


Гайд по обработке данных с помощью Pandas: часть первая
Разбираем, как начать работу с Pandas. В этой части самые базовые приёмы: чтение и запись данных, индексирование, агрегация и другие основы.
28К открытий65К показов

Pandas — это библиотека на Python, предназначенная для обработки и анализа структурированных табличных данных. С её помощью можно фильтровать, сортировать, агрегировать и преобразовывать данные, а также интегрироваться с различными источниками для чтения и записи. Благодаря такому богатому функционалу, эффективности и удобству использования, Pandas — один из наиболее популярных инструментов в области анализа данных.
Руководитель группы видеоаналитики MTS AI Андрей Дугин рассказывает, как начать работу с Pandas и избежать распространённых ошибок.

Андрей Дугин
Руководитель группы видеоаналитики MTS AI
Где и для чего применяется Pandas
Pandas скорее академический исследовательский инструмент: для промышленных масштабов производительность у библиотеки относительно низкая, управление памятью не самое эффективное и нет параллелизма. Тем не менее, библиотека отлично подходит дата-сайентистам и аналитикам для прототипирования и исследования гипотез в нересурснозатратных проектах. Её можно применить практически в любой области, где требуется обработка и анализ табличных данных или временных рядов:
- Предиктивная аналитика для агрегаторов. Например, на сайтах недвижимости. Pandas поможет структурировать массив данных по квартирам: этаж, площадь, количество комнат, год постройки дома и так далее. На этих данных можно строить модели машинного обучения и предсказывать, сколько будет стоить недвижимость.
- Финансовый анализ. Pandas пригодится для анализа динамики цен акций, котировок валют, индексов и так далее. Это помогает при прогнозировании рыночных трендов, определении рисков и оценке инвестиционных стратегий.
- Маркетинговый анализ. Проанализировав с помощью Pandas данные о продажах, потребительском поведении, рекламных кампаниях можно определять оптимальные стратегии маркетинга.
- Исследования в области биоинформатики. Pandas помогает анализировать и обрабатывать биологические данные для выявления закономерностей, например, в болезнях.
- Обработка данных сенсоров и IoT. С помощью Pandas можно обрабатывать и анализировать данные сенсоров, полученных от устройств IoT, чтобы управлять системами, мониторить и диагностировать их.
Рассмотрим некоторые базовые приёмы работы с Pandas на основе классического датасета Titanic. Его используют студенты, изучающие машинное обучение, для предсказания шансов пассажиров на выживание в зависимости от их пола, возраста, класса каюты и других факторов. Подробнее почитать о значении полей можно в описании датасета на Kaggle.
Начало работы с Pandas
DISCLAIMER
- Поскольку примеры кода и вывод выполняются в Jupyter Notebook, то для отображения результата нам не обязательно оборачивать выражения в функцию
print(), однако это может понадобиться в других IDE. - По этой же причине при демонстрации мы иногда не модифицируем исходные данные (не делаем присваивание
A = B, а показываем только правую часть выражения; используемinplace=False), а просто выводим результат.
Установка и импорт
Pandas легко установить через стандартный пакетный менеджер Python, используя команду pip install pandas.
После установки следует импортировать саму библиотеку. Поскольку Pandas строится на базе библиотеки NumPy — инструментария для работы с многомерными массивами — для удобства рекомендуется импортировать и её. Она также будет установлена автоматически в процессе установки Pandas.
Структуры хранения данных
Данные организованы в структурированные таблицы с индексами, что облегчает манипуляции с ними. Операции в Pandas оптимизированы для работы по столбцам — так во многих случаях производительность выше, чем в операциях по строкам.
Структур хранения данных в Pandas две — Series и DataFrame.
- Series — это одномерный массив данных с метками. Он может хранить различные типы данных, включая числа, строки и произвольные объекты Python. Каждому элементу в Series соответствует метка, доступ к которой можно получить через атрибут index.

Есть проводить аналогию со словарём dict, то индекс — это ключи словаря, а сам массив данных — значения, к которым можно получить доступ по ключу:
- DataFrame — это двумерная структура данных, представляющая собой таблицу с метками для строк и столбцов. Каждый столбец в DataFrame является объектом типа Series. Вместе они формируют двумерную таблицу с общим индексом. В DataFrame присутствуют две оси индексации: index для строк и columns для столбцов. Метки столбцов — это их названия.


