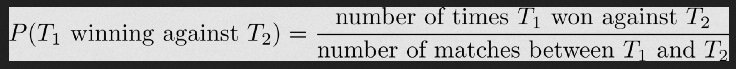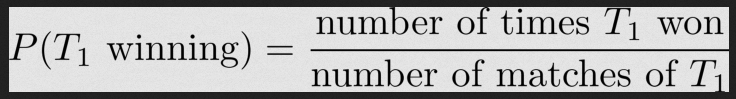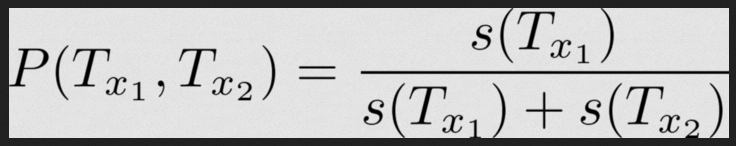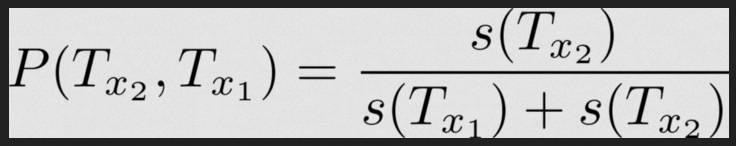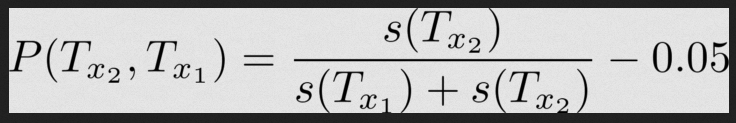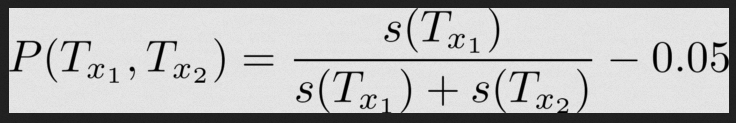Построили математическую модель, которая предсказала победителя Чемпионата мира по футболу в 2022 году по данным побед на прошлых турнирах.
5К открытий5К показов
Пользователь Piero Paialunga провёл математический эксперимент: он построил модель, которая предсказала победителя Чемпионата мира по футболу в 2022 году. Математическая модель учитывает данные прошлых лет и показатели сборных.
Дисклеймер: не используйте модель для ставок на спорт, ради бога! Это всего лишь математика, развлечение для гиков, а не оракул, которому можно безусловно доверять. Реальность куда более непредсказуема, поэтому поберегите свои деньги.
Создадим таблицу с расчётами, чтобы их было удобнее сравнивать. Результаты занесем в столбец Результат — Result.
win_draw_lose = []
for i in range(len(data_matches)):
home_team_goal = int(data_matches['Home Team Goals'].loc[i])
away_team_goal = int(data_matches['Away Team Goals'].loc[i])
if home_team_goal == away_team_goal:
win_draw_lose.append('Draw')
if home_team_goal>away_team_goal:
win_draw_lose.append(data_matches['Home Team Name'].loc[i])
if home_team_goal
Выберем команды, которые принимают участие в Чемпионате мира 2022.
Теперь нужно сопоставить данные расчётов с данными по командам 2022 года. К примеру, данных по Катару, согласно нашей модели, у нас быть не может.
team_list = list(set(data_matches['Home Team Name']))
for t in qatar_team_list:
if t not in team_list:
print('Houston, we have a problem with team %s'%(t))
qatar_probabilities = {'Win':0.20,'Draw':0.20,'Lose':0.60}
Проверим работу модели на случайных странах. К примеру, на сборных Уэльса, Камеруна, Кореи и Мексики.
