Гайд: как настроить API-распознавание документов за 30 минут
Рассказываю о том, как интегрировать распознавание документов за 30 минут — быстро и без головной боли.

Всем привет! Меня зовут Егор, я Python-разработчик, и часто взаимодействую с компаниями среднего и малого бизнеса в качестве внешнего подрядчика. Например, модернизирую CRM в стоматологических клиниках.
Один из последних запросов — прикрутить к CRM автоматическое распознавание паспорта РФ.
Проблематика: стоматологическая клиника заметила, что ручное «перепечатывание» паспортов создает очереди при регистрации пациентов.
Вы отлично понимаете, о чем я, если когда-то ждали в клинике договор на обслуживание перед самым началом приема врача.
Для тех, кто сталкивается с похожими задачами по оптимизации процессов, я написал этот гайд.
Начало: как выбирали распознавание
Поскольку остановились совершенно на конкретном решении российской компании, на его примере и расскажу, что и как делать.
С чем сравнивали: с другим облачным сервисом и SDK-решением для распознавания паспортов. Тестировал сам на открытых демо-стендах и смотрел сравнения в других источниках. Например, здесь.
Что хотел от сервиса заказчик:
- соотношение цена/качество
- функционал без излишеств (нормальные скорость и качество распознавания)
- простая тарификация для небольших объёмов, минимум общения с поставщиком