Операции чтения и записи данных
С помощью Pandas можно читать и записывать данные из различных источников: баз данных, файлов в форматах CSV, Excel, JSON и тому подобных. Для каждого типа данных существуют специализированные функции: read_csv(), read_excel() и другие вида read_*().

Можно даже автоматически спарсить таблицу из веб-страницы, указав URL и порядковый номер таблицы:

Функции чтения принимают много параметров, так можно настраивать все необходимые опции, включая явное задание типов данных или соответствующих функций-конвертеров. Это позволяет предобработать данные или преобразовать их типы к более эффективным ещё на этапе чтения из источника.
Записать данные в файл так же просто, как и прочитать — используйте семейство методов .to_*(), например, .to_excel():
Первичное исследование данных
После того как данные загружены из источника, следует получить общее представление о них.
Первые несколько строк датафрейма можно получить с помощью метода .head(), а последние — .tail():

Тип данных object чаще всего соответствует строковым значениям:

Pandas позволяет автоматически подобрать наиболее эффективные представления с помощью метода .convert_dtypes():

Другой способ взглянуть на датафрейм — метод .info(). Он показывает количество строк, столбцов, их названия и типы, а также позволяет обнаружить столбцы с отсутствующими значениями.

Некоторую статистику по числовым столбцам можно собрать с помощью метода .describe():

Количество различных значений можно посчитать с помощью .value_counts() — как для категориальных, так и для непрерывных данных:


Индексирование
Операции обращения к элементам данных называются индексированием.
В нашем датасете индексная колонка по умолчанию представлена целыми числами. Для наглядности в дальнейших примерах заменим индекс на колонку с именем пассажира:
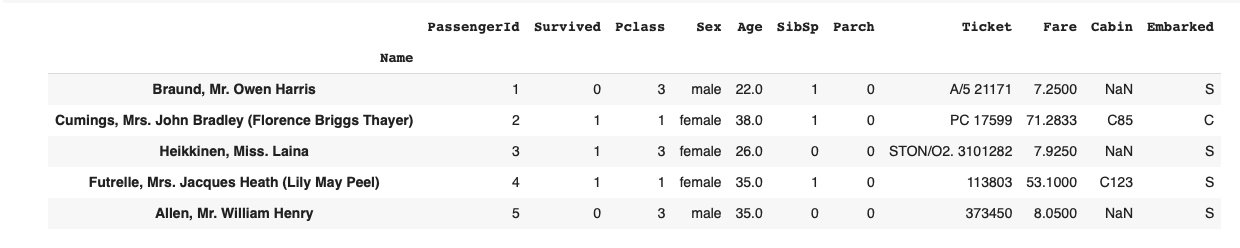
Элементы индекса называются метками (лейблами):

Названия колонок — тоже метки:

К колонкам можно обращаться по их названиям:

Если имя колонки удовлетворяет правилам именования переменных в Python и не совпадает с одним из уже существующих методов или атрибутов DataFrame, то к колонке можно обратиться как к атрибуту DataFrame:
Метод .loc[] есть и у Series, и у DataFrame. Он позволяет обращаться к данным по меткам:

Метод .iloc[] работает аналогично, но вместо меток используются номера строк или столбцов:

С помощью .at[] можно обратиться к конкретной ячейке данных — как в Excel:
При совершении операций над объектами DataFrame и Series Pandas пытается сопоставить элементы с одинаковыми индексами. Рассмотрим для примера последовательность Series с геометрической прогрессией, где каждый следующий элемент больше предыдущего в два раза:

Попытка попарно посчитать отношение следующего элемента к предыдущему приведёт к «странному» результату:

На самом деле мы хотели получить следующее:

Объединение данных
Для объединения нескольких датафреймов можно использовать близкие по смыслу функции: merge(), concat() и join(). Вот несколько базовых примеров:





Агрегация данных
С помощью этих функций и методов можно взглянуть на данные в различных разрезах:
groupby()— для группировки и агрегации данных с большой гибкостью;pivot_table()— для создания сводных таблиц с возможностью применения множественных агрегаций;crosstab()— для подсчёта частоты встречаемости категорий.
Рассчитаем средний возраст пассажиров с разбиением по полу:

Построим сводную таблицу, рассчитав вероятность выживания в зависимости от пола и класса:

Посчитаем, сколько человек каждого пола было в трёх классах кают:

Групповые операции
При обработке данных новички часто используют циклы для итераций по строкам или ячейкам. Такой код выполняется медленно. Лучше использовать методы .apply(), .map(), .transform(), которые работают быстрее за счёт векторизации.
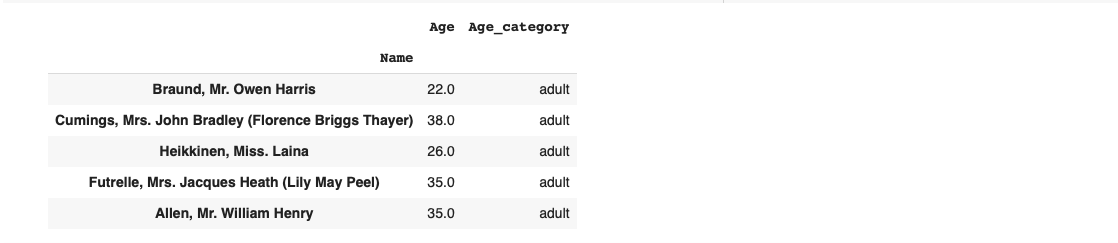
Кстати, такое же разбиение на возрастные группы можно выполнить с помощью функции pd.cut():

Работа с пропущенными данными
В реальных датасетах часть данных может отсутствовать. В библиотеке Pandas эти пропуски обычно представлены как NaN (Not a Number) в ячейках DataFrame или Series. Чтобы с ними работать можно использовать ключевые методы:
.isna()— идентифицирует отсутствующие значения и возвращает булевую маску, где True указывает на пропущенные данные;.fillna()— позволяет заполнить отсутствующие значения с помощью указанных значений или методов интерполяции;.dropna()— удаляет строки или столбцы, содержащие отсутствующие значения.
Метод .isna() есть как у DataFrame, так и у Series, а результатом его вызова будет булевая маска того же класса:


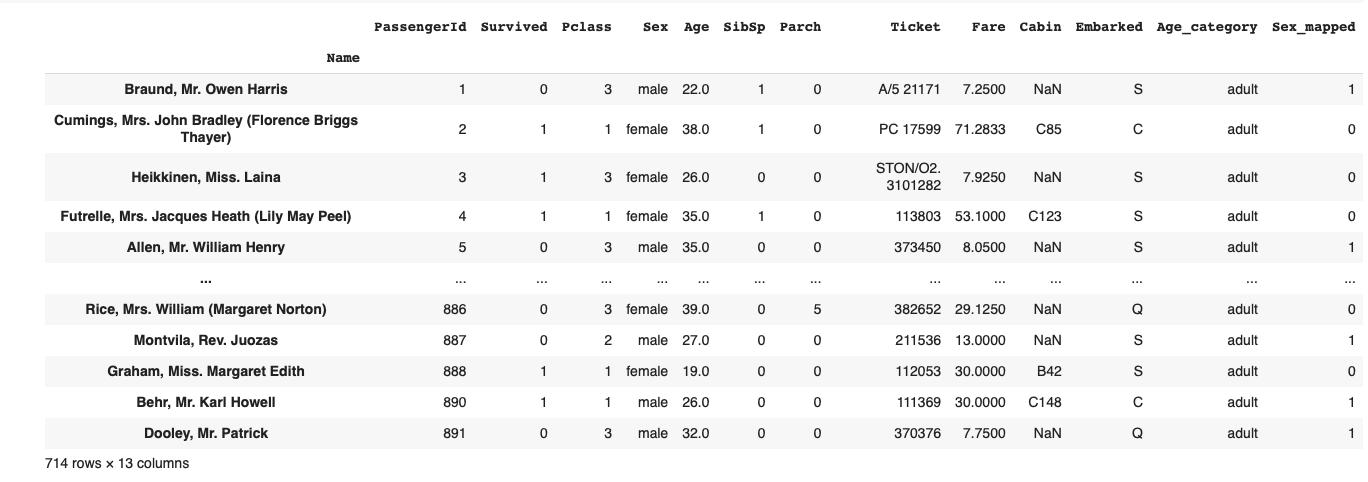
Если датасет небольшой, то удалять отсутствующие данные слишком расточительно. Лучше придумать, как заполнить недостающие значения.
Например, можно заменить их средними значениями в столбце:
Или заполнить предыдущим, либо последующим значением:
Методы генерации и заполнения отсутствующих значений называются импутингом. В библиотекеscikit-learnесть модульsklearn.impute, в котором представлены несколько классов импутеров, основанных на различных алгоритмах.
Визуализация данных
Pandas интегрирована с библиотекой Matplotlib — инструментом для создания двумерных и трёхмерных графических представлений данных. В Pandas можно либо явно использовать её функции для визуализации данных, либо применять встроенные методы, такие как .plot() и .hist(). Второй вариант облегчает построение графиков, автоматически определяя наилучший способ визуализации данных.