for i in range(1,5):
plt.subplot(2,2,i)
random_team = np.random.choice(qatar_team_list)
plt.title('Stats for team = %s'%(random_team),fontweight='bold')
team_data,stats = select_team_statistics(random_team)
labels, values = stats.keys(),stats.values()
plt.pie(values, labels = labels,colors=['navy','darkorange','firebrick'])
Всё работает. Однако нам нужно высчитать вероятности для отдельных матчей, а не для целых сборных. Применим новое правило:
def select_match_statistics(team_A, team_B):
data_team = data_matches[(data_matches['Home Team Name']==team_A)& (data_matches['Away Team Name']==team_B)]
data_team = data_team.append(data_matches[(data_matches['Home Team Name']==team_B)& (data_matches['Away Team Name']==team_A)])
len_data = len(data_team)
if len_data==0:
print('These teams never played against each other')
else:
print('These teams played against each other %i times'%(len_data))
team_A_win = len(data_team[data_team.Result==team_A])
team_B_win = len(data_team[data_team.Result==team_B])
draw = len(data_team[data_team.Result=='Draw'])
return data_team,{team_A:team_A_win,team_B:team_B_win,'Draw':draw}
Такая модель будет работать только в том случае, если сборные уже играли между собой в прошлом. К примеру, вот что будет, если смодулировать матч Франция — Италия:
data_match,stats = select_match_statistics('France','Italy')
These teams played against each other 5 times
Но если сравнить Францию и Катар, возникнет проблема:
data_match,stats = select_match_statistics('France','Qatar')
These teams never played against each other
Теперь мы столкнулись с проблемой. У нас нет никаких данных, чтобы предсказать исход такого матча. В этом случае для сравнения предлагается использовать количество раз, когда команда проходила групповой этап.
Также будут учитываться разы, когда интересная нам сборная выигрывала Кубок мира.
Теперь у нас есть две команды, и первая предположительно выигрывает в функции P(T_x1, T_x2). В этом случае преобразуем модель:
Та же модель для второй команды:
Сейчас модели могут рассчитывать только победу одной из команд, если нет данных по их прошлым играм. Но ведь они могут сыграть вничью, верно?
Вероятность для них в целом выглядит так:
Реализуем эту идею в коде.
Функция для предсказания результата одной команды:
def find_score(team):
team_data, stats = select_team_statistics(team)
team_stage = team_data['Stage'].reset_index().drop('index',axis=1)
sum_groups = 0
sum_finals = 0
for s in range(len(team_stage)):
stage_val = team_stage.loc[s].values[0].split(' ')
if stage_val[0]=='Group':
sum_groups = sum_groups + 1
if stage_val[0]!='Group':
sum_finals = sum_finals + 1
score_1 = sum_finals/(sum_groups+sum_finals)
try:
score_2 = 0.5*data_winner.value_counts(subset='Winner')[team]
except:
score_2=0
return score_1+score_2
Функция для предсказания результатов сразу двух команд:
def find_score_two_teams(team_A,team_B):
if team_A == 'Qatar':
score_1 = 0.09
score_2 = find_score(team_B)
if team_B == 'Qatar':
score_2 = 0.09
score_1 = find_score(team_A)
if team_A!='Qatar' and team_B!='Qatar':
score_1 = find_score(team_A)
score_2 = find_score(team_B)
team_A_score = score_1/(score_1+score_2)
team_B_score = score_2/(score_1+score_2)
if team_A_score>team_B_score:
team_A_score = min(0.90,team_A_score)
team_B_score = max(0.10,team_B_score)
else:
team_B_score = min(0.90,team_B_score)
team_A_score = max(0.10,team_A_score)
team_A_score = team_A_score-0.05
team_B_score = team_B_score-0.05
res = {team_A: team_A_score, team_B:team_B_score, 'Draw':0.10}
return res
Результат Катара, таким образом, будет равен 0.09. Это вполне справедливо при условии, что сборная никогда на играла на Кубке мира.
