Очевидно, что разработанный проект еще очень далек от того, чтобы с ним могли работать пользователи:
В жизненном цикле приложений проекта возникают случаи, когда какие то параметры необходимо изменить.
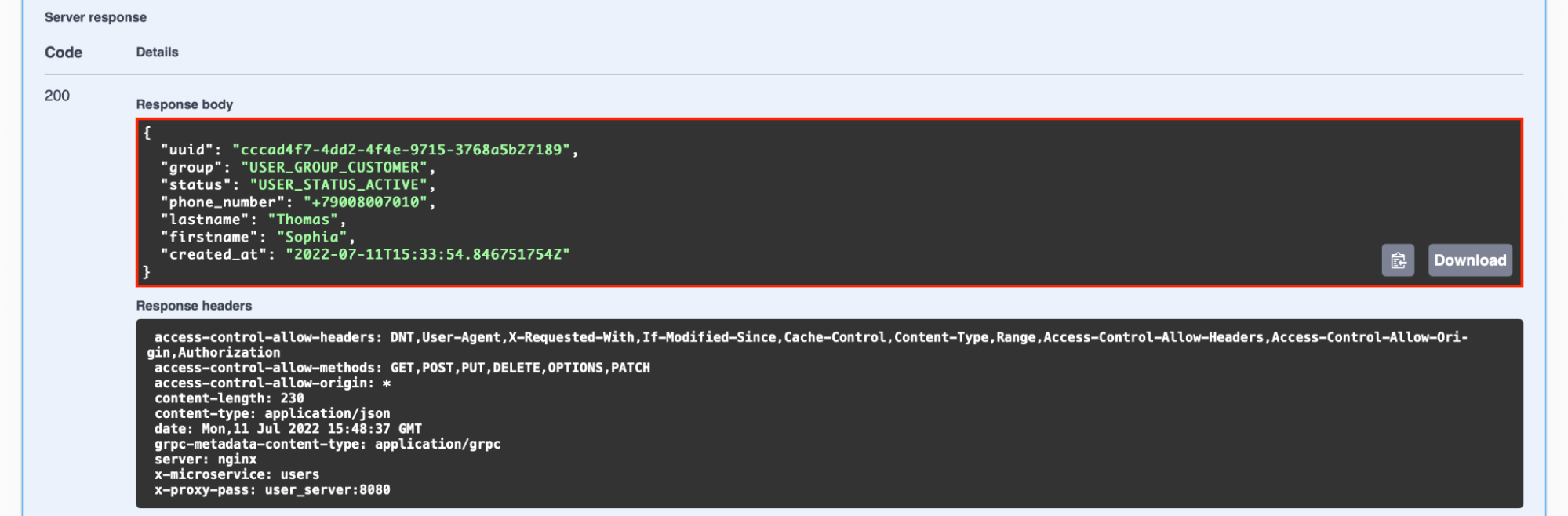
В зависимости от состояния, пользователю доступны разные методы API
Пользователь может получать или изменять только те данные, которыми владеет.
Но прежде чем мы решим описанные проблемы, необходимо понять:
Как поддерживать несколько версий проекта.
Как без труда удовлетворять зависимости одних сервисов от других.
Ветвление репозитория
На изображении представлен реальный жизненный цикл проекта:
В master работает версия v1.0 на production-серверах.
В версии v1.0 нашли баги и подготовили hotfixes.
Hotfixes влили в master и выложили на production-серверы, получив версию проекта v1.1.
Одновременно с master живет новая версия проекта в develop на develop-серверах.
В нее тоже необходимо донести hotfixes с master.
Кроме того, разработчики заливают в develop новые задачи из веток features.
Затем в какой то момент делается срез develop в ветку release.
Release-ветка стабилизируется, проходит регресс-тестирование и выкладывается на production-сервера.
Данный жизненный цикл прекрасно ложится в стратегию ветвления GitFlow.
Использую эту стратегию в своем проекте мы:
Наводим порядок в именовании веток репозитория: a. feature/идентификатор_задачи_в_трекере. b. hotfix/идентификатор_задачи_в_трекере. c. release/Х.Х.Х.
Завязываем сборки CI/CD на стандартизированные префиксы веток.
Делаем независимые друг от друга сборки фичей, фиксов и релизов .
Получаем ситуацию, в которой поддержка текущей версии не мешает разработке новой версии проекта.