То же самое можно сделать через прямой вызов функций matplotlib:

Работа с временными рядами
Индексная колонка датафрейма представлена датой и временем, что позволяет индексировать данные по дате и времени, ресемплировать (осуществлять выборку с большей или с меньшей частотой), интерполировать отсутствующие данные, применять оконные функции.
Допустим, у нас есть статистика перевозки пассажиров некой авиакомпании. Сгенерируем эти данные по месяцам:

А теперь рассчитаем среднемесячное количество пассажиров по каждому году:
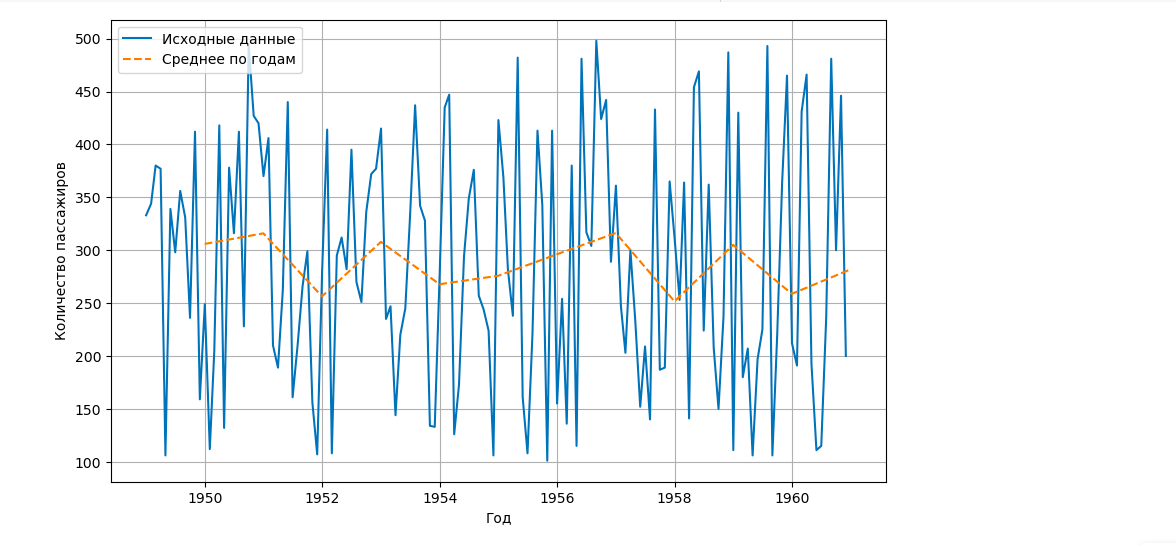
Применим скользящее окно и рассчитаем среднее количество пассажиров за последние 12 месяцев:

В первых 11 строках по умолчанию появились значения NaN, так как количество проанализированных строк меньше размера окна. Это поведение можно изменить, задав параметр min_periods — минимальное количество строк, для которых определён результат:

В заключение
В этой части статьи мы рассмотрели, как использовать Pandas для разных базовых задач. Во второй части разберём, как сделать работу с Pandas эффективнее, узнаем, какие есть альтернативы для этой библиотеки и какие источники можно почитать, чтобы ещё лучше в ней ориентироваться. Следите за обновлениями!

28К открытий65К показов
Разобрались, что происходит с облачным геймингом, чем отличаются подходы западных и российских компаний и что приносит сфера пользователям.

Компания оказалась в топе рейтингов работодателей за 2023 год по версии Forbes и РБК. Вот по каким критериям проходила оценка.

Рассказываем про старт в профессии, подводные камни и карьерные перспективы — их больше, чем принято считать.

Корпорациям нужны не только мидлы и сеньоры, но и молодые таланты. Один из способов их получить — стажировки. Рассказываем о трёх направлениях в МТС: для любых специалистов, аналитиков и будущих руководителей.