Как наладить непрерывную интеграцию в монорепозитории
Практические советы на основе нашего опыта: как мы изменили модель разработки и настроили CI-процесс в монорепозитории.

Сегодня я расскажу о том, как монорепозиторий с собственной инфраструктурой изменил жизнь разработчиков «Лаборатории Касперского» и увеличил скорость доставки изменений в код.
Вы также узнаете, как устроен наш CI-процесс, какие преимущества мы получили, с какими проблемами столкнулись и какие инструменты и мониторинги используем для повышения его работоспособности.
Как мы решились изменить модель разработки
Раньше каждая команда в нашей компании жила в собственном репозитории: выбирала удобную для себя систему контроля версий, использовала свою инфраструктуру для CI-процессов — а некоторые команды даже разрабатывали собственную.
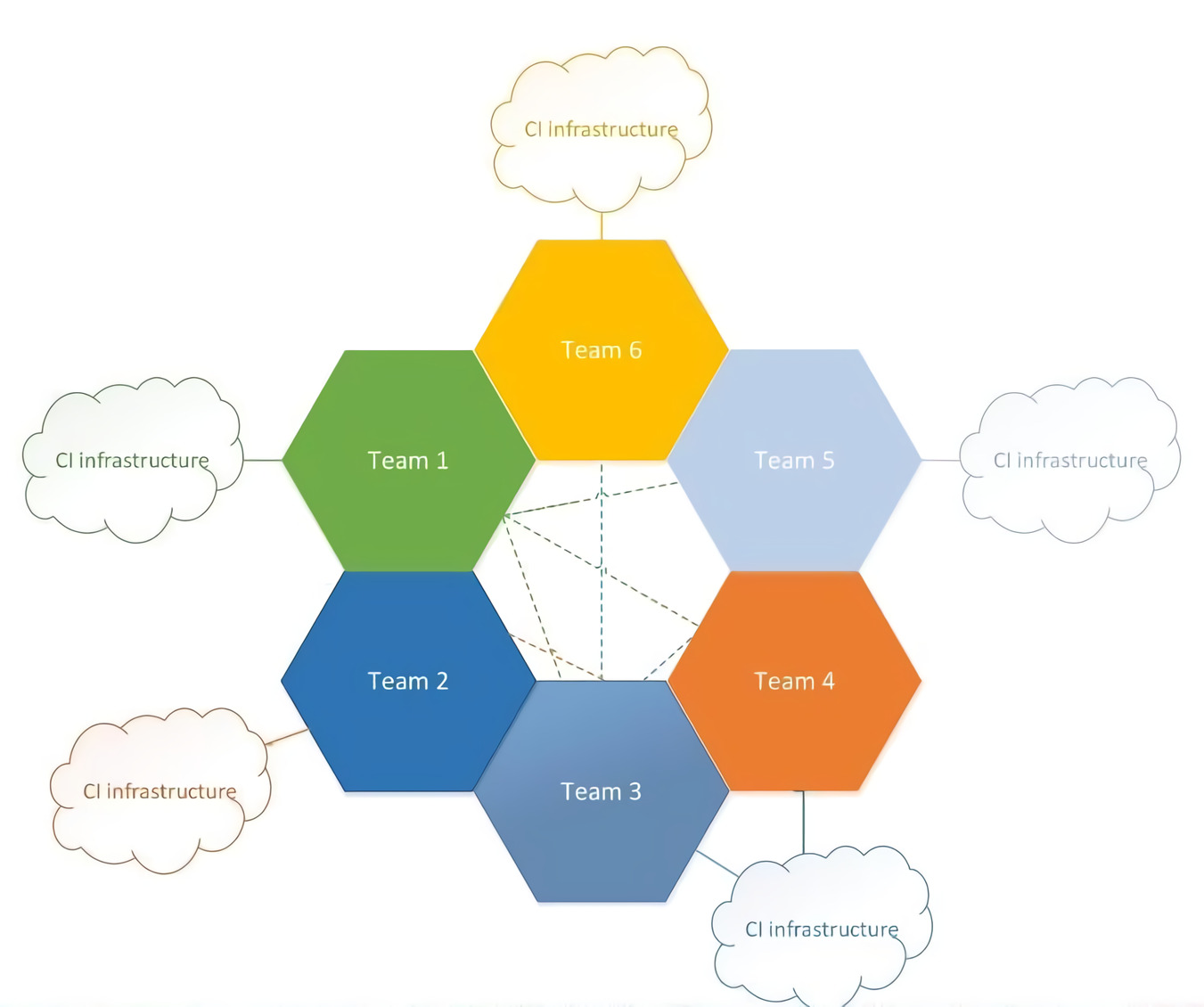
Проблемы старой модели
Такая схема имеет право на жизнь. Но в компании между командами есть множество взаимных связей. Из-за этого возникали проблемы.
- Приходилось вносить одинаковые правки в несколько проектов сразу. А так как у многих проектов различные системы контроля версий и инфраструктуры, это вызывало трудности у разработчика.
- Возникали сложности при валидации зависимых проектов.
- Чем больше взаимных связей появлялось, тем сложнее и дороже было вносить изменения, а также искать всех своих клиентов.
Новая модель с единой инфраструктурой
Все описанные выше пункты отнимают много времени и сил. Чтобы этого избежать, можно перевести все проекты в общий репозиторий и сделать так, чтобы его CI настраивался на общей инфраструктуре, которая с этим репозиторием работает. Мы поняли, что эта схема в целом решит наши проблемы.
В итоге мы переехали в общий Git-репозиторий, перешли на модель разработки Trunk-Based Development и стали использовать общую инфраструктуру для этого репозитория.
