Разобрали Telegram-бота на aiogram по косточкам, показали, как наладить экспорт пользовательских данных для непрограммирующих коллег в Google Sheets, а также как построить кастомный Radar Chart с Plotly.
699 открытий7К показов
Это продолжение статьи о боте, завлекающем на курсы по управлению проектами. В первой части мы разобрались со стандартными файлами проекта, управляющими запуском и кодом, отвечающим за вопросы. И научились уводить диалог в определённую ветку и записывать пользовательские данные в SQLIte.
Это статья из цикла «5 ETL для зоопарка ботов». В нём я пошагово разбираю, как наладить потоки данных из разных библиотек и конструкторов ботов на разных языках и стеках. В основе лежат Python и его библиотеки. Вот предыдущие статьи цикла:
Полный код функции прикладывать не буду, чтобы не перегружать текст. Форкнуть бота можно с помощью этого репозитория.
Сперва импортируем инструменты. Для создания тонко настроенных графиков отлично подходит библиотека Plotly. Далее я покажу, какие визуальные тонкости она позволяет кастомизировать:
import gspread
import pandas as pd
import numpy as np
import plotly.express as px
import os
from texts import texts
Передадим ключи проекта Google Cloud, к которому привязана таблица. Я намеренно выбрала именно этот способ хранить пользовательские данные, чтобы облегчить другим участникам проекта просмотр. Сюда попадают только завершившие опрос пользователи, «бросанты» хранятся в SQLite и отдаются нашему отделу маркетинга по запросу.
Помню, по первой разобраться в многоэтажной документации Google было непросто, особенно в части авторизации. Для таких вещей, как взаимодействие с таблицами, подходит тип кредов для служебной учетной записи. С инструкцией по их получению ознакомьтесь по ссылке.
Таблица выглядит так:
Строим паутинку
Теперь давайте создадим функции, строящую индивидуальный график-паутинку. Тут Plotly потребовал преобразований, чтобы появилась возможность ранжировать очки диапазонам (падаван/рыцарь-джедай/мастер-джедай). Я закладываю специальный столбец «Аспект», чтобы Plotly мог раскидать очки по уровням паутинки:
def create_chart(result_lst):
# Преобразуем элементы списка в целочисленные
lst = result_lst[1:]
score = [eval(i) for i in lst]
# Опишем формулу расчета итогового количества очков col = [score[0] * 3, score[2] * 3, score[4] * 3, score[6] * 3, score[8] * 3, score[10] * 3, score[1] * 2 + score[12], score[3] * 2 + score[13], score[5] * 2 + score[14], score[7] * 2 + score[15], score[9] * 2 + score[16], score[11] * 2 + score[17]]
# Превратим список очков в датафрейм, чтобы корректно отобразить паутинку
df = pd.DataFrame({'category': ['Команда', 'Заинт. стороны', 'Подход и поставка', 'Планирование', 'Работа и измерение', 'Риски',
'Команда', 'Заинт. стороны', 'Подход и поставка', 'Планирование', 'Работа и измерение', 'Риски'],
'Аспект': [0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1]})
df['score'] = col
# Присвоим значениям интервалов категории
conditions = [
(df['score'] == 0),
(df['score'] >= 1) & (df['score'] <= 6),
(df['score'] >= 7) & (df['score'] <= 12),
(df['score'] >= 13) & (df['score'] <= 20)
]
# Перечислим категории
tiers = ['Новичок', 'Падаван', 'Рыцарь-Джедай', 'Мастер-Джедай']
df['mark'] = np.select(conditions, tiers)
df2 = df.assign(mark=pd.Categorical(df["mark"], ordered=False, categories=tiers))
# Построим паутинку fig = px.line_polar(df2, r="score", theta="category", color="Аспект", line_close=True, color_discrete_sequence=['#3b5998', '#52a9f9'], template="plotly_dark", # Зашьем в заголовок имя, уровень и число очков title=f"{result_lst[0]}, очков: {sum(col[:11])}")
# Добавим заливку
fig.update_traces(fill='toself')
# Добавим подписи на шкале
fig.update_layout(polar={"radialaxis":{"tickmode":"array","tickvals":[0, 7, 12, 20],"ticktext":tiers}})
# Настроим легенду
fig.update_layout(legend=dict(
yanchor="top",
y=0.99,
xanchor="right",
x=0.01
))
# Настроим кастомную легенду
fig.data[0].name="Умения"
fig.data[1].name="Проблемы"
fig.write_image(f"{os.environ['SYSTEM_PATH']}{result_lst[0]}.jpeg")
return
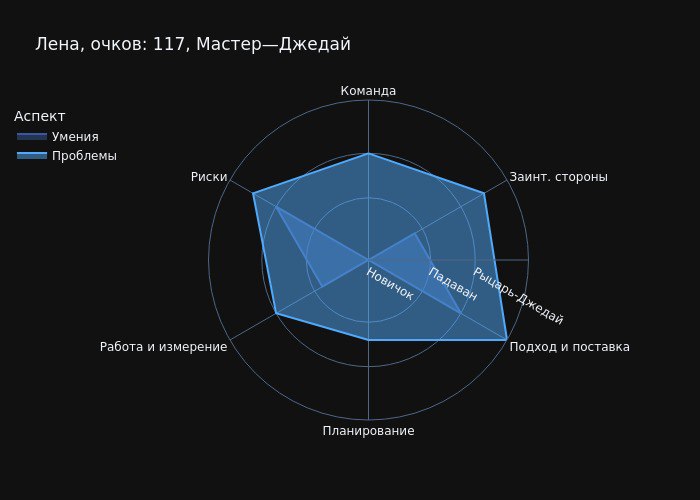
В результате получим такую паутинку:
Из нестандартных визуальных элементов для Radar Charts выделю отображение джедайских уровней на шкале X, создание двух окрашенных компонентов из одного датафрейма, а также тёмную тему. Код готов к запуску на момент создания статьи, так что используйте, если вам понравился дизайн.
