


Дашборд тестировщика, или Как мы собираем метрики в отделе тестирования
В этой статье рассказываем, как мы измеряем эффективность тестирования, какие метрики собираем и какие это приносит результаты.
3К открытий7К показов
В ЮMoney большой отдел тестирования — в нём почти 80 человек, которые каждый день проверяют качество продуктов и сервисов. В этой статье рассказываем, как мы измеряем эффективность тестирования, какие метрики собираем и какие это приносит результаты.
Чтобы пообщаться с 80 сотрудниками, руководителю отдела тестирования нужно 40 часов
Руководитель должен контролировать работу своего отдела, следить за процессами, понимать, где не хватает ресурсов, а где их с избытком. Для этого раз в две недели (спринт) ему нужно пообщаться с каждым тестировщиком, и одна такая встреча длится примерно 30 минут. Соответственно, чем больше отдел, тем больше времени руководитель на это тратит.
Раньше, когда в команде тестировщиков было пять человек, на такие встречи уходило 2,5 часа. Но теперь, когда отдел вырос до 80 человек, чтобы поговорить с каждым, руководителю нужно потратить 40 часов. А это целая рабочая неделя.

Как адекватно оценить обстановку в командах и отделе при такой загрузке руководителя? Нужно делегировать задачи и автоматизировать процессы.
Кто такие кураторы в отделе тестирования и чем они занимаются
Руководитель передаёт часть своих полномочий тестировщикам с лидерскими качествами — они становятся кураторами. Куратор — это старший или ведущий сотрудник отдела, который сопровождает тестировщиков из продуктовых команд:
- проводит с ними встречи каждый спринт;
- обсуждает насущные проблемы;
- помогает решать текущие задачи;
- организует персональные ревью;
- контролирует процесс, чтобы был баланс между временем тестирования и его качеством.
Кураторы у нас, как правило, из смежных продуктовых команд. Мы уже рассказывали об этом подробно.
Чтобы можно было быстро количественно оценивать состояние тестирования, мы начали собирать метрики. Это стало хорошей отправной точкой, чтобы начать обсуждать спринт с командой.
Какие метрики мы собираем
Поначалу мы опасались, что тестировщики не захотят, чтобы их работу оценивали с помощью каких-то общих алгоритмов. Но нам удалось объяснить команде, что метрики нужны не для санкций и штрафов. Они необходимы, чтобы:
- понимать текущее положение дел;
- своевременно выявлять и решать проблемы;
- отслеживать тенденции — улучшаются ли процессы со временем или ухудшаются;
- повышать качество тестирования продуктов.
Тестирование — важный шлюз на пути фичи к пользователю. Не хотелось бы, чтобы этот шлюз тормозил выкладку фичи на прод. Поэтому время тестирования должно постоянно сокращаться. Чем быстрее фича «доезжает» до пользователя, тем больше денег можно заработать. Поэтому в первую очередь мы решили сделать акцент на времени тестирования — сократить его без потери качества.
В каждой продуктовой команде стали собирать такие метрики:
- Testing Speed (TS) — отношение количества протестированных задач к количеству задач, переданных в тестирование за один спринт. Считается по формуле:
TS = Count (протестированные задачи) / Count (задачи, переданные в тестирование)
- Tasks Without Testing (TWT) — задачи без тестирования, когда разработчик перетаскивает таск на продакшн в обход тестирования, что повышает риск багов на проде.
- Production Found Defects (PFD) — инциденты на проде, когда пользователи сами находят баги в продуктах и приносят их в техподдержку.
- Integration Found Defects (IFD) — дефекты, которые нашли на этапе приёмочного тестирования релиза автотестами. Тут выделили ещё три дополнительные метрики:
- Test-cases — количество тест-кейсов;
- Autotests — количество автотестов;
- Coverage — отношение Autotests к Test-cases.
- Test Duration (TD) — среднее время тестирования задач. Посчитать его можно по формуле:
Общее время, которое все задачи провели в тестировании / Общее количество задач
Для всех метрик мы сделали цветовую индикацию — светофор.