Полная функция:
def select_match_statistics(team_A, team_B):
data_team = data_matches[(data_matches['Home Team Name']==team_A)& (data_matches['Away Team Name']==team_B)]
data_team = data_team.append(data_matches[(data_matches['Home Team Name']==team_B)& (data_matches['Away Team Name']==team_A)])
len_data = len(data_team)
if len_data==0:
#print('These teams never played against each other')
res = find_score_two_teams(team_A,team_B)
else:
#print('These teams played against each other %i times'%(len_data))
team_A_win = len(data_team[data_team.Result==team_A])/len_data
team_B_win = len(data_team[data_team.Result==team_B])/len_data
draw = len(data_team[data_team.Result=='Draw'])/len_data
res_list = [team_A_win,team_B_win,draw]
cond = 0
for i in range(len(res_list)):
if res_list[i]==1.0:
res_list[i] = 0.80
k=i
cond = 1
break
if cond==1:
for i in range(len(res_list)):
if i!=k:
res_list[i]=0.10
res = {team_A:res_list[0],team_B:res_list[1],'Draw':res_list[2]}
return data_team,res
group_name = group_B
for team_1 in group_name:
for team_2 in group_name:
if team_1!=team_2:
_,stats = select_match_statistics(team_1,team_2)
if sum(stats.values())==0:
print(stats)
print('How do we do that? :(')
else:
print(stats)
Вот функция, которая позволяет задать название группы и определить результат:
def run_group(group_name):
data_res = pd.DataFrame(np.zeros(len(group_name)).T,index= group_name,columns=['Points'])
for team_1 in group_name:
for team_2 in group_name:
if team_1!=team_2:
_,stats = select_match_statistics(team_1,team_2)
result = np.random.choice(list(stats.keys()),p=list(stats.values()))
try:
data_res['Points'].loc[result]=data_res['Points'].loc[result]+3
except:
data_res['Points'].loc[team_1]=data_res['Points'].loc[team_1]+1
data_res['Points'].loc[team_2]=data_res['Points'].loc[team_2]+1
return data_res.sort_values(by='Points',ascending=False)
Функция для всех групп:
group_names = ['group A','group B','group C','group D','group E','group F','group G','group H']
def run_groups():
group_list =[]
for g in range(len(groups)):
g_group = run_group(groups[g])
g_group = g_group.rename(columns={'Points':'Points '+group_names[g]})
group_list.append(g_group)
return group_list
Та же функция для всех групп:
group_names = ['group A','group B','group C','group D','group E','group F','group G','group H']
def run_groups():
group_list =[]
for g in range(len(groups)):
g_group = run_group(groups[g])
g_group = g_group.rename(columns={'Points':'Points '+group_names[g]})
group_list.append(g_group)
return group_list
Запускаем симуляцию для всех групп:
group_list = run_groups()
Взглянем на результаты:
[ Points group A
Netherlands 13.0
Senegal 11.0
Ecuador 7.0
Qatar 3.0,
Points group B
USA 14.0
England 13.0
Wales 7.0
IR Iran 0.0,
Points group C
Argentina 15.0
Saudi Arabia 9.0
Poland 9.0
Mexico 3.0,
Points group D
Denmark 15.0
France 12.0
Australia 9.0
Tunisia 0.0,
Points group E
Spain 11.0
Germany 11.0
Costa Rica 10.0
Japan 1.0,
Points group F
Belgium 13.0
Croatia 10.0
Morocco 9.0
Canada 2.0,
Points group G
Brazil 14.0
Switzerland 11.0
Cameroon 9.0
Serbia 0.0,
Points group H
Uruguay 14.0
Korea Republic 9.0
Portugal 6.0
Ghana 5.0]
Выглядит вполне реалистично!
