


Обеспечение низких задержек в высоконагруженной системе: разбор реального кейса
Как разработчику обеспечить низкие задержки сложной системы при высоких нагрузках: поделился методологией решения задачи.
800 открытий5К показов

Как разработчику обеспечить низкие задержки сложной системы при высоких нагрузках? Ведущий эксперт IT_ONE Максим Юнусов делится методологией для решения этой задачи, на примере реального проекта: модернизации Подсистемы обеспечения доступа к данным федеральной государственной информационной системы «Единая система межведомственного электронного взаимодействия» (ПОДД СМЭВ 4).
Постановка задачи
СМЭВ – это система, обеспечивающая электронное взаимодействие различных органов государственной власти. Предполагается, что в дальнейшем к ней могут быть подключены в качестве поставщиков и другие участники: коммерческие организации и частные лица. Доступ пользователей (потребителей данных) к информации поставщиков данных внутри системы осуществляется в формате Витрин данных – специализированных наборов структурированных данных. Соответственно, ПОДД СМЭВ – это компонент транспортной подсистемы СМЭВ, обеспечивающий доступ к данным, размещенным на Витринах данных. Предполагается, что ПОДД должна исполнять различные сложные запросы.
Итак, архитектурно ПОДД до трансформации – распределенная система из множества связанных между собой компонентов. Ее ядром является планировщик запросов на базе Apache Calcite, а основной протокол взаимодействия компонентов – журнал на базе Apache Pulsar, обеспечивающий гарантированность доставки. Механизм ограничения нагрузки (Rate Limiting) защищает систему от DoS-атак. Обработка запроса включает разбор запроса, производимый при каждом вызове. С целью обеспечить гарантированную доставку все сообщения сохраняются на диск.
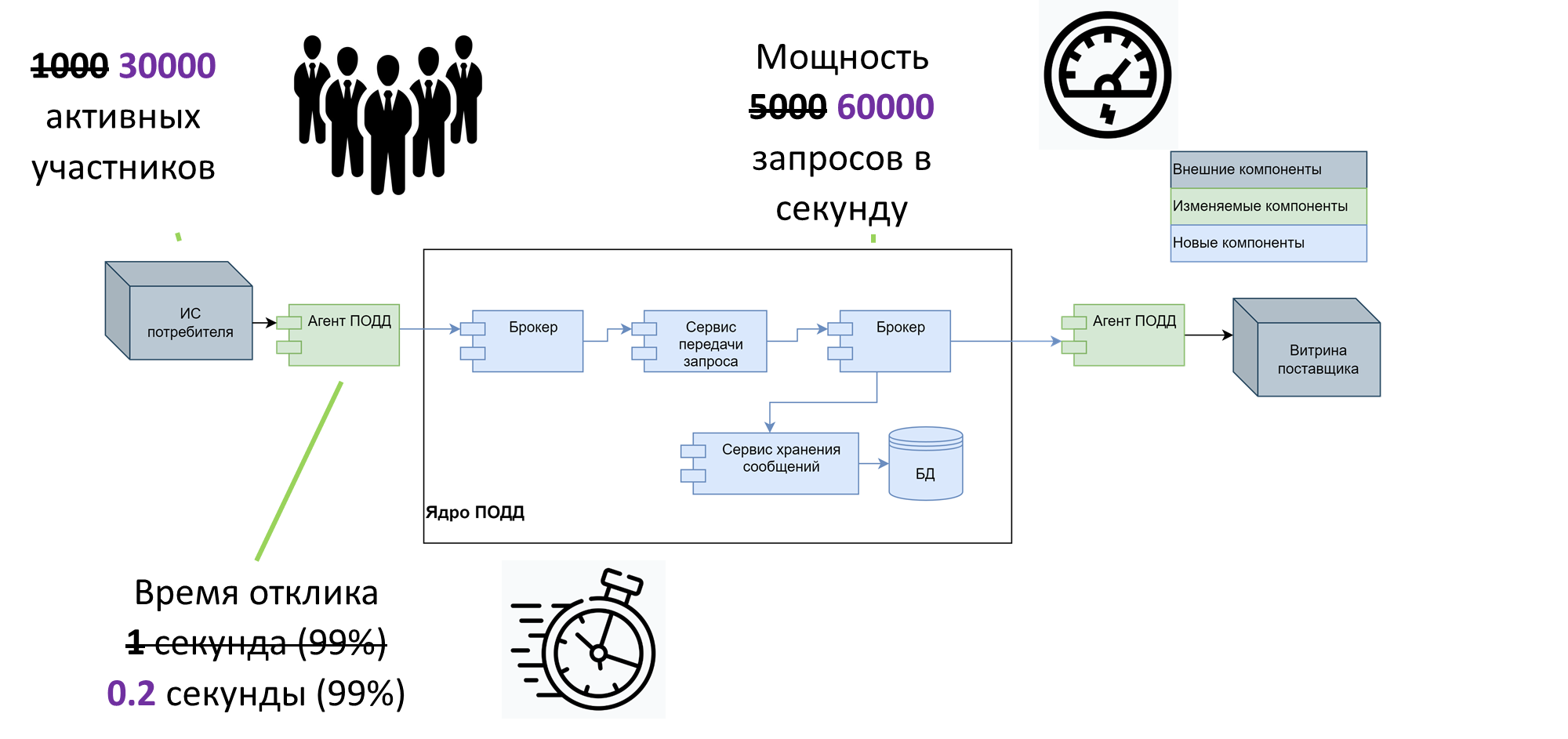
До трансформации система поддерживала 1000 активных пользователей одновременно, время отклика 1 секунду (в 99% случаев) и мощность (пропускную способность) 5000 запросов в секунду. В соответствии с ТЗ заказчика, нам необходимо было получить следующие характеристики: 25000 активных пользователей, мощность 30000 запросов в секунду и время отклика не более 0,5 секунд на 99%.
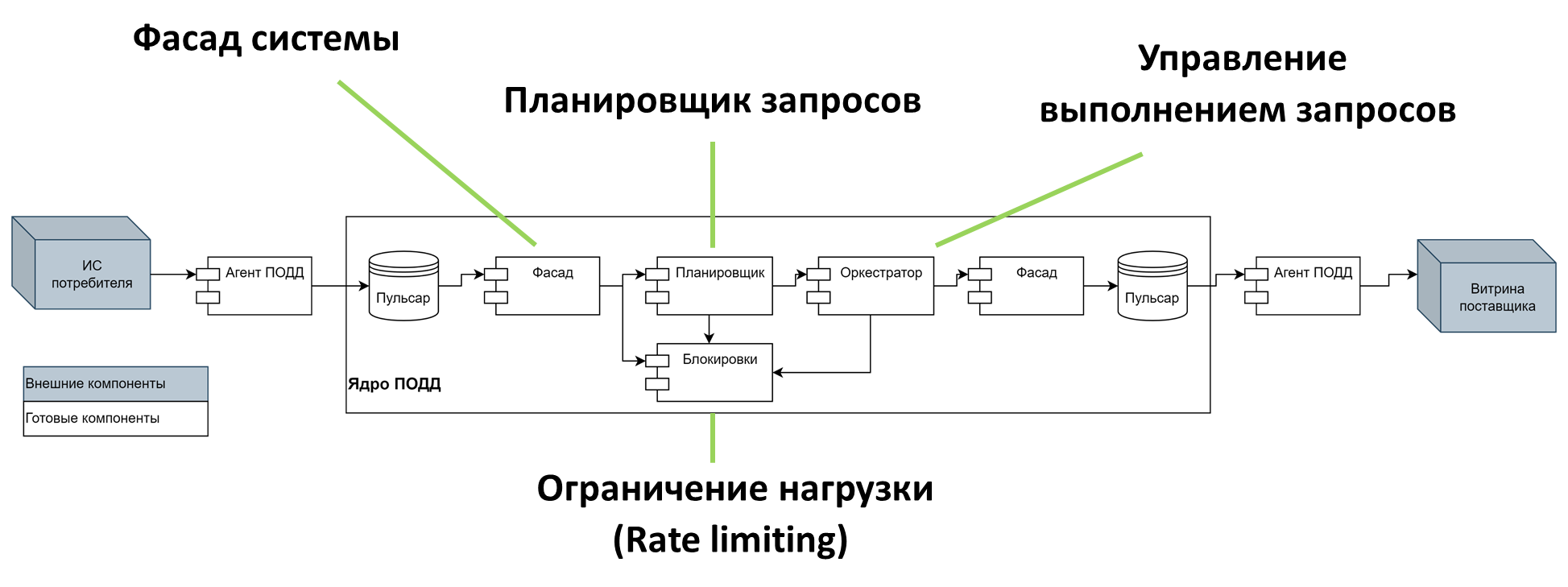
Среди большого количества дополнительных ограничений необходимо отметить два: реализацию проекта на имеющемся «железе» и очень короткие сроки – один квартал. Таким образом, классическое решение задачи производительности – «затопить железом» – отпало само собой. Как и распространенная эволюционная модель: «попробовал, проверил, если не получилось – переделал». Надо было сразу спроектировать систему таким образом, чтобы уже на этапе планирования архитектура решения оказалась приемлемой по стоимости и обеспечивала ожидаемые показатели.