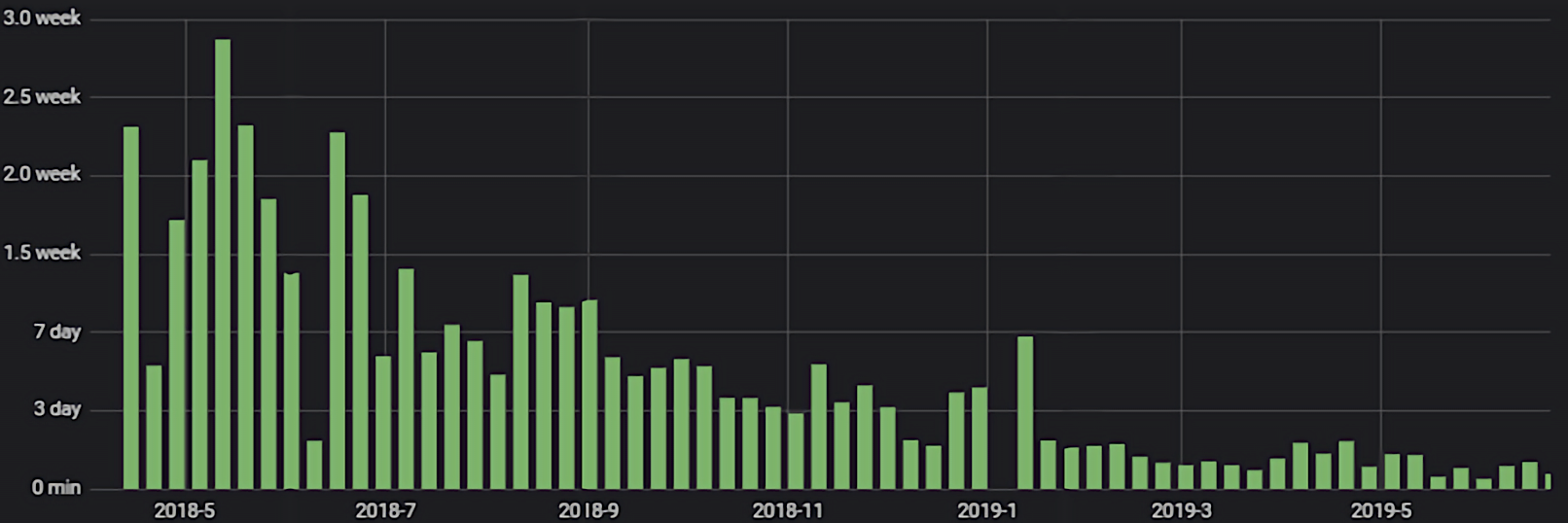
На графике представлено время доставки изменений некоторой команды за период около двух лет. Оно охватывает отрезки времени, до того как мы перешли в единый репозиторий с общей инфраструктурой, и после перехода. Видно, что скорость доставки выросла в несколько раз.
Monorepo
Monorepo «Лаборатории Касперского» — это Git-репозиторий размером 50 ГБ. У него около 350 Pull Request’ов и 150 уникальных контрибьюторов в день.
Более подробное описание нашего Monorepo доступно по ссылке.
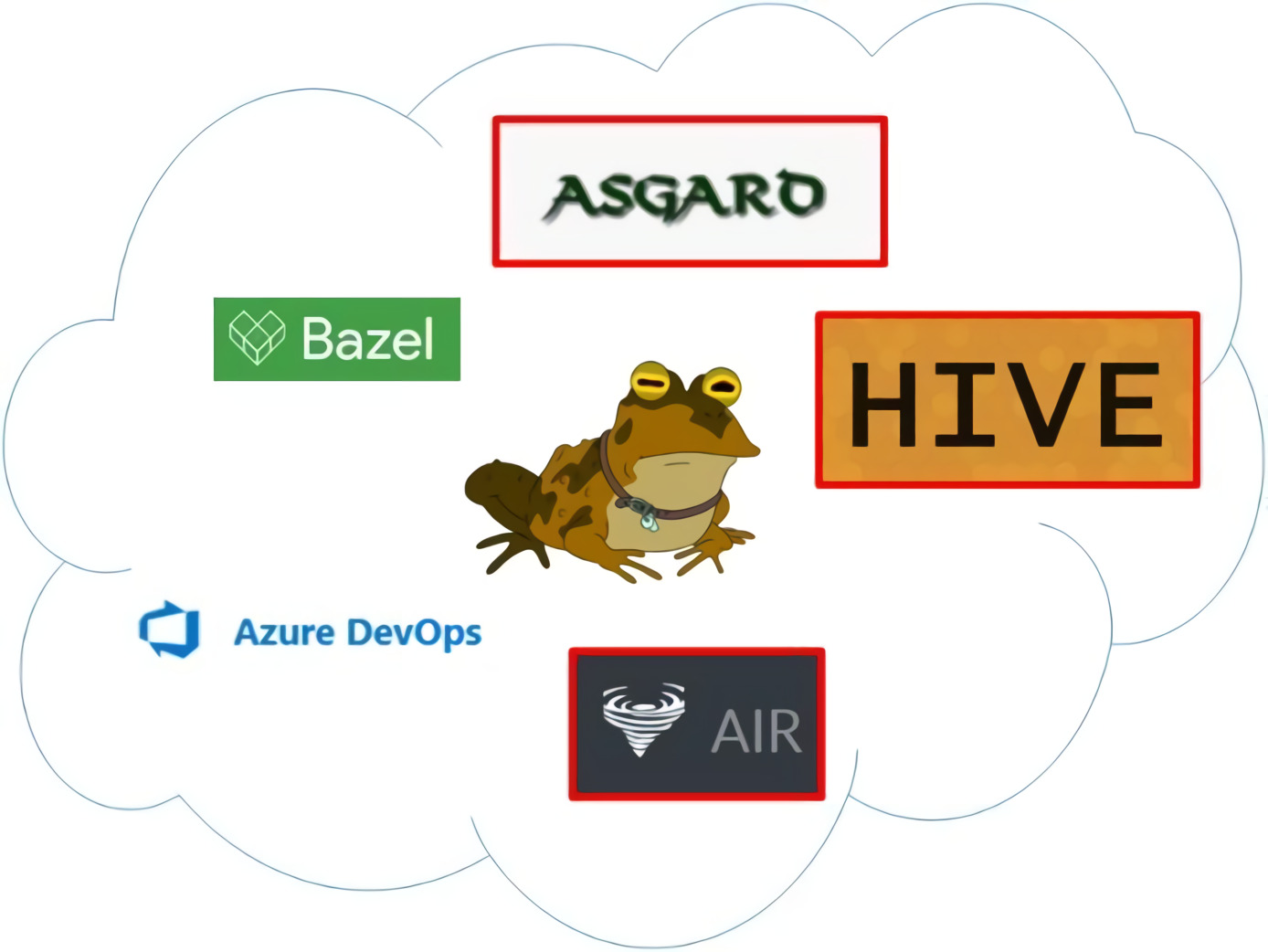
Инфраструктура
- Общий сборочный конвейер Asgard.
- Общая инфраструктура тестирования Hive.
- Распределённое хранилище артефактов Air.
- Общая система сборки Bazel (подробнее о том, как мы используем Bazel, можно узнать на нашем митапе Из CMake в Bazel. Переход для большой кодовой базы С++).