Что в итоге понравилось мне:
- интегрировал быстро, буквально ночью за чашкой кофе, оплатили вообще с карты
- документация просто и понятно составлена, есть swagger.
- минимум общения с поставщиком
Начало работы
Чтобы начать работу с API, надо зарегистрироваться в личном кабинете сервиса.
При регистрации начисляют небольшой баланс для бесплатного тестирования – на 25 распознаваний. По запросу дали ещё 50 распознаваний.
В личном кабинете нас интересует раздел «Распознавание». Выбираем интересующий тип документа (в нашем случае – паспорт РФ, первый разворот и регистрация), прикрепляем PDF c двумя разворотами паспорта и начинаем распознавание.
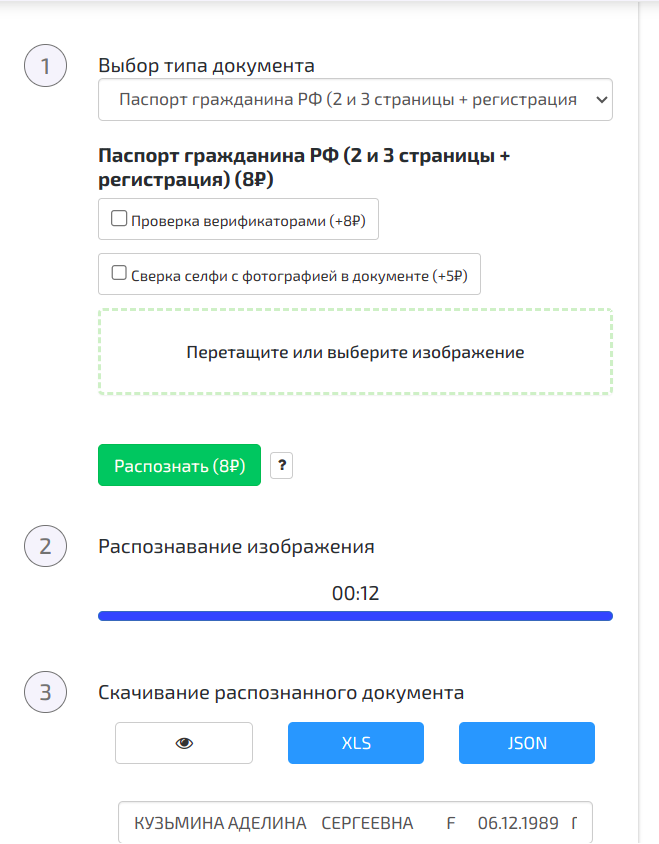
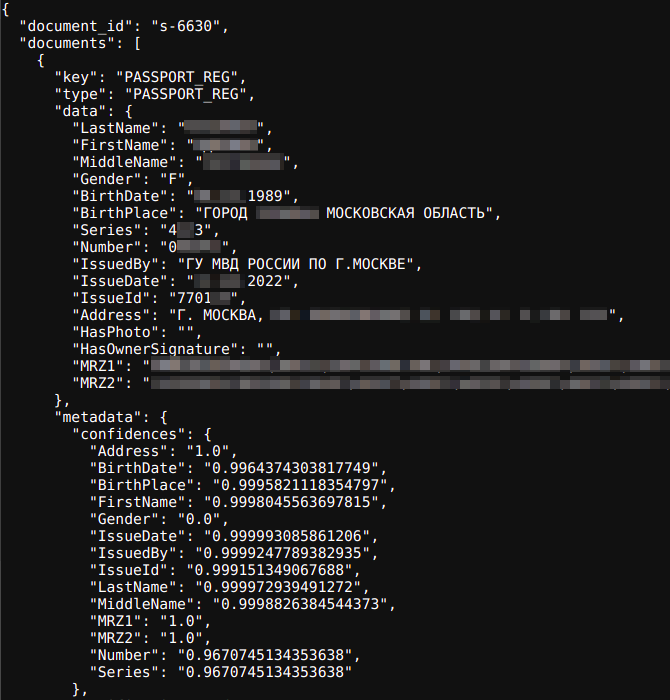
Получаем заветные паспортные данные в формате JSON. Результаты вы можете наблюдать ниже:
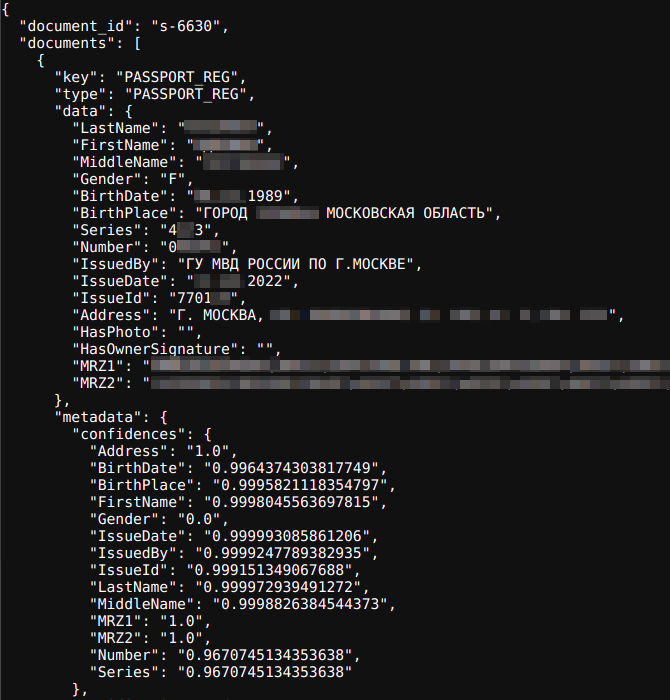
Распознались все поля, включая сложные ключи, такие как машиночитаемые записи.
За расшифровкой всех ключей в ответе можно обратиться к документации: kyc.beorg.ru/reference_public/dev
Подключение к API
Для подключения к API нам понадобится:
- документация
- Python3
- библиотека base64
- библиотека requests
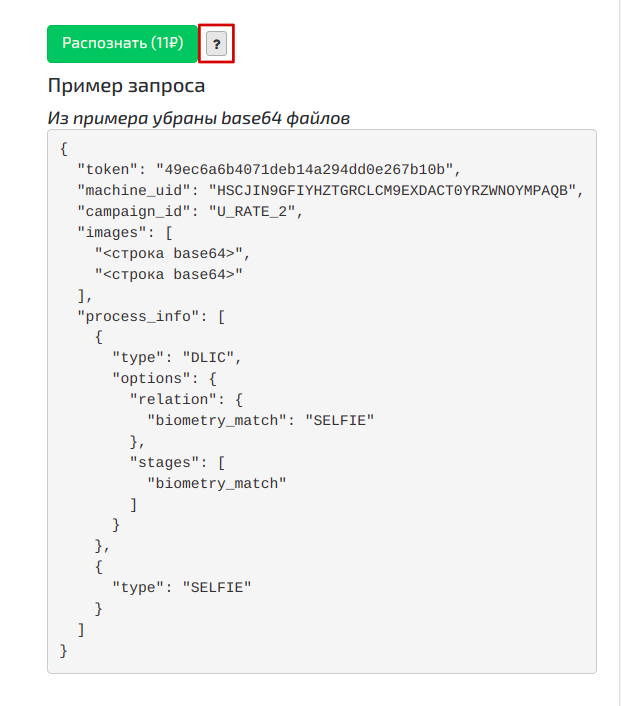
Чтобы начать отправлять запросы в API, получаем ключи доступа. Находятся они в разделе «Проекты»:
Нажимаем пиктограмму с глазом и наблюдаем все необходимые ключи доступа и примеры запросов:
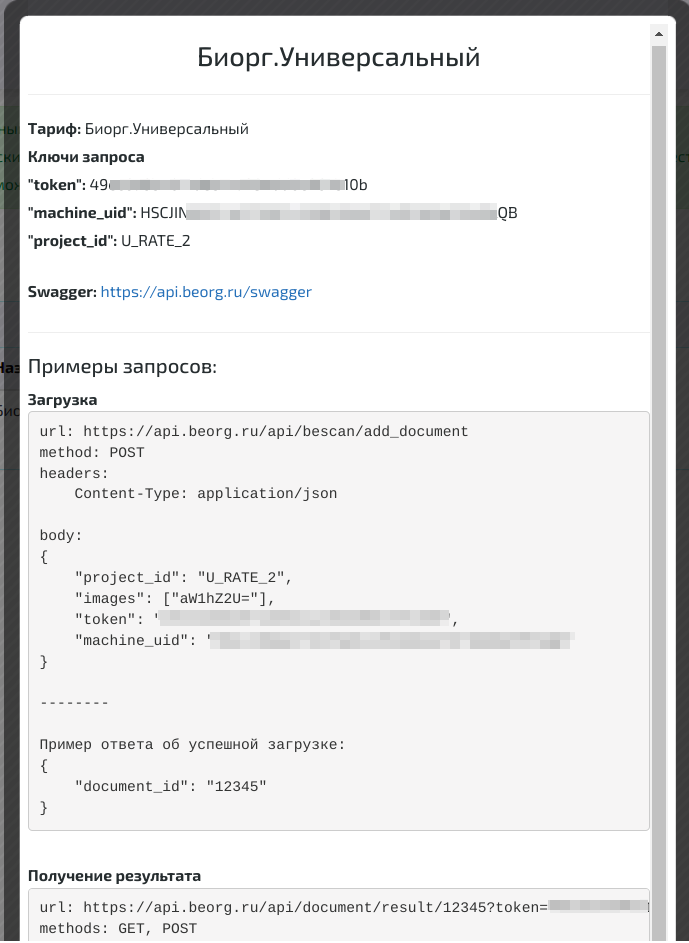
Нам необходимо взять с этой страницы:
- token: токен, по которому API может нас авторизовать
- machine_uid: номер машины, с которой планируется посылать запрос для разделения отслеживания документов со стороны клиента
project_id: идентификатор проекта
Общение по API должно происходить в соответствии со схемой:
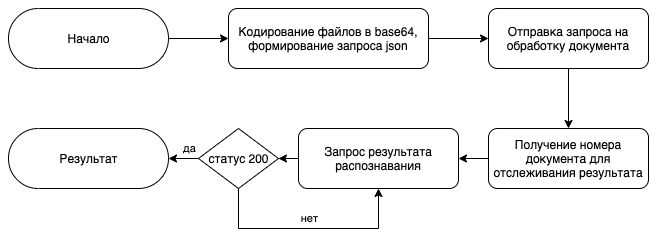
Пишем скрипт:
Тут все просто. Все обрабатывается на стороне Beorg. Также вы можете взять скрипт из репозитория на GitHub.
Вам нужно всего лишь посылать на API два вида запросов:
- Отправить документ
- Получить результат
В результате получаем подобный ответ:
Посмотреть виды запросов можно в документации или в разделе «Распознавание».
Выводы
Вот так просто мы написали небольшой скрипт, который позволяет получить данные из паспорта (и не только паспорта…) за несколько минут.
Разумеется существуют и другие платные и бесплатные сервисы распознавания документов (например от Google), но, увы, он практически ушел с российского рынка, а мы оперируем в этом вопросе персональными данными.
Резюме по избранному сервису распознавания:
- Просто
- Быстро (за кофе)
- Без головной боли для меня, как разраба
- Хорошее качество за свои деньги

