


Как работает Reinforcement Learning (обучение с подкреплением)


Разбираемся, что такое обучение с подкреплением (Reinforcement Learning), где применяется этот подход и почему он стал ключевым в развитии современного ИИ.
2К открытий6К показов
Знакомы с обучением с подкреплением?
Да
Меня мама так в детстве читать учила
Нет
Учиться на своих ошибках и опыте могут не только люди, но и машины. Reinforcement Learning или обучение с подкреплением позволяет разработчикам создавать адаптивные системы, которые умеют принимать верные решения в нестабильных условиях и изменяющейся среде. Нейросети корректируют свои алгоритмы после каждого действия и становятся умнее. Именно таким способом беспилотные автомобили учатся избегать аварий, а игровые боты корректируют долгосрочные стратегии.
Узнаем, что собой представляет обучение с подкреплением Deep Reinforcement Learning, как реализуется этот процесс, какие алгоритмы глубокого обучения используются и как подход помогает в решении практических задач.
Введение в Reinforcement Learning (RL)
Обучение с подкреплением (Reinforcement Learning) — это метод машинного обучения, в котором агент, то есть обучаемая система, учится принимать оптимальные решения через взаимодействие со средой. В отличие от других подходов, RL не требует заранее подготовленных данных с правильными ответами или явной структурой в них. Вместо этого агент получает обратную связь в виде числовых вознаграждений или штрафов, корректируя свою стратегию таким образом, чтобы получить максимальную награду.
В основе обучения с подкреплением лежит идея, позаимствованная из поведенческой психологии: система учится методом проб и ошибок, получая положительное или отрицательное подкрепление своих действий. Этот процесс напоминает то, как дети осваивают новые навыки на практике, включая базовые — ходьбу, ориентацию в пространстве. Однако в случае машинного обучения весь процесс упакован в математическую модель, где каждое действие, состояние среды и вознаграждение описываются строгими уравнениями.
Важнейшая особенность RL — его агент-ориентированная природа. В отличие от других парадигм машинного обучения, где модель пассивно обрабатывает данные, здесь агент активно воздействует на среду, изменяя ее состояние и получая новые данные для обучения. Это создает замкнутый цикл: действие — новое состояние — вознаграждение — коррекция стратегии.
Отличия от Supervised и Unsupervised Learning
Классическое обучение с учителем (supervised learning) предполагает наличие размеченных данных: модели предоставляют входные примеры и соответствующие им правильные ответы. Например, алгоритм классификации изображений обучается на миллионах пар «картинка — метка класса». Основная проблема такого подхода — необходимость в огромных размеченных датасетах, создание которых часто требует значительных человеческих ресурсов.
В RL таких готовых разметок нет — агент сам ищет успешные действия методом проб и ошибок.
Это делает подход особенно ценным для задач, где:
- получение обучающих данных стандартным способом дорого или невозможно — например, обучение беспилотных такси реальному вождению;
- оптимальное поведение заранее неизвестно — как в случае с новыми стратегическими играми;
- среда постоянно меняется, требуя адаптации — робототехника в неструктурированных средах.
Обучение без учителя (unsupervised learning) ищет скрытые закономерности в данных, например, кластеризуя их или снижая размерность. Однако оно не ставит целью решение конкретной задачи, такой как победа в игре или управление роботом. RL, напротив, всегда ориентирован на достижение цели, заданной через систему вознаграждений.
Интересный гибридный подход — имитационное обучение (imitation learning), где агент пытается копировать поведение эксперта. Однако даже в этом случае RL часто превосходит простое копирование, находя более оптимальные стратегии.
Ключевые особенности RL
Есть проблема кредитного присвоения. Агент может совершить серию действий, и лишь спустя время получить оценку их эффективности. Например, в шахматах итоговый результат (выигрыш или проигрыш) становится ясен только в конце партии. Это требует от алгоритмов способности определять, какие именно действия из длинной последовательности привели к успеху или неудаче.