- Система управления репозиторием и пайплайнами Azure DevOps.
Часть инфраструктуры в нашей компании самописная, ниже на схеме она выделена красной рамкой.
Валидационный билд
При изменении кода создаётся Pull Request, в котором запускается валидационный билд. Он собирает все зависимости и тестирует их вместе (схема актуальна при коммите в продукты и компоненты, их использующие). Команды, не связанные с продуктово-компонентной разработкой, могут использовать собственные валидации. О них далее речь не идёт.

У такого билда около 150 джобов — операций сборки или тестирования. В самом длинном сценарии, при правке базовых компонентов нашей компании (на основе которых собирают и тестируют продукты для Windows, macOS, Linux, мобильных устройств), билд длится порядка двух с половиной часов. А если, например, коммитить в продукт, разрабатываемый под Windows, то валидация проходит намного быстрее.
Проблемы такого валидационного билда
- Большое количество зависимостей и, как следствие, сборочных и тестовых джобов. Чем больше зависимостей, тем, скорее всего, будет больше нестабильности этого валидационного билда. Каждая отдельная часть может быть достаточно стабильной, то есть иметь маленький процент нестабильности, но сборка этих частей воедино приведёт к большей нестабильности.
- Свой вклад в нестабильность валидационного билда вносят как внешняя инфраструктура, так и внутренняя, которая находится в процессе разработки.
Допустим, разработчик правит код, валидационный билд запускается и падает. Чтобы выяснить причины падения, нужно ответить на вопросы.
- Кто виноват? Порой валидационный билд падает по независящим от разработчика причинам.
- Поможет ли перезапуск? Если сделать перезапуск билда, пройдёт ли он? А если не пройдёт, то когда исправится?
Давайте посмотрим на график с валидационными билдами из Pull Request’ов.
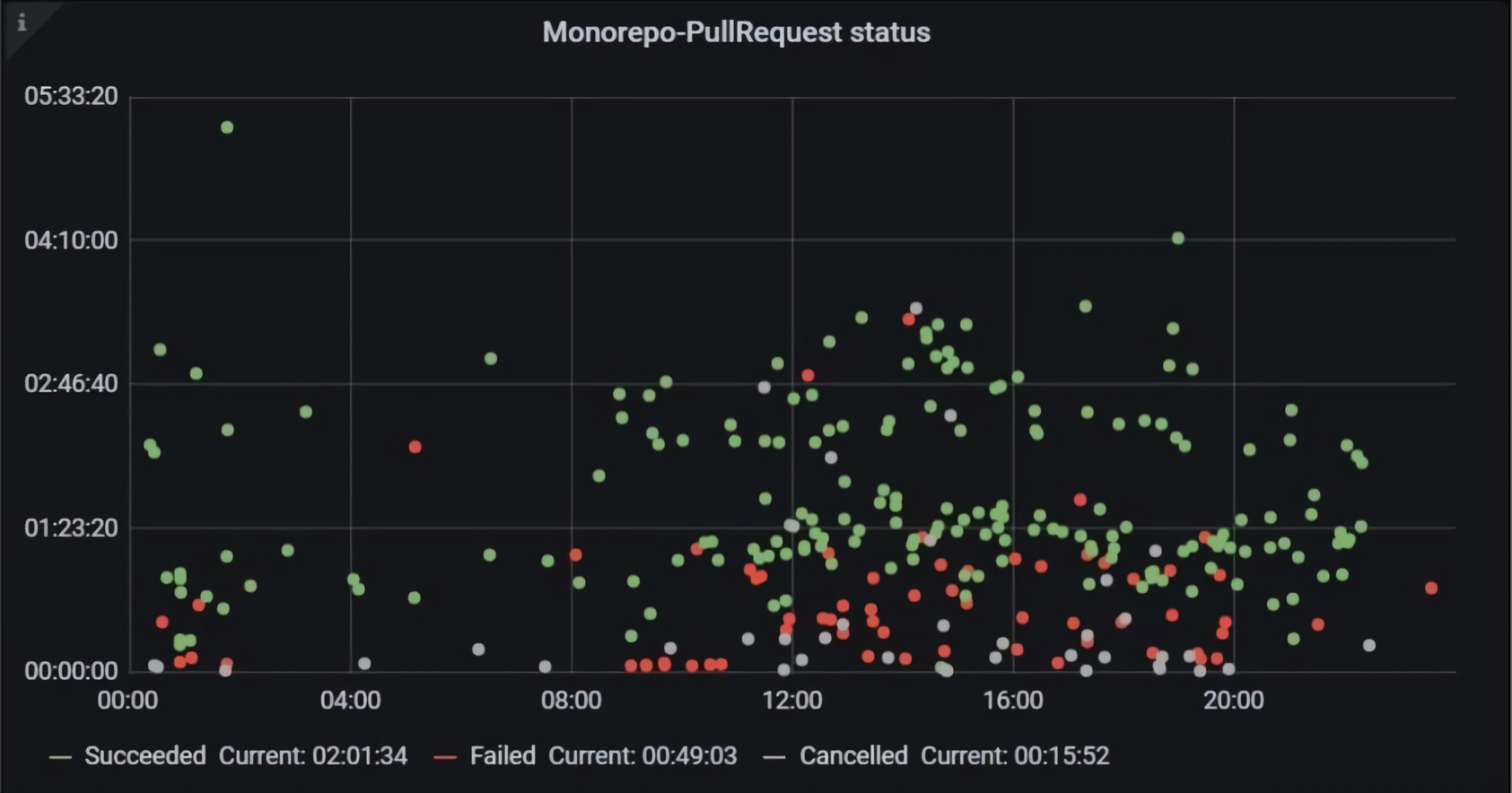
По горизонтали расположено астрономическое время, а по вертикали — длительность билдов. Зелёные билды успешные, красные — неуспешные, серые — отменённые. Возникает вопрос: как отличить билды, которые упали, потому что разработчики коммитили плохой код, от тех, что упали по внешним причинам, из-за различных нестабильностей.
Мы решили попробовать запускать билд просто по мастеру. Как я говорила ранее, у нас Trunk-Based Development. Это значит, что мастер должен быть всегда зелёным, билд должен быть всегда успешным. Мы попробовали его запустить по мастеру раз в час и увидели, что на самом деле это не всегда так и билд периодически падает.