Посмотрим, что покажет отборочный этап:
def find_qualification_stage(res_groups):
qual_matches = []
group_stage = np.arange(0,len(groups),2)
k=0
for g in range(len(group_stage)):
qual_matches.append([res_groups[k].index[0],res_groups[k+1].index[1]])
qual_matches.append([res_groups[k].index[1],res_groups[k+1].index[0]])
k=k+2
return qual_matches
def elimination_stage(selections,k=1):
quarter_finals_team = []
for i in range(len(selections)):
team_1 = selections[i][0]
team_2 = selections[i][1]
_,stats = select_match_statistics(team_1,team_2)
result = np.random.choice(list(stats.keys()),p=list(stats.values()))
if result=='Draw':
result = np.random.choice([team_1,team_2],p=[0.5,0.5])
quarter_finals_team.append(result)
if k ==1:
quarter_finals_team=np.array(quarter_finals_team).reshape(2,-1)
return quarter_finals_team
Запустим симуляцию 10 тысяч раз, чтобы результаты были максимально достоверными:
stats = []
for i in range(10000):
if (i%100)==0 and i>0:
print('Running Simulation number %i' %(i))
so_far = pd.DataFrame(stats).value_counts().index[0][0]
print('Most predicted winner so far is %s'%(so_far))
winner = whole_tournament()
stats.append(winner)
Running Simulation number 100
Most predicted winner so far is Spain
Running Simulation number 200
Most predicted winner so far is Spain
Running Simulation number 300
Most predicted winner so far is Spain
Running Simulation number 400
Most predicted winner so far is Spain
Running Simulation number 500
Most predicted winner so far is Spain
Running Simulation number 600
Most predicted winner so far is Spain
Running Simulation number 700
Most predicted winner so far is Spain
Running Simulation number 800
Most predicted winner so far is Spain
Running Simulation number 900
Most predicted winner so far is Spain
Running Simulation number 1000
Most predicted winner so far is Spain
Running Simulation number 1100
Most predicted winner so far is Spain
Running Simulation number 1200
Most predicted winner so far is Spain
Running Simulation number 1300
Most predicted winner so far is Spain
Running Simulation number 1400
Most predicted winner so far is Spain
Running Simulation number 1500
Most predicted winner so far is Spain
Running Simulation number 1600
Most predicted winner so far is Spain
Running Simulation number 1700
Most predicted winner so far is Spain
Running Simulation number 1800
Most predicted winner so far is Spain
Running Simulation number 1900
Most predicted winner so far is Spain
Running Simulation number 2000
Most predicted winner so far is Spain
Running Simulation number 2100
Most predicted winner so far is Spain
Running Simulation number 2200
Most predicted winner so far is Spain
Running Simulation number 2300
Most predicted winner so far is Spain
Running Simulation number 2400
Most predicted winner so far is Spain
Running Simulation number 2500
Most predicted winner so far is Spain
Running Simulation number 2600
Most predicted winner so far is Spain
Running Simulation number 2700
Most predicted winner so far is Spain
Running Simulation number 2800
Most predicted winner so far is Spain
Running Simulation number 2900
Most predicted winner so far is Spain
Running Simulation number 3000
Most predicted winner so far is Spain
Running Simulation number 3100
Most predicted winner so far is Spain
Running Simulation number 3200
Most predicted winner so far is Spain
Running Simulation number 3300
Most predicted winner so far is Spain
Running Simulation number 3400
Most predicted winner so far is Spain
Running Simulation number 3500
Most predicted winner so far is Spain
Running Simulation number 3600
Most predicted winner so far is Spain
Running Simulation number 3700
Most predicted winner so far is Spain
Running Simulation number 3800
Most predicted winner so far is Spain
Running Simulation number 3900
Most predicted winner so far is Spain
Running Simulation number 4000
Most predicted winner so far is Spain
Running Simulation number 4100
Most predicted winner so far is Spain
Running Simulation number 4200
Most predicted winner so far is Spain
Running Simulation number 4300
Most predicted winner so far is Spain
Running Simulation number 4400
Most predicted winner so far is Spain
Running Simulation number 4500
Most predicted winner so far is Spain
Running Simulation number 4600
Most predicted winner so far is Spain
Running Simulation number 4700
Most predicted winner so far is Spain
Running Simulation number 4800
Most predicted winner so far is Spain
Running Simulation number 4900