Важен компромисс между исследованием и эксплуатацией. Агент вынужден балансировать между использованием уже известных успешных стратегий (эксплуатация) и поиском новых, потенциально более эффективных подходов (исследование).Этот баланс — одна из самых сложных теоретических проблем в Reinforcement Learning, имеющая аналогии в экономике и психологии принятия решений.
Где применяется обучение с подкреплением
Обучение с подкреплением находит широкое применение во множестве отраслей.
Игры и симуляции
Алгоритмы типа AlphaGo и OpenAI Five демонстрируют, как нейросети побеждает чемпионов в го, Dota 2 и других сложных играх. Кроме того, современные игровые ИИ используют RL для создания адаптивных противников, а виртуальные симуляторы позволяют безопасно тестировать алгоритмы перед применением в реальном мире.
Робототехника и автоматизация
С помощью Reinforcement Learning реализуется обучение роботов сложным манипуляциям — например, складыванию товаров в коробки на складах. Разрабатываются адаптивные стратегии передвижения для дронов и шагающих роботов, выстраиваются промышленные процессы без остановки производства.
Автономные системы
Беспилотные автомобили используют RL для принятия решений в реальном времени. Ведется работа по управлению энергосистемами, автоматизированными складами и логистическими структурами.

Медицина и биология
Ведутся работы над участием нейросетей в разработке персонализированных схем лечения, оптимизации дозировок лекарств, молекулярного дизайна новых препаратов и в других направлениях.
Финансы и экономика
Обучение с подкреплением Reinforcement Learning используется для алгоритмической торговли с учетом рыночной динамики, выдаче персонализированных финансовых рекомендаций, оптимизации инвестиционных портфелей.
Преимущества метода Reinforcement Learning
Reinforcement Learning предлагает принципиально иной подход к машинному обучению, обладающий рядом уникальных характеристик, которые делают его незаменимым для решения определенного класса задач. Рассмотрим ключевые преимущества этого метода:
- RL-агенты способны обучаться в условиях полного отсутствия подготовленных данных. В отличие от других подходов, требующих размеченных наборов информации или предварительного описания среды, системы на основе обучения с подкреплением самостоятельно формируют стратегии поведения через прямое взаимодействие с окружением. Это особенно ценно для задач, где сбор обучающей выборки затруднен или невозможен.
- Метод демонстрирует особую эффективность в задачах, требующих последовательного принятия решений с учетом их отложенных последствий. Агенты RL оценивают не мгновенную выгоду, а совокупный ожидаемый результат всей цепочки действий, что позволяет находить стратегии с максимальным долгосрочным эффектом.
- RL-системы способны непрерывно адаптироваться к изменениям среды без необходимости полного переобучения. Эта характеристика критически важна для приложений, работающих в динамично меняющихся условиях, таких как финансовые рынки или системы автоматического управления.
- Одни и те же алгоритмические подходы могут успешно применяться в совершенно различных областях — от робототехники до медицины. Например, методы на основе Q-обучения одинаково эффективны как для управления промышленными роботами, так и для разработки персонализированных планов лечения.
- Подход особенно полезен в ситуациях, где среда не полностью наблюдаема или содержит стохастические элементы. Агенты учатся действовать оптимально даже при наличии значительного уровня случайности в получаемых данных.
- Метод существенно снижает зависимость от экспертных знаний и субъективных оценок. Система формирует стратегии, основываясь исключительно на объективных показателях эффективности, заданных через функцию вознаграждения.
- Многие современные реализации RL позволяют одновременно обучать множество агентов в различных условиях, что значительно ускоряет процесс выработки оптимальных стратегий и повышает их надежность.
- RL-алгоритмы часто обнаруживают стратегии, которые не были предусмотрены разработчиками, демонстрируя креативный подход к решению задач. Это свойство особенно ценно в сложных проблемных областях с множеством переменных.