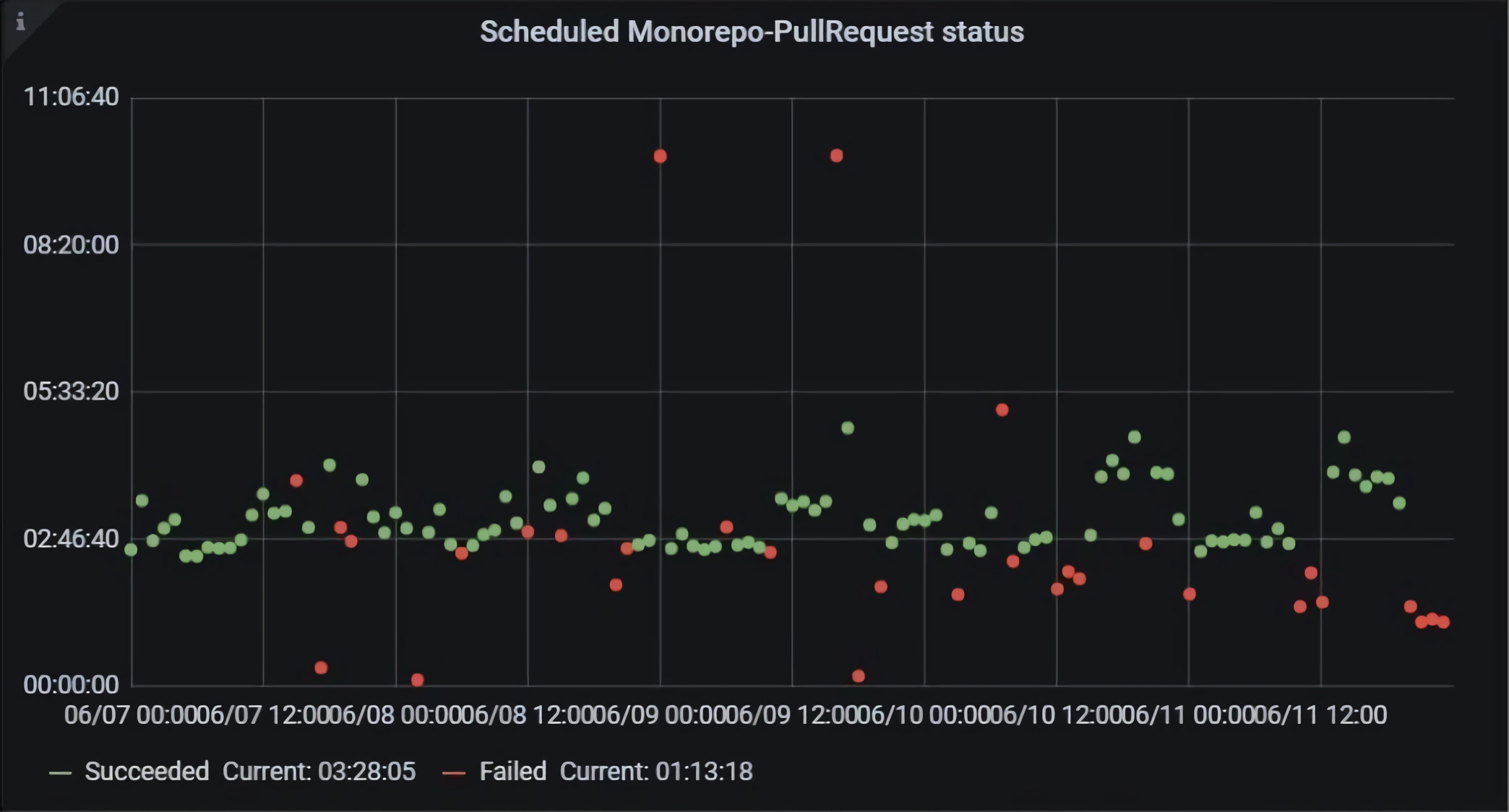
Решение
Мы решили с помощью такого билда по расписанию отслеживать состояние Monorepo. Это позволило сделать следующее.
- Предотвращать проблемы до того, как они воспроизведутся в Pull Request’ах разработчиков.
- Осуществлять мониторинг. Билд запускается каждый час, и мы анализируем, успешен он или нет.
- Находить ответственных.
- Не разбираться, привели ли к падению изменения разработчика в Pull Request’е или причина в каких-то других нестабильностях.
- Замечать глобальные проблемы. Например, если несколько билдов упали подряд и нет ни одного успешного, то, скорее всего, там сломалось всё, и невозможно ничего закоммитить, ничего не работает.
- Заводить баги с каждого падения такого билда не задумываясь.
Итак, мы стали запускать валидационный билд по мастеру каждый час (мы называем его заскедуленным билдом Pull Request’а). Такая практика позволила:
- заводить инцидент на каждое падение валидационного билда;
- собирать статистику: из-за чего и в каком проценте случаев падает валидационный билд, запущенный по мастеру;
- выставлять командам таргеты и цели по достижению стабильности этого валидационного билда;
- системно работать с ошибками: искать, что сделать, чтобы в следующий раз они не воспроизвелись.
Ниже показан график распределения падений такого билда по различным системам.