Most predicted winner so far is Spain
Running Simulation number 5000
Most predicted winner so far is Spain
Running Simulation number 5100
Most predicted winner so far is Spain
Running Simulation number 5200
Most predicted winner so far is Spain
Running Simulation number 5300
Most predicted winner so far is Spain
Running Simulation number 5400
Most predicted winner so far is Spain
Running Simulation number 5500
Most predicted winner so far is Spain
Running Simulation number 5600
Most predicted winner so far is Spain
Running Simulation number 5700
Most predicted winner so far is Spain
Running Simulation number 5800
Most predicted winner so far is Spain
Running Simulation number 5900
Most predicted winner so far is Spain
Running Simulation number 6000
Most predicted winner so far is Spain
Running Simulation number 6100
Most predicted winner so far is Spain
Running Simulation number 6200
Most predicted winner so far is Spain
Running Simulation number 6300
Most predicted winner so far is Spain
Running Simulation number 6400
Most predicted winner so far is Spain
Running Simulation number 6500
Most predicted winner so far is Spain
Running Simulation number 6600
Most predicted winner so far is Spain
Running Simulation number 6700
Most predicted winner so far is Spain
Running Simulation number 6800
Most predicted winner so far is Spain
Running Simulation number 6900
Most predicted winner so far is Spain
Running Simulation number 7000
Most predicted winner so far is Spain
Running Simulation number 7100
Most predicted winner so far is Spain
Running Simulation number 7200
Most predicted winner so far is Spain
Running Simulation number 7300
Most predicted winner so far is Spain
Running Simulation number 7400
Most predicted winner so far is Spain
Running Simulation number 7500
Most predicted winner so far is Spain
Running Simulation number 7600
Most predicted winner so far is Spain
Running Simulation number 7700
Most predicted winner so far is Spain
Running Simulation number 7800
Most predicted winner so far is Spain
Running Simulation number 7900
Most predicted winner so far is Spain
Running Simulation number 8000
Most predicted winner so far is Spain
Running Simulation number 8100
Most predicted winner so far is Spain
Running Simulation number 8200
Most predicted winner so far is Spain
Running Simulation number 8300
Most predicted winner so far is Spain
Running Simulation number 8400
Most predicted winner so far is Spain
Running Simulation number 8500
Most predicted winner so far is Spain
Running Simulation number 8600
Most predicted winner so far is Spain
Running Simulation number 8700
Most predicted winner so far is Spain
Running Simulation number 8800
Most predicted winner so far is Spain
Running Simulation number 8900
Most predicted winner so far is Spain
Running Simulation number 9000
Most predicted winner so far is Spain
Running Simulation number 9100
Most predicted winner so far is Spain
Running Simulation number 9200
Most predicted winner so far is Spain
Running Simulation number 9300
Most predicted winner so far is Spain
Running Simulation number 9400
Most predicted winner so far is Spain
Running Simulation number 9500
Most predicted winner so far is Spain
Running Simulation number 9600
Most predicted winner so far is Spain
Running Simulation number 9700
Most predicted winner so far is Spain
Running Simulation number 9800
Most predicted winner so far is Spain
Running Simulation number 9900
Most predicted winner so far is Spain
Вот диаграмма, на которой показано количество выигрышей для сборных:
В общем, с огромным отрывом должна победить Испания. Сенегал, Коста-Рика, Эквадор приятно удивляют. Испания, Германия и Англия остаются ожидаемыми лидерами.
Попытаемся определить вторую команду турнира:
plt.figure(figsize=(10,10))
plt.title('Second Team Statistics',fontsize=20)
pd.DataFrame(stats[:,1])[0].value_counts().plot(kind="bar")
Модель говорит, что второй командой окажутся Нидерланды!
Заключение
Теперь можно смотреть футбол и сравнивать наши результаты с реальными. ?
Повторяем, не используйте алгоритм для ставок на спорт. Тем более, что реальность уже немного отличается от предсказания математической модели.
Узнайте, как автоматизировать безопасность разработки ПО с помощью DevSecOps и искусственного интеллекта. В статье рассмотрены ключевые принципы, инструменты, примеры применения AI и практические рекомендации по интеграции новых технологий для повышения уровня безопасности и эффективности процессов CI/CD.