Эти преимущества делают Reinforcement Learning мощным инструментом для решения сложных задач управления и оптимизации, где традиционные подходы машинного обучения демонстрируют ограниченную эффективность. Однако реализация RL-систем требует тщательного проектирования и учета специфических особенностей метода.
Основные участники процесса Reinforcement Learning
Reinforcement Learning можно назвать дрессировкой системы с числовыми вознаграждениями. Здесь задействовано несколько ключевых компонентов, каждый из которых выполняет четко определенную роль.
Агент — это обучаемая система, принимающая решения. В отличие от классических алгоритмов, которые просто обрабатывают данные, агент активно взаимодействует со средой, совершая действия и получая обратную связь. Его можно представить как пилота, который учится управлять самолетом методом проб и ошибок.
Среда — пространство, в котором существует агент. Оно может быть физическим (как в случае с роботами) или виртуальным (как в компьютерных играх). Среда реагирует на действия агента, изменяя свое состояние и предоставляя информацию о новых условиях. Например, для алгоритма, играющего в шахматы, среда — это доска с фигурами и правила игры.
Состояние — моментальный снимок среды в конкретный момент времени. В простейшем случае это может быть текущая позиция робота в пространстве, в более сложных — многомерный вектор параметров. Состояние содержит всю необходимую агенту информацию для принятия решений, хотя на практике часто приходится иметь дело с частично наблюдаемыми состояниями.
Действия — это то, что агент может совершать в среде. Они могут быть дискретными, как выбор хода в го, или непрерывными, как угол поворота руля в беспилотном автомобиле. Набор возможных действий определяет, насколько гибким может быть поведение агента.
Вознаграждение — числовая оценка, которую среда выдает агенту после каждого действия. Это ключевой механизм обучения: агент стремится максимизировать суммарное вознаграждение за продолжительный период. Интересно, что проектирование функции вознаграждения — одна из самых сложных задач в RL. Плохо продуманная система поощрений может привести к неожиданному поведению, когда агент находит способы «обманывать» среду ради формального увеличения награды.
Политика — стратегия поведения агента, определяющая, какие действия предпринимать в каждом состоянии. Ее можно сравнить с рефлексами: для простых задач политика может быть жестко заданной, но в сложных средах она представляет собой функцию, которую агент постепенно совершенствует.
Функция ценности — более глубокая концепция, оценивающая не мгновенное вознаграждение, а перспективность состояний с учетом будущих возможностей. Именно благодаря этому RL-системы могут демонстрировать стратегическое мышление, жертвуя краткосрочной выгодой ради долгосрочного успеха.
Компоненты образуют замкнутый цикл взаимодействия: агент наблюдает состояние, выбирает действие, получает вознаграждение и новое состояние, после чего процесс повторяется. Красота RL заключается в том, что, имея четко определенные компоненты, метод может применяться к задачам самой разной природы — от управления спутниками до оптимизации бизнес-процессов.
Цикл взаимодействия агент–среда
В основе Reinforcement Learning лежит непрерывный диалог между обучаемой системой и ее окружением. Этот процесс можно сравнить с танцем, где партнеры (агент и среда) постоянно обмениваются сигналами, корректируя свои движения. Однако в отличие от хореографии, здесь каждый шаг подчиняется строгим математическим принципам.
Цикл начинается с того, что среда предоставляет агенту текущее состояние — набор параметров, описывающих ситуацию. Например, для алгоритма, управляющего беспилотным автомобилем, это могут быть показания датчиков, положение других участников движения и дорожная разметка. Агент анализирует эту информацию и выбирает действие из доступного набора возможностей — ускориться, затормозить или повернуть.