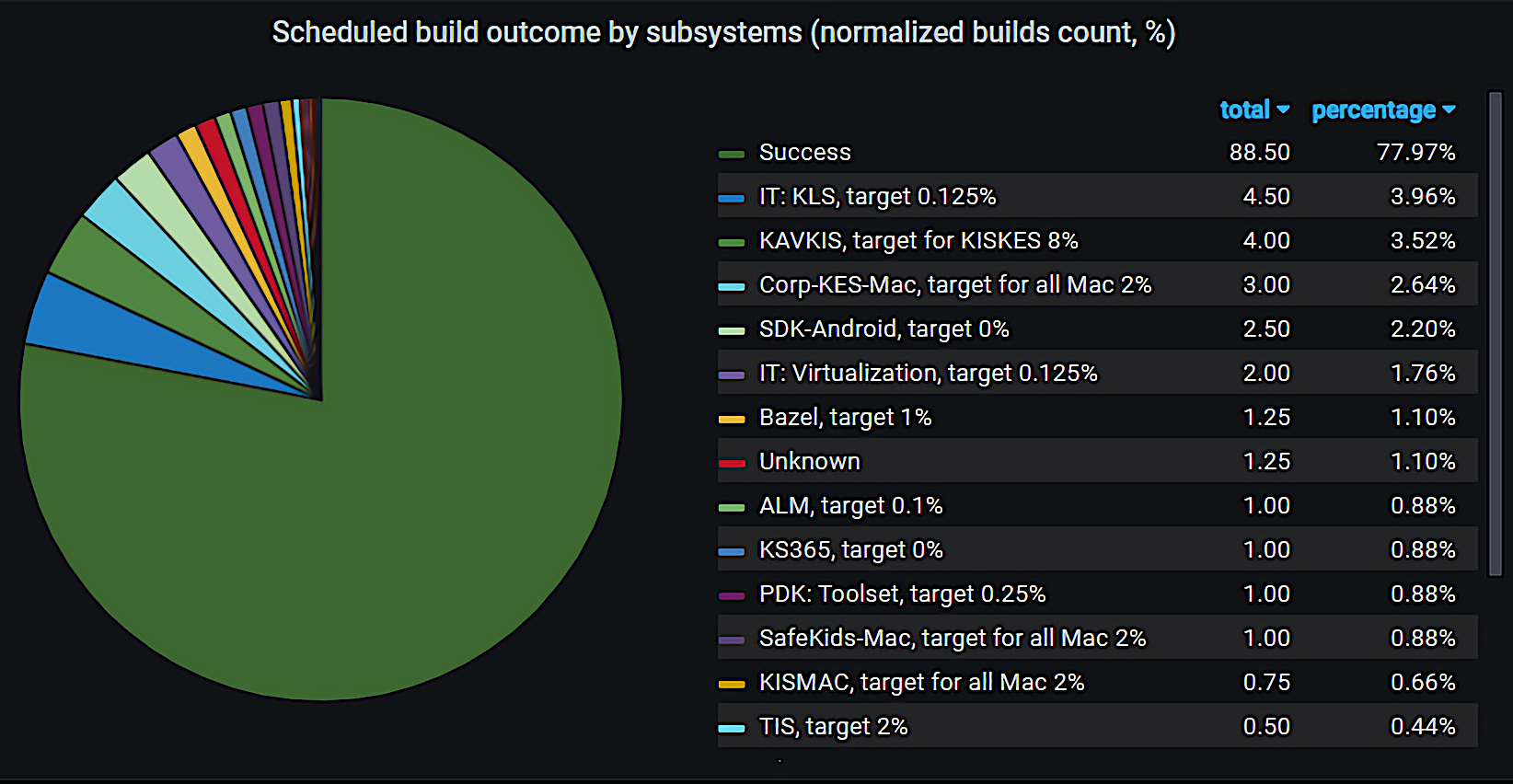
Статистика прохождения Pull Request’ов
Впервые мы начали запускать такой билд по расписанию в 2018 году, тогда было около 57% прохождений успешных, заскедуленных Pull Request’ов по мастеру. Это была очень печальная статистика, близкая к 50 на 50. Сейчас мы достигли порядка 82% успеха, что можно назвать хорошим результатом.

Билд стал падать реже, но проблемы у разработчиков всё равно остались. Если валидационный билд упал не из-за их проблем в Pull Request’е, им нужна обратная связь, которая включает несколько пунктов:
- уведомить разработчиков о наличии проблемы;
- обозначить статус решения проблемы;
- по возможности ускорить перезапуск валидационного билда.
Для того чтобы это осуществить, у нас появился робот Thor.
Thor
Мы назвали Thor’а хранителем Pull Request’а, ведь он умеет следующее.
- Отслеживает глобальные проблемы. Например, на нескольких Pull Request’ах разработчиков валидационный билд падает по одной и той же причине. При этом в обозначенном временном промежутке успешные билды отсутствуют. Thor понимает, что ничего не работает и нужно срочно всё починить, заводит инцидент и ставит валидационный билд Pull Request’а на паузу. А затем пишет об этом в каждый Pull Request — как представлено на скриншоте — и прикладывает линк на инцидент. Когда разработчик заходит в свой Pull Request, то видит, что валидационный билд не работает. Он может кликнуть ссылку и убедиться, что проблему уже заметили и решают.
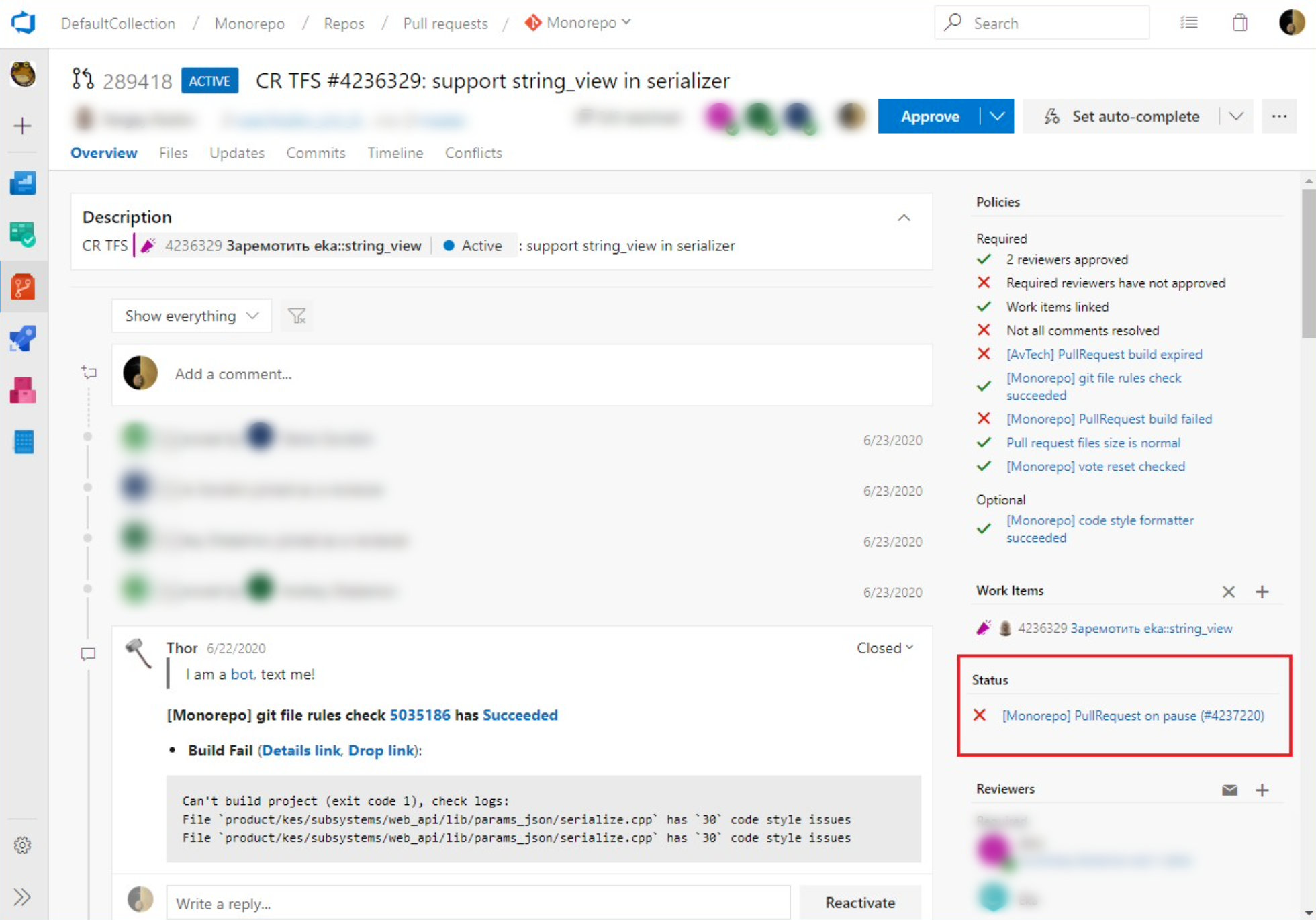
- Снимает билды с паузы и перезапускает их. Когда проблема решается, Thor снимает валидационный билд с паузы и перезапускает упавшие билды. Так, разработчик может прийти в свой Pull Request и обнаружить, что всё уже перезапущено. Возможно, он даже не заметит, что проблемы вообще были.