Этап 1: сдвигаем «бутылочное горлышко»
Предельные значения пропускной способности и времени отклика определяются максимальной потребностью в ресурсе – то есть временем, проведенном задачей на аппаратном ресурсе. Тот ресурс, который более всего замедляет систему, становится так называемым «бутылочным горлышком», задавая показатели производительности, выше которых подняться невозможно. Это основная проблема любой высоконагруженной системы, поэтому авторы учебников рекомендуют начинать ее оптимизацию именно с поиска «бутылочного горлышка». Оптимизация этого ресурса дает существенно больший выигрыш в производительности, чем оптимизация любого другого компонента системы.
Классический алгоритм действий для решения этой задачи – принцип центрирования. Находим «бутылочное горлышко» по симптомам: максимальная утилизация ресурса, максимальная потребность в ресурсе (время пребывания в ресурсе за один запрос), максимальная очередь к ресурсу. В нашем случае оно было очевидным: Apache Calcite. Обработчик запросов и тормозил систему больше всего. Для уменьшения потребности в этом ресурсе мы последовательно рассмотрели несколько тактик.
Первая – оптимизация алгоритма. Это был бы хороший заход, если бы Calcite писался нами «с нуля». Calcite не ускорить и сложно заменить, переписать его можно, но очень дорого. Мы сделали из него практически собственный форк, но в итоге уперлись в некоторые основные механизмы, которые переписывать не рискнули. Таким образом, эффективность здесь не особо работает.
Вторая – переиспользование ресурсов и результатов, кэширование. Это тоже отличная тактика, но в нашем случае она не работает, так как запросы, поступающие в систему, – уникальные, и кэширование не дает никакого эффекта.
Третья – уменьшение накладных расходов, то есть экономия на транспорте. Вариант приемлем, когда в системе много времени уходит на взаимодействия, всевозможные перекладывания, перекодирование и т. д. Здесь он не работает, так как в рамках Calcite накладных расходов просто нет.