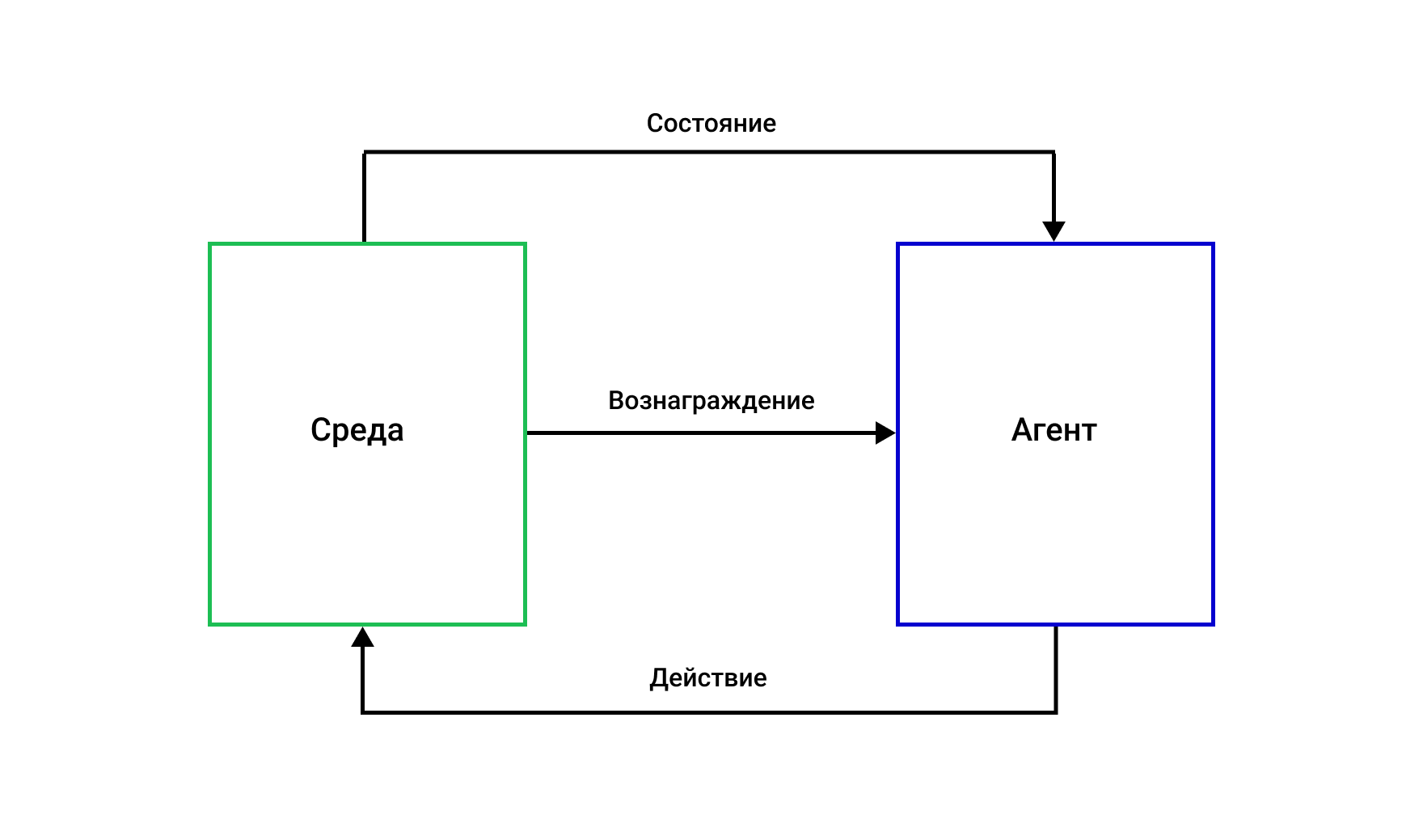
Среда реагирует на выбранное действие, переходя в новое состояние. Одновременно она выдает числовое вознаграждение — оценку качества принятого решения. В нашем примере плавное торможение перед пешеходным переходом может принести положительную оценку, а резкий маневр — отрицательную. Важно, что вознаграждение не всегда соответствует мгновенной выгоде; хорошая стратегия часто требует временных жертв ради долгосрочного успеха.