Перезапуск из-за известной нестабильной проблемы
На практике возникают не только глобальные проблемы, но и нестабильности, которые решаются перезапуском. С такими Thor тоже работает.
Он видит, что на нескольких Pull Request’ах разработчиков валидационный билд падает с одной и той же проблемой, и заводит на это инцидент. Также при каждом падении валидационного билда в пуллреквестах разработчиков он мониторит, не заводили ли на это падение инцидент. И если такой есть, пишет об этом в Pull Request разработчику.
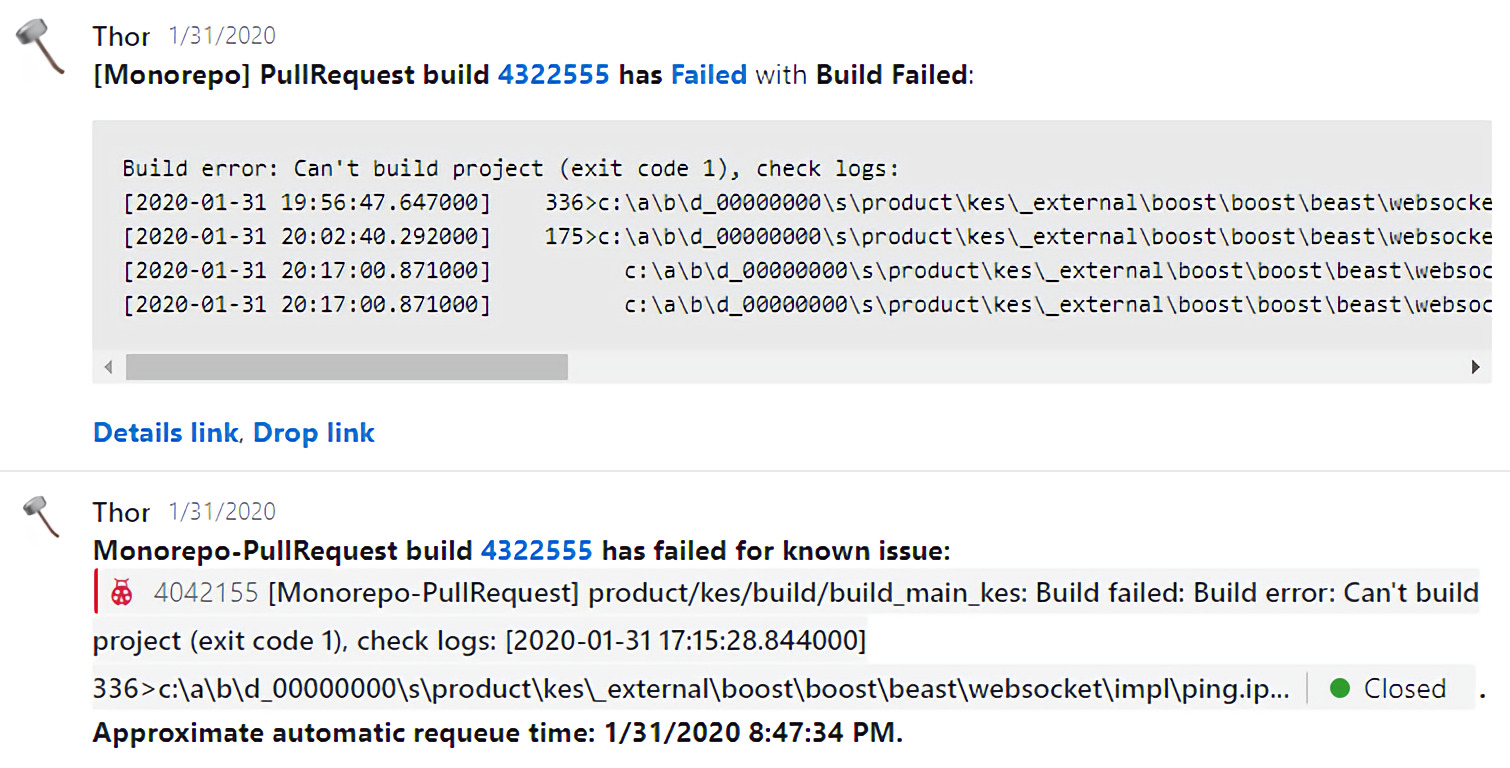
Таким образом, разработчику не нужно тратить время на решение не своих проблем. Он сразу понимает, чья это ответственность, и продолжает заниматься своим кодом.
Также Thor сообщает о том, что валидационный билд будет поставлен в очередь на перезапуск. Мы не перезапускаем всё сразу, чтобы не DDoS-ить инфраструктуру, но примерно 69% валидационных билдов, упавших по причине нестабильности, перезапускаем до того, как это сделают разработчики.
Thor – бот

Thor — это ещё и бот, который:
- помогает, если непонятно, что делать с проблемой в Pull Request’е, — он вызывает специальную команду, которая приходит в Pull Request и решает проблему;
- умеет запускать расширенные сборки;
- постоянно обновляется — и его функционал расширяется.