Определяем рекомендации
Чтобы в заголовок закладывался определённый уровень джедая, я реализовала функцию, рассчитывающую итоговый счёт по той же формуле:
def interprete_score(result_lst):
# Преобразуем элементы списка в целочисленные
lst = result_lst[1:]
score = [eval(i) for i in lst]
scores = [score[0] * 3, score[2] * 3, score[4] * 3, score[6] * 3, score[8] * 3, score[10] * 3, score[1] * 2 + score[12], score[3] * 2 + score[13], score[5] * 2 + score[14], score[7] * 2 + score[15], score[9] * 2 + score[16], score[11] * 2 + score[17]]
skills_lst = scores[:5]
# Определим минимальное умение
skills_min = min(skills_lst)
# Определим среднее значение по умениям
def find_mean(lst):
return sum(lst) / len(lst)
skills_mean = find_mean(skills_lst)
mean_min_diff = skills_mean - skills_min
# Создадим текст итоговой рекомендации
interpretation = []
# Добавляем вывод в зависимости от разности между навыками и проблемами
if mean_min_diff < 5:
interpretation.append('У вас ровные компетенции\.')
elif 5 <= mean_min_diff <= 10:
interpretation.append('Из графика явно видно, что ваши компетенции развиты в разной степени\.')
else:
interpretation.append('Из графика явно видно, что ваши компетенции в разных сферах существенно различаются\. Постарайтесь обращать больше внимания на те сферы, которые у вас выпадают \- без этого не получится стать профессиональным РП\.')
# Вычисляем разность между проблемами и навыками
team_diff = scores[0] - scores[1]
stakeholders_diff = scores[2] - scores[3]
approach_diff = scores[4] - scores[5]
planning_diff = scores[6] - scores[7]
work_diff = scores[8] - scores[9]
risk_diff = scores[10] - scores[11]
# Добавляем вывод на базе разностей навыков и проблем
if (team_diff > 0 and stakeholders_diff > 0 and approach_diff > 0 and planning_diff > 0 and work_diff > 0 and risk_diff > 0):
interpretation.append('Хорошие новости - судя по всему в вашей текущей рабочей деятельности ваших компетенций хватает, чтобы справляться с возникающими проблемами\. Однако мы советуем не расслабляться - кто знает, какие вызовы ждут вас в будущем?.. ')
else:
interpretation.append('Но обратите внимание: их часто недостаточно для того, чтобы решить возникающие проблемы в следующих сферах:')
# Определяем проблемные зоны
if team_diff > 0:
interpretation.append('\n\- Команда')
if stakeholders_diff > 0:
interpretation.append('\n\- Заинтересованные стороны')
if approach_diff > 0:
interpretation.append('\n\- Подход и поставка')
if planning_diff > 0:
interpretation.append('\n\- Планирование')
if work_diff > 0:
interpretation.append('\n\- Работа и измерение')
if risk_diff > 0:
interpretation.append('\n\- Риски')
else:
pass
output = ' '.join(interpretation)
return output
Функция append_result() присоединит результат нового игрока к таблице:
def append_result(result_lst):
body = result_lst
sheet.append_row(body)
Рассчитываем уровень будущего студента
Подошел черед функции, определяющей уровень игрока:
def level_count(result_lst):
lst = result_lst[1:]
res = [eval(i) for i in lst]
col = [res[0] * 3, res[2] * 3, res[4] * 3, res[6] * 3, res[8] * 3, res[10] * 3, res[1] * 2 + res[12], res[3] * 2 + res[13], res[5] * 2 + res[14], res[7] * 2 + res[15], res[9] * 2 + res[16], res[11] * 2 + res[17]]
score = sum(col)
# Присвоим уровень в зависимости от числа очков: if 0 <= score <= 41:
return ‘Новичок’
elif 42 <= score <= 50:
return ‘Падаван’
elif 51 <= score <= 70:
return ‘Падаван—Джедай’
elif 71 <= score <= 100:
return ‘Рыцарь—Джедай’
else:
return ‘Мастер—Джедай’
Заключение
Теперь основные компоненты бота изучены и прокомментированы. Помню, самой хотелось когда-то расковырять похожего бота и на его базе создать что-то своё, так что дерзайте.
Надеюсь, с помощью такого разбора вы упростите себе сборку первого самописного бота для Telegram. Хотя библиотек создано немало, именно aiogram заработала репутацию развитого и регулярно обновляемого фреймворка. Да и обучающих видео предостаточно. Так что начинать советую именно с него.
Если вам захотелось пройти этот опрос и выяснить, какой вы джедай-руководитель проекта, то бот здесь: @infostart_mt_course_bot.
Что такое конечный автомат (FSM) и зачем он нужен программисту? Эта статья простыми словами объясняет концепцию FSM, его компоненты, преимущества и реализацию на JavaScript с примерами. Разберём логику состояний, событий и переходов без сложной теории.