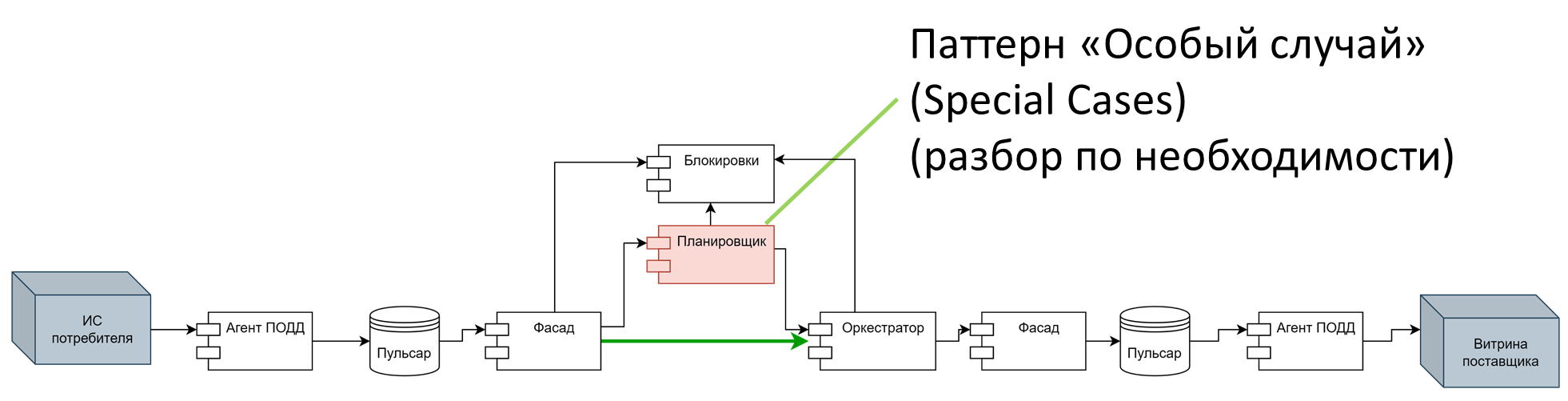
Четвертая – раннее связывание. Подход здесь следующий: если большинство запросов регламентированы, то есть SQL известны заранее, мы можем разобрать их еще до выполнения, а потом просто брать их с диска и выполнять.
Эту тактику мы и выбрали. Убрали разбор и планирование запроса Calcite с основного пути, передвинув его в область «особых случаев» (паттерн Special Cases). То есть, когда система получит неизвестный SQL, то погонит его через Calcite. В остальных случаях планы запросов составляются заранее и берется уже готовый, закэшированный план выполнения. Это существенно сократило время выполнения запросов.
К сожалению, «бутылочное горлышко» полностью устранить нельзя, его можно только передвинуть. В нашем случае, решив проблему с Calcite, мы уперлись в следующую проблему: механизм проверки подписи входящих сообщений «КриптоПро». С ним не работает ни одна тактика оптимизации, поэтому данное «бутылочное горлышко» нам пришлось оставить.
Но уже на этом этапе мы добились времени отклика примерно 300 микросекунд на основных сервисах и пропускной способности 10000 запросов в секунду. Количество одновременных активных пользователей осталась прежней – 1000.
Оптимизация «надсистемы»
Согласно методологии, если системе не удается больше ничего улучшить, нужно выходить в «надсистему» – то есть не бить «точечно» по сервисам, а смотреть на систему целиком. И на этом этапе на первый план выходит третья из перечисленных выше тактик – уменьшение накладных расходов. Здесь уже появляется сетевое взаимодействие, которое вполне можно оптимизировать.
По нашим подсчетам, на пути каждого запроса в системе происходит 6 взаимодействий, большинство из них это Apache Pulsar. Мы можем уменьшить накладные расходы прежде всего за счет снижения количества этих взаимодействий, а также за счет их облегчения самих по себе. Важное правило, которым я всегда пользуюсь: быстро бегущий «монолит» лучше группы микросервисов. Микросервисы – это не про производительность, а скорее про то, как быстро вывести фичу на рынок. Если же вы хотите избавиться от накладных расходов, сервисы придется укрупнять. Мы уменьшили количество соединений до 4, сэкономили несколько микросекунд, устранили избыточные сетевые задержки.
Чтобы сделать сами соединения легче, мы обратили внимание на дисковые операции. Дело в том, что Pulsar каждое сообщение пишет на диск. Делает он это быстро и эффективно, но в силу своих особенностей не умеет так же быстро и эффективно стирать вычитанные сообщения. Вследствие этого дисковое пространство под нагрузкой переполнялось очень быстро, отсюда и возникало ограничение количества активных пользователей.
Разумное решение – убрать сохранение на диск, заменив Pulsar механизмом RSocket. В итоге брокер у нас остался, но самописный и легкий. Потоковое взаимодействие обеспечивается поверх других взаимодействий, а значит, если мы один раз установили соединение, то потом не тратим время на его переустановление.