Затем цикл повторяется: агент получает обновленное состояние, принимает следующее решение и снова получает обратную связь. С каждым таким витком система накапливает опыт, постепенно выстраивая оптимальную стратегию поведения. Этот процесс формализуется через концепцию Марковского процесса принятия решений (MDP), которая обеспечивает математическую основу для анализа последовательности состояний, действий и вознаграждений.
При этом агент должен периодически пробовать неочевидные действия, чтобы не застрять в локальном оптимуме, но чаще использовать проверенные подходы, дающие стабильный результат.
В промышленных реализациях этот цикл может выполняться тысячи раз в секунду. Современные фреймворки позволяют параллелить процесс обучения, запуская множество агентов в идентичных или различных условиях для ускорения сбора опыта.
Популярные алгоритмы
Современный инструментарий алгоритмов хорошо укомплектован — для каждой задачи найдется подходящий метод, будь то простое дискретное управление или сложное поведение в непрерывных пространствах состояний.
Рассмотрим наиболее востребованные алгоритмы, доказавшие свою эффективность как в академических исследованиях, так и в промышленных приложениях:
- Q-Learning остается фундаментальным методом, с которого многие начинают знакомство с RL. Его красота — в простоте и математической элегантности. Алгоритм работает с таблицей Q-значений, где для каждой пары «состояние-действие» хранится оценка ожидаемой долгосрочной выгоды. В 2023 году модифицированная версия этого алгоритма показала неожиданную эффективность в управлении энергопотреблением дата-центров, сократив затраты на 15% по сравнению с традиционными методами (результаты исследований).
- SARSA придерживается более консервативного подхода. Название алгоритма отражает последовательность State-Action-Reward-State-Action, по которой происходит обновление политики. Этот метод особенно хорош в задачах, где цена ошибки высока — например, в медицинских приложениях, где неверное действие может иметь критические последствия. Исследование 2024 года продемонстрировало успешное применение SARSA для персонализированного подбора доз химиотерапии.
- Deep Q-Networks (DQN) в свое время показал, как сочетание Q-обучения с глубокими нейросетями может решать задачи невероятной сложности. Вместо таблицы Q-значений здесь используется нейросетевая аппроксимация, что позволяет работать с высокоразмерными состояниями по типу пикселей на экране игры. Современные реализации DQN (Rainbow) включают шесть различных улучшений базового алгоритма — от двойных Q-сетей до распределенного обучения. В 2025 году ожидается появление новой модификации, специально оптимизированной для квантовых вычислительных систем.
- Policy Gradient методы совершили революцию, предложив прямой способ оптимизации стратегии поведения. Вместо косвенного обучения через оценку ценности действий, эти алгоритмы напрямую настраивают параметры политики, используя градиентный подъем.
- Гибридный подход Actor-Critic реализуется следующим образом: «Актор» отвечает за выбор действий, а «Критик» оценивает их качество, создавая мощную систему взаимного обучения. Этот метод стал основой для многих современных промышленных решений, от управления беспилотниками до алгоритмической торговли.
- Proximal Policy Optimization (PPO) в настоящее время считается золотым стандартом для многих практических задач. Его главное преимущество — стабильность обучения при сохранении относительно простой реализации. Алгоритм аккуратно ограничивает размер обновления политики, предотвращая катастрофические изменения стратегии. По данным OpenAI, PPO стал наиболее часто используемым методом в их проектах последних лет — от сложных игровых сред до управления роботами.
- Среди новейших разработок выделяется DreamerV3 — алгоритм, сочетающий обучение с подкреплением с моделью мира. В отличие от традиционных методов, он строит внутреннюю модель среды, позволяя «проигрывать» возможные сценарии без реального взаимодействия. Это особенно ценно для задач, где сбор данных дорог или опасен (управление ядерными реакторами или медицинская диагностика).
