


Добавляем Schema.org в Docusaurus для GEO

Как Pingera внедрила Schema.org в документацию Docusaurus с помощью swizzling. Технические детали, примеры кода и почему это важно для GEO — оптимизации под AI-поиск.
70 открытий1К показов

От SEO к GEO (Generative Engine Optimization)
Мы в Pingera, как и любая технически подкованная команда, постоянно работаем над улучшением наших инструментов и следим за тем, как наш контент индексируется поисковыми системами. Но после взрывного роста больших языковых моделей и ИИ инструментов правила игры изменились кардинально. Речь уже не только о классическом SEO (Search Engine Optimization), а о GEO — Generative Engine Optimization.
GEO — это оптимизация контента для того, чтобы он был максимально понятен и точно использовался генеративными AI-моделями. Наша техническая документация, расположенная на docs.pingera.ru и построенная на популярном фреймворке Docusaurus, — важный актив. Именно здесь инженеры находят ответы на вопросы об интеграциях, API и тонкостях мониторинга. Поэтому мы задались вопросом: как убедиться, что LLM-инструменты, такие как YandexGPT и Google Gemini, будут давать максимально точные ответы, ссылаясь на нашу документацию? Ведь при наличии AI Overview ответа от поисковика пользователи кликнут на ссылку всего в 8% случаев (даже если она первая).
Говорим с AI на его языке
Schema.org разметка перешла из разряда «неплохо бы иметь» в «обязательно, и вчера». Это не просто набор тегов для «красивых сниппетов» в поиске. Это семантический каркас, который даёт явные и недвусмысленные подсказки о смысле и структуре нашего контента.
Ключевые фигуры в индустрии прямо указывают на это:
- Fabrice Canel (Microsoft Bing): «Schema Markup помогает Large Language Models Microsoft понимать и интерпретировать контент веб‑страниц».
- Google Search Central: «Вы можете существенно помочь нашим системам, предоставив явные и недвусмысленные подсказки о значении и структуре страницы через включение структурированных данных».
Бенчмарк-исследование компании Data World показало, что LLM, основанные на Knowledge Graphs со структурированными данными, достигают уровня точности ответов на 300% выше по сравнению с моделями, работающими только с сырым текстом. Это трёхкратное превосходство в точности, которое невозможно игнорировать.
Для нас это стало сигналом: внедрение структурированных данных — это технический императив для обеспечения качества ответов об API и наших продуктах.
Как внедрить Schema.org в Docusaurus
Фреймворк Docusaurus не имеет встроенного гибкого механизма для генерации сложной JSON-LD разметки. Тут мы и расскажем, какие изменения нужны, чтобы разметка появилась.
Шаг 1. Глобальные Схемы: Organization и WebSite
Мы начали с добавления базовой информации о компании и сайте, используя массив headTags в файле docusaurus.config.js. Это самый простой способ внедрить статические глобальные схемы, которые описывают нашу организацию и сайт документации.
Шаг 2. Динамические Схемы: TechArticle и BreadcrumbList
Для создания схем, которые должны динамически меняться для каждой страницы (например, заголовок, URL, дата), мы использовали Swizzling — инструмент для кастомизации Docusaurus.
Оборачивание компонента DocItem: Мы запустили swizzle в режиме обертывания (wrap), чтобы не нарушать логику основного компонента:
- Это создало файл
src/theme/DocItem/index.js. - Реализация логики в
src/theme/DocItem/index.js: Внутри этого файла мы получаем метаданные страницы (metadata) иfrontMatterи используем их для генерации схемTechArticleиBreadcrumbList. - Схема
TechArticleдинамически заполняется заголовком, описанием, датой последнего обновления, явно указывая на технический тип контента. - Схема
BreadcrumbListгенерируется на основе пермалинка страницы, обеспечивая полный иерархический путь, который критически важен для LLM.
Шаг 3. Устраняем Дублирование: Удаление Дефолтных Хлебных Крошек
Docusaurus по умолчанию генерирует свою собственную JSON-LD для хлебных крошек, что приводит к дублированию и ошибкам валидации. Чтобы этого избежать, мы выполнили Eject компонента DocItem/Layout всё через тот же swizzle:
npm run swizzle @docusaurus/theme-classic DocItem/Layout -- --eject --danger
В файле src/theme/DocItem/Layout/index.js мы удалили импорт и рендеринг компонента DocBreadcrumbs. Это гарантировало, что в HTML страницы остаётся только наша кастомная схема BreadcrumbList.
Тестирование и проверка валидности
Для подтверждения корректности нашей реализации мы использовали два основных инструмента:
- Google Rich Results Test: Для проверки того, как Google видит наши структурированные данные и какие расширенные сниппеты он может сгенерировать.
- Schema Markup Validator: Основной инструмент для проверки синтаксической и семантической корректности JSON-LD разметки: https://validator.schema.org/.
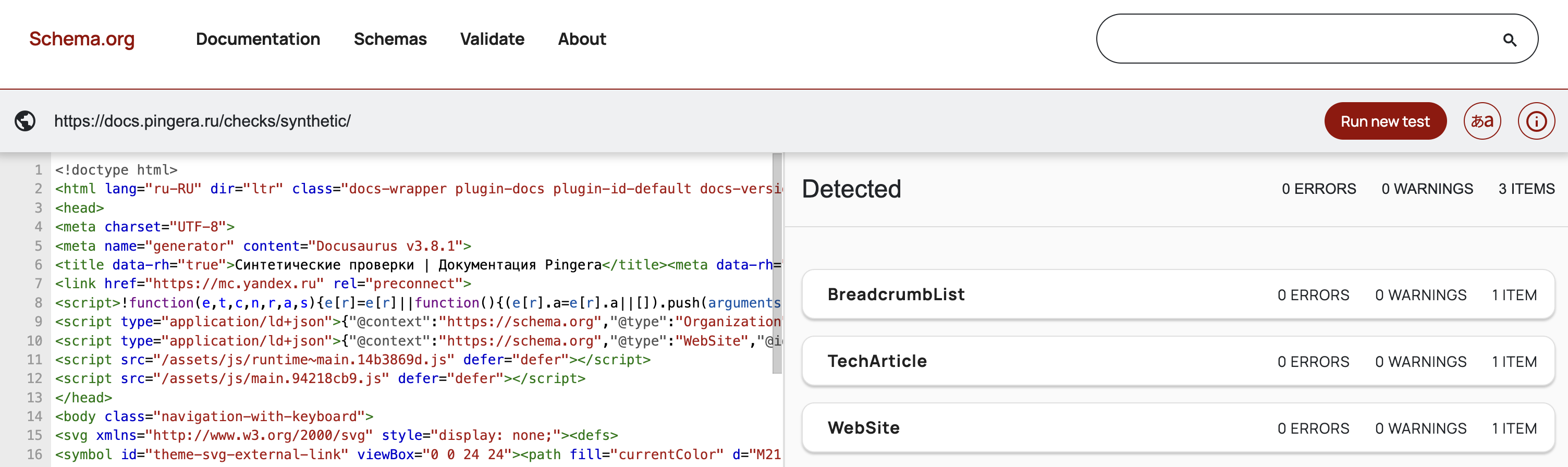
Результат и Преимущества
Пока ещё рано говорить о результате, но мы ожидаем следующего:
- Улучшенная Точность AI-ответов (GEO): Наш контент теперь имеет высокий приоритет и точность при формировании AI-ответов.
- Rich Snippets: Расширенные сниппеты с хлебными крошками и датами в результатах поиска улучшили CTR.
- Knowledge Graph: Схема Organization помогает Google отображать информацию о Pingera в панели знаний.
- Техническое Признание Контента: Схема TechArticle сигнализирует поисковым системам, что это специализированный, технический контент.
Заключение
Эпоха, когда SEO ограничивалось ключевыми словами, прошла. Сегодня успех контента в поиске зависит от его семантической чистоты. Schema.org — это не просто инструмент для маркетологов, а технический стандарт, который становится критически важным для каждого разработчика, отвечающего за документацию и качество контента.
Если вы используете Docusaurus или любую другую платформу для документации, не откладывайте внедрение структурированных данных. Ваша цель — не просто быть в поиске, а быть максимально понятным для искусственного интеллекта.

70 открытий1К показов

Фотореалистичный генератор изображений в ChatGPT стал доступен бесплатно, но в таком случае у OpenAI есть лимит в 3 запроса в день

Разработчики фиксируют всплеск неработающих ИИ-проектов: код медленный, сырой и опасный, а спрос на «очистку» и ручное ревью растёт

Американец подал более миллиона заявок на работу с помощью ИИ и получил лишь три оффера — алгоритмы не смогли обмануть друг друга

Duolingo запускает ИИ-видеозвонки для изучения языков на Android. Практикуйте разговорную речь с персонажем Лили через Duolingo Max