Значение цветов:
- Зелёный — всё хорошо.
- Жёлтый — скоро всё будет плохо, но пока нормально.
- Красный — уже вчера пора было вмешаться.
Мы определили для себя, что если на тестирование одной фичи уходит меньше двух дней, то это нас устраивает. Если средний показатель метрики Test Duration не выходит за эти рамки, значит, в команде со временем тестирования всё хорошо, Time to Market не страдает и все довольны скоростью.
Но не все метрики мы оцениваем светофором. Иногда сложно сказать, какое количество тест-кейсов для команды считается хорошим. У всех команд разное количество бизнес-процессов и приложений, которые они развивают и поддерживают. Такие метрики мы окрашиваем в серый цвет и обращаем больше внимания на то, как они меняются со временем.
Первые результаты команды тестирования после внедрения светофора
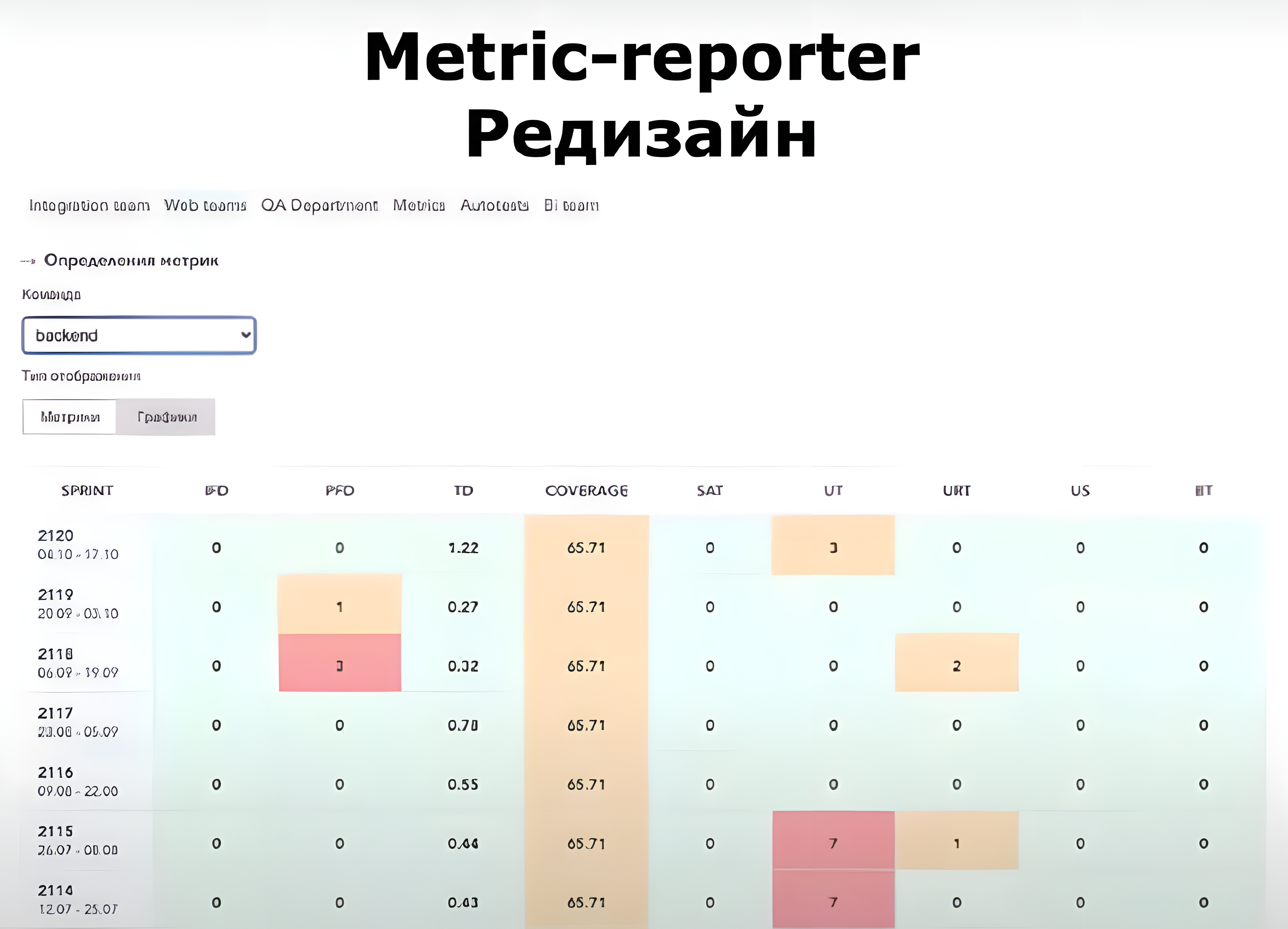
Для каждой продуктовой команды мы сделали такую таблицу:
В верхней части видно, что большинство ячеек в таблице для этой конкретной команды — красные. Подобную картину мы увидели в нескольких командах отдела тестирования. С этим надо было что-то делать.
Как мы проработали красные зоны
- Провели ротацию в некоторых продуктовых командах.
- Начали оценивать тестирование при планировании спринта.
- Изменили флоу работы с задачами — чтобы разработчик не мог протолкнуть задачу в продакшн без тестирования.
- Сделали акцент на написание автотестов. Это дорогой и трудоёмкий процесс. Мы вложили много ресурсов в то, чтобы начать писать автотесты, провели внутреннюю школу автоматизации и школу код-ревью, разными способами мотивировали тестировщиков писать автотесты.
В итоге мы улучшили скорость тестирования в отделе, и метрики позеленели:
Но ещё было над чем работать.
Почему мы пересмотрели метрики: убрали одни и добавили другие