Команда проекта ogon.ru не использует консольную программу git-flow, т.к. она не ложится в один процесс с CI/CD системами типа GitLab, поэтому давайте создадим необходимые ветки сами:
git checkout -b release/1.0.0 master # зафиксировали версию первой статьи
git checkout -b develop master
git checkout -b feature/article-2 develop # будем разрабатывать вторую статью в отдельной ветке
Таким образом получили результат:
Читатели первой статьи получают рабочий пример в ветке release/1.0.0.
Функционал второй статьи будет разрабатываться в ветке feature/article-2.
Этот код плох тем, что мы вручную удовлетворяем зависимости конструкторов:
usersrvimpl.NewUserProductService
userapp.NewServer
Возможно, сейчас проблема не кажется такой серьезной, но в реальном проекте у одного сервиса может быть десяток зависимостей, которые, в свою очередь, могут иметь свои зависимости. В итоге реальный проект имеет большой граф зависимостей, который сложно удовлетворить вручную.
Для решения проблемы существуют популярные пакеты удовлетворяющие зависимости:
uber fx + uber dig.
google wire.
Оба варианта решают проблемы зависимостей, но мы остановились на fx + dig. У fx под капотом рефлексия, и на этапе компиляции мы не увидим ошибок неудовлетворения зависимостей. Однако мы увидим эти ошибки при запуске программы, затем fx предлагает модель приложения и позволяет группировать зависимости. Давайте создадим универсальный конструктор приложения pkg/common/adapter/application/application.go:
Теперь давайте рассмотрим файл с конструкторами pkg/user/infra/constructors.go:
var Constructors = fx.Provide(
usersrvimpl.NewFxUserService,
usersrvimpl.NewFxUserProductService,
)
Как мы видим, файл с конструкторами имеет простой вид. Все конструкторы для fx имеют префикс NewFx. Все пакеты проекта должны содержать подобные файлы с конструкторами.
Как понять, что код рабочий? Конечно, можно внедрить код в проект и проверить, как отрабатывает приложение, но это слишком дорогой путь, особенно в больших проектах. Чтобы проверить реализацию конкретного интерфейса, необходимо его протестировать. Для тестирования мы пишем unit-тесты с помощью пакета testify.
Напишем тестовый набор для поставщика настроек pkg/common/adapter/application/provider_test.go:
type Config struct {
A A
Partition int
}
type A struct {
B string
C struct {
D bool
F int
}
}
func TestConfigProviderSuite(t *testing.T) {
suite.Run(t, new(ConfigProviderSuite))
}
type ConfigProviderSuite struct {
suite.Suite
}
func (s *ConfigProviderSuite) TestPopulate() {
reader := strings.NewReader("a: {b: bar, c: {d: true, f: 12}}")
provider, err := application.NewProviderByOptions(config.Source(reader))
s.Nil(err)
var a A
s.Nil(provider.PopulateByKey("a", &a))
s.Equal("bar", a.B)
s.Equal(true, a.C.D)
s.Equal(12, a.C.F)
var f int
s.Nil(provider.PopulateByKey("a.c.f", &f))
s.Equal(12, f)
var cfg Config
s.Nil(provider.Populate(&cfg))
s.Equal(cfg.A, a)
s.Equal(cfg.A.B, a.B)
}
func (s *ConfigProviderSuite) TestExpand() {
var a int
var b string
var c string
varB := "hello world"
err := os.Setenv("VAR_B", varB)
if err != nil {
s.Error(err)
}
reader := strings.NewReader(`
a: 1
b: "$VAR_B"
c: "$VAR_C"
`)
provider, err := application.NewProviderByOptions(config.Source(reader))
s.Nil(err)
s.Nil(provider.PopulateByKey("a", &a))
s.Equal(1, a)
s.Nil(provider.PopulateByKey("b", &b))
s.Equal(varB, b)
s.Nil(provider.PopulateByKey("b", &b))
s.Equal("", c)
}
Запустим в Goland тест с покрытием:
Или запустим тест в терминале:
Важно мерить покрытие кода тестами, т.к. тесты должны проверять все вхождения в условия и циклы. Если не тестировать код, то внедрение новой большой фичи или проведение крупного рефакторинга приведет к тому, что сломается половина функционала, отладка которого будет очень дорогой. Конечно, тесты необходимо поддерживать, но они же дают уверенность в том, что код рабочий.