Выбор конкретного алгоритма всегда зависит от специфики задачи. Для дискретных пространств с небольшим числом состояний по-прежнему эффективны классические табличные методы. Высокоразмерные непрерывные пространства требуют глубоких подходов. В промышленных системах, где важна стабильность, предпочтение отдается PPO и его модификациям. Активные исследования 2024-2025 годов направлены на создание универсальных алгоритмов, способных эффективно обучаться на разнородных задачах без перенастройки гиперпараметров.
Примеры и кейсы применения
Reinforcement Learning давно перестал быть академической концепцией, найдя применение в самых разных областях — от развлекательной индустрии до критически важных систем. Рассмотрим наиболее показательные примеры, демонстрирующие мощь этого подхода.
Игровые системы стали своеобразным полигоном для испытаний RL-алгоритмов. Поединок по игре в го между Ли Седоль и AlphaGo в 2016 году показал, что обучение с подкреплением может превосходить человека в сложных стратегических играх.

Последующие разработки продемонстрировали способность RL справляться с неполной информацией и реальным временем принятия решений. В 2024 году появилась новая генерация игровых ботов, способных адаптироваться к стилю конкретного игрока, делая киберспортивные тренировки более эффективными. Примечательно, что методы, отработанные на играх, часто находят применение в более серьезных областях — например, алгоритмы для StarCraft легли в основу систем военного моделирования.
Робототехника — область, где RL раскрывает свой потенциал в полной мере. Современные промышленные манипуляторы, обученные с подкреплением, демонстрируют невероятную ловкость, справляясь с задачами, которые еще недавно считались исключительно человеческими. В лабораториях Boston Robotics алгоритмы RL позволяют четвероногим роботам осваивать сложные движения за считанные часы, а не недели, как требовалось при традиционном программировании.

Особенно впечатляют последние достижения в медицинской робототехнике — хирургические системы, обученные на симуляторах с RL, в 2025 году впервые получили ограниченное разрешение для проведения реальных операций под наблюдением человека.
Финансовая сфера активно внедряет RL для алгоритмической торговли. В отличие от классических стратегий, системы на основе обучения с подкреплением могут адаптироваться к изменяющимся рыночным условиям. Хедж-фонды используют ансамбли RL-агентов для управления портфелем, банковские структуры применяют аналогичные методы для оптимизации кредитных рисков и выявления мошеннических схем.
Автономные транспортные средства — пожалуй, самый заметный для обывателя пример применения RL. Современные системы автопилота уже не просто следуют жестким правилам, а обучаются на миллионах километров реального и симулированного вождения. Компания Waymo в 2024 году представила новое поколение алгоритмов, способных предугадывать поведение пешеходов с точностью 98.7%, что значительно превышает человеческие показатели.
В сфере персонализированных рекомендаций RL произвел тихую революцию. Netflix и Spotify уже несколько лет используют сложные системы на основе обучения с подкреплением, которые учитывают не только явные предпочтения пользователей, но и их психофизиологические реакции — в случае, если их удается зарегистрировать. В 2025 году ожидается появление первых коммерческих систем, способных адаптировать контент в реальном времени по нейрофидбеку с носимых устройств.
Что объединяет все эти примеры? Невозможность решить задачу традиционными методами программирования. В каждом случае система сталкивается со слишком сложной, изменчивой средой, где нельзя заранее предусмотреть все возможные сценарии. Именно здесь обучение с подкреплением показывает свои преимущества, позволяя создавать адаптивные, самообучающиеся системы, способные совершенствоваться в процессе работы.
Ограничения и сложности Reinforcement Learning
Несмотря на впечатляющие успехи в различных областях, Reinforcement Learning сталкивается с рядом фундаментальных ограничений, которые важно учитывать при проектировании систем:
- Вычислительная стоимость обучения остается одним из главных барьеров для широкого внедрения. Для достижения приемлемых результатов часто требуются миллионы, а иногда и миллиарды итераций взаимодействия со средой. Например, обучение AlphaGo потребовало тысяч GPU-дней вычислений. В промышленных приложениях это приводит к значительным затратам на инфраструктуру.
