потеряется даже человек — RAG не поможет.
Иногда оказывается, что вся документация умещается на пять страниц. Такой объём легко помещается в системный промпт модели, и качество ответов может быть даже лучше. Многие провайдеры LLM (OpenAI, Anthropic) позволяют кэшировать префикс промпта. За счёт этого при каждом запросе модель не проводит вычисления заново — ответ приходит быстрее и стоит дешевле. Но важно помнить: чем больше данных передаётся в промпт, тем дольше и дороже становится ответ. Поэтому RAG имеет смысл тогда, когда данных слишком много, чтобы передавать их в промпте.
2. Валидация ответов. Чтобы проверить, насколько хорошо работают разные подходы, обычно делают «золотой датасет» — набор примеров. Он состоит из пар: запрос пользователя и эталонный ответ, который заранее пишет эксперт на основе документов. На таком наборе можно сравнить разные варианты RAG и выбрать тот, что справляется лучше остальных.
Источников и документов может быть сколько угодно — главное, их качество. Методы поиска, такие как векторный поиск или поиск по ключевым словам, хорошо справляются даже с большими объёмами. Векторный поиск использует алгоритмы приближённого поиска (ANN), которые специально созданы, чтобы размер базы знаний почти не влиял на скорость.
Когда RAG не подойдёт
Он не нужен там, где дополнительные данные просто не приносят ценности. Обычно это простые prompt-based приложения, где достаточно статического системного промпта. Например, ранние GPT-приложения просто генерировали 10 идей или переписывали текст в заданном стиле. Дополнительные данные при этом не нужны, а хорошие примеры (few-shot) можно просто вставить в системный промпт.
RAG — это подход к решению фундаментальной проблемы LLM: модель ограничена знаниями на момент обучения и может ошибаться в точных фактах, которые берёт из своей внутренней памяти. Если в проекте нет этих проблем — RAG вам не нужен.
Подборка полезных туториалов
- LangChain — Q&A на RAG: создаём чат-бота, который отвечает на вопросы по твоим данным.
- Python + ChromaDB + Ollama: подключаем поиск по своим заметкам к LLM.
- LangChain FAQ на SQL: спрашиваешь про базу данных — получаешь ответ на человеческом языке.
- Secure Telegram Bot for Article Q&A: Telegram-бот, который отвечает на вопросы по статьям.
- Telegram Customer Service Bot (GPT-4 + Pinecone): Telegram-бот для общения с клиентами.
- PDF-Based RAG (OpenAI + Pinecone + Cohere): воркфлоу для n8n — бот, который отвечает по содержимому PDF-документов.
- RAG Chatbot для Confluence (Chainlit + pgvector): ищет ответы в документации прямо в Confluence.
- Intelligent Report Generator (Hybrid RAG): бот для автоматической генерации отчётов с проверкой и исправлением.
- Базовый RAG: воркшоп «сделай свой поисковик на LLM» от магистратуры AI Talent Hub.
- Автопарсинг для RAG (LlamaIndex): за 5 минут формируем базу знаний с контекстом, готовую к RAG.

2К открытий5К показов

В России запустили бесконтактную оплату iPhone через Bluetooth в приложении Сбера — первый аналог Apple Pay, работающий без NFC и интернета
Составили мини-дайджест из 5 новостей о ChatGPT: Microsoft инвестировал $10 млрд в OpenAI, а Google ищет конкурентный ответ ChatGPT.

Microsoft добавила видеогенератор Sora в Bing — теперь любой пользователь может бесплатно создавать короткие ролики прямо в мобильном приложении

Стартует турнир за звание лучшего языка программирования в 2023 году среди читателей Tproger. Кто же победит в этом году?