За метриками нужно постоянно следить. Не получится просто добавить несколько штук и забыть о них. И надо понимать, что не всегда новая метрика принесёт пользу. Бывает, через некоторое время ты понимаешь, что она не даёт необходимой информации. Такие метрики нужно беспощадно удалять и искать альтернативу. Иначе будет много «мусорных» метрик, с которыми невозможно работать.
Мы убрали метрики, которые не давали нам полезной информации. Это Testing Speed и Tasks Without Testing. Вместо них мы добавили другие, на которые ориентируемся до сих пор:
- Unstable Tests (UT) — количество нестабильных автотестов (тех, у которых Success Rate за две недели был ниже 70%).
- Bad Tests (BT) — «плохие» автотесты, то есть те, которые три раза за месяц требовали ручного вмешательства на этапе приёмочного тестирования релиза автотестами. Такие автотесты сильно снижают Time To Market, за который мы боремся.
- Skipped Autotests (SA) — количество заблокированных автотестов, тех, которые по каким-то причинам не могут пройти приёмочное тестирование релиза из-за отключенных бизнес-процессов, багов в системе, неготовой инфраструктуры или из-за кода самого автотеста.
Мы регулярно пересматриваем и актуализируем свои метрики. Их развитие — эволюционный процесс. Каждый может предложить улучшить существующую метрику или добавить новую. Для нас это живой инструмент, на который может повлиять любой человек из QA или других отделов.
Но метрик может стать слишком много, и тогда на них перестанут обращать внимание. Поэтому, когда добавляете новую метрику, всегда задавайте следующие вопросы:
- С какой целью мы её добавляем?
- Что планируем делать, если она будет красной?
- Нет ли другой похожей метрики, которая будет дублировать информацию?
И так далее. Также не забывайте собирать обратную связь от пользователей этих метрик.
Метрики подсвечивают проблемы в отделе, но не показывают их причину и не подсказывают решение
Рассмотрим один из кейсов по работе с метриками в тестировании. Вот метрики одной из QA-команд за восемь спринтов. Очерёдность спринтов считаем сверху вниз:

В первом спринте года, с 7 по 20 января, значение метрики зелёное. Это значит, что всё было хорошо — задачи тестировали быстро.
В следующем спринте, с 21 января по 3 февраля, время тестирования задач резко увеличилось, метрика покраснела и очень долго приходила в норму. Случилось это из-за того, что самый опытный тестировщик на какое-то время выбыл из команды, а заменил его новичок, который долго адаптировался. К середине апреля метрика позеленела.
Это показывает, что метрики лишь подсвечивают проблему, но не отвечают на вопрос, почему она возникла и как её решить. С каждой проблемой нужно разбираться индивидуально, универсального решения для всех не существует.
Как мы автоматизировали процесс сбора метрик
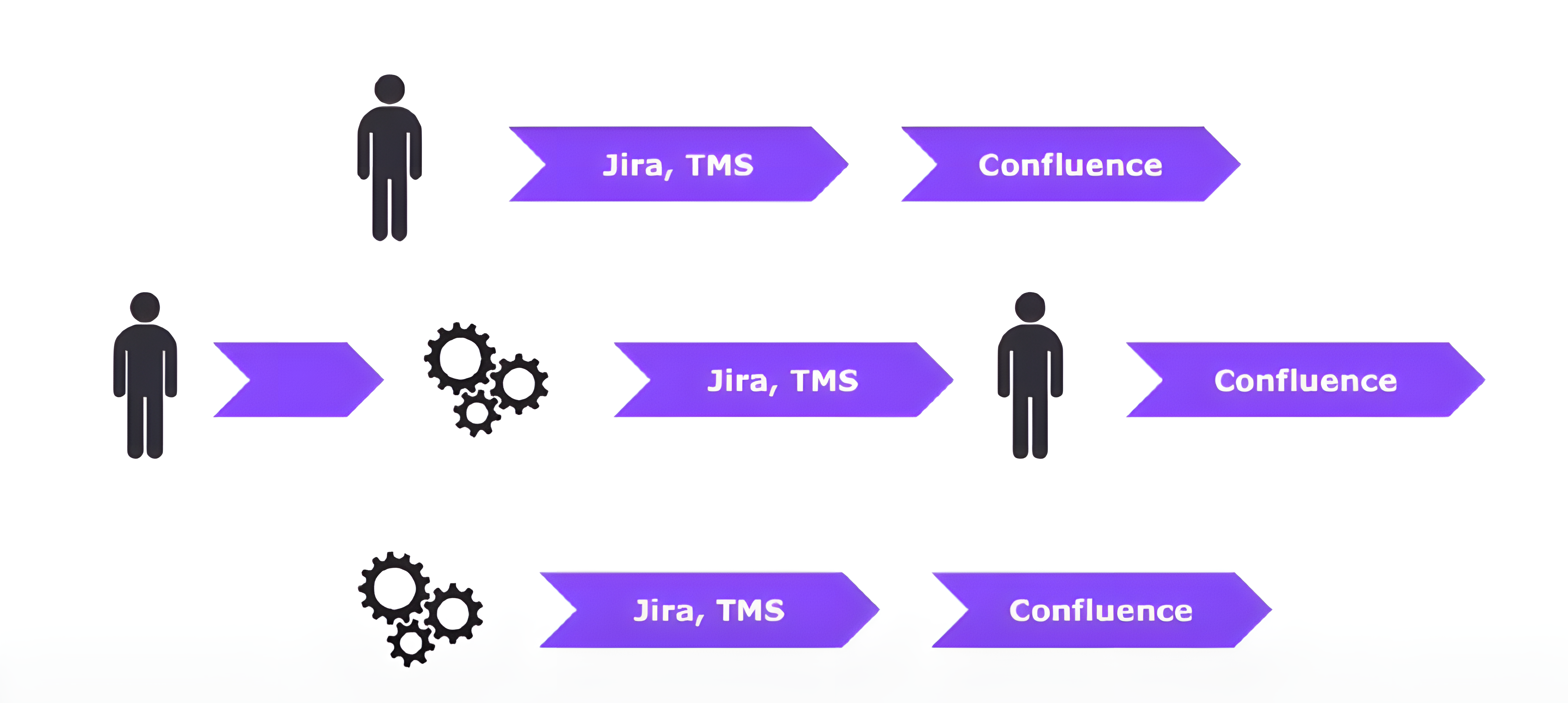
Когда мы запустили метрики в отделе тестирования, кураторы команд вручную собирали их по фильтрам из Jira и TMS и складывали в Confluence в таблицу. Через какое-то время, когда процесс устоялся и все к нему привыкли, мы решили его автоматизировать.
Сначала автоматизация была очень простой: мы подняли бэкенд-сервис и сделали один обработчик. При его вызове сервис шёл в Jira, обрабатывал данные и отдавал их в виде JSON. Куратор каждой команды раз в спринт открывал Postman, вызывал обработчик и перекладывал данные с JSON в Confluence.