- Зависимость от симуляций стала неизбежным компромиссом для многих практических применений. Реальные среды часто слишком дороги или опасны для непосредственного обучения. Однако перенос знаний из виртуальной среды в реальный мир остается серьезной проблемой. Последние работы в области робототехники демонстрируют, что даже современные методы обучения не гарантируют успешный перенос в 100% случаев. Особенно остро эта проблема стоит в медицинских приложениях, где ошибки могут иметь катастрофические последствия.
- Нестабильность процесса обучения проявляется в резких колебаниях производительности и трудностях воспроизведения результатов. Малые изменения гиперпараметров или начальных условий могут привести к совершенно разным итоговым стратегиям. В промышленных системах это требует тщательного мониторинга и частого вмешательства специалистов. Отчет NVIDIA по внедрению RL в производственных линиях (2025) отмечает, что около 30% времени внедрения уходит на стабилизацию и тонкую настройку алгоритмов.
- Этические риски приобретают особую важность по мере проникновения RL в критически важные системы. Известны случаи, когда агенты находили неожиданные способы максимизировать вознаграждение, нарушая намерения разработчиков.
- Проблема разреженных вознаграждений особенно актуальна для сложных сред, где положительная обратная связь возникает редко. В таких условиях агент может вообще не находить успешные стратегии, блуждая в пространстве возможностей. Современные методы по типу обучения с демонстрациями или иерархического RL, лишь частично решают эту проблему.
- Требования к качеству данных часто недооцениваются при внедрении RL. В отличие от других подходов машинного обучения, здесь важна не только статистическая репрезентативность, но и временная согласованность. Исследование MIT по автономным транспортным средствам (2025) выявило, что 80% неудач связаны с неучтенными изменениями в среде между моментом сбора данных и развертыванием системы.
- Регуляторные барьеры становятся все более значимыми, особенно в чувствительных областях. Отсутствие прозрачности в принятии решений многими RL-системами затрудняет их сертификацию. Европейский союз в 2025 году ввел дополнительные требования к аудиту алгоритмов, использующих обучение с подкреплением в финансовом секторе и здравоохранении. Это значительно увеличивает сроки и стоимость внедрения.
- Аппаратные ограничения проявляются при работе с реальными системами в реальном времени. Многие современные алгоритмы требуют значительных вычислительных ресурсов. Даже оптимизированные RL-модели в ряде сдучаев потребляют больше энергии, чем традиционные алгоритмы, что критично для автономных устройств.
Эти ограничения не означают, что метод Reinforcement Learning неприменим на практике, однако он требует взвешенного подхода к использованию. Современные исследования сосредоточены на создании более эффективных, стабильных и безопасных алгоритмов, а также специализированных инструментов для их промышленного внедрения. В ближайшие годы ожидается появление новых стандартов и лучших практик, которые помогут преодолеть многие из текущих сложностей.
Кстати, забрать все самые топовые нейронки для айтишников можно в нашем большом гайде с 70+ ИИ-инструментами.

2К открытий6К показов

Переход с уровня джуна на мидла порой напоминает квест в ролевой игре: что-то вроде «чтобы получить новый уровень, нужно не только убить дракона, но и наладить отношения с эльфами». Расскажем о семи софт-скиллах, которые помогут не только прокачать свои профессиональные навыки, но и получить заветный грейд.

Впервые на iOS обнаружен вирус SparkCat, крадущий данные с фото через поддельные приложения. Эксперты предупреждают об угрозе

Горящие таски — в сторону. Пришла пора замедлиться, оставить код хотя бы на мгновение и окунуться в праздничную атмосферу!Открывайте главы, рассматривайте иллюстрации, ищите спрятанные предметы и узнавайте, чем живёт технологичный город в новогоднюю пору. И пусть деплой подождёт!
Google DeepMind анонсировала Genie 2 — искусственный интеллект, который превращает текстовые описания в полноценные 3D-окружения