Теперь мы можем интегрировать поставщика в проект, для этого добавим конструктор в fx pkg/common/adapter/constructors.go:
var Constructors = fx.Provide(
application.NewFxProvider,
…
)
Теперь мы можем конфигурировать наше приложение, вычитывая в пакетах только ту информацию, которая необходима.
Middleware
Для каждого запроса, который принимает наше приложение необходимо выполнить последовательность одинаковых действий:
Аутентифицировать пользователя.
Проверить права пользователя перед выполнением метода API.
Как правило, такие задачи выносятся из бизнес-кода в специальный слой, который называется middleware. Middleware – это небольшая функция, которая:
Перехватывает поток обработки запроса.
Совершает какие-либо действия.
Затем или прекращает выполнение запроса…
…или передает запрос другой middleware или обработчику запроса.
К middleware предъявлены следующие требования:
У нас монорепозиторий, в котором живут сразу несколько микросервисов, поэтому для каждого микросервиса может быть свой массив middleware.
Middleware должны быть отсортированы в определенном порядке. Обрабатывая запрос, middleware наполняют контекст данными, которые могут смотреть другие middleware.
Опишем middleware в pkg/common/adapter/server/grpc/server.go:
type Middleware struct {
Priority int
GrpcOption grpc.UnaryServerInterceptor
MuxOption runtime.ServeMuxOption
}
Наши микросервисы используют и grpc и grpc-gateway, поэтому middleware содержит опции для обоих пакетов.