Однако при такой схеме мы теряем важную характеристику – гарантированную доставку, которая должна обеспечить надежность системы на уровне 99,999% (пять девяток). Поэтому вместо сохранения всех сообщений на диске мы применяем схему с надежным подписчиком (Durable Subscriber): то есть прогоняем все запросы через память, но если кто-то на этом пути запрос не забрал, система отправляет его на диск и поднимает оттуда, когда Агент ПОДД заново вычитывает свои сообщения. Для реализации этой схемы мы использовали инструмент BookKeeper, который остался после Pulsar.

Результат – система поддерживает одновременную работу 30000 активных участников, сквозное время отклика – 20 микросекунд. Пропускная способность сохраняется с первого этапа: 10000 запросов в секунду. Напомним, что нам нужно поднять ее до 30000.
Разумное масштабирование
Поскольку на этапе оптимизации «бутылочного горлышка» мы уперлись в «КриптоПро», решение задачи по увеличению пропускной способности системы теперь будет связано с масштабированием – добавлением новых инстансов сервиса. Расчет необходимого количества элементов для масштабирования с запасом показал, что количество инстансов необходимо увеличить в 4 раза.
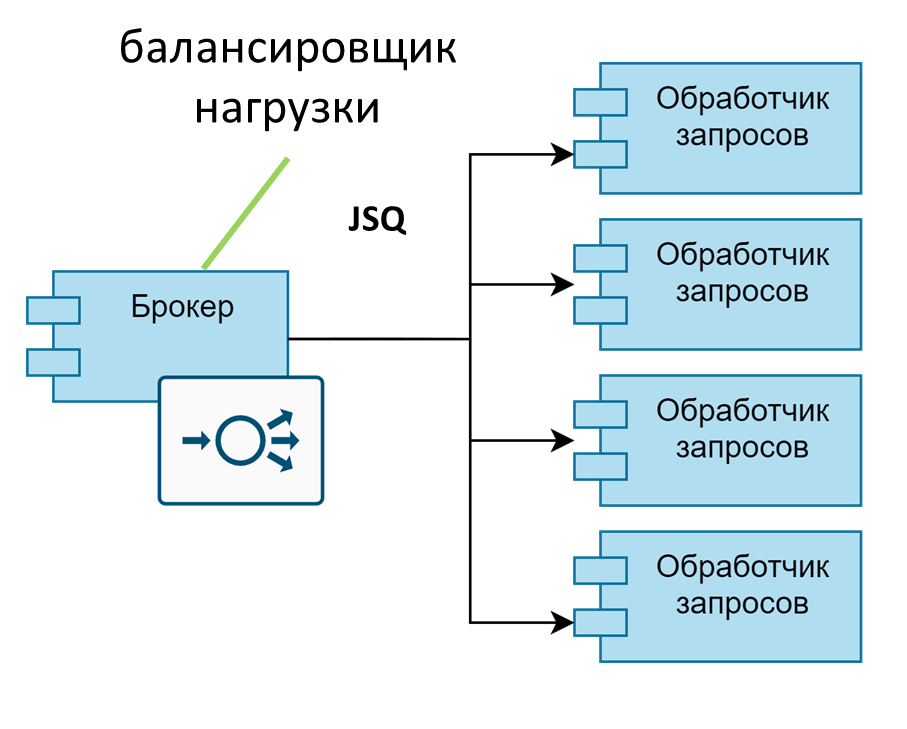
Однако на этом задача на практике не исчерпывается. Дело в том, что масштабирование – это не только количество «железа», но и, в том числе, грамотная балансировка. Несбалансированная обработка нивелирует эффективность масштабирования – ведь если балансировщик все запросы будет отправлять на один инстанс, все остальные будут бездействовать. Так, сервис K8s с настройками по умолчанию не выполняет балансировку запросов на обслуживаемые сервисы. Когда создается TCP-соединение, оно проходит через правила iptables, которые и выбирают конкретный pod бэкенда, куда попадет трафик. Поскольку все следующие запросы идут уже по открытому TCP-соединению, правила iptables больше не вызываются.