Другие возможности Thor’а
- Краткое описание падений.
- Ссылки на артефакты.
- Помощь разработчикам с проблемами, которые они внесли своими правками.
Когда у разработчика падает валидационный билд, даже по причине его изменений, Thor сообщает об ошибке. Он непосредственно пишет в Pull Request и прикладывает прямую ссылку на артефакты сборки и тестов, которые упали.

Это важно потому, что у нас в билде 150 зависимостей, множество сборок и тестов. Иногда бывает сложно найти, в чём конкретно проблема, а Thor обо всём сообщает, чтобы разработчику было удобнее разобраться.
Механизм flaky-проблем

Мы не просто находим проблемы и перезапускаем билды, а стараемся делать так, чтобы билды вообще не падали — или падали как можно реже. Поэтому мы сделали функциональность flaky-проблем. С ней любую проблему можно пометить вручную как flaky. И если тест упадёт по её вине, валидационный билд всё равно будет считаться успешным.
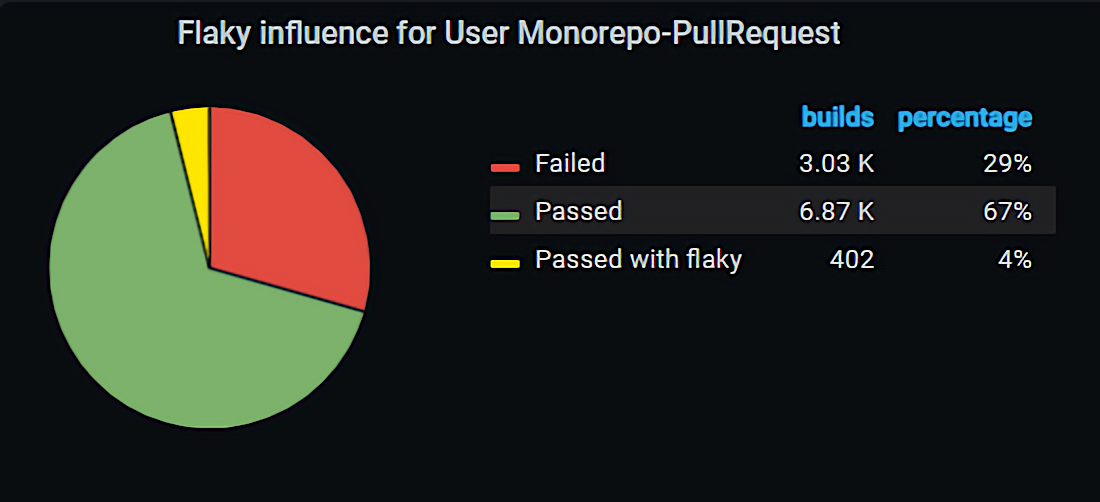
Также у нас есть flaky-робот, который подключается, когда на нескольких Pull Request’ах разработчиков тест падает по одной и той же причине. Он помечает это flaky-проблемой, которая игнорируется.
Благодаря функциональности flaky-проблем, около 4% валидационных билдов проходит, хотя могли упасть.
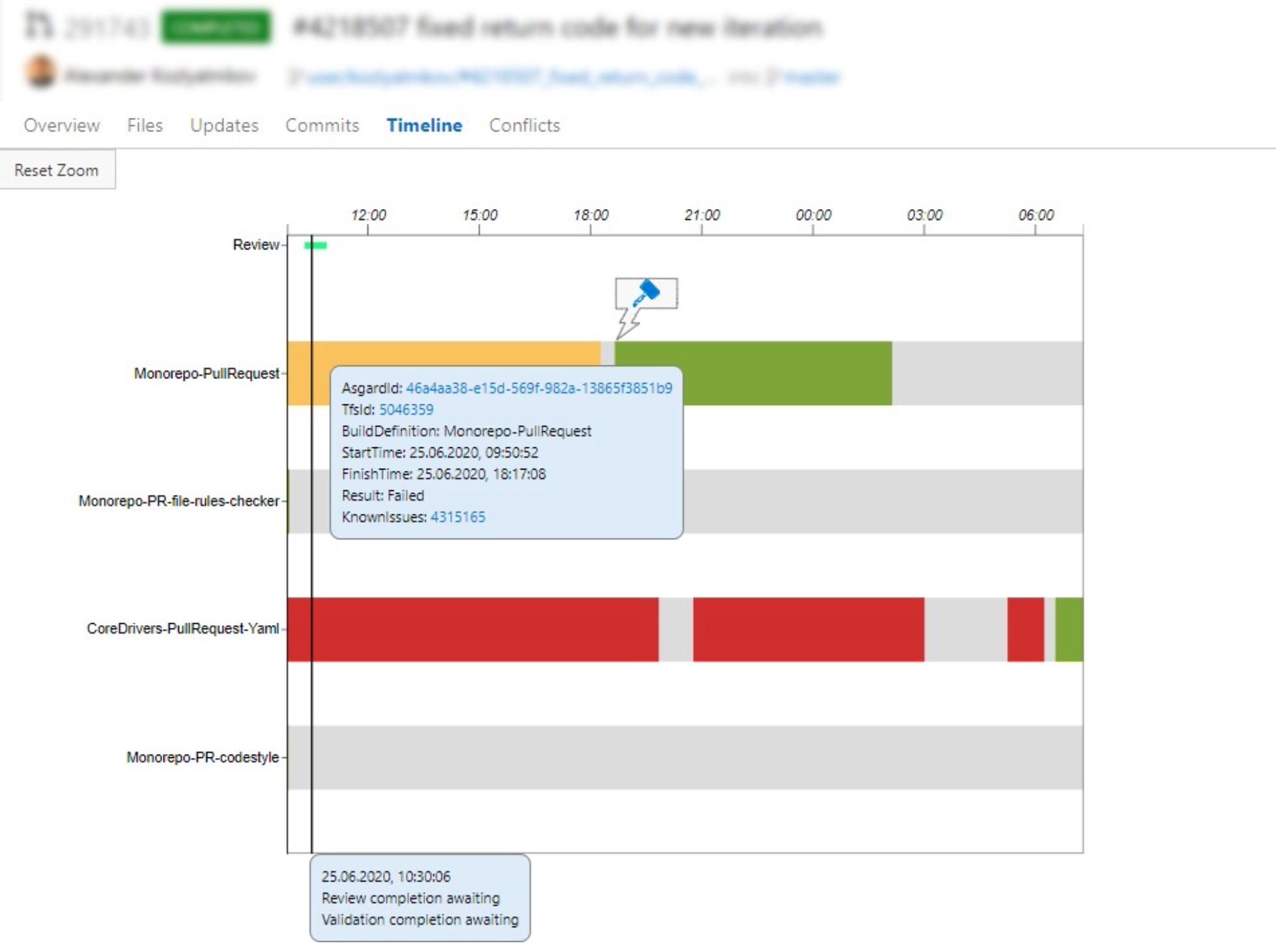
Timeline
Эта usability-фича нужна для удобства наших разработчиков. В каждом Pull Request’е у разработчика есть timeline, в котором отображается:
- какие валидационные билды запускались;
- как они перезапускались — вручную или автоматически;
- какие глобальные проблемы произошли, из-за чего были падения;
- какова продолжительность валидационных билдов;
- сколько длилось ревью его Pull Request’а;
- периоды и причины постановки на паузу.