Для того, чтобы гибко собирать middleware массив, воспользуемся группировкой зависимостей fx:
func NewFxServer(
in FxServerIn,
) (Server, error) {
…
sort.Sort(ByPriority(in.MuxMiddlewares))
sort.Sort(ByPriority(in.GrpcMiddlewares))
interceptors := make([]grpc.UnaryServerInterceptor, len(in.GrpcMiddlewares))
for i, middleware := range in.GrpcMiddlewares {
interceptors[i] = middleware.GrpcOption
}
serverMuxOptions := make([]runtime.ServeMuxOption, len(in.MuxMiddlewares))
for i, middleware := range in.MuxMiddlewares {
serverMuxOptions[i] = middleware.MuxOption
}
srv := &server{
…
grpcServer: grpc.NewServer(
grpc.MaxRecvMsgSize(cfg.MaxReceiveMessageLength),
grpc.MaxSendMsgSize(cfg.MaxSendMessageLength),
grpc.ChainUnaryInterceptor(interceptors...),
),
mux: runtime.NewServeMux(
serverMuxOptions...,
),
…
}
return srv, nil
}
Итак, мы организовали механизм гибкой инициализации middleware, теперь давайте наполним его полезным функционалом.
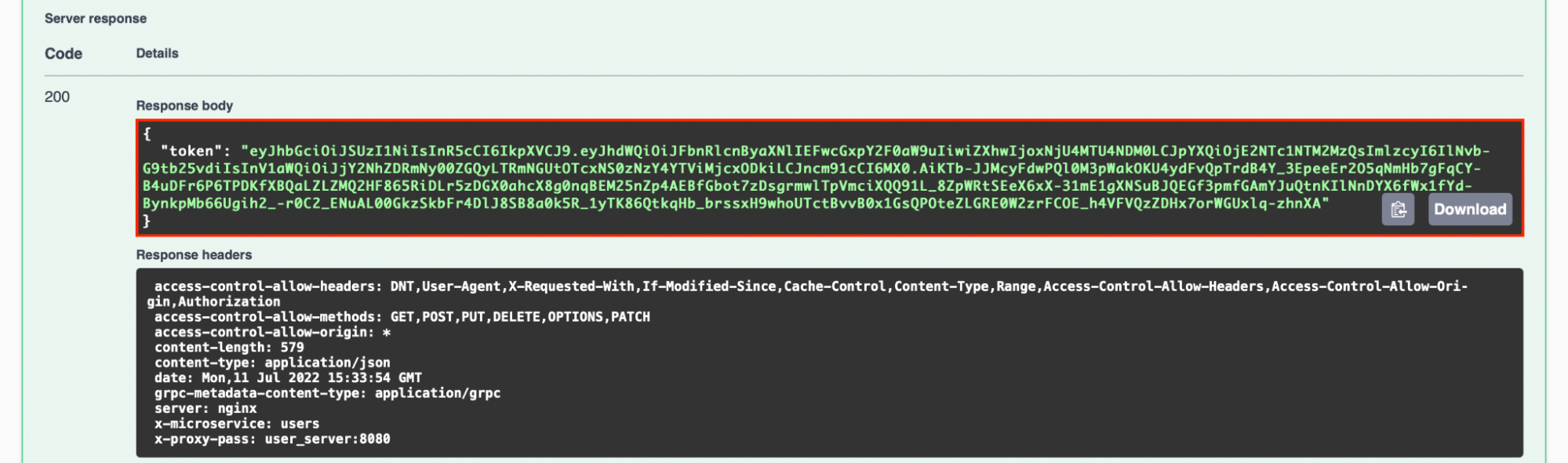
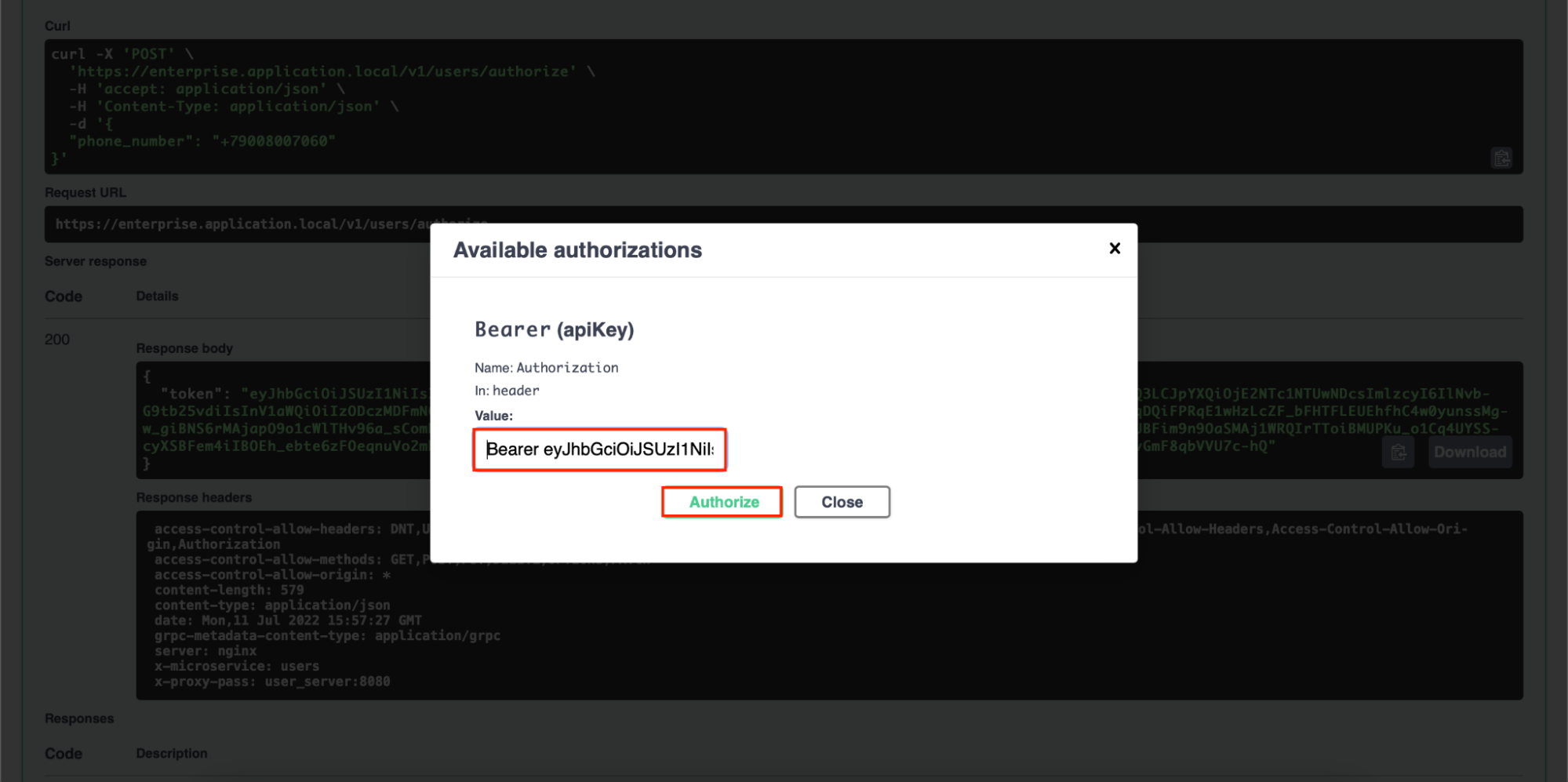
Аутентификация
Наше приложение принимает множество запросов. Чтобы понять от какого пользователя идут запросы, необходимо аутентифицировать пользователя. В качестве механизма аутентификации мы используем JWT. Для создания и валидации JWT необходимы приватный и публичный ключ, создадим их:
Опишем сессию, которую будем хранить в JWT в pkg/common/adapter/auth/claims.go:
type SessionClaims struct {
jwt.StandardClaims
pbv1.Session
}
func (c SessionClaims) Valid() error {
err := c.StandardClaims.Valid()
if err != nil {
return err
}
if len(c.Uuid) == 0 {
return errors.New("uuid is invalid")
}
if _, ok := pbv1.UserGroup_name[int32(c.Group)]; !ok {
return errors.New("group is invalid")
}
return nil
}
Кроме стандартных проверок на подпись и время жизни, мы валидируем содержимое токена, необходимое нашему приложению. Самое время реализовать адаптер pkg/common/adapter/auth/jwt_helper.go:
Если это не удается, создается гостевая сессия и кладется в контекст.
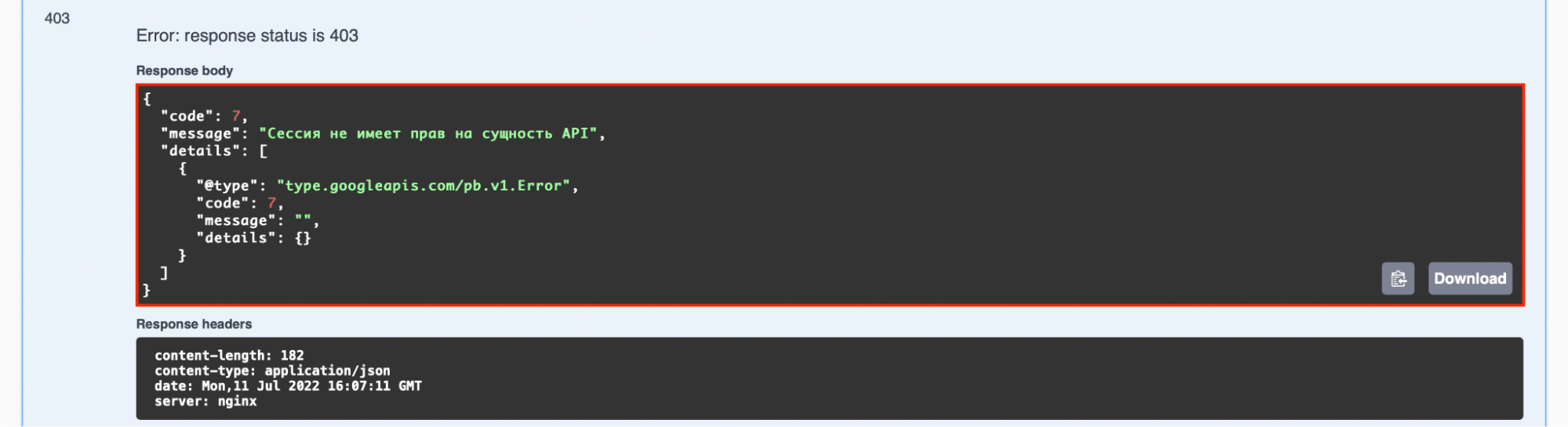
Если удается, и токен невалидный API, то выполнение запроса прерывается.
Если токен валидный, то пользовательская сессия кладется в контекст.
Аутентификация пользователя готова, теперь необходимо понять, может ли пользователь выполнять запрос к конкретному методу API.
RBAC
Наше приложение может быть доступно нескольким группам пользователей:
Неавторизованным пользователям, т.е. гостям
Покупателям
Сотрудникам магазина
У каждой группы пользователей могут быть свои права на выполнение методов API, например:
Гости могут авторизовываться, просматривать товары, но не могут добавлять товар в корзину и осуществлять покупку.
Покупатели могут просматривать товары, добавлять товар в корзину и осуществлять покупку, но не могут управлять пользователями, товарами и покупками.