Нужен грамотный балансировщик, который правильно распределяет задачи по инстансам, желательно используя понимание размеров и веса этих задач – так называемое умное планирование. «Коробочных» решений для этого, к сожалению, нет. Надо либо дорабатывать Kubernetes, либо самим разрабатывать решение. Мы остановились на втором варианте: использовали клиентскую балансировку Join-Shortest-Queue (JSQ) на хост с минимальной очередью. Данная балансировка самая простая с точки зрения реализации – эффективный, хотя и не идеальный алгоритм. С точки зрения времени отклика здесь идеально смотрелся бы алгоритм SITA (Size-Interval Splitting), но он может привести к недоутилизации и снижению пропускной способности.
А как же закон Амдала? Ведь, согласно нему, масштабирование не всегда приводит к успеху: бывает, что производительность падает с увеличением количества инстансов. Допустим, мы выдержим нагрузку на четырех инстансах – а какова предельная мощность системы? Для расчета максимально возможного количества инстансов мы используем не формулу Эрланга 2-го рода (в данном случае слишком сложную), а универсальный закон масштабируемости Гюнтера, USL. Эта формула дает более приблизительные ответы, но они достаточны для предварительной оценки. Закон рассматривает два коэффициента, влияющие на падение производительности: «штраф конкурентности» (contention penalty) и «штраф когерентности» (coherence penalty). Учитывая их, мы вычислили, что в нашей схеме производительность будет падать при масштабировании примерно до 10 инстансов.
Также мы нашли участника нашего взаимодействия который ограничивал наши сервисы по взаимодействию – это сервис блокировок. Без Rate Limiter в асинхронной системе не обойтись: если не ограничивать каким-то образом поток, систему рано или поздно «затопит». Если мы хотим держаться в рамках приемлемого Latency, мы должны это контролировать. В то же время существуют другие механизмы контроля потока, не только ограничение пропускной способности. В частности, контроль длины очереди возможен через организацию обратного давления (Back Pressure).
Таким образом, мы контролируем длину очереди, организуя обратное давление на агентов – просто не пускаем их в систему, пока длина очереди не станет приемлемой. Таким образом обеспечивается работоспособность системы целиком. Rate Limit в системе остался, но за пределами основного контура.
Результат
В результате проекта модернизации системы ПОДД мы добились целевых показателей и даже существенно перевыполнили их: 30000 активных участников (цель по ТЗ – 25000), мощность – 60000 запросов в секунду на 4 инстансах (цель – 30000), время отклика – 0,2 сек в 99% случаях (цель – 0,5 сек).
Перечислю основные результаты нашей работы:
- распределенная система из нескольких слабосвязанных компонентов;
- оптимизированный брокер сообщений на базе протокола Rsocket;
- предварительный расчет планов обработки с использованием Apache Calcite;
- сохранение сообщений на диск осуществляется только при невозможности доставки;
- оперативные данные не привязаны к конкретным экземплярам сервисов;
- балансировка по наименьшей очереди;
- обратное давление.
Важно, что все перечисленные шаги к достижению цели были произведены согласно эффективно выстроенной методологии, четко определенному поэтапному плану.
В качестве потенциальных доработок системы можно назвать добавление умного планирования очереди выполнения, перевод некоторых важных задач в фоновый режим, отдельную обработку непредсказуемых по времени обработки запросов. Систему можно улучшать с точки зрения производительности, но на данном этапе мы достигли целевых показателей, и остальные сценарии пока просто оставляем в уме.

800 открытий5К показов

Python 3.14 станет быстрее на 30% без изменений в коде. Оптимизация хвостовых вызовов ускорит работу интерпретатора уже в 2025 году

Подборка из 8 сервисов, которые позволяют использовать ChatGPT, Midjourney, DALL·E и другие нейросети в России — без VPN, с русским интерфейсом и полным доступом.

Разбираем трансформацию сетевых технологий — от проводных LAN до беспроводных 5G и перспектив 6G. Узнайте, как роутеры, безопасность и скорость интернета изменились за 20 лет.

Что нового в Go 1.25 — узнайте про самые заметные изменения за 10 минут. Новый сборщик мусора Green Tea, пакет encoding/json/v2, улучшение логики GOMAXPROCS, пакет testing/synctest. Обзор заметок о релизе Golang 1.25.