Команде с такой автоматизацией стало полегче, но хотелось упростить её ещё больше. Тогда мы прикрутили к сервису базу данных, добавили клиент для работы с Confluence и начали складывать данные в Confluence автоматически по расписанию — раз в спринт, то есть в две недели.
Казалось бы: всё отлично, метрики собираем автоматически, их можно в любой момент посмотреть. Но была проблема — Confluence не покрывал все наши потребности.

Например, было сложно сравнивать несколько команд друг с другом. А когда данных накапливалось много, страницы долго загружались и тормозили. Мы подумали, что надо сделать свою визуализацию, потому что график в Confluence из коробки выглядел вот так:
У нас уже был опыт написания фронтенда в отделе тестирования, поэтому к готовому бэкенду прикрутили самописный UI, подобрав библиотеку для построения графиков. Новый сервис мы назвали Metric Reporter.
И наши метрики стали выглядеть так:

Через какое-то время мы с дизайнерами переработали внешний вид нового UI и добавили недостающую функциональность.
Мы подумали, что неплохо было бы работать с командой над метриками прямо в интерфейсе, поэтому добавили возможность комментировать отдельные метрики и спринты. Также добавили общие метрики по отделу из различных специализированных команд QA.
В итоге мы получили сервис, которым начал пользоваться не только руководитель, но и все коллеги из отдела тестирования. Мы смогли наблюдать за показателями и отслеживать сигналы, необходимые для анализа ситуации в команде и во всём отделе.
Почему самописный инструмент
Логично было бы взять какой-нибудь готовый инструмент визуализации метрик, например Grafana. Но:
- Grafana не покрывала все наши задачи. Например, там нет возможности комментировать.
- Cрок хранения данных в Grafana ограничен по времени, а нам нужно смотреть метрики с учётом длительных сроков.
- Своё решение легко кастомизировать под любые потребности. Особенно когда процессы постоянно развиваются и меняются.
Подведём итоги
Какие возможности дали нам метрики:
- Объективно оценивать, что происходит в командах.
- Своевременно выявлять и решать проблемы внутри отдела.
- Выявлять зависимости. Например, если сравнивать метрики год к году, то видно, как возрастает нагрузка на тестировщиков перед новым годом, когда команды хотят закрыть свои квартальные планы в срок.
- Следить за изменениями и трендами, например за внедрением новых процессов или технологий.
- Находить точки роста. Одни метрики зеленеют после того, как мы над ними поработали, мы пересматриваем их, выделяем другие. Находим новые проблемы и решаем их.
- Распределять ресурс тестирования по командам.

Это отзывы коллег из отдела тестирования, которые пользуются метриками. Они помогают им:
- Выполнять задачи.
- Мониторить процесс тестирования и визуально определять тот самый баланс между качеством и количеством.
- Улучшать процессы в отделе QA.
Если вы до сих пор не измеряете ваше тестирование, то действуйте. Метрики могут вскрыть проблемы, о которых вы даже не подозревали.
Как начать собирать метрики
- Выявите проблему, которую хотите мониторить.
- Соберите показатели, которые хотите считать.
- Разработайте формулу подсчёта и индикаторы для светофора.
- Поработайте с коллективом, продайте идею, что внедрить метрики — это круто.
- Получите и проанализируйте результаты.
- Проработайте красные зоны.
- Ищите новые точки роста — постоянно актуализируйте метрики.
Чтобы начать собирать метрики, не обязательно создавать сложную автоматизацию или пилить свои сервисы. Можно использовать любой инструмент, который умеет строить графики и таблицы. Начните с элементарного Excel или с Google-таблиц — через какое-то время вы точно заметите, что процесс тестирования улучшился.

3К открытий7К показов

Сергей Востриков, руководитель направления Маркетплейс и интеграции в Битрикс24, про фундаментальные механизмы зрелой AI-разработки.

Иван Некулицы, основатель PQ.Hosting, рассказывает, как организовать переезд на другой хостинг без рисков и простоев.

Узнайте, почему в Японии COBOL до сих пор основа экономики, на нём всё ещё учатся программировать и к чему привело использование такого старого языка.

Как отличить людей от ботов в A/B-тестах с помощью JavaScript и сделать результаты статистически честными.