Сотрудник может управлять пользователями, товарами и покупками, но не может осуществлять покупки.
Очевидно, что для разграничения доступов к API требуется ролевая модель доступов (RBAC). Ролевую модель можем завязать на группы пользователей, которые мы описали ранее в api/proto/v1/user.proto:
Далее необходимо найти пакет, который умеет работать с RBAC. Самым популярным решением является casbin, но его требуется вписать в общую архитектуру проекта. Для этого пишем небольшой адаптер pkg/common/adapter/auth/role_enforcer.go:
Предоставление прав на выполнение тех или иных методов API хорошо, но этого не достаточно, т.к. авторизованный злоумышленник может попытаться получить информацию о другом пользователе. Нам необходимо проверять что переданный JWT-токен может получать или изменять указанные данные. Для этого создадим интерфейс и описание к нему:
type RightsEnforcer interface {
Enforce(ctx context.Context, session pbv1.Session, value protoreflect.Value) (context.Context, error)
}
type RightsEnforcerDescriptorOut struct {
fx.Out
Descriptor RightsEnforcerDescriptor `group:"rights_enforcer"`
}
type RightsEnforcerDescriptor struct {
Name string
RightsEnforcer RightsEnforcer
}
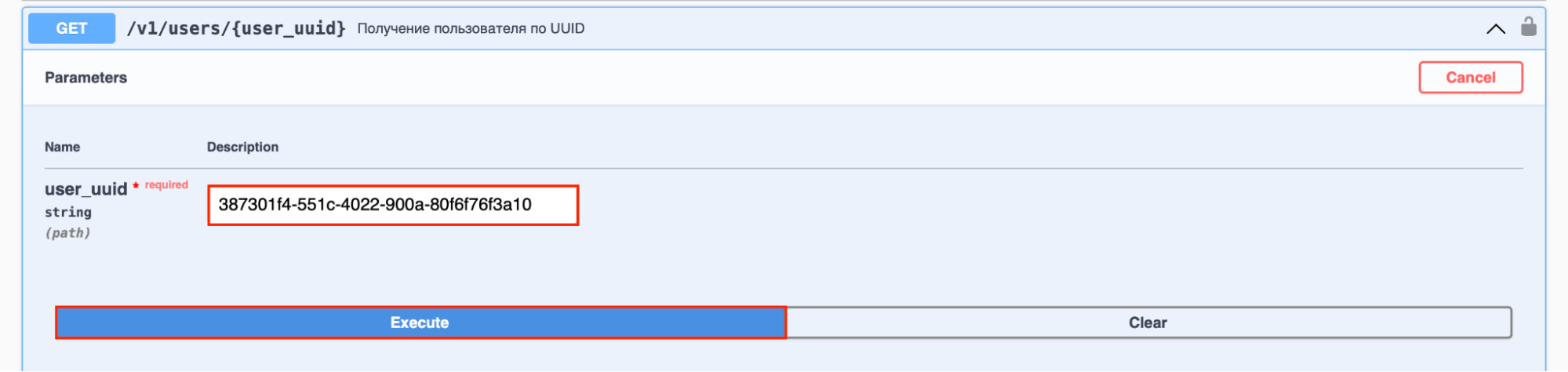
Реализация интерфейса должна регистрироваться в fx по переменной из url-пути и осуществлять какие-либо проверки. Давайте рассмотрим пример.
У нас есть GET-запрос /v1/users/{user_uuid}, в котором используется переменная user_uuid. Напишем и зарегистрируем по user_uuid реализацию RightsEnforcer для пользователя в pkg/user/infra/middleware/user_rights_enforcer.go:
Данная реализация RightsEnforcer сравнивает идентификаторы пользователя из url-пути и JWT-токена. Если идентификаторы не совпадают, тогда выполнение запроса прерывается. Добавим реализацию RightsEnforcer для:
Товаров в корзине pkg/user/infra/middleware/user_product_right_enforcer.go.
Пошагово объясняем, как встроить быстрое и безопасное распознавание паспорта РФ в Android. Нативное приложение с возможностью распознавания ДУЛ на устройстве.
Вышел Ruby 4.0: язык получил экспериментальную изоляцию Ruby Box, новый JIT-компилятор ZJIT, ускорения производительности, улучшенный параллелизм и обновления стандартной библиотеки