Каждый разработчик может зайти и посмотреть эту информацию в своём Pull Request’е.
Статистика удовлетворённости разработчиков
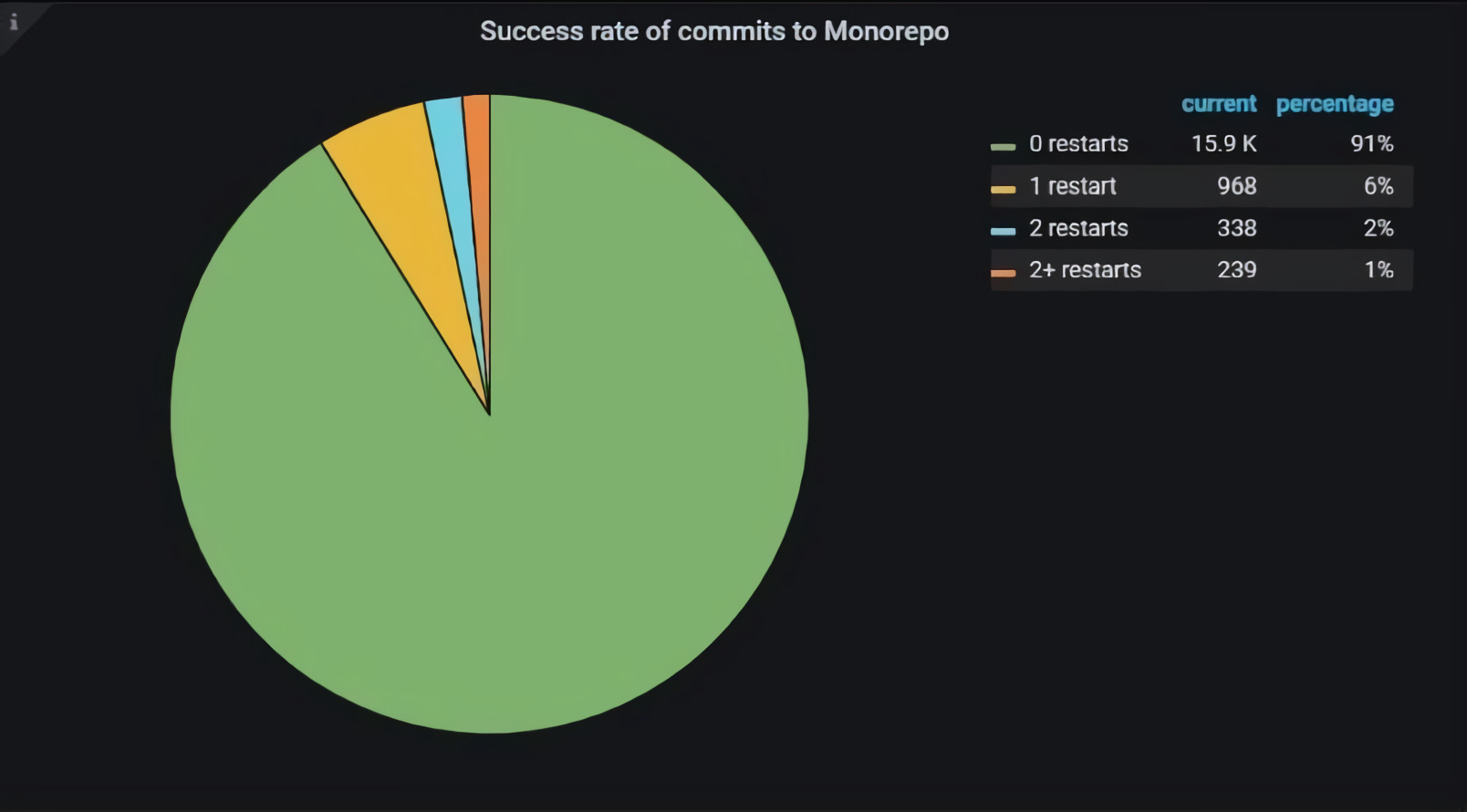
Мы собираем статистику и на её основе принимаем различные решения. В том числе мы научились собирать статистику удовлетворённости разработчиков.
Мы считаем количество перезапусков валидационных билдов от последнего апдейта до комплита Pull Request’а.
Например, мы в последний раз проапдейтили Pull Request и валидационный билд упал. Мы, не делая в своём Pull Request’е никаких апдейтов, просто его перезапустили. После этого билд прошел, и мы закомплитили Pull Request. Скорее всего, в первый раз валидационный билд упал по каким-то внешним причинам, не связанным с изменениями в этом Pull Request’е.
Так, мы считаем, какое количество Pull Request’ов заливается без ретраев валидационных билдов, с 1, 2, 3 и более ретраями. В данный момент без ретраев валидационных билдов у нас заливается в репозиторий порядка 90% Pull Request’ов, что мы считаем неплохим результатом. Однако нам есть к чему стремиться. Мы будем продолжать развивать собственные инструменты. Вкупе с нашими бенефитами это добавит спокойствия разработчикам.

2К открытий2К показов

%%excerpt%% Кибератаки, вредоносы, сбои в системе — дайте отпор всему этому в игре от Kaspersky и Tproger. И да помогут вам знания С++!

Нейрогороду нужна помощь! Вооружитесь знаниями JavaScript и устраните все баги в виртуальном мегаполисе.

Как придумывать, формулировать и откуда брать гипотезы для UX-исследований, и какие гипотезы считать эффективными.

Рассказываем, как мы четыре раза пытались запустить совместную учебу в разных форматах, поняли, в чем проблема, и на пятый подобрали нужный.